Guide de solution : Sauvegarde et reprise après sinistre Google Cloud pour Oracle sur solution Bare Metal
Présentation
Pour assurer la résilience de vos bases de données Oracle dans un environnement de solution Bare Metal, vous devez disposer d'une stratégie claire pour les sauvegardes de bases de données et la reprise après sinistre. Pour vous aider à répondre à cette exigence, l'équipe d'architectes de solutions deGoogle Cloud a effectué des tests approfondis du service de sauvegarde et de reprise après sinistre Google Cloud et a compilé ses conclusions dans ce guide. Nous vous montrerons les meilleures façons de déployer, configurer et optimiser vos options de sauvegarde et de récupération pour les bases de données Oracle dans un environnement de solution Bare Metal à l'aide du service Backup and DR. Nous partagerons également des chiffres de performances issus de nos résultats de tests afin que vous disposiez d'un point de référence à comparer avec votre propre environnement. Ce guide vous sera utile si vous êtes administrateur de sauvegarde, administrateurGoogle Cloud ou administrateur de base de données Oracle.
Arrière-plan
En juin 2022, l'équipe d'architectes de solutions a commencé une démonstration de preuve de concept (POC) de Google Cloud Backup and DR pour un client Enterprise. Pour répondre à leurs critères de réussite, nous devions prendre en charge la récupération de leur base de données Oracle de 50 To et la restaurer dans les 24 heures.
Cet objectif a posé un certain nombre de défis, mais la plupart des personnes impliquées dans le PoC ont estimé que nous pouvions atteindre ce résultat et que nous devions poursuivre le PoC. Nous avons estimé que le risque était relativement faible, car nous disposions de données de tests précédents de l'équipe d'ingénierie Backup and DR montrant qu'il était possible d'obtenir ces résultats. Nous avons également partagé les résultats du test avec le client pour qu'il se sente à l'aise pour poursuivre le PoC.
Au cours de la démonstration de faisabilité, nous avons appris à configurer plusieurs éléments ensemble (Oracle, Google Cloud Backup and DR, stockage et liens d'extension régionale) dans un environnement de solution Bare Metal. En suivant les bonnes pratiques que nous avons apprises, vous pouvez obtenir vos propres résultats.
L'expression "Vos résultats peuvent varier" est un bon moyen de penser aux résultats globaux de ce document. Notre objectif est de partager certaines connaissances que nous avons acquises, les points sur lesquels vous devez vous concentrer, les choses à éviter et les domaines à examiner si vous n'obtenez pas les performances ou les résultats souhaités. Nous espérons que ce guide vous aidera à avoir confiance dans les solutions proposées et à répondre à vos besoins.
Architecture
La figure 1 présente une vue simplifiée de l'infrastructure que vous devez créer lorsque vous déployez Backup and DR pour protéger les bases de données Oracle s'exécutant dans un environnement de solution Bare Metal.
Figure 1 : Composants permettant d'utiliser Backup and DR avec des bases de données Oracle dans un environnement de solution Bare Metal

Comme vous pouvez le voir dans le schéma, cette solution nécessite les composants suivants :
- Extension régionale de la solution Bare Metal : vous permet d'exécuter des bases de données Oracle dans un centre de données tiers adjacent à un centre de données Google Cloud et d'utiliser vos licences logicielles sur site existantes.
- Projet de service Backup and DR : vous permet d'héberger votre appliance de sauvegarde/restauration et de sauvegarder les charges de travail solution Bare Metal et Google Cloud dans des buckets Cloud Storage.
- Projet de service de calcul : vous permet d'exécuter vos VM Compute Engine.
- Service Backup and DR : fournit la console de gestion Backup and DR qui vous permet de gérer vos sauvegardes et votre reprise après sinistre.
- Projet hôte : vous permet de créer des sous-réseaux régionaux dans un VPC partagé qui peut connecter l'extension régionale de la solution Bare Metal au service Backup and DR, à l'appliance de sauvegarde/récupération, à vos buckets Cloud Storage et à vos VM Compute Engine.
Installer Google Cloud Backup and DR
Pour que la solution Backup and DR fonctionne, elle doit au minimum comporter les deux composants majeurs suivants :
- Console de gestion Backup and DR : interface utilisateur HTML5 et point de terminaison d'API qui vous permettent de créer et de gérer des sauvegardes depuis la consoleGoogle Cloud .
- Appareil de sauvegarde/restauration : cet appareil sert de worker pour effectuer les sauvegardes, ainsi que les tâches de montage et de restauration.
Google Cloud gère la console de gestion Backup and DR. Vous devez déployer la console de gestion dans un projet producteur de services (côté gestion,Google Cloud ) et déployer l'appliance de sauvegarde/restauration dans un projet client de service (côté client). Pour en savoir plus sur Backup and DR, consultez Configurer et planifier un déploiement Backup and DR. Pour consulter la définition d'un producteur de services et d'un consommateur de services, consultez le glossaire Google Cloud.
Avant de commencer
Pour installer le service de sauvegarde et de reprise après sinistre Google Cloud , vous devez effectuer les étapes de configuration suivantes avant de commencer le déploiement :
- Activez une connexion d'accès aux services privés. Vous devez établir cette connexion avant de pouvoir lancer l'installation. Même si vous avez déjà configuré un sous-réseau d'accès aux services privés, il doit comporter au moins un sous-réseau
/23. Par exemple, si vous avez déjà configuré un sous-réseau/24pour la connexion d'accès aux services privés, nous vous recommandons d'ajouter un sous-réseau/23. Mieux encore, vous pouvez ajouter un sous-réseau/20pour vous assurer de pouvoir ajouter d'autres services ultérieurement. - Configurez Cloud DNS pour qu'il soit accessible dans le réseau VPC où vous déployez l'appliance de sauvegarde/récupération. Cela garantit la résolution correcte de googleapis.com (via une recherche privée ou publique).
- Configurez les routes par défaut du réseau et les règles de pare-feu pour autoriser le trafic sortant vers
*.googleapis.com(via les adresses IP publiques) ouprivate.googleapis.com(199.36.153.8/30) sur le port TCP 443, ou une sortie explicite pour0.0.0.0/0. Là encore, vous devez configurer les routes et le pare-feu dans le réseau VPC où vous installez votre appliance de sauvegarde/récupération. Nous vous recommandons également d'utiliser l'accès privé à Google comme option privilégiée. Pour en savoir plus, consultez Configurer l'accès privé à Google. - Activez les API suivantes dans votre projet consommateur :
- API Compute Engine
- API Cloud Key Management Service (KMS)
- API Cloud Resource Manager (pour le projet hôte et le projet de service, le cas échéant)
- API Identity and Access Management
- API Workflows
- API Cloud Logging
- Si vous avez activé des règles d'administration, assurez-vous de configurer les éléments suivants :
constraints/cloudkms.allowedProtectionLevelsinclutSOFTWAREouALL.
- Configurez les règles de pare-feu suivantes :
- Ingress depuis l'appliance de sauvegarde/récupération dans le VPC Compute Engine vers l'hôte Linux (agent) sur le port TCP-5106.
- Si vous utilisez un disque de sauvegarde basé sur des blocs avec iSCSI, la sortie de l'hôte Linux (agent) dans la solution Bare Metal vers l'appliance de sauvegarde/récupération dans le VPC Compute Engine sur le port TCP-3260.
- Si vous utilisez un disque de sauvegarde basé sur NFS ou dNFS, la sortie de l'hôte Linux (agent) dans la solution Bare Metal vers l'appliance de sauvegarde/récupération dans le VPC Compute Engine doit s'effectuer sur les ports suivants :
- TCP/UDP-111 (rpcbind)
- TCP/UDP-756 (état)
- TCP/UDP-2049 (nfs)
- TCP/UDP-4001 (mountd)
- TCP/UDP-4045 (nlockmgr)
- Configurez Google Cloud DNS pour résoudre les noms d'hôte et les domaines de la solution Bare Metal. Cela permet d'assurer une résolution de noms cohérente sur les serveurs, les VM et les ressources basées sur Compute Engine de la solution Bare Metal, comme le service Backup and DR.
Installer la console de gestion Backup and DR
- Activez l'API du service Backup and DR si ce n'est pas déjà fait.
Dans la console Google Cloud , utilisez le menu de navigation pour accéder à la section Opérations, puis sélectionnez Sauvegarde et reprise après sinistre :
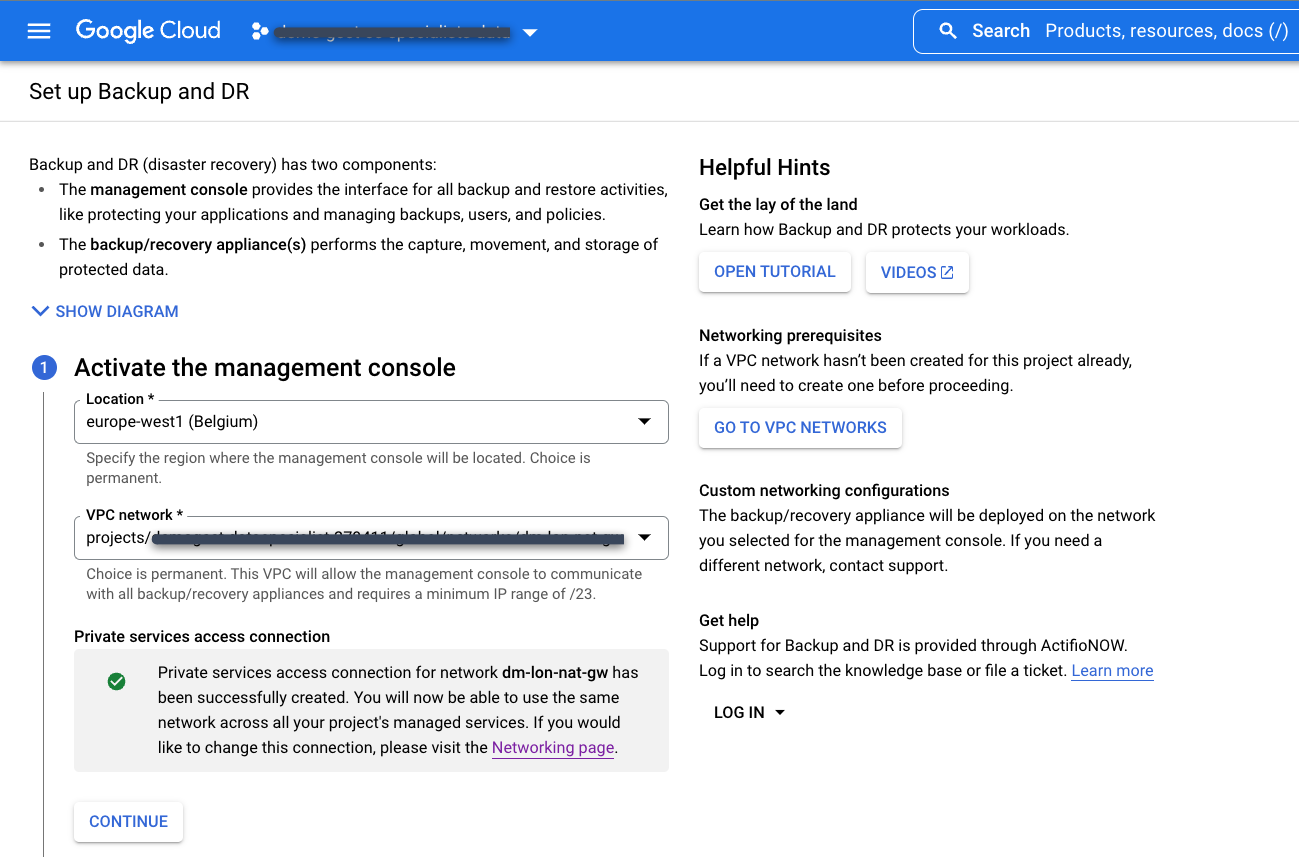
Sélectionnez la connexion d'accès privé aux services que vous avez créée précédemment.
Choisissez l'emplacement de la console de gestion Backup and DR. Il s'agit de la région dans laquelle vous déployez l'interface utilisateur de la console de gestion Backup and DR dans un projet de producteur de services. Google Cloud possède et gère les ressources de la console de gestion.
Choisissez le réseau VPC du projet de consommateur de services auquel vous souhaitez vous connecter au service de sauvegarde et de reprise après sinistre. Il s'agit généralement d'un projet hôte ou de VPC partagé.
Après avoir patienté jusqu'à une heure, l'écran suivant devrait s'afficher une fois le déploiement terminé.
