BigQuery におけるコスト最適化の ベスト プラクティス
Google Cloud Japan Team
※この投稿は米国時間 2019 年 9 月 25 日に Cloud Blog に 投稿されたものの抄訳です。
あらゆる業務のデータが各所に分散する今日の状況において、データ ウェアハウスの運営、管理は厄介で手間のかかる作業となりがちです。こうしたデータの急激な増加に対応してシステムをスケーリングし、日々の運用を維持することは、これまでになく大きな課題となっています。課題はそれだけではありません。データ ウェアハウスをアップグレードするときにダウンタイムをできるだけ短くする、ML や AI に向けた取り組みを支えてビジネスニーズに応えるなどの必要にも迫られています。Google Cloud のサーバーレス、エンタープライズ向けデータ ウェアハウスである BigQuery は、インフラ管理に手間を取られず分析作業に集中できるという点が評価され、数々の企業に導入されています。
BigQuery を使用すると、クエリを瞬く間に実行し、ストリーミング データの分析情報をリアルタイムで取得したり、高度な予測分析を行ったりできるようになります。とは言え、BigQuery に格納したデータを最適化する余地がないわけではありません。クラウド コンピューティングの時代において、テクノロジーの導入を決める最大の要素の 1 つはコストです。そのため、当然の流れとして、料金の詳細や、コストを継続的に最適化する方法がお客様の関心事となります。
Google Cloud に関するお客様からのご質問やご相談は、通常、テクニカル アカウント マネージャー(TAM)が窓口となって受け付け、信頼の置けるアドバイザーとして、お客様が正しい方向へ進めるように支援しています。ここでは、TAM としての経験と知識をもとにコストを最適化し、結果として収益の増加をもたらす方法をまとめて紹介します。BigQuery はサーバーレス アーキテクチャなので、コストを最適化することによってパフォーマンスも向上できるという特長があります。
パフォーマンスとコストのどちらか 1 つを選ぶという苦渋の決断に迫られることはありません。
(ここでは、BigQuery のコストの最適化に的を絞って説明します。Cloud Storage でのコストの最適化については、こちらのブログをご覧ください)。
BigQuery の基本的な料金体系を理解する
まず、BigQuery の料金体系を見ていきましょう。続けて、料金をサブカテゴリごとに掘り下げて、BigQuery のコストを抑える方法を紹介します。BigQuery の料金は、ロケーションにかかわらず、以下のような内訳になっています。
