BigQuery のクラスタリングで メンテナンスの手間を省いて クエリを高速化
Google Cloud Japan Team
※この投稿は米国時間 2019 年 8 月 24 日に Google Cloud blog に投稿されたものの抄訳です。
BigQuery は、Google が提供するサーバーレス データ ウェアハウスです。BigQuery を使用すると、エンタープライズ クラスのデータ ウェアハウスの設定や管理に伴う、手間のかかる複雑な作業の大半を自動化できます。必要なメンテナンス作業があれば、ユーザーに代わって自動で行うというのが BigQuery の哲学です。
BigQuery を最大限に活用するための重要なベスト プラクティスの 1 つが、テーブルのパーティショニングとクラスタリングです。本ブログでは、クラスタ化テーブルが BigQuery 内部でどのように機能しているかについて説明します。また、従来のデータ ウェアハウジングの問題を透過的に修正できる自動再クラスタリングについても解説します。これは、最高のパフォーマンスを得られるよう継続的にクラスタ化テーブルを最適化する、BigQuery 独自のバックグラウンド プロセスとして行われます。
パーティショニングとクラスタリングは、ワークロードのコストとパフォーマンス プロファイルを大幅に改善します。さらに、自動再クラスタリングは、クラスタ化テーブルに実際のニーズ(継続的なデータ挿入など)に対する弾力性を持たせるという、実用的なメリットをシームレスにもたらします。BigQuery で手間を省きましょう。
BigQuery のクラスタリングの仕組み
パーティション分割テーブル内の個々のパーティションは、それぞれが独立した 1 つのテーブルとして動作します。そのため、パーティション分割テーブルの各パーティションに対するクラスタリングの動作は、パーティショニングされていないテーブルのクラスタリングにも及びます。
クラスタリングは、INT64、BOOL、NUMERIC、STRING、DATE、GEOGRAPHY、TIMESTAMP などの繰り返されないプリミティブな最上位列でサポートされています。
通常、データハウス内でのクラスタリングの使用には 2 つの典型的なパターンがあります。
userIdやtransactionIdといった一意の値を大量に含む列をクラスタ化する。組み合わせて使われることの多い複数の列をクラスタ化する。複数の列でクラスタ化する場合、指定する列の順序が重要となります。データの並び順は、指定した列の順序によって決まります。クラスタリング列の接頭辞を自由に組み合わせてフィルタすることで、クラスタリングのメリットを得られます(
regionId、shopId、productIdの組み合わせ、またはregionIdとshopId、またはregionIdのみなど)。
BigQuery テーブルのデータは Capacitor 形式のブロック内に格納されます。これは、テーブル クラスタリングによって、これらのブロックの「弱い」並び順が定義されるということです。つまり、BigQuery は、クラスタキーと重複しない範囲の値がブロックに格納されるように、データを分散しようとします。BigQuery は、テーブルへの書き込み時に、各パーティション内のこうした新しいブロックの境界を自動的に決定します。
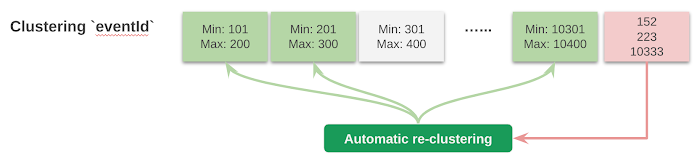
以下の図は、eventDate の日付列で分割され、eventId のクラスタリング列でクラスタ化されたテーブルのレイアウトを示しています。
このクエリでは、まずパーティショニング列にフィルタが適用され、「2019-08-02」のパーティションにあるブロックのみに絞り込まれます。次に、テーブルは eventID でクラスタ化されているため、eventID 列の値の範囲が重複しないようにブロックが整理されます。さらに、BigQuery のスケーラブルなメタデータ管理システムによって、各ブロック内の列の範囲情報が格納されます。
この情報を使用して、eventId の値が 201~300 と、10301~10400 の範囲のブロックのみにスキャン対象がさらに絞り込まれます。
クラスタリングで集約クエリのパフォーマンスを改善