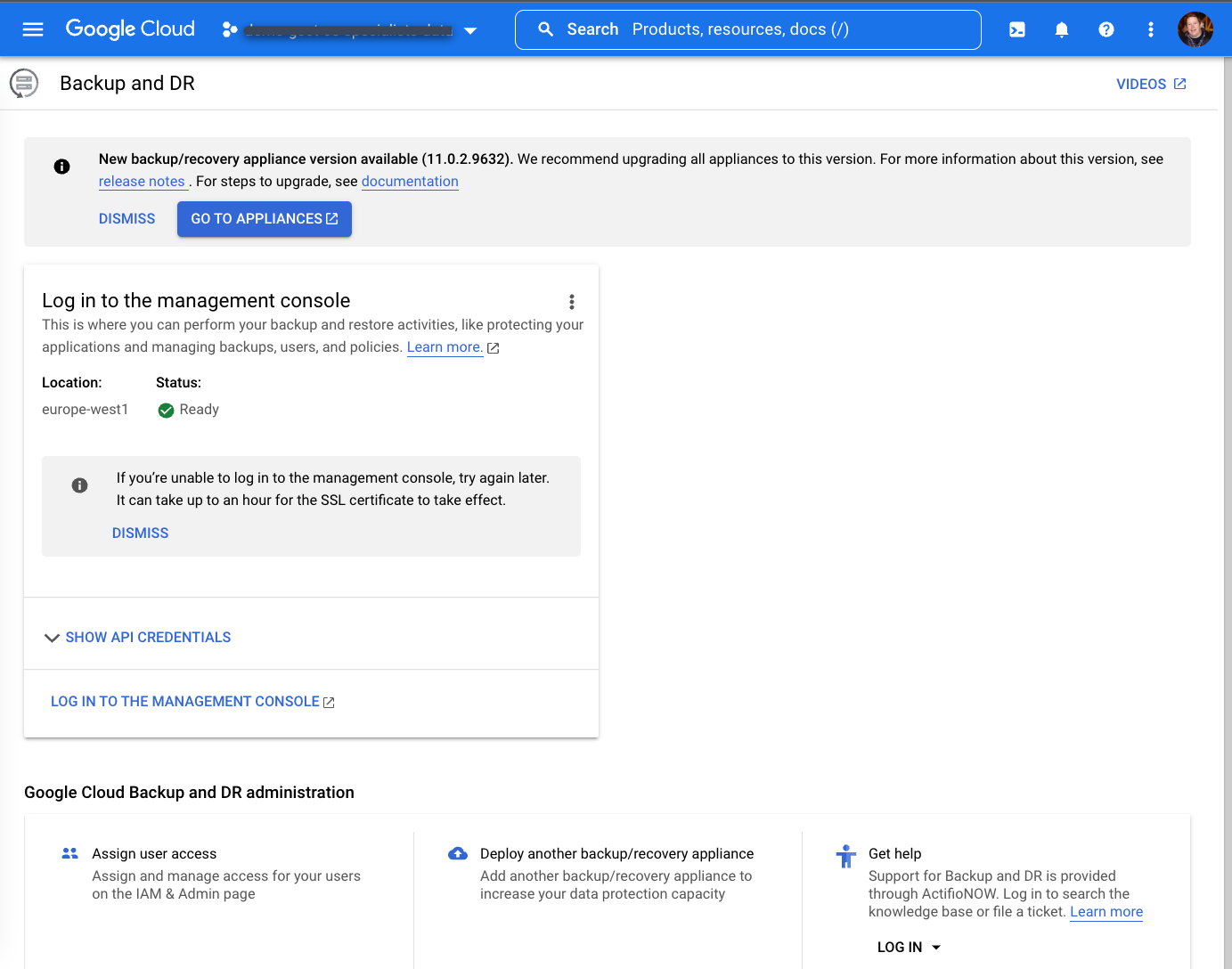
Installer l'appliance de sauvegarde/restauration
Sur la page Backup and DR, cliquez sur Se connecter à la console de gestion :
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
Sur la page principale de la console de gestion Backup and DR, accédez à la page Appareils :
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Saisissez le nom de l'appliance de sauvegarde/récupération. Notez que Google Cloud ajoute automatiquement des nombres aléatoires à la fin du nom une fois le déploiement commencé.
Choisissez le projet consommateur dans lequel vous souhaitez installer l'appliance de sauvegarde/récupération.
Choisissez la région, la zone et le sous-réseau de votre choix.
Sélectionnez un type de stockage. Nous vous recommandons de choisir Disque persistant standard pour les tests de validation et Disque persistant SSD pour un environnement de production.
Cliquez sur le bouton Begin Installation (Commencer l'installation). Le déploiement de la console de gestion Backup and DR et du premier appareil de sauvegarde/restauration devrait prendre une heure.
Vous pouvez ajouter d'autres appliances de sauvegarde/récupération dans d'autres régions ou zones une fois le processus d'installation initial terminé.
Configurer Google Cloud Backup and DR
Dans cette section, vous allez découvrir la procédure à suivre pour configurer le service Backup and DR et protéger vos charges de travail.
Configurer un compte de service
Depuis la version 11.0.2 (version de décembre 2022 de Backup and DR), vous pouvez utiliser un seul compte de service pour exécuter l'appliance de sauvegarde/récupération afin d'accéder aux buckets Cloud Storage et de protéger vos machines virtuelles (VM) Compute Engine (non traitées dans ce document).
Rôles de compte de service
Google Cloud Backup and DR utilise Google Cloud Identity and Access Management (IAM) pour l'autorisation et l'authentification des utilisateurs et des comptes de service. Vous pouvez utiliser des rôles prédéfinis pour activer diverses fonctionnalités de sauvegarde. Voici les deux plus importants :
- Opérateur Backup and DR Cloud Storage : attribuez ce rôle aux comptes de service utilisés par une appliance de sauvegarde/récupération qui se connecte aux bucket Cloud Storage. Ce rôle permet de créer des buckets Cloud Storage pour les sauvegardes d'instantanés Compute Engine et d'accéder aux buckets contenant des données de sauvegarde existantes basées sur des agents pour restaurer les charges de travail.
- Opérateur Backup and DR Compute Engine : attribuez ce rôle aux comptes de service utilisés par un dispositif de sauvegarde/récupération pour créer des instantanés de disques persistants pour les machines virtuelles Compute Engine. En plus de créer des instantanés, ce rôle permet au compte de service de restaurer des VM dans le même projet source ou dans d'autres projets.
Pour trouver votre compte de service, consultez la VM Compute Engine exécutant votre appliance de sauvegarde/récupération dans votre projet de consommateur/de service, puis examinez la valeur du compte de service listée dans la section Gestion des API et des identités.
Pour accorder les autorisations appropriées à vos appliances de sauvegarde/récupération, accédez à la page Identity and Access Management et attribuez les rôles Identity and Access Management suivants au compte de service de votre appliance de sauvegarde/récupération.
- Opérateur de sauvegarde et de reprise après sinistre pour Cloud Storage
- Opérateur Compute Engine de sauvegarde et de reprise après sinistre (facultatif)
Configurer des pools de stockage
Les pools de stockage stockent les données dans des emplacements de stockage physiques. Vous devez utiliser un disque persistant pour vos données les plus récentes (1 à 14 jours) et Cloud Storage pour la conservation à long terme (jours, semaines, mois et années).
Cloud Storage
Créez un bucket standard régional ou multirégional à l'emplacement où vous devez stocker les données de sauvegarde.
Suivez ces instructions pour créer un bucket Cloud Storage :
- Sur la page Buckets Cloud Storage, nommez le bucket.
- Sélectionnez votre emplacement de stockage.
- Choisissez une classe de stockage : standard, nearline ou coldline.
- Si vous choisissez le stockage Nearline ou Coldline, définissez le mode Contrôle des accès sur Ultraprécis. Pour le stockage standard, acceptez le mode de contrôle des accès par défaut Uniforme.
Enfin, ne configurez aucune autre option de protection des données et cliquez sur Créer.
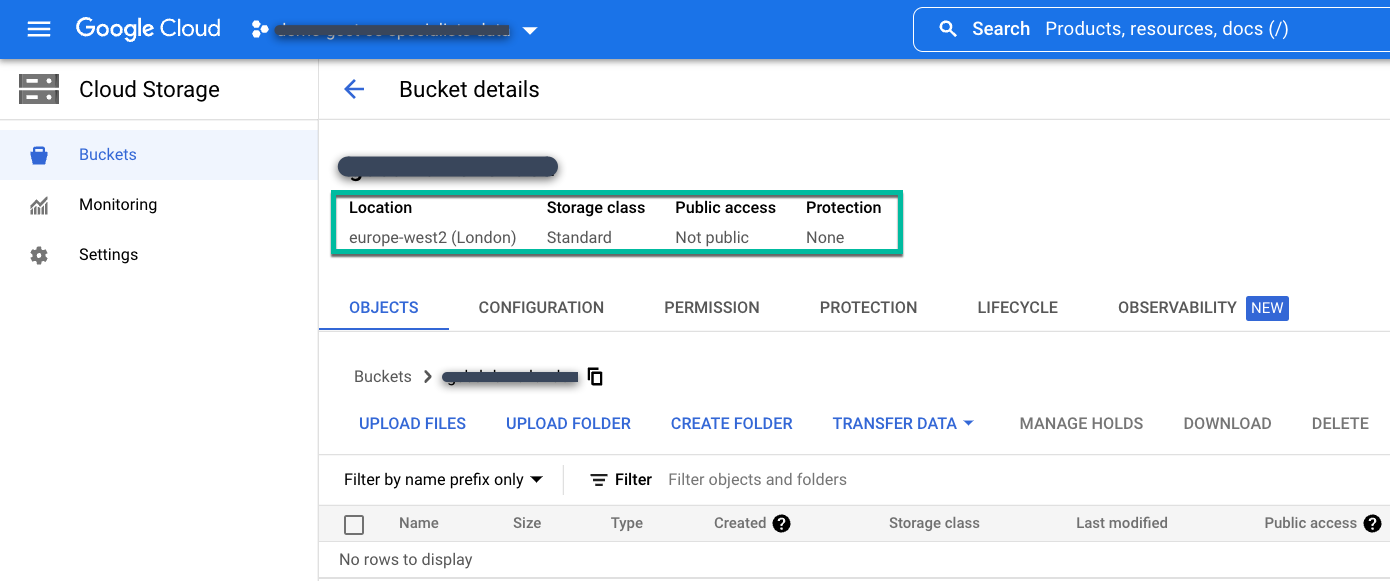
Ajoutez ensuite ce bucket à l'appliance de sauvegarde/récupération. Accédez à la console de gestion Backup and DR.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
Sélectionnez l'élément de menu Gérer > Pools de stockage.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#pools
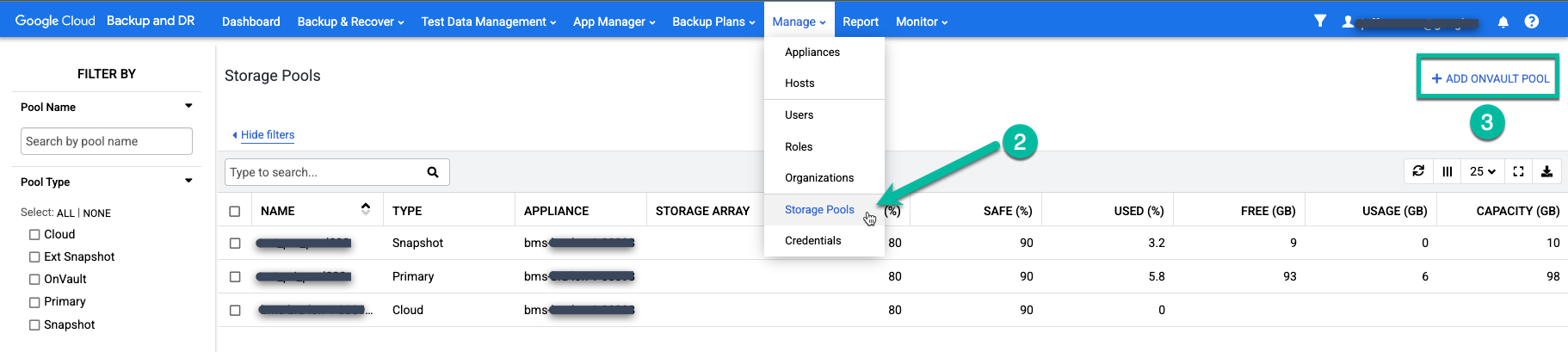
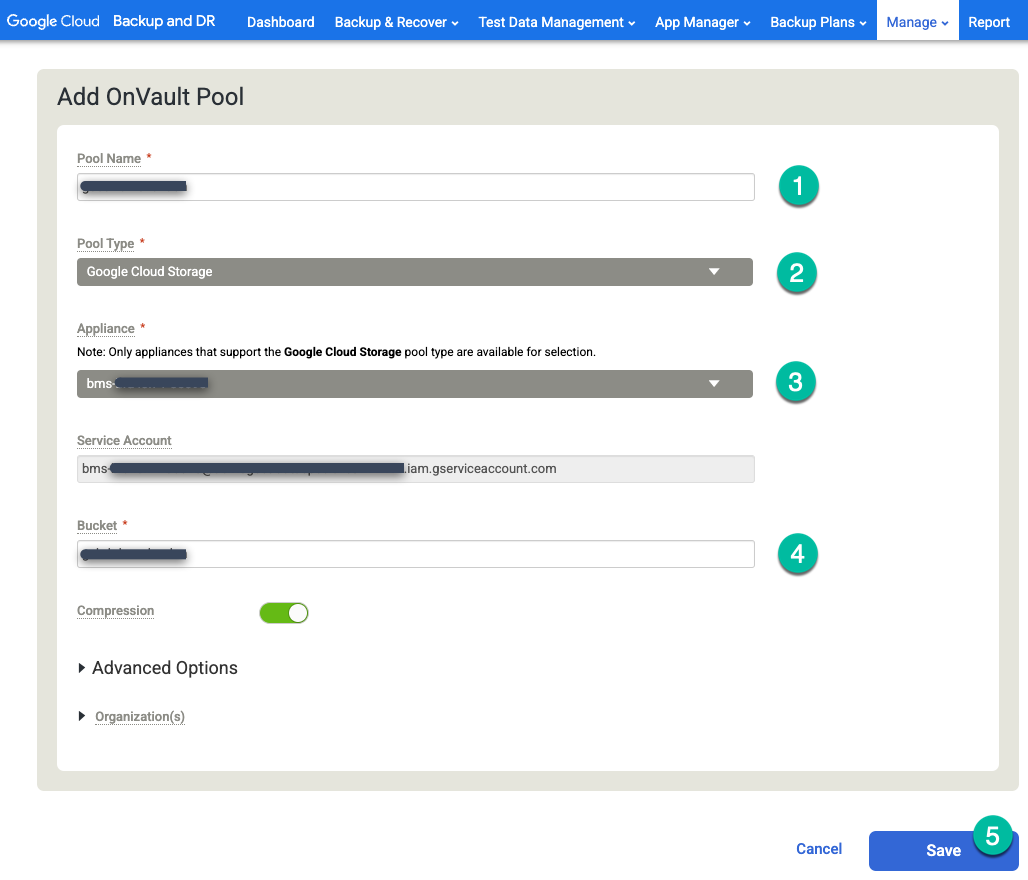
Cliquez sur l'option tout à droite + Add OnVault Pool (Ajouter un pool OnVault).