ストレージ
アクティブ ストレージ
長期保存ストレージ
ストリーミング挿入
クエリの処理
オンデマンド
定額料金
それぞれについて詳しく見ていく前に、まず、どのロケーションでも無料の BigQuery オペレーションをおさえておきましょう。
BigQuery へのデータの一括読み込み
自動再クラスタリング(セットアップ、メンテナンス不要)
データのエクスポート オペレーション
テーブル、ビュー、パーティション、関数、データセットの削除
エラーを返したクエリ
ストレージは毎月 10 GB まで無料
クエリで処理するデータは、毎月 1 TB まで無料(オンデマンド料金の場合の特典)
BigQuery のコスト最適化テクニック: ストレージ
BigQuery にデータを読み込むと、テーブルに格納したデータ量と秒数に基づいて課金されます。BigQuery のストレージのコストを抑えるコツは以下のとおりです。
1. 必要なデータだけをキープする。
BigQuery では、データがデフォルトで Capacitor と呼ばれるカラム形式で暗号化、圧縮された状態で格納されます。データセットにテーブルのデフォルトの有効期間を構成し、長期間にわたって保存する必要のない一時的なステージング データを削除するようにしましょう。
たとえば、天気のステージング データセットは、ダウンストリームのジョブによるクエリやクリーニングを経て、本番環境のデータセットにプッシュされた時点で不要になります。このような場合は、テーブルのデフォルトの有効期限を 7 日間に設定できます。
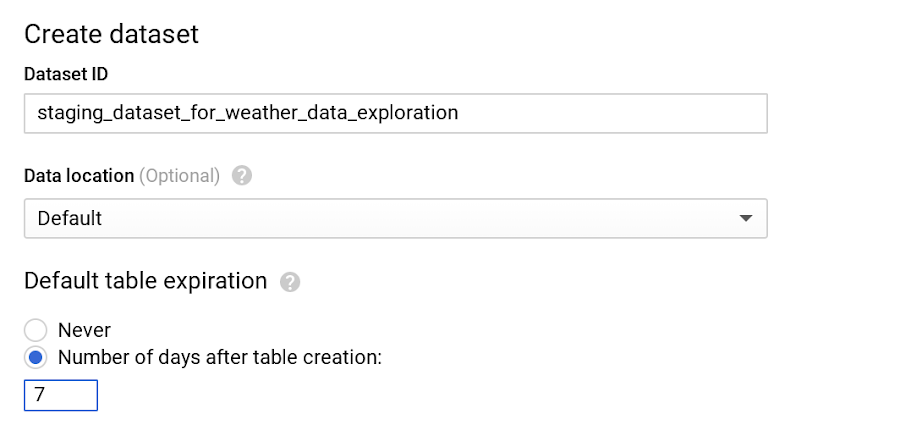
なお、テーブルのデフォルトの有効期間を変更すると、その変更は新しく作成したテーブルに対してのみ有効となります。既存のテーブルに変更を加えるには、DDL ステートメントを使用してください。
BigQuery では、同じデータセット内でテーブルごとに異なる有効期限を設定することもできます。たとえば、先ほどのデータセットに new_york というテーブルがあり、他のテーブルよりも長く保存する必要があるとしましょう。
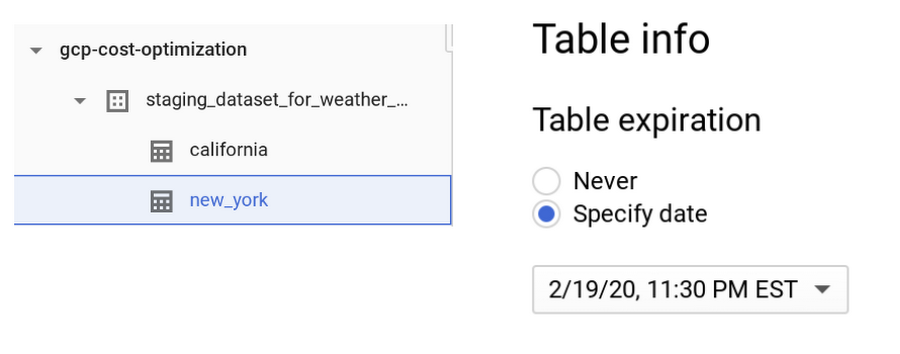
上の図のように設定すると、new_york テーブルのデータは 6 か月間保持されますが、california テーブルの有効期限は特に設定していないので、デフォルトの 7 日間になります。
ワンポイント: 有効期限は、データセットやテーブルごとのほか、パーティションごとに設定することも可能です。デフォルトの動作については、一般公開されているドキュメントをご覧ください。
