金融サービスを対象とする、Google Cloud でのデータ ガバナンスの構成要素
Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
データ ガバナンスには、人員、プロセス、テクノロジーが関わります。これらの要素によって組織は次のような項目を通じて検証し、管理できるようになります。
データとパイプラインのライフサイクル管理、マスターデータ管理を含むデータ管理
監査とコンプライアンスのほか、データアクセス管理、データ マスキング、暗号化におよぶデータ保護
データカタログ、データ品質保証、データ系列登録、管理を含むデータの検出可能性
データユーザーの特定、ポリシー管理の要件を含むデータ アカウンタビリティ
望ましい形に企業文化を変革し、運用の効果と効率を高めるプロセスを実現するために従業員への投資を優先することは、企業にとって有益である一方、ユーザーがデータを操作して組織がデータ イニシアチブを真に管理できるようにする重要なイネーブラーはテクノロジーの柱にほかなりません。
金融サービス機関はセキュリティ、規制遵守、一般的な堅牢性に関して、特に厳しいデータ ガバナンス要件に直面しています。人員が調整され、プロセスが定義されると、テクノロジーの課題が明らかになります。ここでは、既存のガバナンス プロセスを補完できる柔軟性があり、データアセット全体での統一性によってデータ管理を簡素化できるソリューションが必要になります。
次のセクションでは、まず金融サービスでのデータ ガバナンスの実装に関する標準的な要件を確認し、それらの要件が Google Cloud サービス、オープンソース リソース、サードパーティのサービスにどう当てはまるのかについて見ていきます。世界クラスの金融サービス機関でデータ ガバナンス ソリューションを実装した経験に基づいて、データ ライフサイクル全体をサポートできるアーキテクチャを紹介します。
データ管理
まずデータ管理の側面を確認し、テクノロジーの観点から Google Cloud の関連するサービスおよび機能とともに、最も一般的な要件のいくつかをまとめました。
データ管理の要件 | サービスと機能 | |
データとパイプラインのライフサイクル管理 | バッチ取り込み: データ パイプライン管理、スケジュール設定、データ パイプライン処理の記録 ストリーミング パイプライン: メタデータ データ ライフサイクル管理 状態と統計メタデータの両方が含まれるオペレーショナル メタデータ | Data Fusion パイプライン ライフサイクル管理、オーケストレーション、調整、メタデータ管理 Dataplex インテリジェント自動化データ ライフサイクル管理 |
コンプライアンス | 規制要件の遵守を容易にする | 簡単に拡張可能で、IAM、CMEK、BQ 列レベルアクセス制御、BQ テーブル ACL、データ マスキング、承認済みビュー、DLP PII データを使用したセキュリティ管理の実装を通じて CCPA、HIPAA, PCI、SOX、GDPR の遵守を容易に DCAM データと分析評価フレームワーク CDMC のベスト プラクティスの評価と認定 |
マスターデータ管理 | 疑わしい処理ルールの重複 ソリューションと部門の範囲 | KG エンティティ解決 / 調整および金融犯罪記録照合 MDM + ML |
サイトの信頼性 | データ パイプラインの SLA 保存データの SLA | データ パイプラインに適用される SLA データを管理するサービスに適用される SLA |
データ パイプラインの登録、作成、スケジュール設定は、組織が繰り返し直面する課題です。同様に、データ ライフサイクル管理は総合的なデータ ガバナンス戦略の要になります。
Google Cloud は、統合済みでオーケストレーションとカタログ化を簡単に行える、それぞれのニーズに合った複数のデータ処理エンジンとデータ ストレージ オプションを提供します。
データ保護
金融機関は、定義済みの社内プロセスに対応し、規制要件の遵守に役立つ世界水準のデータ保護サービスと機能を求めています。