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#addonvaultpool
- Saisissez un nom pour le pool.
- Choisissez Cloud Storage pour le type de pool.
- Sélectionnez l'appliance que vous souhaitez associer au bucket Cloud Storage.
- Saisissez le nom du bucket Cloud Storage.
Cliquez sur Enregistrer.
Pools d'instantanés Persistent Disk
Si vous avez déployé l'appliance de sauvegarde/récupération avec les options standard ou SSD, le pool d'instantanés Persistent Disk sera de 4 To par défaut. Si vos bases de données ou systèmes de fichiers sources nécessitent un pool de plus grande taille, vous pouvez modifier les paramètres de votre appliance de sauvegarde/récupération déployée, ajouter un disque persistant, puis créer un pool personnalisé ou configurer un autre pool par défaut.
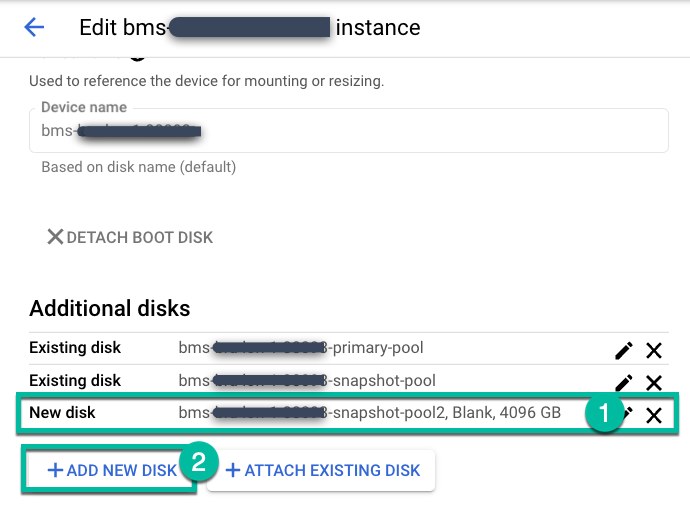
Accédez à la page Gérer > Appareils.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Modifiez l'instance backup-server, puis cliquez sur + Ajouter un disque.
- Donnez un nom au disque.
- Sélectionnez un type de disque Vide.
- Choisissez "Standard", "Équilibré" ou "SSD" en fonction de vos besoins.
- Saisissez la taille de disque dont vous avez besoin.
Cliquez sur Enregistrer.
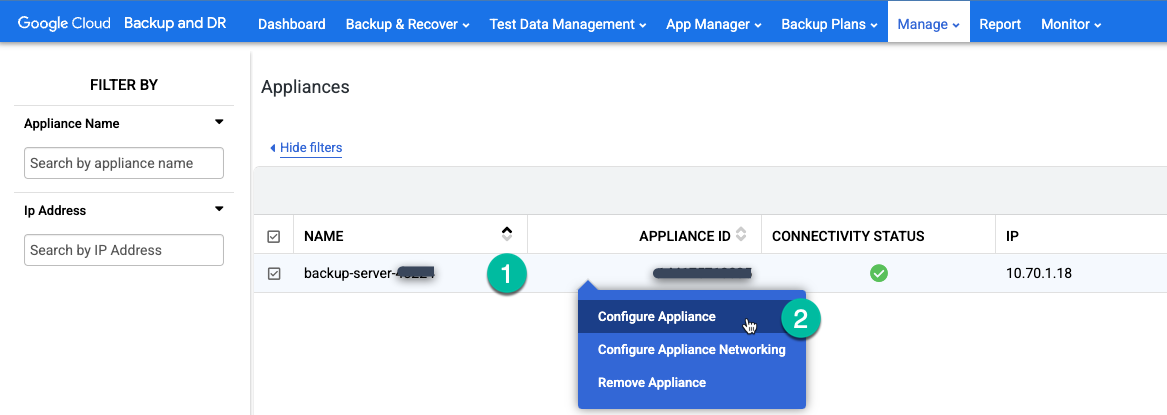
Accédez à la page Gérer > Appareils dans la console de gestion Backup and DR.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Effectuez un clic droit sur le nom de l'appliance, puis sélectionnez Configurer l'appliance dans le menu.
Vous pouvez ajouter le disque au pool d'instantanés existant (extension) ou créer un pool (toutefois, ne mélangez pas les types de disques persistants dans le même pool). Si vous souhaitez développer un pool, cliquez sur l'icône en haut à droite.
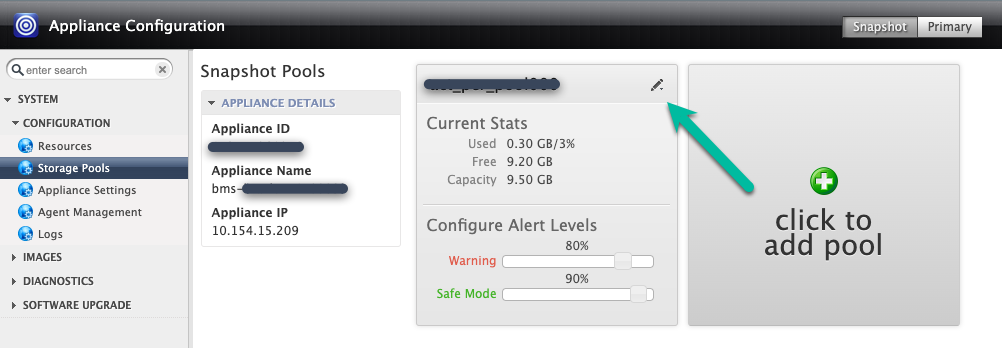
Dans cet exemple, vous allez créer un pool à l'aide de l'option Cliquer pour ajouter un pool. Après avoir cliqué sur ce bouton, patientez 20 secondes avant que la page suivante s'ouvre.
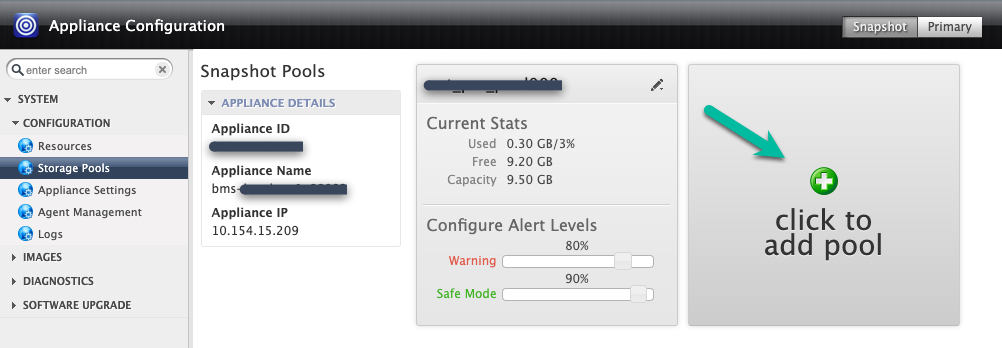
À cette étape, configurez votre nouveau pool.
- Donnez un nom au pool, puis cliquez sur l'icône + verte pour ajouter le disque au pool.
- Cliquez sur Envoyer.
- Lorsque vous y êtes invité, confirmez que vous souhaitez continuer en saisissant CONTINUER en majuscules.
Cliquez sur Confirmer.
Votre pool sera alors étendu ou créé avec le disque persistant.
Configurer des plans de sauvegarde
Les plans de sauvegarde vous permettent de configurer deux éléments clés pour sauvegarder une base de données, une VM ou un système de fichiers. Les plans de sauvegarde intègrent des profils et des modèles.
- Les profils vous permettent de définir quand sauvegarder un élément et pendant combien de temps les données de sauvegarde doivent être conservées.
- Les modèles fournissent un élément de configuration qui vous permet de choisir l'appliance de sauvegarde/récupération et le pool de stockage (disque persistant, Cloud Storage, etc.) doit être utilisé pour la tâche de sauvegarde.
Créer un profil
Dans la console de gestion Backup and DR, accédez à la page Plans de sauvegarde > Profils.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#manageprofiles
Deux profils seront déjà créés. Vous pouvez utiliser un profil pour les instantanés de VM Compute Engine, et modifier l'autre profil pour l'utiliser pour les sauvegardes solution Bare Metal. Vous pouvez avoir plusieurs profils, ce qui est utile si vous sauvegardez de nombreuses bases de données qui nécessitent différents niveaux de disque pour la sauvegarde. Par exemple, vous pouvez créer un pool pour les disques persistants SSD (performances supérieures) et un autre pour les disques persistants standards (performances standards). Pour chaque profil, vous pouvez choisir un pool d'instantanés différent.
Effectuez un clic droit sur le profil par défaut nommé LocalProfile et sélectionnez Modifier.
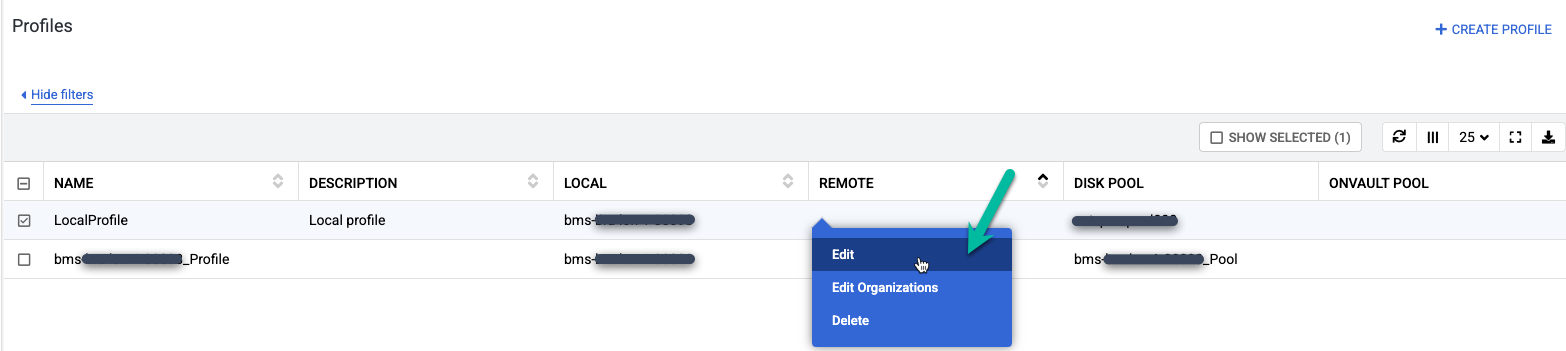
Apportez les modifications suivantes :
- Modifiez les paramètres Profils en ajoutant un nom et une description plus pertinents. Vous pouvez spécifier le niveau de disque à utiliser, l'emplacement des bucket Cloud Storage ou d'autres informations expliquant l'objectif de ce profil.
- Remplacez le pool d'instantanés par le pool étendu ou le nouveau pool que vous avez créé précédemment.
- Sélectionnez un pool OnVault (bucket Cloud Storage) pour ce profil.
Cliquez sur Enregistrer le profil.
