BigQuery ML とオブジェクト テーブルを使用して非構造化データの価値を大規模に引き出す
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
これまでは一般的に言って、データチームは構造化データを扱ってきました。2025 年までには、画像、ドキュメント、動画を含む非構造化データは、データの最大 80% を占めるようになるでしょう。ところが現在の組織は、有益な分析情報を抽出するにあたって、非構造化データの数パーセントしか使用していません。
非構造化データから価値を引き出す主な方法の一つは、データに ML を適用することです。これによって、画像からのオブジェクトの抽出、ある言語から別の言語へのテキストの変換、画像からの文字認識、感情分析などが可能になります。現在は、対応する ML モデルをホストするサービスを利用することによってこのようなタスクを実行できます。しかし、さまざまな業界の企業が次の 3 つの主な課題に直面しています。
データ管理: データ サイエンティストやアナリストは、ML パイプライン、ノートブック、その他の AI プラットフォームを構築する場所に、保存データを移動する必要がある
インフラストラクチャ管理: 大企業にとって望ましいセキュリティやガバナンスの保証がない
データ サイエンス リソースの不足: Python でのカスタム ソリューションの開発、そして Spark や Beam / Dataflow などのフレームワークの使用が必要である
BigQuery は、ユーザーが構造化データと半構造化データのすべてを管理および分析するのを支援する、業界をリードするフルマネージドのクラウド データ ウェアハウスです。BigQuery はストレージとコンピューティングのスケール メリットを活かし、ユーザーによるデータベース内機械学習の実施も可能にします。現在、BigQuery は、基礎となるデータ ウェアハウスから提供されるエンタープライズグレードのセキュリティやガバナンスの保証を犠牲にすることなくデータサイロの排除やコンピューティングの民主化を実現する、統合ソリューションを提供することによって、これらの機能を非構造化データにまで広げようとしています。データ実務者は、使い慣れた SQL コンストラクトを使用して、1 つのシステム内で構造化データと非構造化データを組み合わせることによって、画像やテキストなどを大規模に分析し、分析情報を拡充することができるようになりました。この記事では、以下について学びます。
非構造化データへのアクセスを可能にするオブジェクト テーブルについて
SQL を実行して画像から分析情報を得る方法
Cloud AI サービスを利用しながら非構造化データ分析を拡張する方法
オブジェクト テーブルを導入して非構造化データへのアクセスを可能にする
Next ‘22 において、Google は BigQuery の新しいテーブルタイプであるオブジェクト テーブルのプレビューを発表しました。オブジェクト テーブルは、Google Cloud Storage に保存されたオブジェクトのメタデータを提供します。BigLake が活用されている オブジェクト テーブルは、単一の管理フレームワークの下に構造化データと非構造化データを集約する、基本的なインフラストラクチャとして機能します。これにより、データを移動することなく、あらゆる形状や形式のデータからビジネス分析情報を引き出すための機械学習モデルを構築できます。