2. データの編集操作に注意する。
テーブルやパーティションを 90 日間編集しなかった場合、そのデータのストレージ価格は自動的に約 50% 値下がりします。テーブルやパーティションが長期保存ストレージと見なされた場合でも、パフォーマンス、耐久性、可用性などが低下することはありません。
長期保存ストレージをできるだけ活用するため、テーブルのデータを編集する操作(データのストリーミング、コピー、読み込みや、DML オペレーション、DDL オペレーション)に気を付けましょう。こうした操作を行うと、長期保存ストレージからアクティブ ストレージに戻り、90 日間のカウントがリセットされます。これを防ぐには、新しいデータバッチを読み込む際、新しいテーブルやパーティションへの読み込みが可能かどうかを用途に応じて検討しましょう。
ワンポイント: テーブルデータに対するクエリの実行など、一部の操作では、90 日間のカウントがリセットされず、長期保存ストレージのままになります。
一般的には BigQuery にデータを置いたままにするほうがメリットが大きいですが、テーブル内のデータにアクセスするのが年に 1 度あるかないかという程度の場合は(法律や規制に従ってアーカイブを保存する場合など)、Cloud Storage バケットの Coldline クラスにテーブルデータをエクスポートすることを検討しましょう。このクラスは、長期保存ストレージよりもさらにお得な価格設定になっています。
3. データの重複コピーを避ける。
BigQuery では連携型のデータアクセス モデルを採用しており、Cloud Bigtable、Cloud Storage、Google ドライブ、Cloud SQL(ベータ版)などの外部データソースに対して直接クエリを実行することが可能です。この仕組みを利用すれば、データの重複コピーを避け、ストレージのコストを抑えることができます。さらに、外部ソースから直接データを読み取れるほか、少量のデータが頻繁に変更されるような場合には、変更のたびに BigQuery に読み込まなくても直接アクセスできるので便利です。
ワンポイント: このテクニックは、目的に応じてメリットが得られる場合にのみ使用するようにしましょう。一般的に言って、外部ソースに対するクエリは、BigQuery 上の同一データに対するクエリに比べてパフォーマンスが劣ります。BigQuery のデータはカラム形式で格納されているため、高いパフォーマンスを得られるのが特長です。
4. データをストリーミング挿入で読み込んでいるかどうかを確認する。
