Architecting a data lineage system for BigQuery
Anant Damle
Solutions Architect
Democratization of data within an organization is essential to help users derive innovative insights for growth. In a big data environment, traceability of where the data in the data warehouse originated and how it flows through a business is critical. This traceability information is called data lineage. Being able to track, manage, and view data lineage helps you to simplify tracking data errors, forensics, and data dependency identification.
In addition, data lineage has become essential for securing business data. An organization’s data governance practices require tracking all movement of sensitive data, including personally identifiable information (PII). Of key concern is ensuring that metadata stays within the customer’s cloud organization or project.
Data Catalog provides a rich interface to attach business metadata to the swathes of data scattered across Google Cloud in BigQuery, Cloud Storage, Pub/Sub or outside Google Cloud in your on-premises data centers or databases. Data Catalog enables you to organize operational/business metadata for data assets using structured tags. Data Catalog structured tags are user-specified and you can use them to organize complex business and operational metadata, such as entity schema, as well as data lineage.
Common data lineage user journeys
Data lineage can be useful in a variety of user journeys that require a number of related but different capabilities. Different user journeys require lineage information at different granularities like relationships between data assets such as tables or datasets, while other user journeys require data lineage at column level for each table. Another category of user journeys trace data from specific rows in a table and is often referred to as row-level lineage.
Here, we’ll describe our proposed architecture, which focuses on the most commonly used (column-level) granularity for automated data lineage and can be used for the following user journeys:
Impact/dependency analysis
Schema modification of existing data assets, like deprecation and replacement of old data assets, is commonplace in enterprises. Data lineage helps you flag the breaking changes and identify specific tables or BI dashboards that will be impacted by the planned changes.
Data leakage/exfiltration
In a self-service analytics environment, accidental data exfiltration is high risk and can cause a loss of face for the enterprise. Data lineage helps in identifying unexpected data movement to ensure that data egress is done only to the approved projects/locations where it is accessible only by approved people.
Debugging data correctness/quality
Data quality is often compromised by missing or incorrect raw data as well as incorrect data transformations in the data pipelines. Data lineage enables you to traverse the lineage graph back, troubleshoot the data transformations, and trace the data issues all the way to raw data.
Validating data pipelines
Compliance requirements need you to ensure that all approved data assets are sourcing data exclusively from authorized data sources and the data pipelines are not erroneously using, for instance, a table that was created by an analyst for their own use, or a table that still has PII data. Data lineage empowers you to validate and certify data pipelines’ adherence to governance requirements.
Introspection for data scientist
Most data scientists require a close examination of the data lineage graph to really understand the usability of data for their intended purpose. By traversing the data lineage graph and examining the data transformations, you get critical insights into how the data asset was built and how it can be used for building ML models or for generating business insights.
Lineage extraction system
A passive data lineage system is suitable for SQL data warehouses like BigQuery. The lineage extraction process starts with identifying source entities used to generate the target entity through the SQL query. Parsing a query requires the schema information of the source entities of the query from the Schema Provider. The Grammar Provider is then used to identify the relation between output columns to the source columns and the list of functions/transforms applied for each output column. Here’s a look at the procedure to derive lineage:
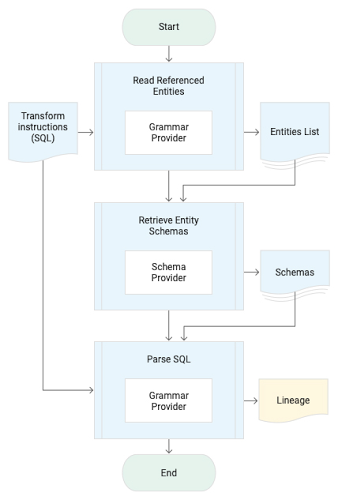
A tuple of source, target, and transform information based lineage data model is used to record the extracted lineage.