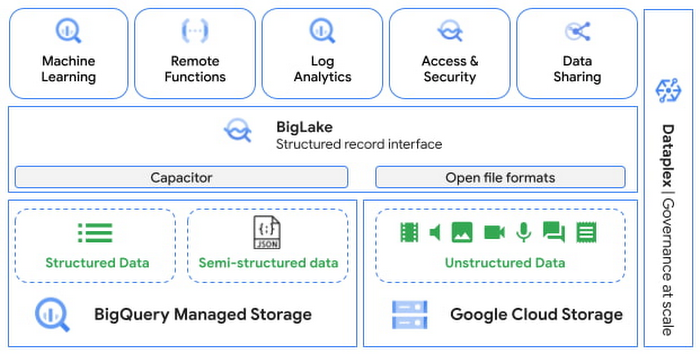
SQL を実行して画像から分析情報を獲得する
非構造化データに簡単にアクセスできることによって、画像に対する SQL を作成したり、BigQuery ML を使用して機械学習モデルから結果を予測したりできるようになります。最新の TensorFlow Vision モデル(ImageNet や ResNet 50 など)または独自のモデルのどちらかをインポートし、オブジェクトの検出、写真のアノテーション付け、画像からのテキストの抽出などを行うことができます。画像分析の結果と構造化データ(ウェブサイト トラフィックや販売注文など)を統合し、ビジネス成果を上げるための分析情報を生成するように機械学習モデルをトレーニングできます。Adswerve と Twiddy がどのようにして賃貸物件の画像を分析に組み込み、最もユーザーの心に響く検索結果を生成することができたかを見てみましょう。
Adswerve と Twiddy の事例
Adswerve は、データを身近なものにすることをミッションとする、Google マーケティング、Google アナリティクス、および Google Cloud の主要パートナーです。Twiddy & Co. は Adswerve のクライアントで、ノースカロライナ州の貸別荘会社です。顧客が夢の別荘を見つけるのをお手伝いすることにより、格別の顧客体験を創出しています。
「弊社は 45 年の長きにわたって、地元の家族経営の貸別荘会社として米国南部の温かいおもてなしを提供することに注力してきました。これまでずっと、この地ならではの体験を魅力的に表現する別荘の画像を探し求めてきました。今では、BigQuery ML によって、何千もの可能性のある選択肢を分析し、それらを既存のクリックスルー データと組み合わせることによって、適切な画像をクリエイティブに導き出すことができています。これにより、弊社のビジネス分析担当者の業務の手間が大幅に削減されました。他の方法では、もっと多くの時間がかかるか、何もできないかのどちらかでしょう。」— Twiddy & Company マーケティング ディレクター Shelley Tolbert 氏
ウェブサイト上での顧客の検索体験をさらに向上させるために、この会社は次の 3 つの課題に直面していました。
顧客の好みを予測する際、構造化データ(場所や規模など)のみに依存している
編集チームが写真選択プロセスを手作業で行っている
機械学習パイプラインを構築するためのデータ サイエンス リソースが必要であり、画像サイズを変更するためのデータの処理に手間がかかっている
この会社は、ウェブサイト検索データと賃貸物件画像の両方を使用して機械学習モデルを構築し、賃貸不動産のクリック率を予測できるようにしたいと考えていました。この会社が オブジェクト テーブルという新しい機能を備えた BigQuery ML を使用して、この目標を実現した方法を紹介します。
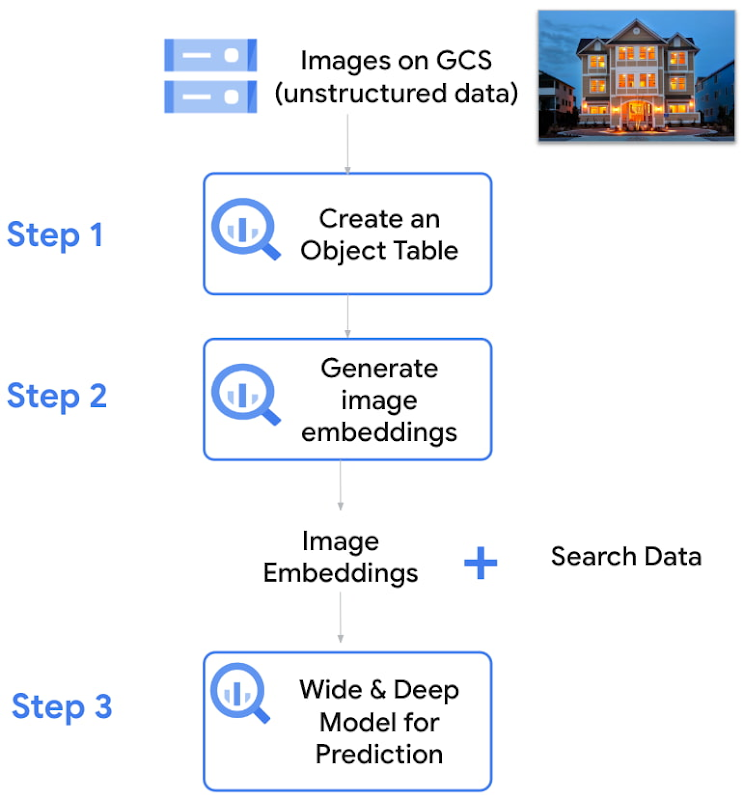
ステップ 1: オブジェクト テーブルを作成することによって画像データにアクセスする

ステップ 2: TensorFlow の画像モデルをインポートすることによって画像エンベディングを作成する