BigQuery の先月の請求書を見て、ストリーミング挿入の料金が発生しているかどうかをチェックしてみましょう。ストリーミング挿入の料金がかかっている場合は、以下の点を確認してみてください。「BigQuery のデータは早急に(数時間ではなく、数秒で)必要か?」、「BigQuery で用意したデータを、リアルタイムで使用するケースがあるか?」いずれかの答えがノーである場合は、完全無料の一括読み込みに切り替えることをおすすめします。
ワンポイント: BigQuery のストリーミング挿入は、データがダウンストリームの利用者によって即座に使用される場合にのみ使用しましょう。
5. BigQuery のバックアップおよび DR プロセスを理解する。
BigQuery では、テーブルの変更履歴が 7 日間保持されます。ポイントインタイム スナップショットに対してクエリを実行できるので、バックアップから復元しなくても、データを特定の時点まで戻すことが可能です。なお、テーブルを削除すると、その履歴は 2 日後にフラッシュされます。
1 時間前のテーブルのスナップショットから行数を求めるクエリの例を以下に示します。
詳しくは、ドキュメントに記載されている例を参照してください。
ワンポイント: ビジネスに不可欠なデータは、データの障害復旧シナリオのガイドに従ってバックアップするようにしましょう。特に、BigQuery をリージョンのロケーションで使用している場合は、データを必ずバックアップしてください。
BigQuery のコスト最適化テクニック: クエリの処理
BigQuery データのクエリを実行する目的には、予測分析、リアルタイムの在庫管理、企業の財務データの唯一の正確な情報源など、分析やビジネスのユースケースへの利用が考えられます。
目的は何であれ、最初は BigQuery をオンデマンド料金で使い始めるケースが一般的です。オンデマンドの場合、BigQuery や外部データソースに格納されているデータ量にかかわらず、クエリで処理するデータ量(バイト数)に応じて課金されます。従って、クエリで処理するデータ量を減らす方法を取り入れると効果的です。ここでは、クエリ(SQL コマンド、ジョブ、ユーザー定義関数など)の実行コストを削減するテクニックを見ていきましょう。
1. クエリの対象データを絞る。(特におすすめの方法)
BigQuery は、データがカラム形式で格納されているため、パフォーマンスが高いのが特長です。ただし「SELECT *」を使用すると、テーブル中のすべての列に対してクエリが実行されるため、コストが最も高くなります。この中には、不要なデータも含まれているかもしれません(前月に「SELECT *」を使った回数を数えて罪悪感に囚われるのは、あなただけではありません)。
