Data governance building blocks on Google Cloud for financial services
Daryus Medora
Strategic Cloud Engineer, Data & Analytics
Oscar Pulido
Strategic Cloud Engineer, Data & Analytics
Data governance includes people, processes, and technology. Together, these principles enable organizations to validate and manage across dimensions such as:
Data management, including data and pipelines lifecycle management and master data management.
Data protection, spanning data access management, data masking and encryption, along with audit and compliance.
Data discoverability, including data cataloging, data quality assurance, and data lineage registration and administration.
Data accountability, with data user identification and policies management requirements.
While prioritizing investment in their people to achieve the desired cultural transformation and processes to increase operational effectiveness and efficiency will help enterprises, the technology pillar is the critical enabler for people to interact with data and for organizations to truly govern their data initiatives.
Financial services organizations are faced with particularly stringent data governance requirements regarding security, regulatory compliance, and general robustness. Once people are aligned and processes are defined, the challenge for technology comes to the picture: solutions should be flexible enough to complement existing governance processes and be cohesive across data assets to help make data management simpler.
In the following sections, starting with standard requirements for data governance implementations in financial services, we will cover how these correspond to Google Cloud services, open-source resources, and third-party offerings. We will share an architecture capable of supporting the entire data lifecycle, based on our experience implementing data governance solutions with world-class financial services organizations.
Data management
Looking first at the data management dimension, we have compiled some of the most common requirements, along with the relevant Google Cloud services and capabilities from the technology perspective.
Data Management Requirements | Services & Capabilities | |
Data and pipelines lifecycle management | Batch ingestions: Data pipelines management, scheduling, and data pipelines processing logging Streaming Pipelines: Metadata Data lifecycle management Operational metadata including both state and statistical metadata | A comprehensive end-to-end data platform Data Fusion pipeline lifecycle management, orchestration, coordination, and metadata management Dataplex Intelligent automation data lifecycle management |
Compliance | Facilitate regulatory compliance requirements | Easily expandable to help comply with CCPA, HIPAA, PCI, SOX, and GDPR, through security controls implementation using IAM, CMEKs, BQ column-level access control, BQ Table ACL, Data Masking, Authorized views, DLP PII data Identification, and Policy tags. DCAM data and analytics assessment framework CDMC best practice assessment and certification |
Master Data Management | Duplicate Suspect Processing rules Solution and department scope | KG Entity Resolution/reconciliation and Financial Crime Record matching MDM + ML |
Site Reliability | Data Pipelines SLA Data at Rest SLA | SLAs applied to data pipeline SLAs applied to services managing data |
Registering, creating, and scheduling data pipelines is a recurring challenge that organizations face. Similarly, data lifecycle management is a key part of a comprehensive data governance strategy.
This is where Google Cloud can help, offering multiple data processing engines and data storage options tailored for each need, but that are integrated and make orchestration and cataloging easy.
Data protection
Financial organizations demand world-class data protection services and capabilities to support their defined internal processes and help meet regulatory compliance requirements.
Data Protection Requirements | Services & Capabilities | |
Data Access Management | Definition of access policies Multi-cloud approval workflow integration* | Access Approvals
Hierarchical resources & policies
Multi-cloud Approval workflow by 3rd Party - Collibra* |
Data Audit & Compliance | Operational metadata logs capture Failing process alerting and root cause identification | |
Security Health | Data vulnerabilities identification Security health checks | |
Data Masking and Encryption | Storage-level encryption metadata Application-level encryption metadata PII data identification and tagging | Encryption at rest, Encryption in transit, KMS |
Access management, along with data and pipeline audit, is a common requirement that should be managed across the board for all data assets. These security requirements are usually supported by security health checks and automatic remediation processes.
Specifically on data protection, capabilities like data masking, data encryption, or PII data management should be available as an integral part for processing pipelines, and be defined and managed as policies.
Data discoverability
Data describes what an organization does, how it relates to its users, competitors, and regulatory institutions. This is why data discoverability capabilities are crucial for financial organizations.
Data Discoverability Requirements | Services & Capabilities | |
Data Cataloging | Data catalog storage Metadata tags association with fields Data classification metadata registration Schema Versions control Schema definition before data loading | Dataplex logical aggregations (Lakes, Zones and Assets) Collibra Asset version control Collibra Asset Type creation and Asset pre-registration |
Data Quality | On ingestion data quality rules definition (like regex validations for each column) Issues remediation lifecycle management | CloudDQ declarative Data Quality validation (CLI)* |
Data Lineage | Storage and Attribute level Data Lineage Multi-cloud/on-premises lineage | Cloud Data Fusion Data Lineage
|
Data Classification | Data Discovery and Data Classification metadata registration | DLP Discovery and classification
|
A data catalog is the foundation on which a large part of a data governance strategy is built. You need automatic classification options and data lineage registration and administration capabilities to make data discoverable. Dataplex is a fully managed data discovery and metadata management service that offers unified data discovery of all data assets, spread across multiple storage targets. Dataplex empowers users to annotate business metadata, providing necessary data governance foundation within Google Cloud, and providing metadata that can be integrated later with external metadata by a multi-cloud or enterprise-level catalog. The Collibra Catalog is an example of an enterprise data catalog on Google Cloud that complements Dataplex by providing enterprise functionality such as an operating model that includes the business and logical layer of governance, federation and the ability to catalog across multi-cloud and on-premises environments.