データ保護の要件 | サービスと機能 | |
データのアクセス管理 | アクセス ポリシーの定義 マルチクラウド承認ワークフローの統合* | アクセス承認
サードパーティのマルチクラウド承認ワークフロー - Collibra* |
データの監査とコンプライアンス | オペレーショナル メタデータ ログ キャプチャ プロセス障害アラートと根本原因の特定 | |
セキュリティの状況 | データの脆弱性の特定 セキュリティ ヘルスチェック | |
データのマスキングと暗号化 | ストレージレベルの暗号化メタデータ アプリケーションレベルの暗号化メタデータ 個人情報(PII)データの識別とタグ付け |
アクセス管理はデータとパイプラインの監査とともに一般的な要件で、すべてのデータアセット全体で管理されるべきです。こうしたセキュリティ要件は通常、セキュリティ ヘルスチェックと自動修復プロセスでサポートされます。
データ保護の場合は特に、データのマスキング、データ暗号化、個人情報(PII)データ管理などが、処理パイプラインに組み込まれた機能として利用でき、ポリシーとして定義、管理されるべきでしょう。
データの検出可能性
データを見れば、組織が行っていることや、それがユーザー、競合他社、規制機関にどのように関連しているかを確認できます。そのため、データの検出可能性機能は金融機関にとって重要です。
データの検出可能性の要件 | サービスと機能 | |
データのカタログ化 | データ カタログ ストレージ メタデータタグのフィールドへの関連付け データ分類メタデータ登録 スキーマ バージョン管理 データ読み込み前のスキーマの定義 | Dataplex 論理的集約体(レイク、 ゾーン、アセット) Collibra アセット バージョン管理 |
データ品質 | 取り込み時のデータ品質ルールの定義(各列の正規表現の確認など) 問題解決ライフサイクル管理 | CloudDQ 宣言型データ品質確認(CLI)* |
データ系列 | ストレージと属性レベルのデータ系列 マルチクラウド / オンプレミスの系列 |
|
データ分類 | データ検出とデータ分類メタデータ登録 | DLP 検出と分類 |
データカタログはデータ ガバナンス戦略の大部分が構築される基盤です。データを検出できるようにするには自動分類オプション、データ系列登録、管理機能が必要になります。Dataplex はフルマネージド型のデータ検出、メタデータ管理サービスです。複数のストレージ ターゲットに分散したすべてのデータアセットで統合的にデータを検出できます。このプロダクトでは、ビジネス メタデータにアノテーションを付けて、Google Cloud 内で必要なデータ ガバナンス基盤を使用することができます。また、マルチクラウドやエンタープライズ レベルのカタログによって、外部メタデータと後で統合可能なメタデータも提供されます。Collibra Catalog は Google Cloud で利用できるエンタープライズ データ カタログの一つです。ガバナンスのビジネス層と論理層を含む運用モデル、フェデレーション、マルチクラウドとオンプレミス環境でのカタログ化などのエンタープライズ機能によって、Dataplex を補完します。
データ品質の保証と自動化は、データの検出可能性の 2 番目の基盤になります。これに役立つ Dataprep はプロセスの評価、修正、検証を行うツールで、宣言型かつスケーラブルなデータ品質検証コマンドライン インターフェースの Cloud Data Quality Engine など、カスタマイズされたデータ品質ライブラリと一緒に使用できます。Collibra DQ はもう一つのデータ品質評価ツールで、機械学習を使ってデータ品質に関する問題の特定やデータ品質ルールの提案を行うほか、検出可能性の向上を図ります。
データのアカウンタビリティ
データのオーナー、管理者、スチュワード、ユーザーを特定し、関連するメタデータを効果的に管理することで、組織は信頼できる安全な方法でデータを使用できるようになります。以下は、データ アカウンタビリティに関する最も一般的な要件と、それらを満たすために使用できるツールとサービスです。