では、クエリで処理されるデータ量の具体例を見てみましょう。以下は、BigQuery の一般公開されている天気データセットに対してクエリを実行する例です。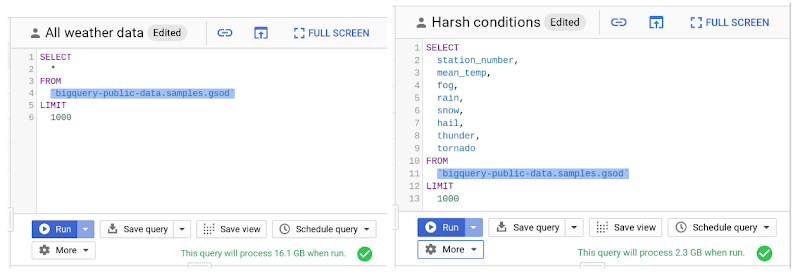
ご覧のとおり、必要な列を絞り込むことで、処理データのバイト数が約 8 分の 1 にまで減り、コスト削減に直結していることがわかります。また、LIMIT 句を適用しても、特にコストには影響しないことにご注目ください。
ワンポイント: データについて深く掘り下げたり、その背景情報を理解したりする必要がない場合は、無料のデータ プレビュー オプションの使用をおすすめします。
また、クエリ実行の最初のステージで処理されたバイト数だけが課金対象となることも重要なポイントです。中間ステージで処理されるバイト数を減らすために、複数のステージから成る複雑なクエリを作成することは、コスト面では意味がないので避けましょう(ただし、パフォーマンスが向上する可能性はあります)。
ワンポイント: クエリのできるだけ早い段階でフィルタリングを行うことで、BigQuery のコストを削減すると同時にパフォーマンスも向上できます。
2. 人為的なミスを防ぐために、上限を設定する。
上記のクエリで処理されるデータ量は GB 規模なので、たとえ間違いがあっても無駄になるのは数円程度で、ビジネスには大きく影響しません。しかし、データセット テーブルの規模が TB、PB におよぶ場合、そのすべての列に対して、しかも多数のユーザーがクエリを実行すると、いつの間にかコストが膨れ上がる恐れがあります。
このような事態を防ぐために、課金される最大バイト数を設定しておくようにしましょう。この上限を越えると、以下のようにクエリのエラーとなり、コストがそれ以上発生しなくなります。
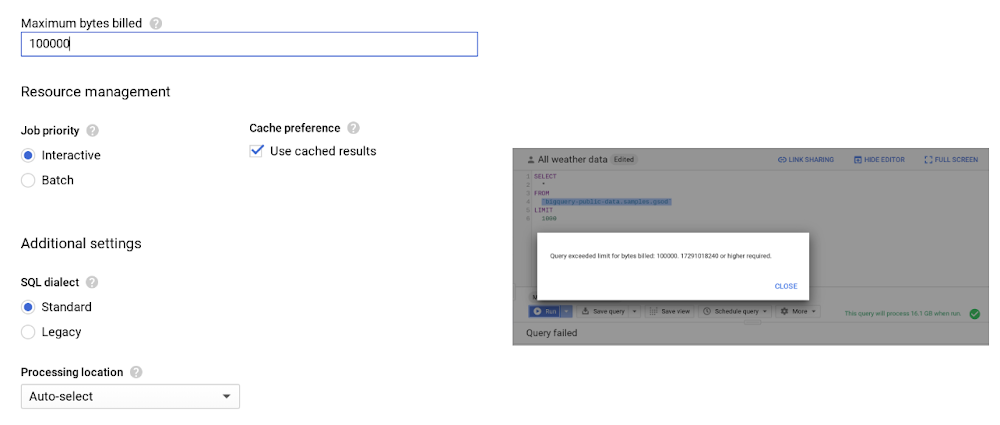
以前、カスタム コントロールの重要性について、お客様に尋ねられたことがあります。わかりやすいように、次の例を挙げて説明しました。たとえば、米国(マルチリージョンのロケーション)に 10 TB のデータがあるとしましょう。ストレージの料金は、1 か月あたり約 $200 です。このデータに対して、10 人のユーザーがそれぞれ [SELECT * .. ] を月に 10 回実行した場合、BigQuery の 1 か月あたりの処理データは 1 PB となり、料金は約 $5,000 にまで跳ね上がります。妥当な上限を設けることによって、こうした不用意なクエリを防止できます。なお、クエリの実行を途中でキャンセルした場合でも、クエリを最後まで実行したのと同じだけの料金が発生する可能性があるのでご注意ください。