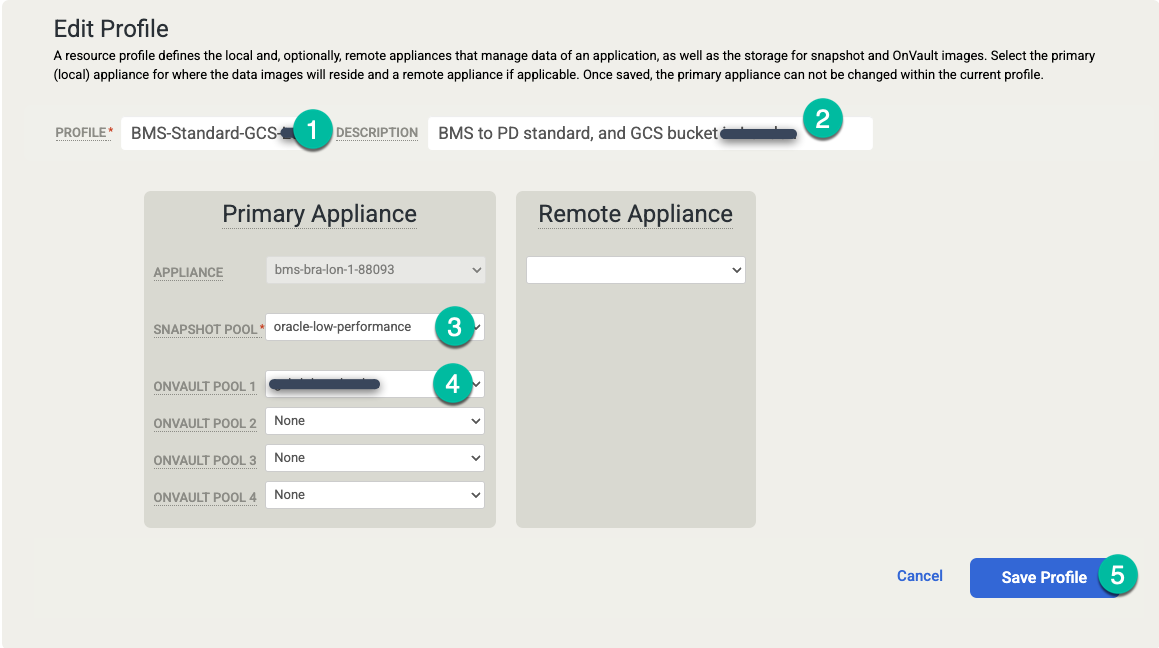
Créer un modèle
Dans la console de gestion Backup and DR, accédez au menu Plans de sauvegarde > Modèles.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#managetemplates
Cliquez sur + Créer un modèle.
- Attribuez un nom au modèle.
- Sélectionnez Oui pour Autoriser les remplacements des paramètres des règles.
- Ajoutez une description de ce modèle.
Cliquez sur Enregistrer le modèle.
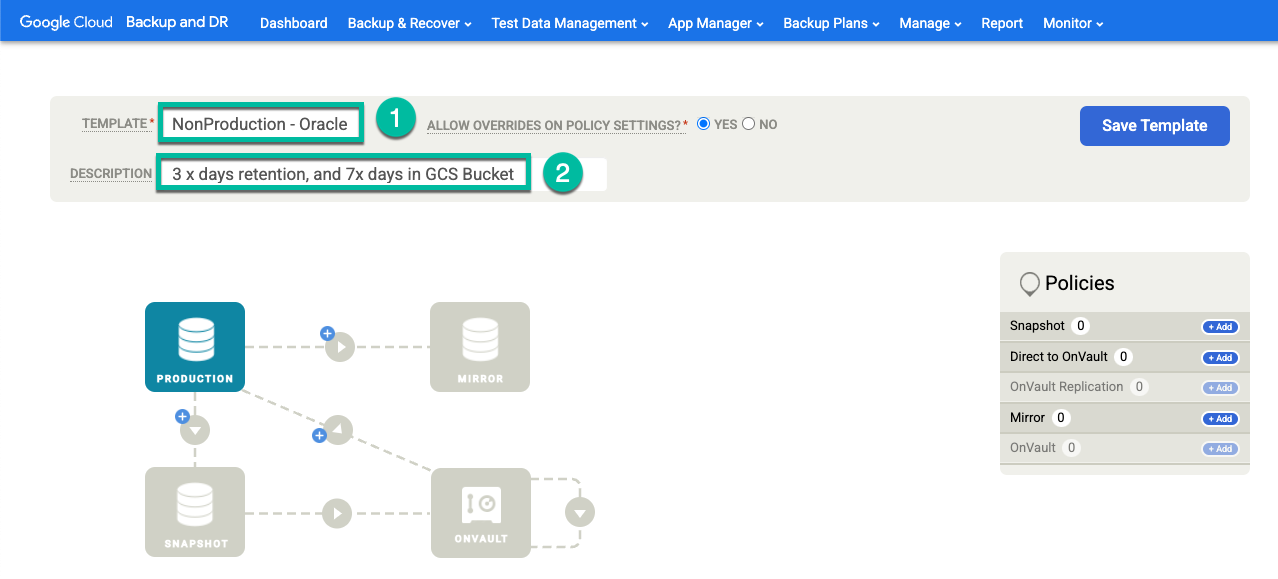
Dans votre modèle, configurez les éléments suivants :
- Dans la section Règles à droite, cliquez sur + Ajouter.
- Nommez la règle.
- Cochez les cases correspondant aux jours où vous souhaitez que le règlement s'applique, ou laissez la valeur par défaut Tous les jours.
- Modifiez la fenêtre pour les jobs que vous souhaitez exécuter au cours de cette période.
- Sélectionnez une durée de conservation.
Cliquez sur Paramètres avancés des règles.
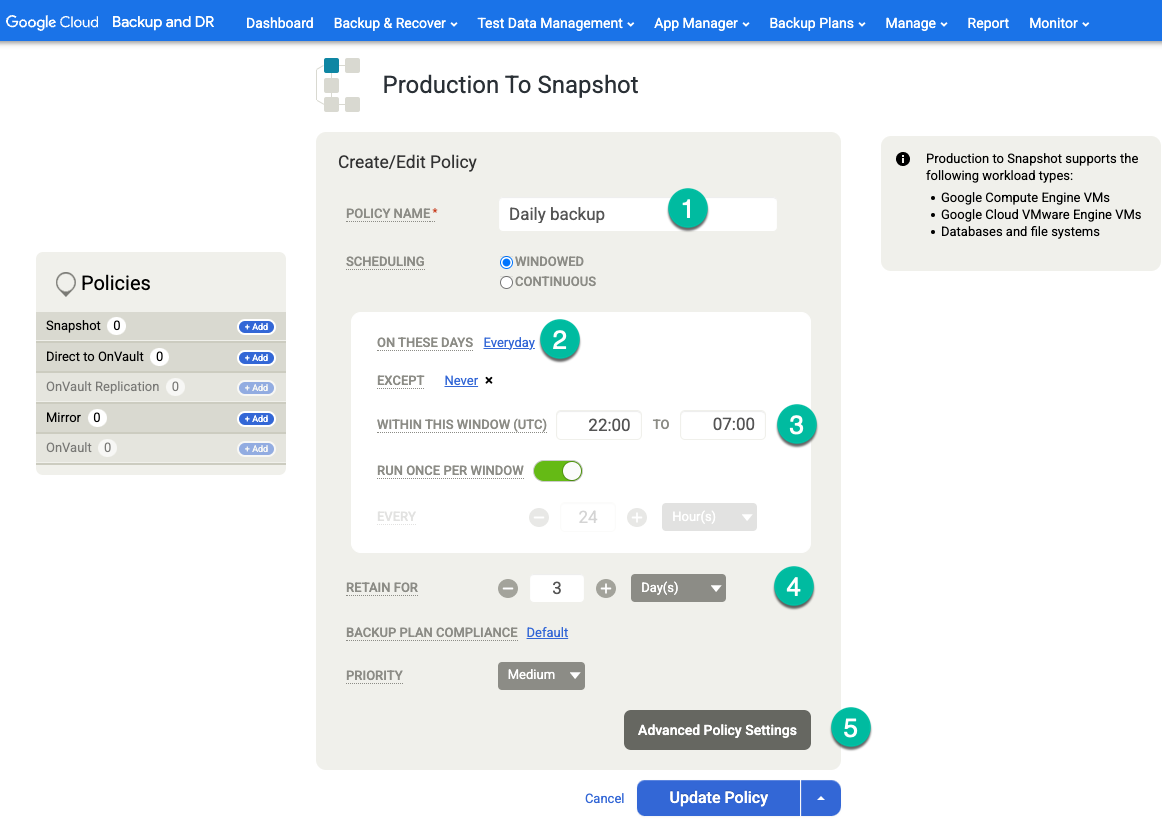
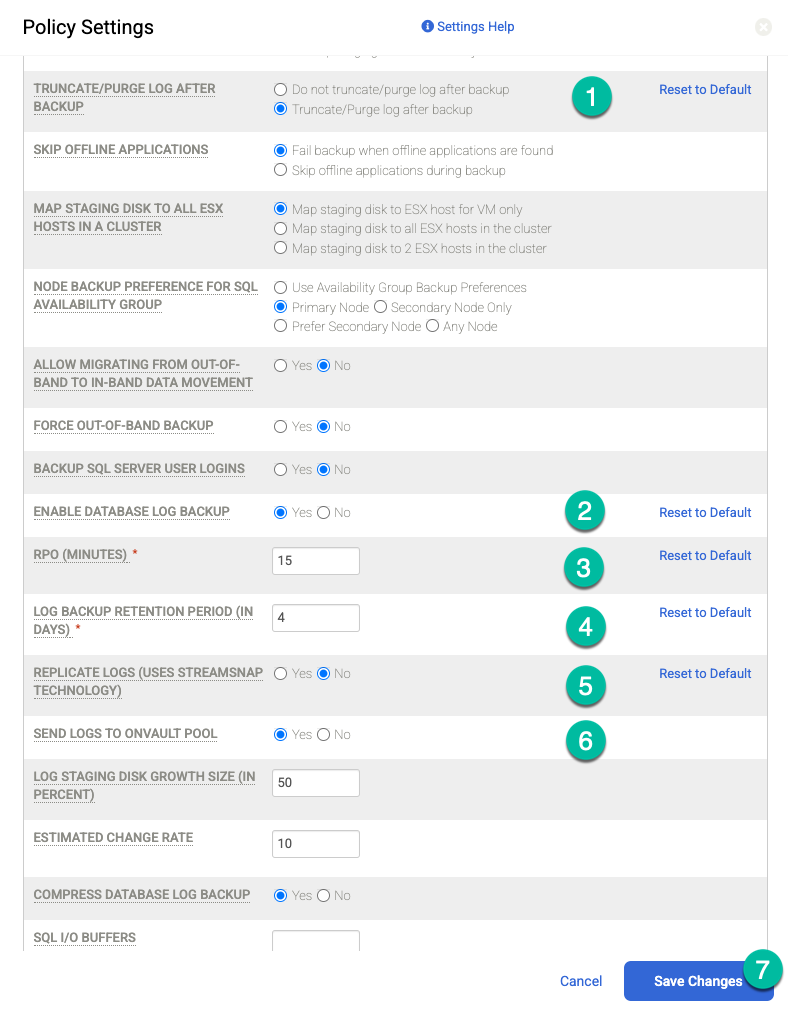
Si vous souhaitez effectuer des sauvegardes de journaux d'archive à une fréquence régulière (par exemple, toutes les 15 minutes) et répliquer les journaux d'archive dans Cloud Storage, vous devez activer les paramètres de règle suivants :
- Définissez Tronquer/Purger le journal après la sauvegarde sur Tronquer si c'est ce que vous souhaitez.
- Définissez Activer la sauvegarde du journal de base de données sur Oui si vous le souhaitez.
- Définissez RPO (minutes) sur l'intervalle de sauvegarde des journaux d'archive souhaité.
- Définissez la durée de conservation des sauvegardes de journaux (en jours) sur la durée de conservation souhaitée.
- Définissez Répliquer les journaux (utilise la technologie Streamsnap) sur Non.
- Définissez Send Logs to OnVault Pool (Envoyer les journaux au pool OnVault) sur Yes (Oui) si vous souhaitez envoyer les journaux à votre bucket Cloud Storage. Sinon, sélectionnez Non.
Cliquez sur Enregistrer les modifications.
Cliquez sur Mettre à jour le règlement pour enregistrer vos modifications.
Pour OnVault à droite, procédez comme suit :
- Cliquez sur +Ajouter.
- Ajoutez le nom de la règle.
- Définissez la période de conservation en jours, semaines, mois ou années.
Cliquez sur Mettre à jour la règle.