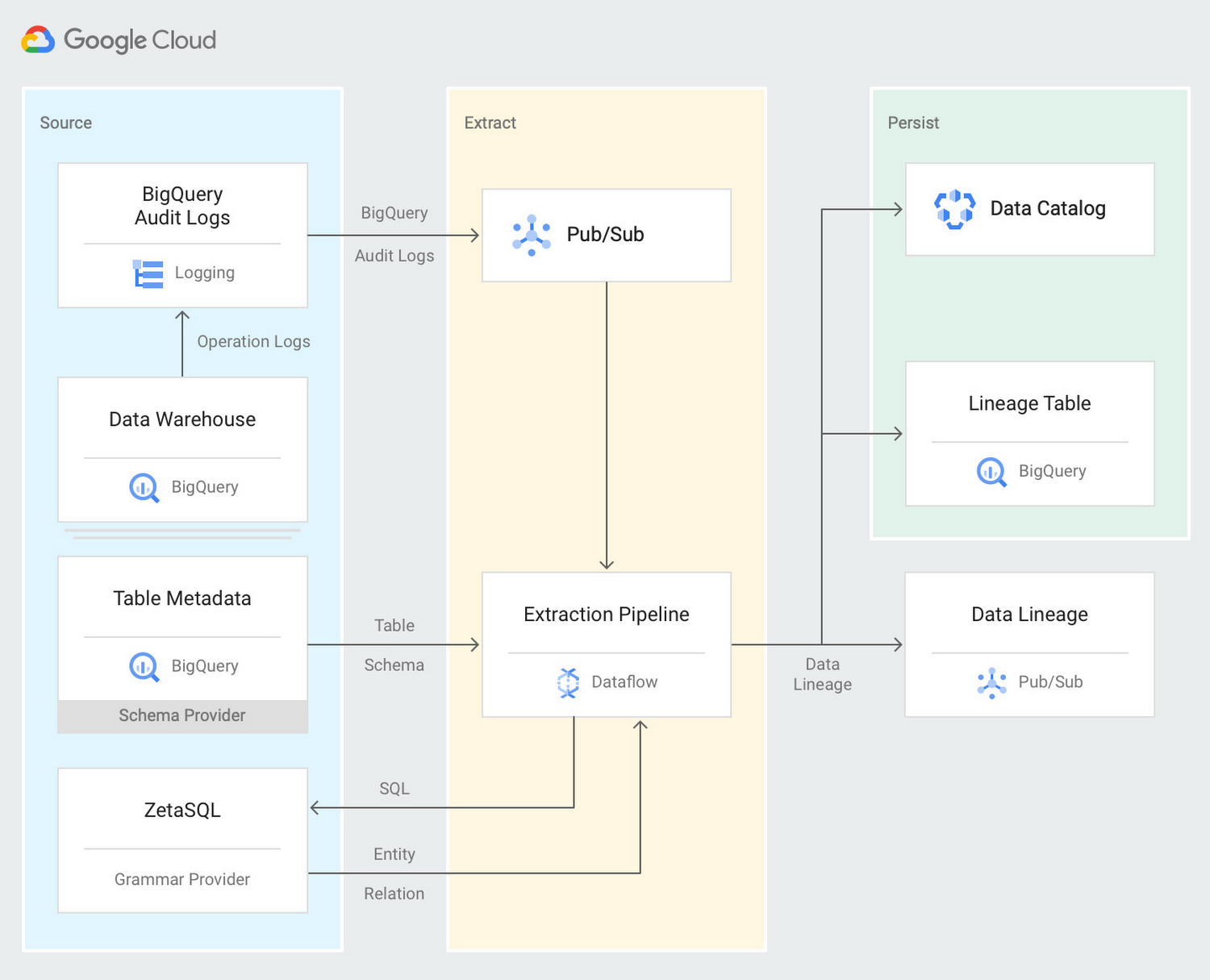
A cloud-native lineage solution for your BigQuery serverless data warehouse would use the BigQuery audit logs in real time from Pub/Sub. An extraction Dataflow pipeline parses the query’s SQL using the ZetaSQL grammar engine, uses the table schema from BigQuery API and persists the generated lineage in a BigQuery table and as a tag in Data Catalog. The lineage table can then be queried to identify the complete flow of data in the data warehouse. Here’s a look at the architecture:
Try data lineage for yourself
Enough talk! Deploy your own BigQuery data lineage system by cloning the bigquery-data-lineage Github repository or take it a step further by trying to dynamically propagate the data access policy to derived tables based on the lineage signals.