ワンポイント: クエリごとに上限を設けるほか、ユーザーレベルやプロジェクト レベルで同じように制限を設けてコストをコントロールすることも可能です。
3. キャッシュを賢く利用する。
一部の例外を除き、キャッシュを使ったほうがクエリのパフォーマンスが向上します。加えて、キャッシュ テーブルから取得した結果については料金が発生しないというメリットもあります。キャッシュの設定はデフォルトでオンになっています。この設定は、GCP Console のクエリエディタで [詳細] > [クエリの設定] をクリックして、以下の画面で確認できます。
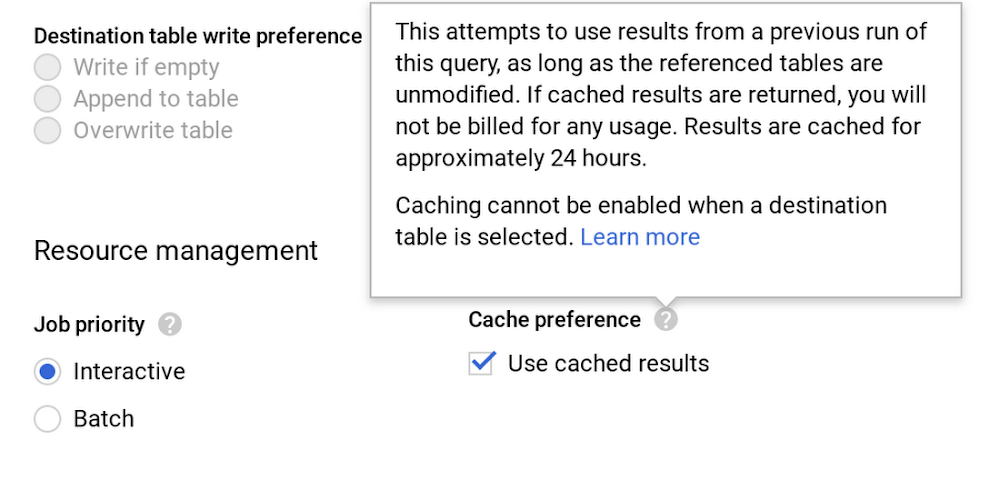
また、キャッシュはユーザーごと、プロジェクトごとに維持される点にもご注意ください。
具体例を挙げてみましょう。数百人から数千人のユーザーがアクセスするデータポータルのダッシュボードがあり、その背後で BigQuery が動作しているとします。この場合、複数のユーザー間でクエリのキャッシュを共有する工夫が必要であることがすぐにおわかりいただけるでしょう。
ワンポイント: ユーザー間のキャッシュ ヒットが高確率で起こるようにするには、単一のサービス アカウントを使って BigQuery のクエリを実行するか、コミュニティ コネクタを使用します。詳しくは、こちらの Next ‘19 のデモをご覧ください。
4. テーブルを分割する。
できるだけテーブルを分割すると、クエリ処理のコストを削減できると同時に、パフォーマンスも向上します。現時点では、取り込み時間、日付、タイムスタンプの列の値に従って、テーブルを分割できます。たとえば、過去 12 か月分のデータを含む sales テーブルを以下のように日別のテーブルに分割するとしましょう。
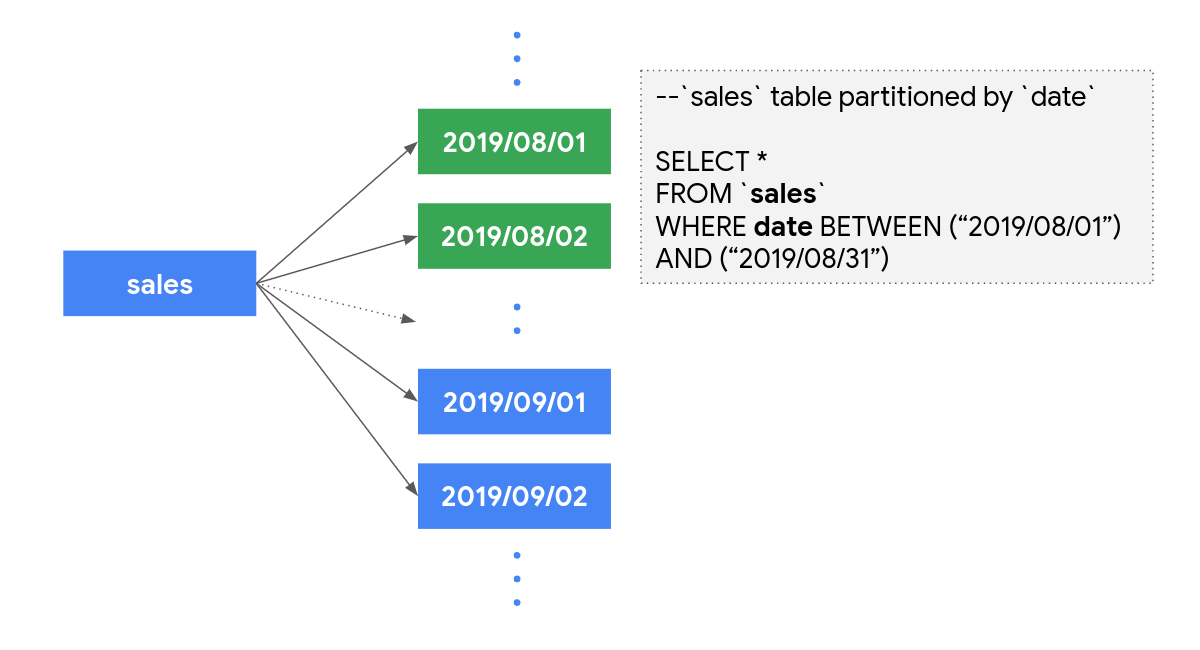
こうしておけば、8 月の sales データを分析するとき、テーブル全体ではなく、31 個のパーティションのデータのみが処理されることになり、コストを節約できます。
この方法のもう 1 つのメリットは、先ほど説明した長期保存ストレージへの移行が、個々のパーティションごとに考慮されるようになるという点です。上記の sales データの例で言うと、頻繁に読み込みや編集の対象となるデータは過去 2~3 か月分です。従って、その他の過去 90 日間編集しなかったパーティションについては、ストレージ コストが自動的に削減されることになります。