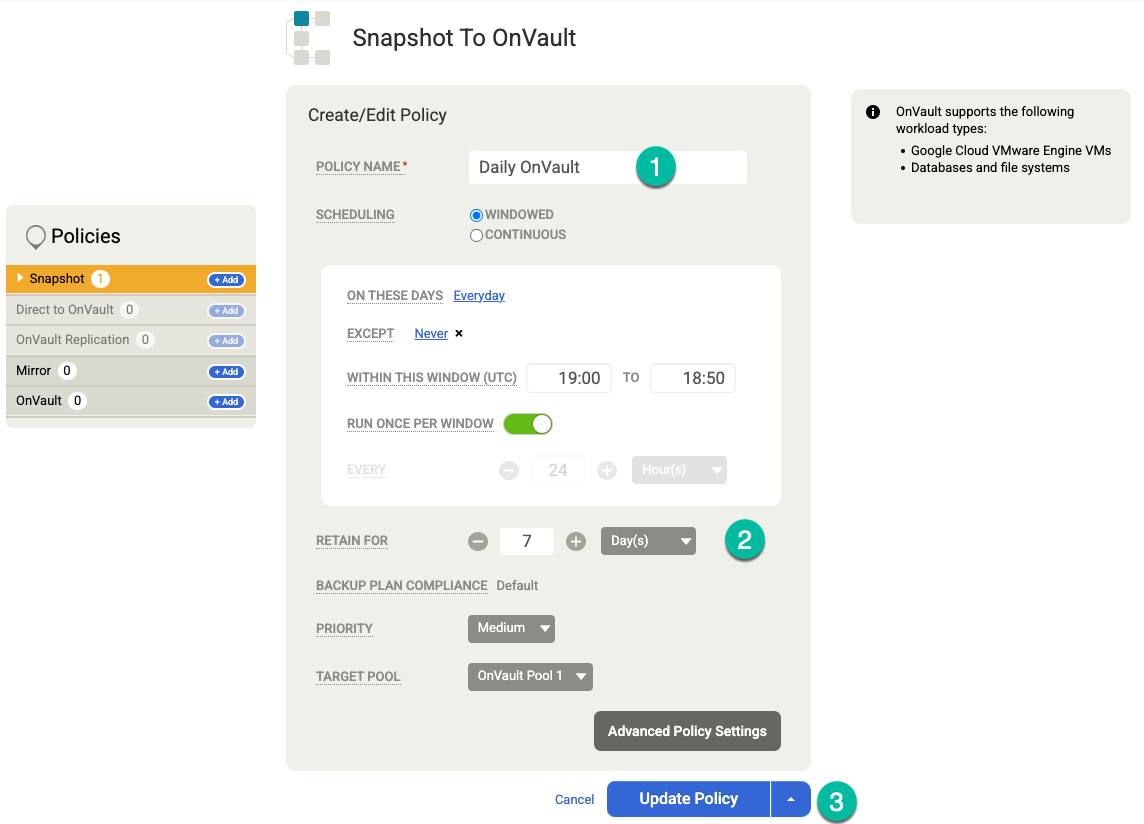
(Facultatif) Si vous devez ajouter d'autres options de conservation, créez des règles supplémentaires pour la conservation hebdomadaire, mensuelle et annuelle. Pour ajouter une autre règle de conservation, procédez comme suit :
- À droite, sous OnVault, cliquez sur + Ajouter.
- Ajoutez un nom de règle.
- Modifiez la valeur de On These Days (Ces jours-ci) pour définir le jour où vous souhaitez déclencher ce job.
- Définissez la durée de conservation en jours, semaines, mois ou années.
Cliquez sur Mettre à jour la règle.
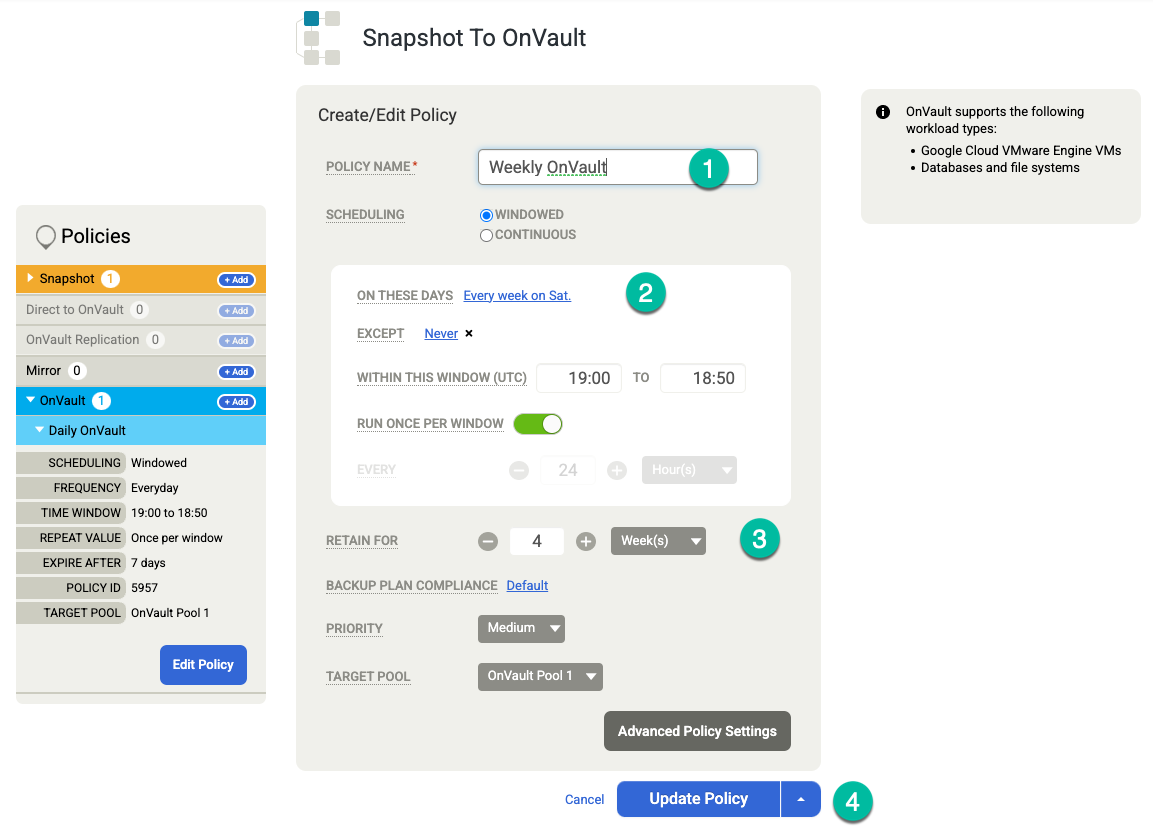
Cliquez sur Enregistrer le modèle. Dans l'exemple suivant, vous verrez une règle d'instantané qui conserve les sauvegardes pendant trois jours dans le niveau Disque persistant, sept jours pour les tâches OnVault et quatre semaines au total. La sauvegarde hebdomadaire s'exécute le samedi soir.
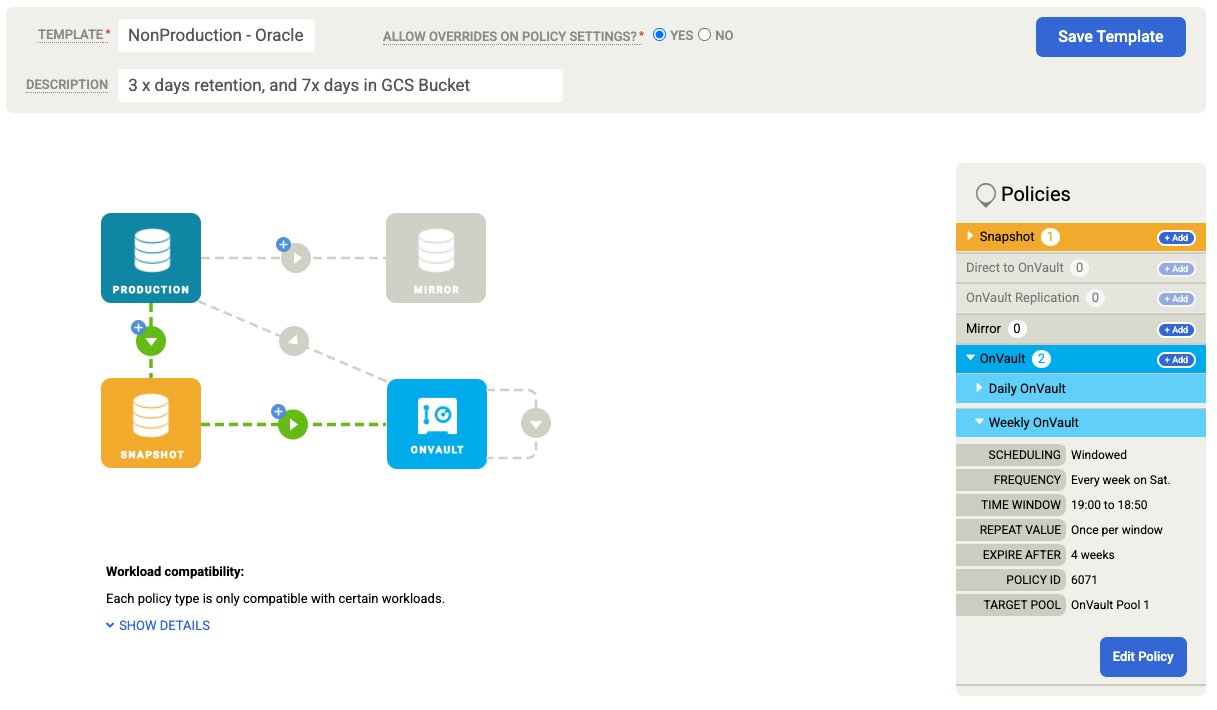
Sauvegarder une base de données Oracle
L'architecture Backup and DR fournit une sauvegarde Oracle incrémentielle et cohérente des applications vers Google Cloud, ainsi qu'une récupération et un clonage instantanés pour les bases de données Oracle de plusieurs téraoctets. Google Cloud
Google Cloud Backup and DR utilise les API Oracle suivantes :
- API RMAN image copy : la restauration d'une copie d'image d'un fichier de données est beaucoup plus rapide, car la structure physique du fichier de données existe déjà. La directive Recovery Manager (RMAN) BACKUP AS COPY crée des copies d'image pour tous les fichiers de données de l'ensemble de la base de données et conserve le format des fichiers de données.
- API ASM et CRS : utilisez l'API ASM (Automatic Storage Management) et CRS (Cluster Ready Services) pour gérer le groupe de disques de sauvegarde ASM.
- API de sauvegarde des journaux d'archive RMAN : cette API génère des journaux d'archive, les sauvegarde sur un disque intermédiaire et les supprime de l'emplacement de l'archive de production.
Configurer les hôtes Oracle
Pour configurer vos hôtes Oracle, vous devez installer l'agent, ajouter les hôtes à Backup and DR, configurer les hôtes et découvrir la ou les bases de données Oracle. Une fois que tout est en place, vous pouvez effectuer vos sauvegardes de la base de données Oracle vers Backup and DR.
Installer l'agent de sauvegarde
L'installation de l'agent Backup and DR est relativement simple. Vous n'avez besoin d'installer l'agent que la première fois que vous utilisez l'hôte. Les mises à niveau ultérieures peuvent être effectuées depuis l'interface utilisateur Backup and DR dans la console Google Cloud . Pour installer un agent, vous devez être connecté en tant qu'utilisateur root ou dans une session authentifiée sudo. Vous n'avez pas besoin de redémarrer l'hôte pour terminer l'installation.
Téléchargez l'agent de sauvegarde depuis l'interface utilisateur ou sur la page Gérer > Appliances.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Effectuez un clic droit sur le nom de l'appliance de sauvegarde/récupération, puis sélectionnez Configurer l'appliance. Une nouvelle fenêtre de navigateur s'ouvre.
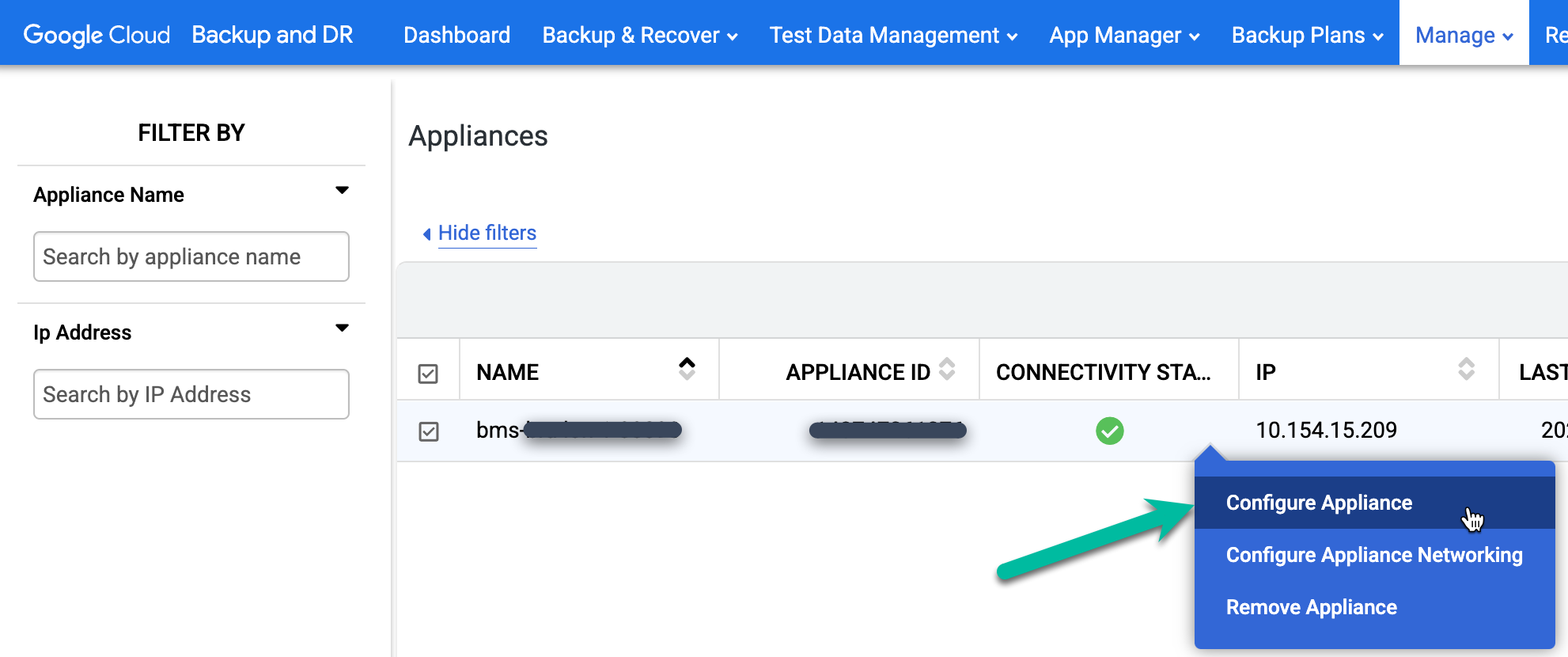
Cliquez sur l'icône Linux 64 bits pour télécharger l'agent de sauvegarde sur l'ordinateur qui héberge votre session de navigateur. Utilisez scp (copie sécurisée) pour déplacer le fichier de l'agent téléchargé vers les hôtes Oracle pour l'installation.