データ アカウンタビリティの要件 | サービスと機能 | |
データユーザーの特定 | データオーナーとデータセットがリンクされた登録 データ スチュワードとデータセットがリンクされた登録 ユーザーロールに基づくデータ使用量のロギング | |
ポリシー管理 | ドメインに基づくポリシー管理 列レベルのポリシー管理 | BigQuery の列レベルのセキュリティ |
ドメインに基づくアカウンタビリティ | 管理されるデータの共有 |
データを取り巻く環境の全体で、一元化された Identity and Access Management ソリューションを備えることは、データ セキュリティ戦略を定義するうえでの重要な促進剤となります。ここでは主な機能として、ユーザー識別、ロールベースおよびドメインベースのアクセス ポリシー管理、ポリシー管理型データアクセス認証ワークフローが必要でしょう。
データ ガバナンスの業界基準を満たす構成要素
Google ではこうした機能を踏まえ、マルチクラウドの一元化されたガバナンス環境を実現するリファレンス アーキテクチャを提供しています。これにより、金融サービス機関はそれぞれの要件を満たせるようになります。ここではデータ ガバナンスのテクノロジーの柱に重点を置いていますが、人員の足並みが揃っておりプロセスもしっかりと定義されていることが重要です。
次のアーキテクチャは、上記の要件を完全に網羅することは意図していないものの、テクノロジーの柱については、このブログの執筆時点で可能な限り業界基準を満たすための、データ ガバナンス実装の核となる要素で構成されています。
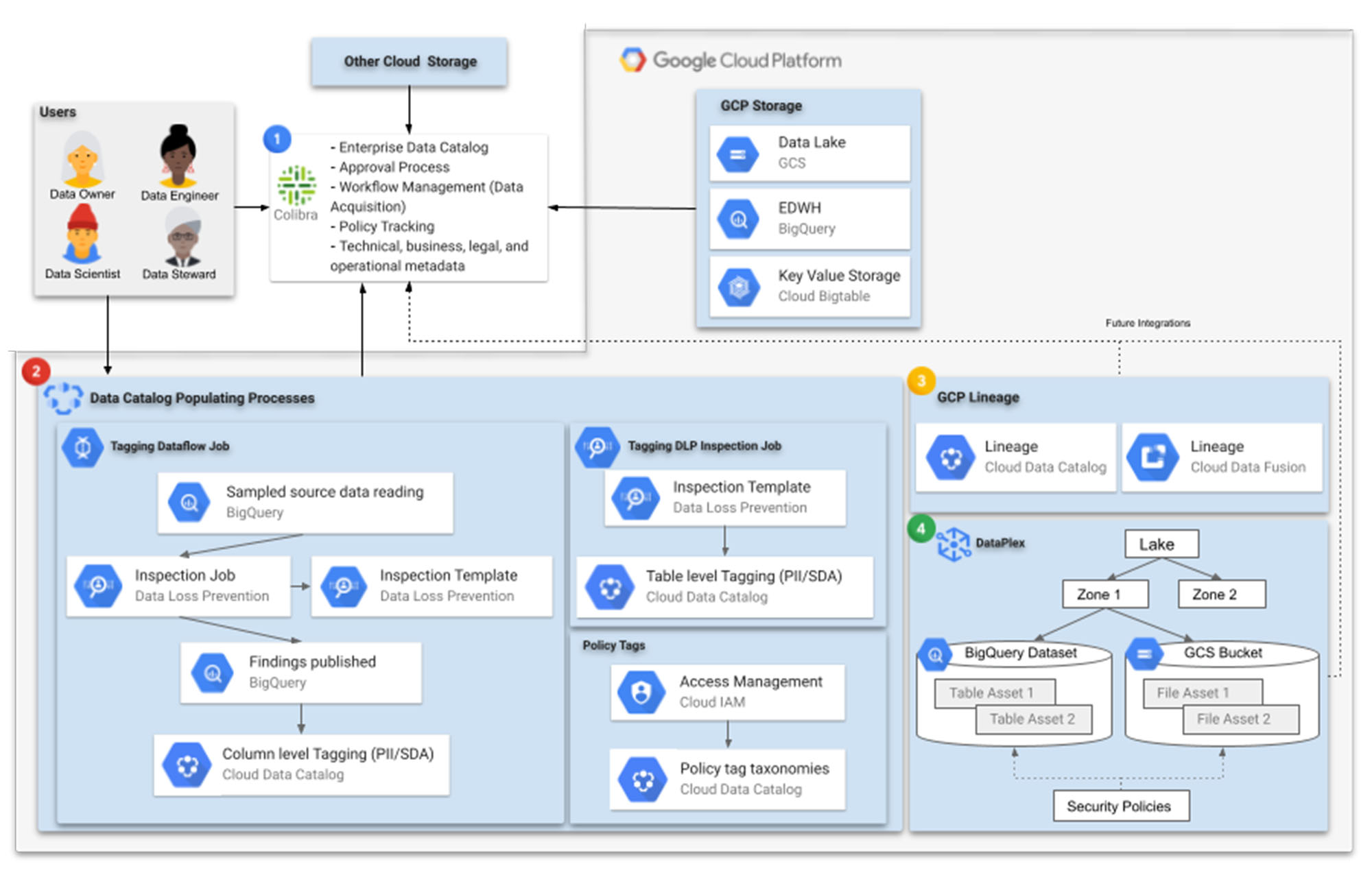
1. データのカタログ化はあらゆるデータ ガバナンス テクノロジーの取り組みの心臓部になります。金融機関は多くの場合、複数のクラウド プロバイダとオンプレミスに存在するストレージ システムに対応する必要があります。エンタープライズ レベルのカタログである「総合カタログ」は、組織内のすべてのデータアセットを一元化して発見できるようにするもので、どこにあるデータも最大限に活用できるようになります。
これについては、Google Data Catalog がオープンソースのコネクタを通じて Google Cloud 以外のデータアセットをサポートしているものの、複数のストレージ システムやメタデータ管理の追加レイヤが提供されるサードパーティのカタログ化ソリューション(Collibra など)が適している場合もあります。たとえば、これによってデータアセットがストレージで利用可能になる前に事前登録を行い、実際のテーブルやファイルセットが作成されたら、スキーマの進化の追跡を含めてそれらのテーブルやファイルセットを統合できるようになります。
2. Google Cloud の観点から検出、カタログ化、保護されるデータは、Cloud Storage のデータレイクまたはランディング ゾーン、BigQuery のエンタープライズ データ ウェアハウス、BigTable のような高スループットで低レイテンシのデータストア、さらには Spanner、CloudSQL、Firestore でサポートされるリレーショナル データベースや NoSQL データベースなどに格納されています。
タグなどの Cloud Data Catalog メタデータの収集は、複数の段階で実施されます。金融機関は信頼できる完全なメタデータを獲得するために、可能な限り標準化と自動化を進める必要があります。Data Catalog へのラベルの入力には、Cloud Data Loss Prevention(DLP)APIが重要な役割を果たします。ここでは、DLP 検査テンプレートと検査ジョブを使って、データへのタグ付けの標準化、データのサンプリングと検出、最後にテーブルとファイルセットへのタグ付けが行われます。