なお、パーティション分割テーブルのメリットを活かすには、クエリを実行するときに、パーティション列を指定してテーブルを絞り込むようにしてください。
ワンポイント: パーティション分割テーブルの作成や更新を行うときに [パーティション フィルタを要求] を有効にすると、WHERE 句を使ったパーティション列の指定をユーザーに強制できます(指定しないと、エラーが返されるようになります)。
5. クラスタリングを使って、データをさらに縮小する。
テーブルを分割した後、さらにそのテーブルをクラスタリングできるようになりました。クラスタリングとは、最大 4 つの列に値に基づいてデータを分類、整理する仕組みで、クラスタリングで指定された列の値に基づいてデータが並べられ、ブロックに分けられます。これらの列の値で絞り込むようなクエリを実行すると、ブロック プルーニングと呼ばれるプロセスによって、該当する値が含まれるブロックだけが自動的に判別されてスキャンされます。
たとえば、セールス部門の幹部社員が、特定の営業部員の指標だけをダッシュボードで確認できるようにしたいとしましょう。この場合は、絞り込みの条件となる sales_rep 列の値を順番に並べて、クラスタリングしておくと便利です。以下の例では、1 つのパーティション(2019/09/01)中の、Bob と Tom が含まれる 2 つのブロックのみがスキャンされ、このパーティションのその他のブロックは除かれています。これにより、処理するバイト数をさらに減らして、クエリ処理のコストを削減できます。
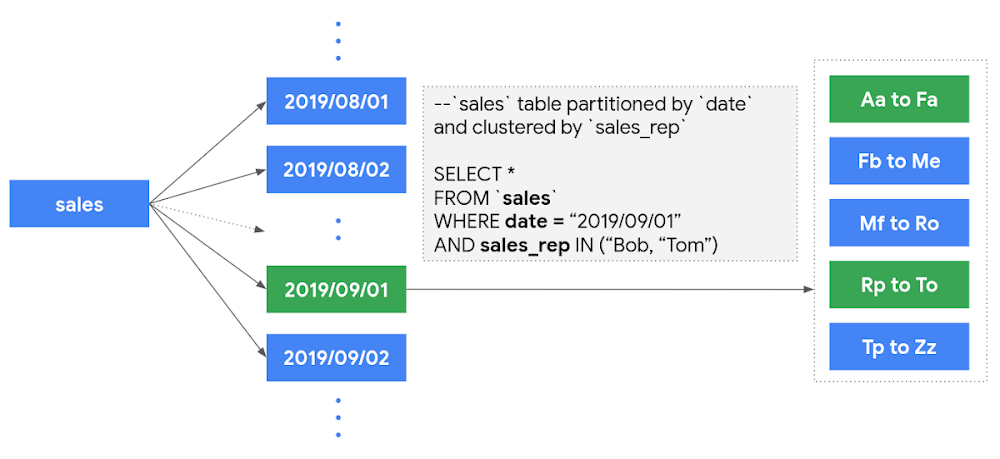
クラスタリングについて詳しくは、こちらをご覧ください。
ワンポイント: クラスタリングは、パーティションに対してのみ実行できます。テーブルをパーティションに分割するには、データの取り込み情報を使用できます。または、架空の日付やタイムスタンプの列を導入し、その列の値に基づいて分割することも可能です。
定額料金とオンデマンド料金の違いを理解する
BigQuery のクエリ料金が 1 か月あたり $10,000 を越える場合は、定額料金プランへの変更を検討しましょう。オンデマンド料金プランでは処理データ量に基づいて課金されるため、料金が変動しますが、定額料金プランの場合、処理データの量は無制限で、毎月一定料金が課金されます。定額料金プランの場合、契約時にクエリの演算能力に相当する BigQuery スロットを購入します。この記事の公開時点では、定額料金プランは 500 スロットからとなっています。購入するスロット数を判断するには、Stackdriver を使って前月のスロット使用量を可視化してみることをおすすめします。