Vous pouvez également stocker l'agent de sauvegarde dans un bucket Cloud Storage, activer les téléchargements et utiliser les commandes
wgetoucurlpour télécharger l'agent directement sur vos hôtes Linux.curl -o agent-Linux-latestversion.rpm https://storage.googleapis.com/backup-agent-images/connector-Linux-11.0.2.9595.rpm
Utilisez la commande
rpm -ivhpour installer l'agent de sauvegarde.Il est très important de copier la clé secrète générée automatiquement. À l'aide de la console de gestion Backup and DR, vous devez ajouter la clé secrète aux métadonnées de l'hôte.
La sortie de la commande ressemble à ceci :
[oracle@host `~]# sudo rpm -ivh agent-Linux-latestversion.rpm Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing… 1:udsagent-11.0.2-9595 ################################# [100%] Created symlink /etc/systemd/system/multi-user.target.wants/udsagent.service → /usr/lib/systemd/system/udsagent.service. Action Required: -- Add this host to Backup and DR management console to backup/recover workloads from/to this host. You can do this by navigating to Manage->Hosts->Add Host on your management console. -- A secret key is required to complete this process. Please use b010502a8f383cae5a076d4ac9e868777657cebd0000000063abee83 (valid for 2 hrs) to register this host. -- A new secret key can be generated later by running: '/opt/act/bin/udsagent secret --reset --restart
Si vous utilisez la commande
iptables, ouvrez les ports pour le pare-feu de l'agent de sauvegarde (TCP 5106) et les services Oracle (TCP 1521) :sudo iptables -A INPUT -p tcp --dport 5106 -j ACCEPT sudo iptables -A INPUT -p tcp --dport 1521 -j ACCEPT sudo firewall-cmd --permanent --add-port=5106/tcp sudo firewall-cmd --permanent --add-port=1521/tcp sudo firewall-cmd --reload
Ajouter des hôtes à Backup and DR
Dans la console de gestion Backup and DR, accédez à Gérer > Hôtes.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
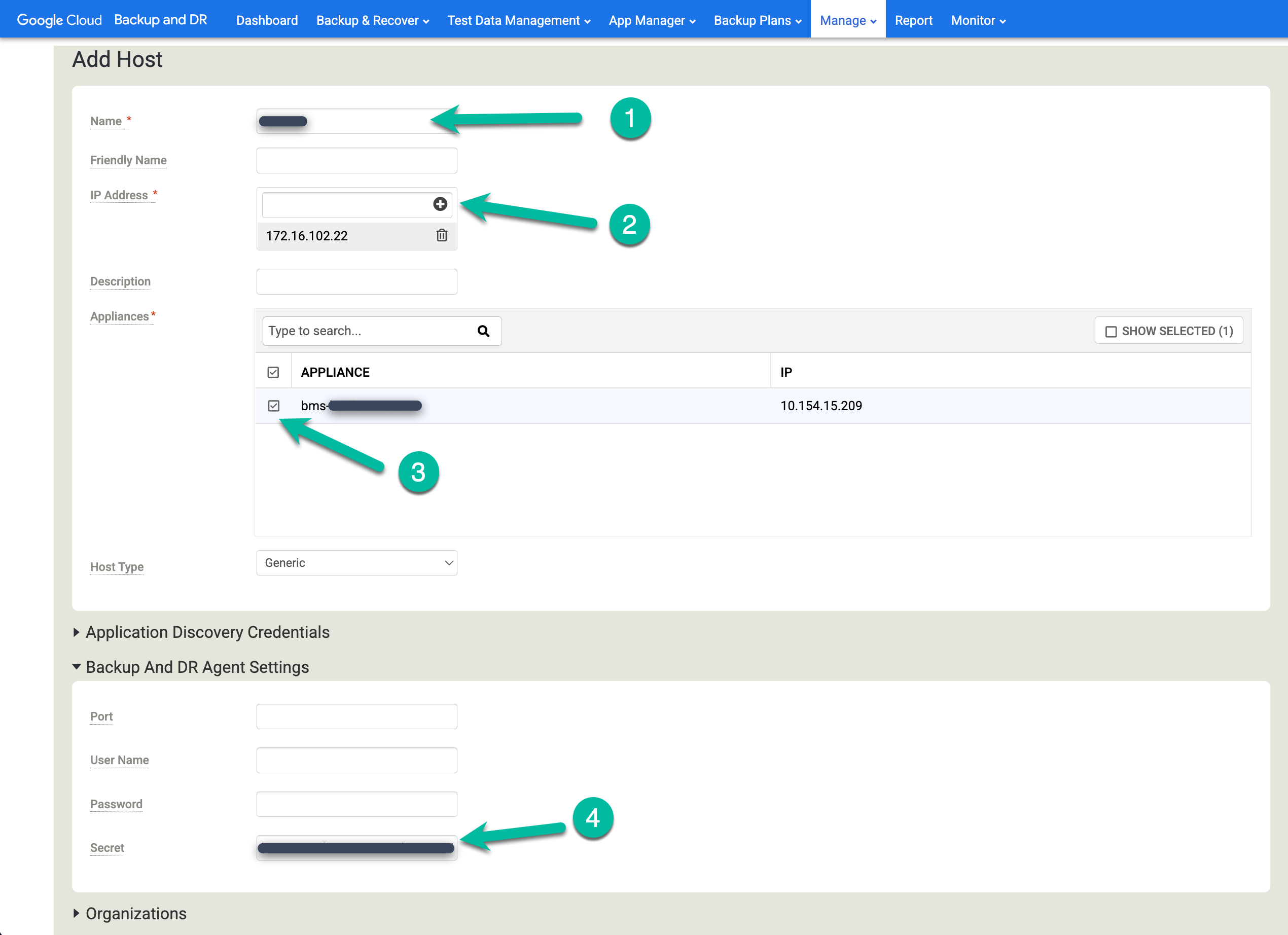
- Cliquez sur + Ajouter un hôte.
- Ajoutez le nom d'hôte.
- Ajoutez une adresse IP pour l'hôte, puis cliquez sur le bouton + pour confirmer la configuration.
- Cliquez sur le ou les appareils auxquels vous souhaitez ajouter l'hôte.
- Collez la clé secrète. Vous devez effectuer cette tâche moins de deux heures après avoir installé l'agent de sauvegarde et généré la clé secrète.
Cliquez sur Ajouter pour enregistrer l'hôte.
Si vous recevez un message d'erreur ou Succès partiel, essayez les solutions de contournement suivantes :
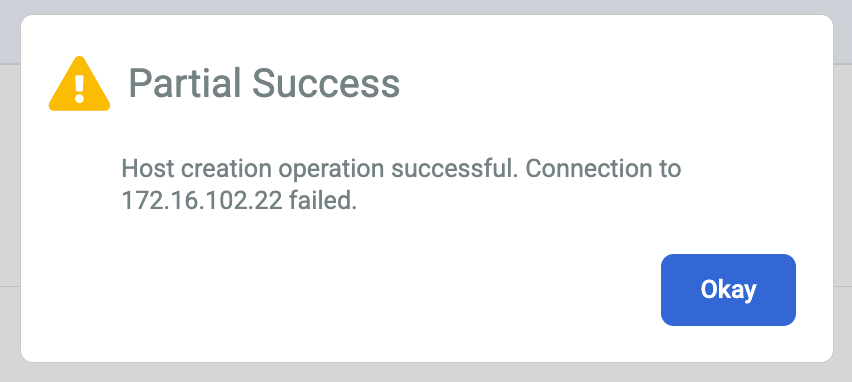
La clé secrète de chiffrement de l'agent de sauvegarde a peut-être expiré. Si vous n'avez pas ajouté la clé secrète à l'hôte dans les deux heures suivant sa création. Vous pouvez générer une clé secrète sur l'hôte Linux à l'aide de la syntaxe de ligne de commande suivante :
/opt/act/bin/udsagent secret --reset --restart
Il est possible que le pare-feu qui permet la communication entre l'appliance de sauvegarde/récupération et l'agent installé sur l'hôte ne soit pas correctement configuré. Suivez la procédure pour ouvrir les ports du pare-feu de l'agent de sauvegarde et des services Oracle.
Il est possible que la configuration NTP (Network Time Protocol) de vos hôtes Linux soit incorrecte. Vérifiez que vos paramètres NTP sont corrects.
Lorsque vous résolvez le problème sous-jacent, l'état du certificat doit passer de Non applicable à Valide.

Configurer les hôtes
Dans la console de gestion Backup and DR, accédez à Gérer > Hôtes.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
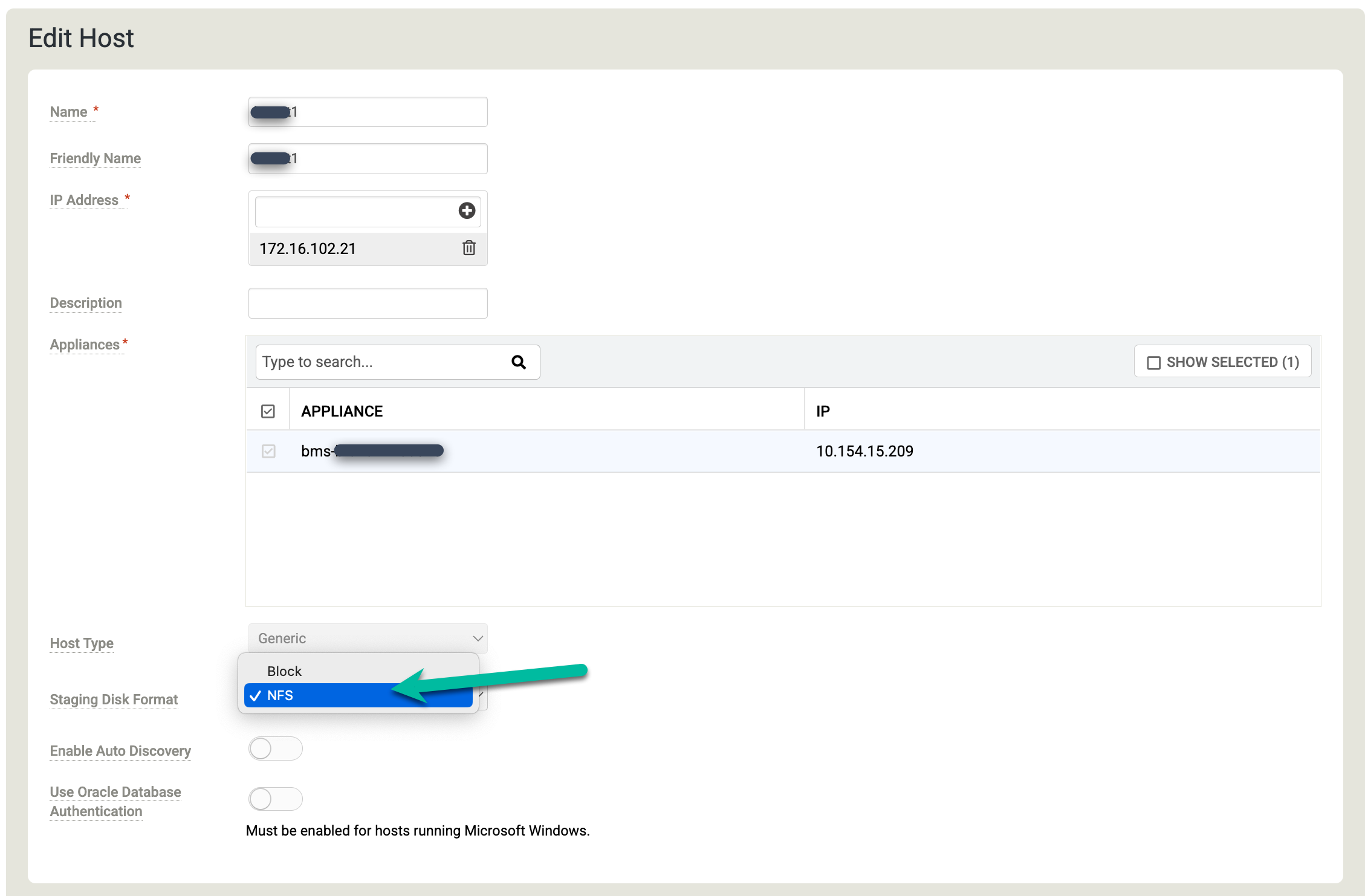
Effectuez un clic droit sur l'hôte Linux sur lequel vous souhaitez sauvegarder vos bases de données Oracle, puis sélectionnez Edit (Modifier).