処理するデータの機密性を踏まえると、金融機関にとってその他の大きな懸念事項はセキュリティとアクセス制御であり、通常は複数の暗号化とマスキング レイヤがデータに適用されます。こうしたシナリオでは、追加するラベルを判断するためのデータのサンプリングと読み込みは少々複雑なプロセスとなり、復号が必要になります。
BigQuery で列レベルのポリシータグを適用する場合などには、Cloud Data Catalog を使ってタグ付けジョブにアクセスできる中間ストレージに、DLP 検査ジョブの結果を公開する必要があります。このような場合は、必要な復号とタグ付けを Dataflow ジョブで処理できます。こちらから詳細な手順を示したコミュニティ チュートリアルをご覧ください。
膨大なデータセットにある適切なデータに適切な人員がアクセスできるようにするのは、困難な場合があります。IAM アクセス管理とポリシー分類タグは、このニーズに対応します。
Google Cloud の Dataplex サービス(後述)では、動的スキーマ検出を使ってデータの検出と分類を自動化できます。メタデータは Data Catalog で最終的に使用される前に、Dataproc Metastore や BigQuery に自動的に登録されます。
3. 経時的なデータの発生、移動、変換について理解するには、データ系列システムが不可欠です。このシステムにより、系列の記録を保存してアクセスできるようになります。また、データ パイプラインのエラーを特定する信頼性の高いトレーサビリティも確保されます。金融機関の大規模なデータ ウェアハウス環境では、自動化されたデータ系列記録システムによりユーザーのデータ ガバナンスを簡素化できます。
金融機関はコンプライアンスと監査可能性の基準を満たし、アクセス ポリシーを適用して、品質の低いデータやパイプライン障害の根本原因分析を実施する必要があります。その際、Cloud Data Catalog Lineage と Cloud Data Fusion Lineage のトレーサビリティ機能が役に立ちます。
4. Dataplex はデータ ガバナンスに関する Google Cloud のビジョンの基礎となる部分です。Dataplex はデータ管理を結合、自動化するインテリジェントなデータ ファブリックで、分析処理のジョブを簡単かつグラフィカルに管理できます。このプロダクトは、金融機関がデータとパイプラインのライフサイクル管理に関する複雑な要件を満たすのに役立ちます。
Dataplex では、レイク、ゾーン、アセットと呼ばれる論理的な集約体にデータを整理できます。アセットは、Cloud Storage のファイルや BigQuery のテーブルに直接関連付けられ、論理的にゾーンにグループ化されます。ゾーンには Raw、Refined、Analytics などの一般的なデータレイク実装ゾーンや、セールスや金融などビジネス ドメインに基づくゾーンがあります。ユーザーはそうした論理的な構成の上に、データアセット全体のセキュリティ ポリシー(詳細なアクセス制御など)を定義できます。この方法により、データオーナーは権限を付与できる一方で、データ マネージャーは付与された権限をモニタリング、監査できます。
クラウドでデータ ガバナンス戦略を構築
金融データ ガバナンスを実装し、データの信頼性を高めて規制要件を満たすには、プロセスを構築して人員の足並みを揃えるための、強固で柔軟性の高いテクノロジーの柱が不可欠です。Google Cloud を使用すると、総合的なデータ ガバナンス戦略を作成すると同時に、特定の業界ニーズを満たすサードパーティ機能も追加できます。
詳しくは、以下をご参照ください。
Google 社員 Jessi Ashdown と Uri Gilad のポッドキャストを視聴する
データ ガバナンス戦略において Dataplex と Data Catalog が重要な要素になりうる理由を確認する
ホワイトペーパーでクラウドでのデータ ガバナンスに関する原則とベスト プラクティスを確認する
- データ分析担当戦略的クラウド エンジニア Oscar Pulido