注: 定額料金の演算能力を超えるクエリを実行した場合は、必要なスロットが使用可能になるまでの間、一定の比率で処理速度が落ちます。
定額料金にすれば、クエリの最適化について一切心配しないで済むように思えるかもしれませんが、実際には、パフォーマンスも考慮する必要があります。同じスロット数でも、クエリの実行速度が速いほど、一定の時間内で完了できるジョブ数が多くなります。つまり、それ自体が、コストの最適化になるというわけです。
購入するスロット数が少なすぎるとパフォーマンスが低下し、多すぎると演算能力がフル活用されず、コストが無駄になります。適切なスロット数を判断するには、まず、月額料金プランを開始してみましょう。このプランなら、30 日後にスロット数を減らしたり、キャンセルしたりすることが可能です。必要なスロット数の見当がついたら、年額プランに切り替えることでさらに節約できます。
ワンポイント: オンデマンド料金と定額料金を組み合わせることによって、GCP 組織全体でコストを大きく削減することもできます。
次のステップ
BigQuery を効率良く使用し、この最新のデータ ウェアハウスのメリットをフルに活用していただければ幸いです。ここで紹介した数々のテクニックの効果を実感するには、進捗の確認や成果の可視化が不可欠です。そこで、これらを実行に移す前に、前月の BigQuery の使用量レポートを簡単に作成して、現時点でのコストを把握しておきましょう。そのうえで、この先、数日あるいは数か月間かけて実行に移すテクニックの優先順位を検討されてはいかがでしょうか。データポータルのダッシュボードを使ってさまざまな指標への影響を分析するのもよいでしょう。
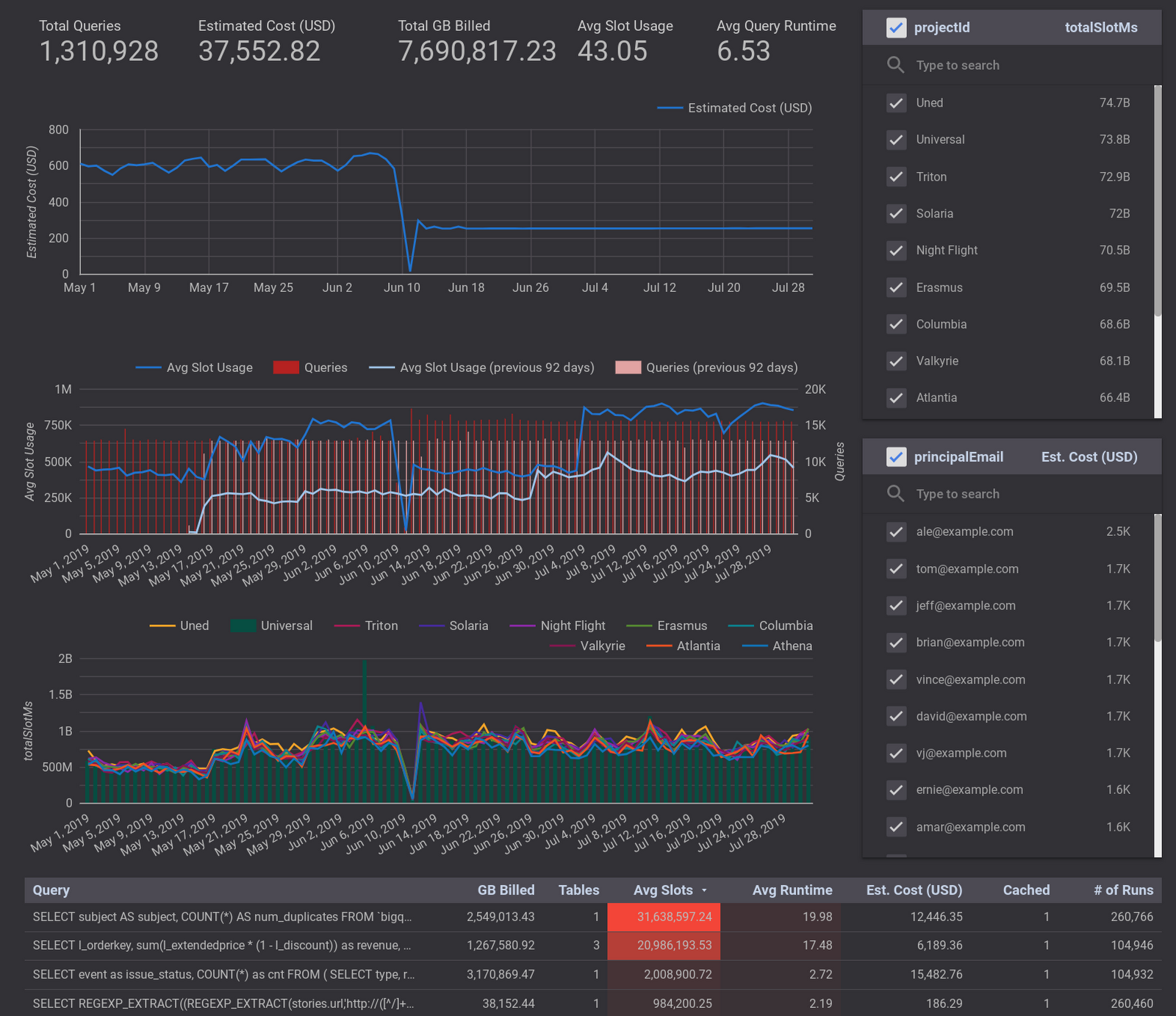
これらのコスト削減テクニックをいったん取り入れれば、BigQuery の料金が目に見えて下がっていくのを実感できるはずです(最初から実践していたのなら、話は別ですが)。いずれにしても、必ずや成果を得られるものと確信しております。
BigQuery の仕組みの詳細については、こちらをご覧ください。
執筆にあたり、プロダクト マネージャーの Tino Teresko、プロフェッショナル サービス担当の Justin Lerma からフィードバックをいただきました。この場を借りて、感謝を申し上げます。
- By Pathik Sharma, Professional Services, Technical Account Manager / James Fu, Professional Services, Staff Cloud Data Engineer