Cliquez sur Format du disque intermédiaire, puis sélectionnez NFS.
Faites défiler la page jusqu'à la section Applications détectées, puis cliquez sur Détecter les applications pour lancer le processus de détection des appliances vers les agents.
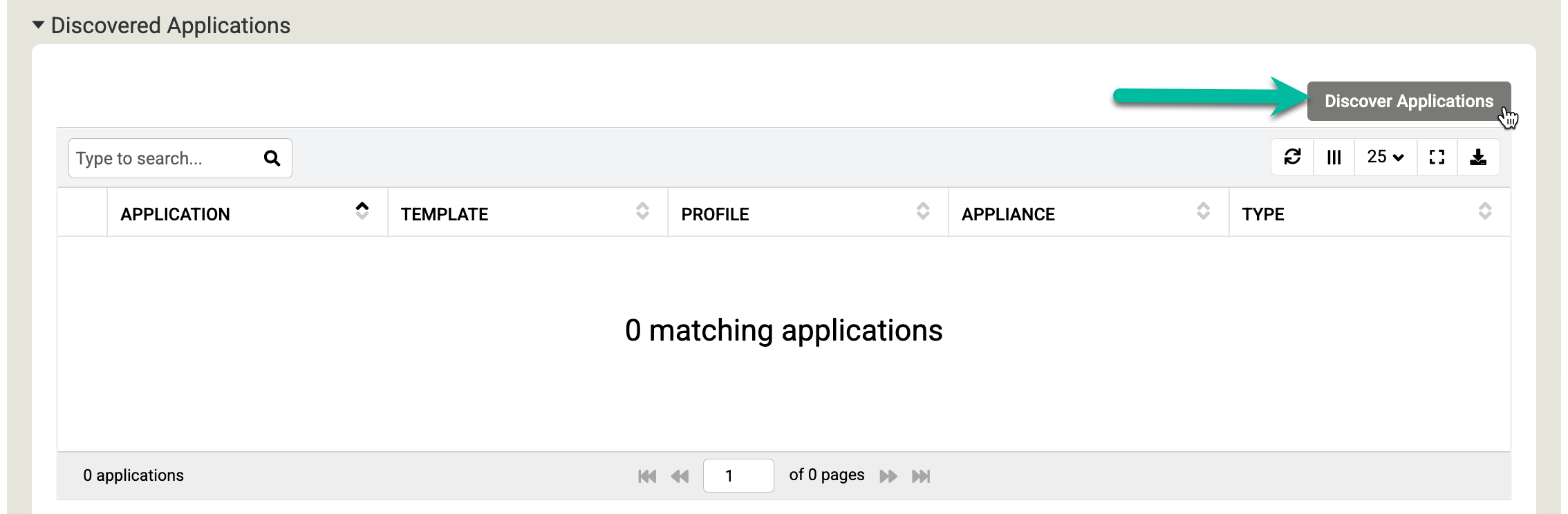
Cliquez sur Découvrir pour commencer. Le processus de découverte prend jusqu'à cinq minutes. Une fois l'opération terminée, les systèmes de fichiers et les bases de données Oracle détectés s'affichent dans la fenêtre des applications.
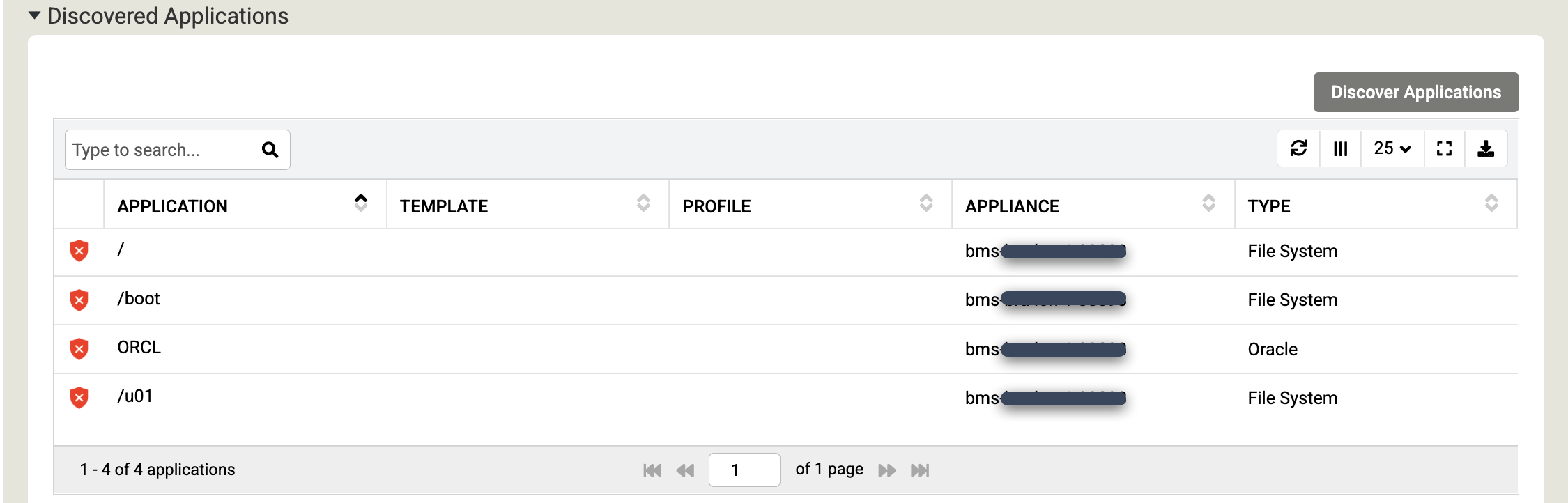
Cliquez sur Enregistrer pour appliquer les modifications à vos hôtes.
Préparer l'hôte Linux
En installant des packages d'utilitaires iSCSI ou NFS dans votre hôte basé sur un OS Linux, vous pouvez mapper un disque intermédiaire à un appareil qui écrit les données de sauvegarde. Exécutez les commandes suivantes pour installer les utilitaires iSCSI et NFS. Bien que vous puissiez utiliser l'un ou l'autre des ensembles d'utilitaires, ou les deux, cette étape vous permet de vous assurer que vous disposez de ce dont vous avez besoin, quand vous en avez besoin.
Pour installer les utilitaires iSCSI, exécutez la commande suivante :
sudo yum install -y iscsi-initiator-utils
Pour installer les utilitaires NFS, exécutez la commande suivante :
sudo yum install -y nfs-utils
Préparer la base de données Oracle
Ce guide suppose que vous avez déjà configuré une instance et une base de données Oracle. Google Cloud Backup and DR est compatible avec la protection des bases de données exécutées sur des systèmes de fichiers, ASM, Real Application Clusters (RAC) et de nombreuses autres configurations. Pour en savoir plus, consultez Sauvegarde et reprise après sinistre pour les bases de données Oracle.
Vous devez configurer quelques éléments avant de démarrer la tâche de sauvegarde. Certaines de ces tâches sont facultatives. Toutefois, nous vous recommandons d'utiliser les paramètres suivants pour des performances optimales :
- Utilisez SSH pour vous connecter à l'hôte Linux et connectez-vous en tant qu'utilisateur Oracle avec les droits su.
Définissez l'environnement Oracle sur votre instance spécifique :
. oraenv ORACLE_SID = [ORCL] ? The Oracle base remains unchanged with value /u01/app/oracle
Connectez-vous à SQL*Plus avec le compte
sysdba:sqlplus / as sysdba
Utilisez les commandes suivantes pour activer le mode ARCHIVELOG. La sortie des commandes ressemble à ceci :
SQL> shutdown Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ORACLE instance started. Total System Global Area 2415918600 bytes Fixed Size 9137672 bytes Variable Size 637534208 bytes Database Buffers 1761607680 bytes Redo Buffers 7639040 bytes Database mounted. SQL> alter database archivelog; Database altered. SQL> alter database open; Database altered. SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination /u01/app/oracle/product/19c/dbhome_1/dbs/arch Oldest online log sequence 20 Next log sequence to archive 22 Current log sequence 22 SQL> alter pluggable database ORCLPDB save state; Pluggable database altered.
Configurez Direct NFS pour l'hôte Linux :
cd $ORACLE_HOME/rdbms/lib make -f [ins_rdbms.mk](http://ins_rdbms.mk/) dnfs_on
Configurez le suivi des modifications des blocs. Vérifiez d'abord s'il est activé ou désactivé. L'exemple suivant montre que le suivi des modifications de blocs est désactivé :
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ DISABLED
SQL> alter database enable block change tracking using file +ASM_DISK_GROUP_NAME/DATABASE_NAME/DBNAME.bct; Database altered.
Exécutez la commande suivante lorsque vous utilisez un système de fichiers :
SQL> alter database enable block change tracking using file '$ORACLE_HOME/dbs/DBNAME.bct';; Database altered.
Vérifiez que le suivi des modifications de blocs est désormais activé :
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Protéger une base de données Oracle
Dans la console de gestion Backup and DR, accédez à la page Gestionnaire d'applications > Applications.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
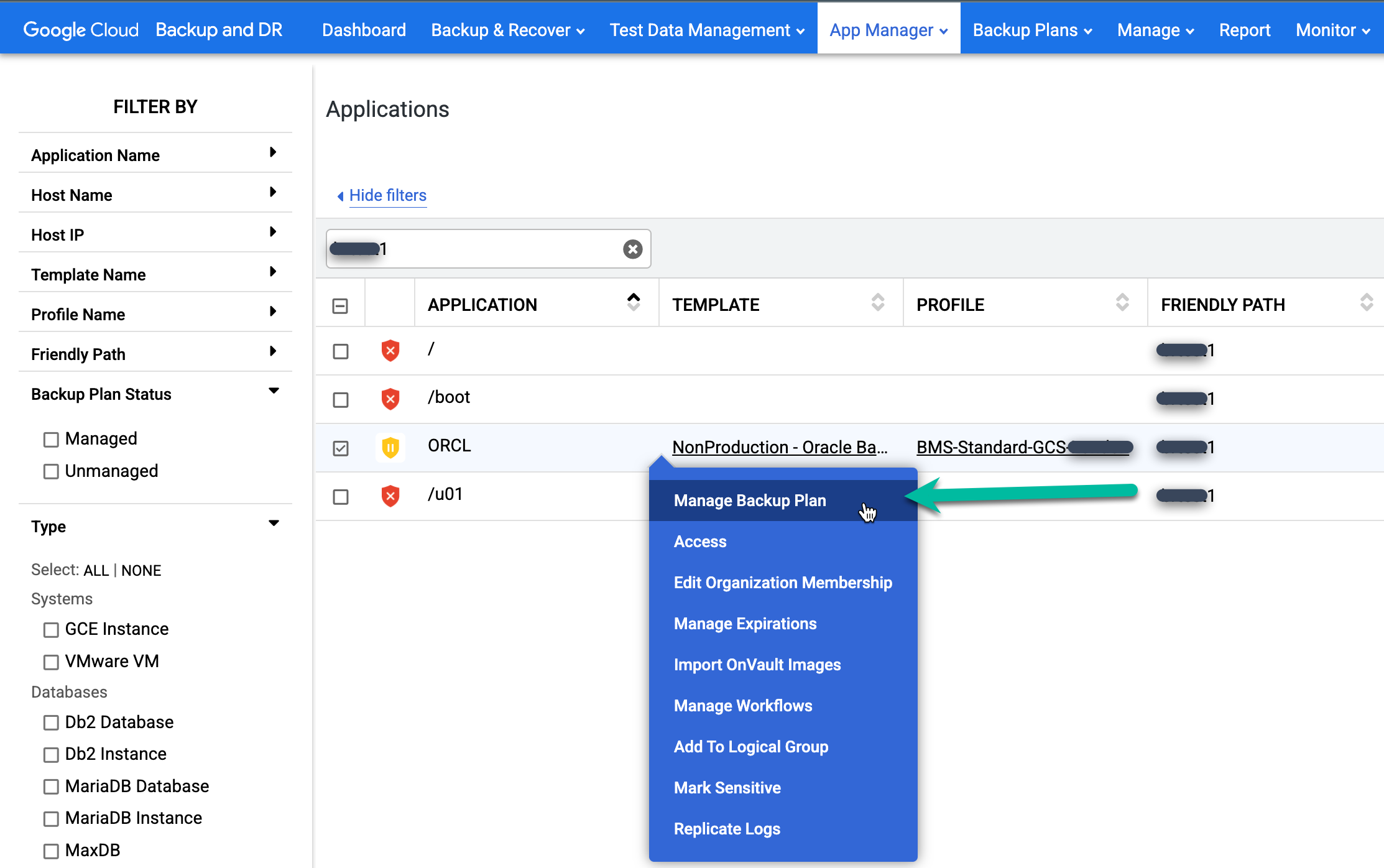
Effectuez un clic droit sur le nom de la base de données Oracle que vous souhaitez protéger, puis sélectionnez Gérer le plan de sauvegarde dans le menu.
Sélectionnez le modèle et le profil que vous souhaitez utiliser, puis cliquez sur Appliquer le plan de sauvegarde.