Data quality assurance and automation is the second foundation of data discoverability. To help with that effort Dataprep is another tool for assessing, remediating, and validating processes, and can be used in conjunction with customized data quality libraries like Cloud Data Quality Engine, a declarative and scalable data quality validation command-line Interface. Collibra DQ is another data quality assurance tool, and uses machine learning to identify data quality issues, recommend data quality rules and allow for enhanced discoverability.
Data accountability
Identifying data owners, controllers, stewards, or users, and effectively managing the related metadata, provides organizations with a way to ensure trusted and secure use of the data. Here we have the most commonly identified data accountability requirements and some tools and services you can use to meet them.
Data Accountability Requirements | Services & Capabilities | |
Data User Identification | Data owner and dataset linked registration Data steward and dataset linked registration Users role based data usage logging | |
Policies Management | Domain based policies management Column level policies management | BigQuery Column Level Security |
Domain Based Accountability | Governed data sharing |
Having a centralized identity and access management solution across the data landscape is a key accelerator to defining a data security strategy. Core capabilities should include user identification, role- and domain-based access policy management, and a policy-managed data access authorization workflows.
Data governance building blocks to meet industry standards
Given these capabilities, we provide a reference architecture for a multi-cloud and centralized governance environment that enables a financial services organization to meet its requirements. While here we focus on the technology pillar of data governance, it is essential that people and processes are also aligned and well-defined.
The following architecture does not intend to cover each and every requirement presented above, but provides core building blocks for data governance implementation to meet industry standards as far as the technology pillar is concerned at the time of writing this blog.
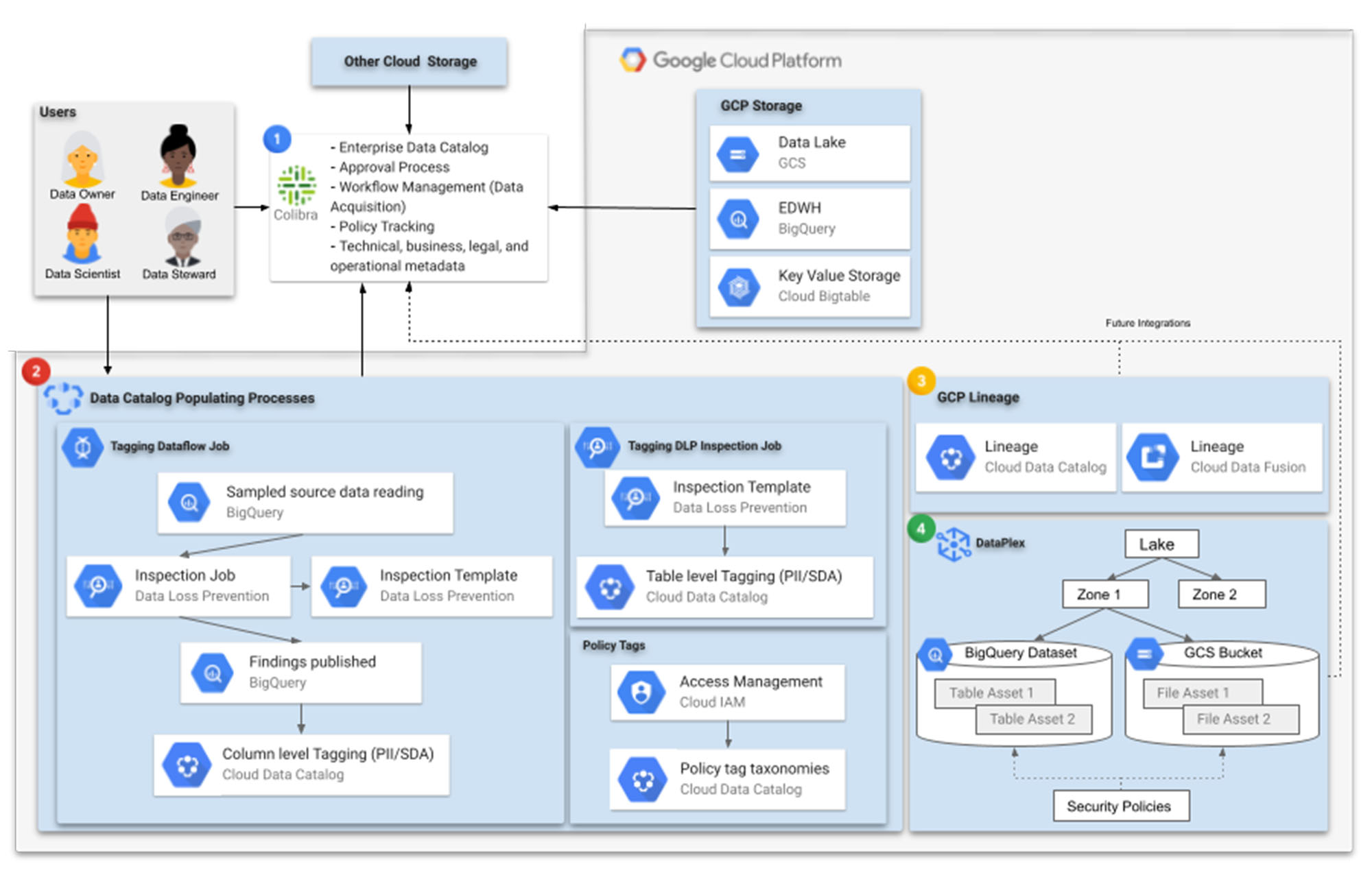
1. Data cataloging is a central piece in any data governance technology journey. Finance enterprises often need to deal with several storage systems residing in multiple cloud providers and also on-premises. As such, an enterprise-level catalog, a “catalog of catalogs”, that centralizes and makes discoverable all the data assets in the organization, is a helpful capability to helping the business get the most from its data, wherever it sits.