クラスタリングは並び順を示すものであるため、クラスタリング列と同じ値を持つ行は、その近くまたは同じブロックに格納されます。これにより、クラスタリング列でグループ化した集約クエリの最適化が可能になります。集約を計算するために、BigQuery ではまず各ブロックから部分的な集約を計算します。次に、これらの部分的な集約をシャッフルおよびマージして、最終的な集約を計算します。通常はクラスタリング列と同じ値を持つ行が一緒にされているため、作成された部分的な集約のサイズはかなり小さくなり、シャッフルする必要のある中間データの量が減少します。これにより、集約クエリのパフォーマンスが向上します。
テーブル クラスタリングの管理
通常、BigQuery テーブルへのデータの書き込みは、読み込み、クエリ、コピーの各ジョブ、またはストリーミング API を使用して継続的に行われます。受け取るデータが増えるにつれ、テーブル内で現在アクティブなブロックの列の値の範囲と重複する範囲を持つブロックに、新たに挿入されたデータが書き込まれてしまう可能性があります。クラスタ化テーブルのパフォーマンス特性を維持するため、BigQuery ではバックグラウンドで自動再クラスタリングが行われ、テーブルの並べ替えプロパティが復元されます。パーティション分割テーブルでは、各パーティションの範囲内のデータに対してクラスタリングが維持されるということにご注意ください。
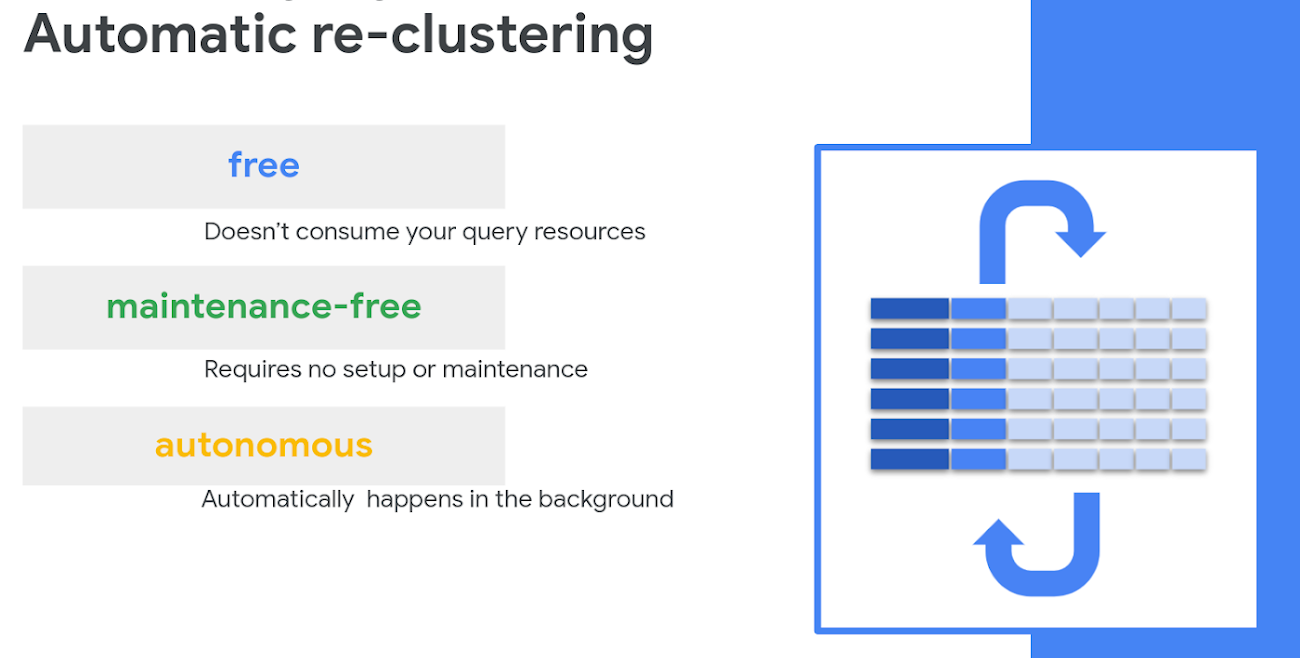
これまで、データ ウェアハウスにおける同様のプロセス(VACUUM、自動クラスタリングなど)では、ある程度の設定や管理が必要でした。また、ユーザーがそのプロセスの費用を負担する必要がありました(重要な分析のための時間をクラスタ化のために費やしていたため)。BigQuery の自動再クラスタリングには、他にはない以下の 2 つの特長があります。
このバックグラウンド処理でユーザーのリソースが消費されることはなく、無料でユーザーに提供されます。
自動再クラスタリングは、ユーザーの操作を必要とせず、自動的かつ透過的に行われます。
自動再クラスタリングの仕組み
自動再クラスタリングは LSM tree と似た仕組みで機能します。定常状態では、パーティション内のほとんどのデータは完全に並べ替えられたブロック(これをベースラインといいます)内にあります。パーティションに新しいデータが挿入されると、BigQuery はその新しいデータをローカルで並べ替えるか、書き込むのに十分な量のデータになるまで並べ替えを保留します。データが十分な量になると、「差分」という、ローカルで並べ替えられたブロックが生成されます。現在のベースラインのサイズと比較して十分なサイズのデータが差分に蓄積されると、BigQuery はベースラインと差分をマージして新しいベースラインを生成します。ベースラインの再生成は I/O や CPU に高い負荷のかかる作業ですが、ユーザーがそれを意識することはありません。
BigQuery は、新しいベースラインのサイズが 500 GB になるまで、差分とベースラインのマージを試みます。その後は、以前のベースラインの並びを変えることなく、新たに作成された差分を新しいベースラインにマージします。この手法により、BigQuery に新たなデータを挿入するたびにベースラインを書き換える時間とリソースを節約することができます。
BigQuery の使用に関する詳細
自動再クラスタリングは完全に無料かつ自動でご利用いただけます。BigQuery へのデータ取り込みの料金もかからないため、クエリ処理容量をまったく消費しなくて済みます。お客様からの情報によると、この 2 つのワークロードを合わせると、ビジネスに不可欠な分析やデータ処理に使うことができる処理リソースのうち約 30% を消費してしまうこともあるそうです。BigQuery のアプローチなら、こうした効率性をより弾力性のあるデータ ウェアハウスへと直接変換し、クエリを高速化してコストや時間を節約できます。
クラスタリングがコストとパフォーマンスに与える影響についての実例は、Felipe Hoffa によるクラスタリングに関するブログ投稿をご覧ください。BigQuery は、1 か月あたりのデータ処理は 1 TB、ストレージは 10 GB までご利用いただける永久的な無料枠でいつでもお試しいただけます。
- By Pavan Edara, Senior Staff Software Engineer, Google BigQuery