ステップ 3: 画像データとウェブサイト データの両方を使用して、ワイド&ディープ BigQuery ML 対応モデルをトレーニングし、賃貸不動産のクリック率を予測する
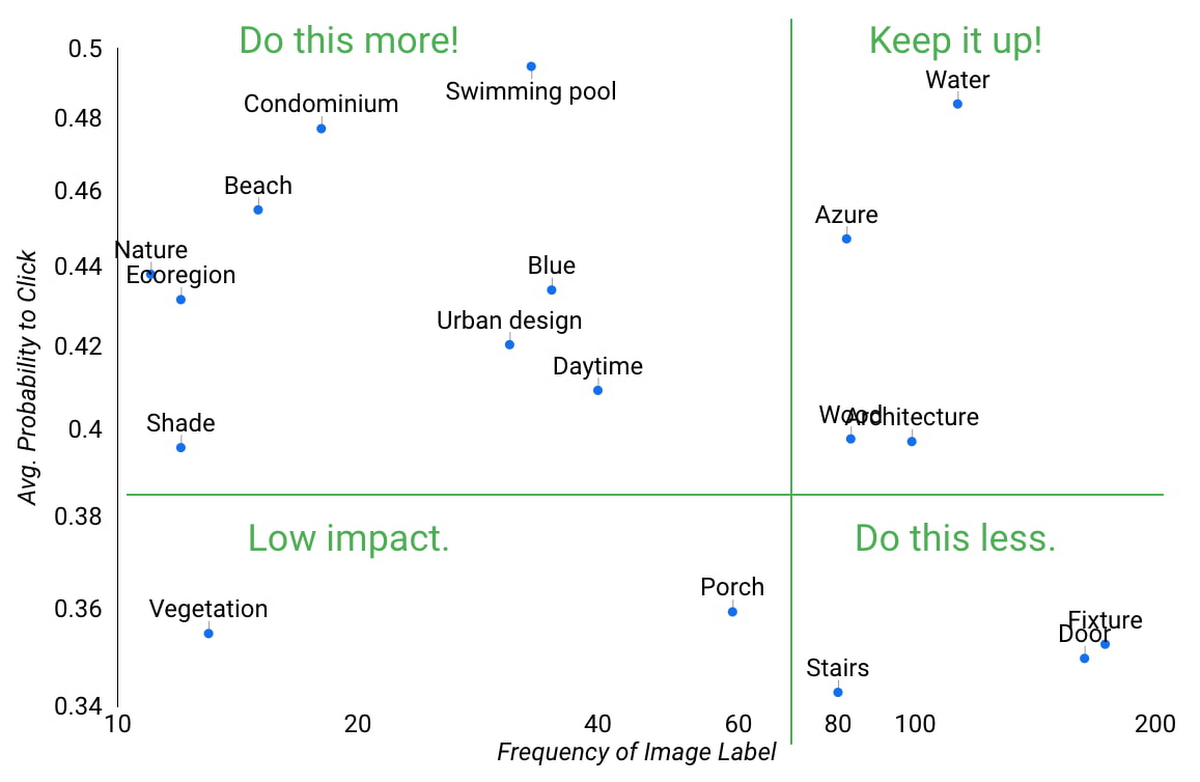
結果は、ユーザーが水辺やその他の良い景色が写った画像をクリックする傾向が強いことを示唆していました。Twiddy の編集チームはこれらの分析情報を使用して、画像の選択や編集の際に、よりデータドリブンなアプローチを取るようになりました。より専門的なデータ サイエンティストを雇用しなくても、既存のアナリストのスキルで扱える SQL を使用することによって、これらすべてを行うことができます。詳細については、Adswerve が制作した次のデモをご覧ください。
Cloud AI サービスを利用した非構造化データ分析の拡張
ユーザー独自のまたは一般に使用される機械学習モデルを使用した非構造化データの分析に加えて、Google は Cloud AI サービスを提供しており、Translation AI、Vision AI、Natural Language AI、および BigQuery に内蔵されたその他の多くの機能をご利用いただけます。テキストの翻訳、写真からのオブジェクトの検出、ユーザー フィードバックに対する感情分析の実行などのすべてを SQL で行うことができます。また、この結果を機械学習モデルに組み込んでさらに分析を進めることができます。
YouVersion 聖書アプリは 5 億台以上の一意のデバイスにインストールされています。このアプリは、聖書の本文を 1,800 を超える言語で提供し、検索は 103 の言語でサポートされています。ウクライナにおける地政学的問題の発生時に、ウクライナ語での検索件数が約 2 倍になりました。チームは、人々が何を検索しているかを理解し、検索結果が人々に希望と平和をもたらすコンテンツを提供できているかどうかを確認したいと考えました。しかし、自動翻訳機能がなかったために、チームは 1 日に何回も、検索された語をすべて手作業でコピーして Google 翻訳に貼り付けるということを何週にもわたって続けなければならず、多くの時間を費やしていました。
YouVersion は BigQuery ML を使用した翻訳機能によって、今後はアプリ内でユーザーが何を探しているかを簡単に学習できるようになるでしょう。チームは、検索結果をすばやく微調整して、ユーザーにとって適切なコンテンツを提供できるようになります。これにより、チームとサービスを受ける人々との間の言語の壁を取り払うことができます。これは世界的なコミュニティに十分に奉仕するという YouVersion の方向性と一致するものです。詳細については、YouVersion が制作した次のデモをご覧ください。
次のステップ
Google は今後も、ドキュメント、音声、動画などのさまざまな非構造化データタイプのために、これらの機能を拡張し続けます。BigQuery ML を使用して BigQuery 内の非構造化データの力を引き出す、これらの新しい機能を試すには、こちらのフォームを送信してください。Google Cloud Next で発表されたその他の BigQuery ML 機能を見つけることができます。
- BigQuery ML プロダクト マネージャー Candice Chen
- BigQuery シニア ソフトウェア エンジニアリング マネージャー Amir Hormati