Even when Google Data Catalog supports non-Google Cloud data assets through open-source connectors, a third-party cataloging solution (such as Collibra) may be well-suited to help with this, providing connection capabilities to several storage systems and additional layers of metadata administration. For example, this could enable having the ability to pre-register data assets even before they are available in storage, and to integrate those once actual tables or filesets are created, including schema evolution tracking.
2. From a Google cloud perspective, data to be discovered, cataloged, or protected can reside in a data lake or a landing zone in Cloud Storage, an enterprise data warehouse in BigQuery, a high-throughput low-latency datastore like BigTable, or even in relational or NoSQL databases supported by Spanner, CloudSQL or Firestore, for example.
Gathering Cloud Data Catalog metadata such as tags is a multi-step process. Financial enterprises should standardize and automate as much as possible to have reliable and complete metadata. To populate the Data Catalog with labels, the Cloud Data Loss Prevention API (DLP) is a key player. DLP inspection templates and inspection jobs can be used to standardize tagging, sampling, and discovering data, and finally to tag tables and filesets.
Security and access control is another big concern for finance organizations given the sensitivity of the data they handle. Several encryption and masking layers are usually applied to the data. In these scenarios, sampling and reading data to determine which labels to add is a slightly more complex process, requiring decryption along the way.
In order to be able to do things like apply column-level policy tags to BigQuery, the DLP inspection job findings need to be published to an intermediate storage location accessible to a tagging job using Cloud Data Catalog. In these contexts, a Dataflow job could help handle the required decryption and tagging. There is a step by step community tutorial on that here.
Ensuring the right people accessing the right data across numerous datasets can be challenging. Policy Taxonomy tags, in conjunction with IAM access management, covers that need.
Google Cloud’s Dataplex service (discussed more below) will also help to automate data discovery and classification using dynamic schema detection, such that metadata can be automatically registered in a Dataproc Metastore or in BigQuery before finally being used by Data Catalog.
3. To understand the origin, movement, and transformation of data over time, data lineage systems are fundamental. These allow users to store and access lineage records and provide reliable traceability to identify data pipeline errors. Given the large volume of data in a finance enterprise data warehouse environment, an automated data lineage recording system can simplify data governance for users.
Finance organizations have to meet compliance and auditability standards, enforce access policies, and perform root cause analysis on poor data or failing pipelines. To do that, Cloud Data Catalog Lineage and Cloud Data Fusion Lineage provide traceability capabilities that can help.
4. Dataplex is a fundamental part of Google Cloud’s vision for data governance. Dataplex is an intelligent data fabric that unifies and automates data management and allows easy and graphical control for analytics processing jobs. This helps financial organizations meet the complex requirements for data and pipeline lifecycle management.
Dataplex also provides a way to organize data into logical aggregations called lakes, zones and assets. Assets are directly related to Cloud Storage files or tables in BigQuery. Those assets are logically grouped into zones. Zones can be typical data lake implementation zones like raw zones, refined zones, or analytics zones, or can be based on business domains like sales or finance. On top of that logical organization, users can define security policies across your data assets, including granular access control. This way, data owners can grant permissions while data managers can monitor and audit the access granted.
Build a data governance strategy in the cloud
For financial data governance implementations to have trust in their data, and meet regulatory compliance requirements, they must have a solid and flexible technology pillar from which to build processes and align people. Google Cloud can help build that comprehensive data governance strategy, while allowing you to add third-party capabilities to meet specific industry needs.
To learn more:
Listen to this podcast with Googlers Jessi Ashdown and Uri Gilad
See how Dataplex and Data catalog can become key pieces in your data governance strategy
- Review the principles and best practices for data governance in the cloud in this white paper.