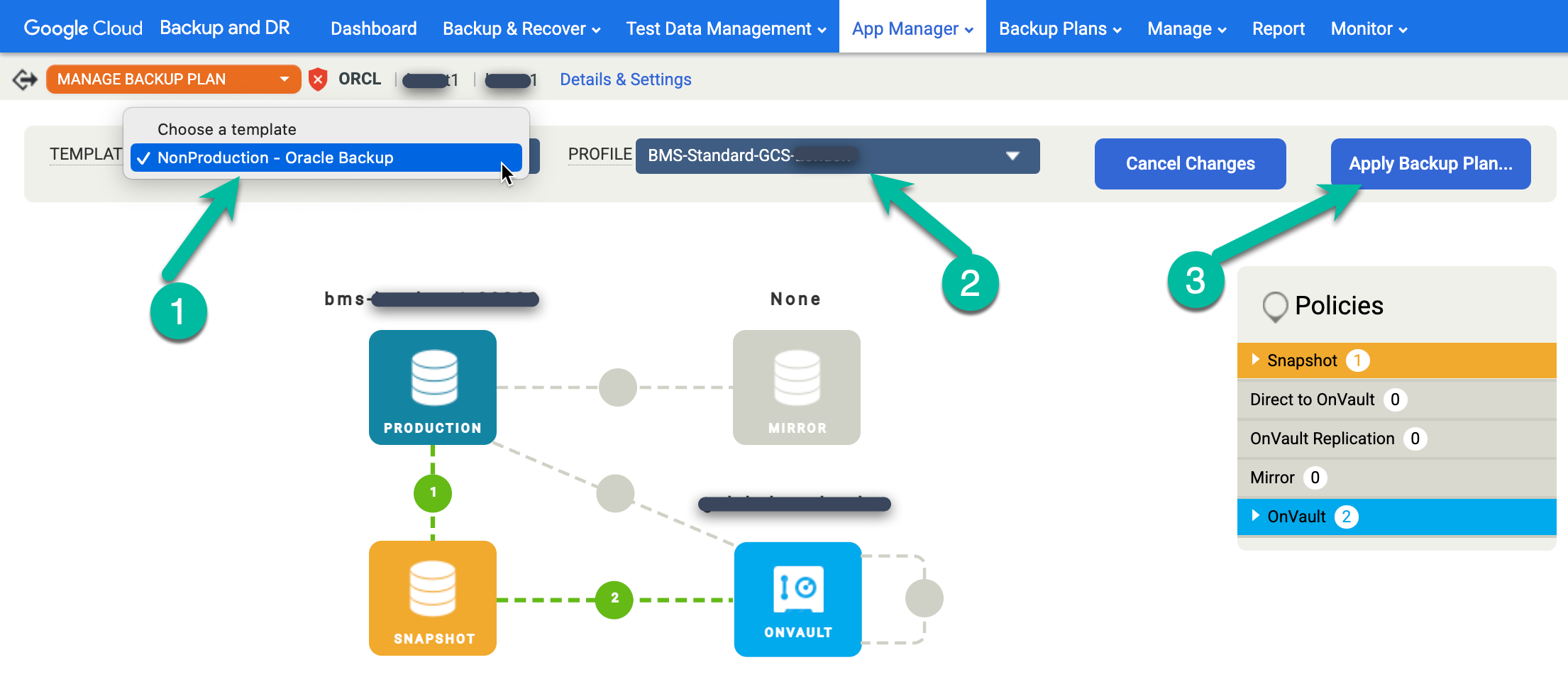
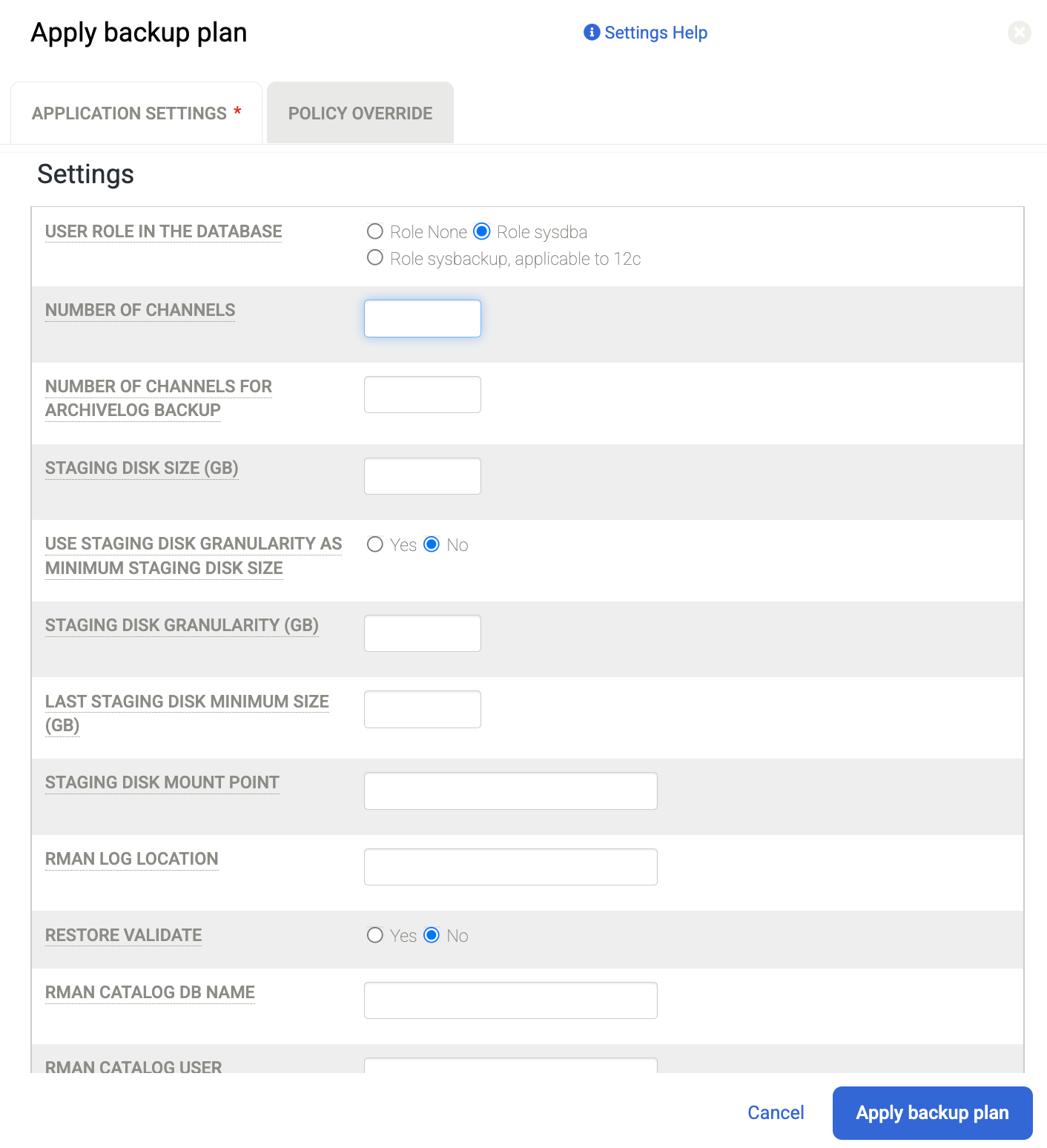
Lorsque vous y êtes invité, définissez les paramètres avancés spécifiques à Oracle et RMAN requis pour votre configuration. Lorsque vous avez terminé, cliquez sur Appliquer le plan de sauvegarde.
Par exemple, Number of Channels (Nombre de canaux) est défini par défaut sur 2. Ainsi, si vous disposez d'un grand nombre de cœurs de processeur, vous pouvez augmenter le nombre de canaux pour les opérations de sauvegarde parallèles et définir une valeur plus élevée.
Pour en savoir plus sur les paramètres avancés, consultez Configurer les détails et les paramètres de l'application pour les bases de données Oracle.
En plus de ces paramètres, vous pouvez modifier le protocole utilisé par le disque intermédiaire pour mapper le disque de l'appliance de sauvegarde à l'hôte. Accédez à la page Gérer > Hôtes, puis sélectionnez l'hôte que vous souhaitez modifier. Cochez l'option Format du disque intermédiaire pour l'invité. Par défaut, le format Block est sélectionné, ce qui mappe le disque intermédiaire via iSCSI. Vous pouvez également le remplacer par NFS, auquel cas le disque intermédiaire utilise le protocole NFS.
Les paramètres par défaut dépendent du format de votre base de données. Si vous utilisez ASM, le système utilise iSCSI pour envoyer la sauvegarde à un groupe de disques ASM. Si vous utilisez un système de fichiers, le système utilise iSCSI pour envoyer la sauvegarde à un système de fichiers. Si vous souhaitez utiliser NFS ou Direct NFS (dNFS), vous devez modifier les paramètres Hosts du disque de préparation sur NFS. En revanche, si vous utilisez le paramètre par défaut, tous les disques de préparation de la sauvegarde utilisent le format de stockage par blocs et iSCSI.
Démarrer le job de sauvegarde
Dans la console de gestion Backup and DR, accédez à la page Gestionnaire d'applications > Applications.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Effectuez un clic droit sur la base de données Oracle que vous souhaitez protéger, puis sélectionnez Gérer le plan de sauvegarde dans le menu.
Cliquez sur le menu Snapshot à droite, puis sur Run Now (Exécuter maintenant). Cette action lance un job de sauvegarde à la demande.
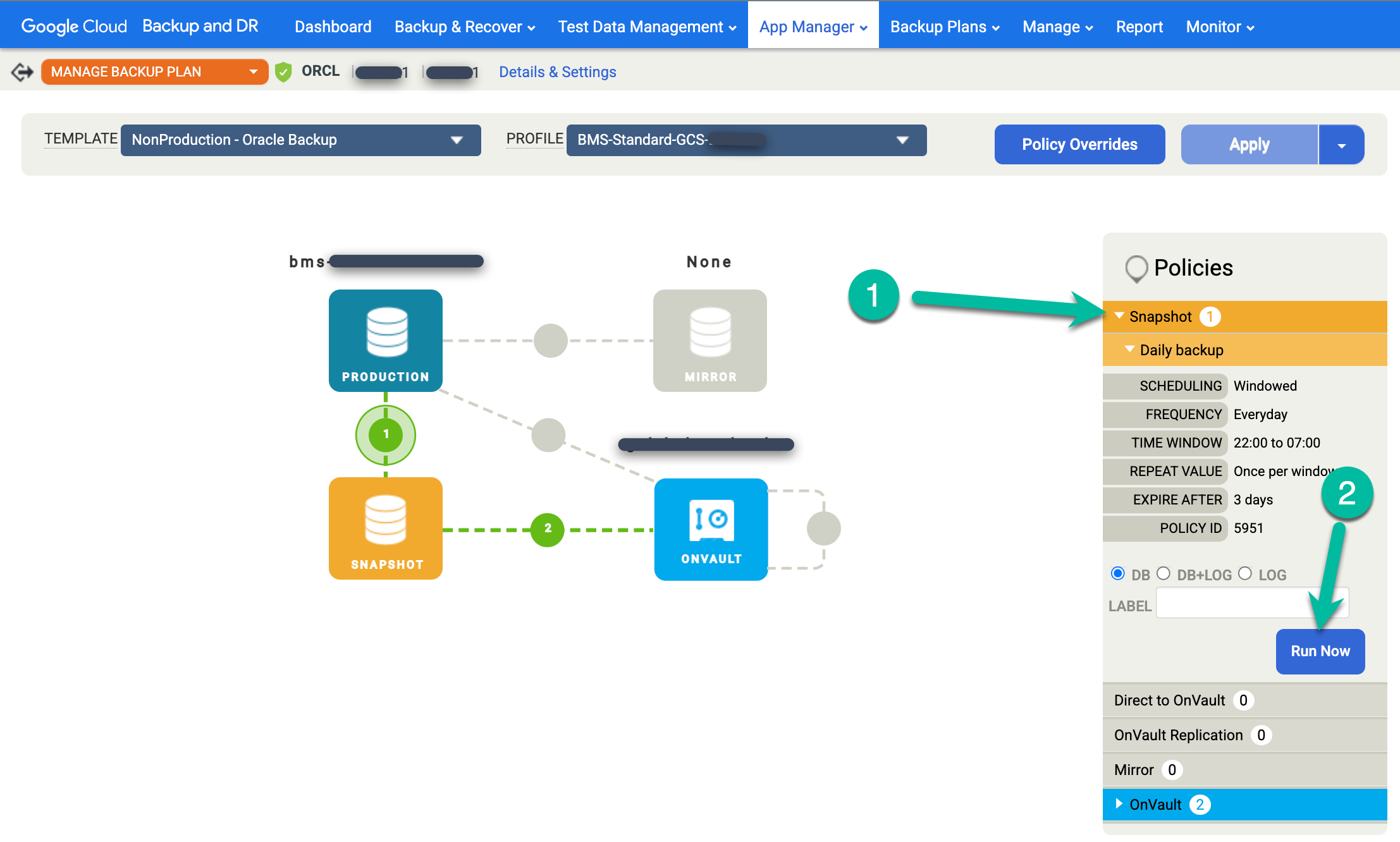
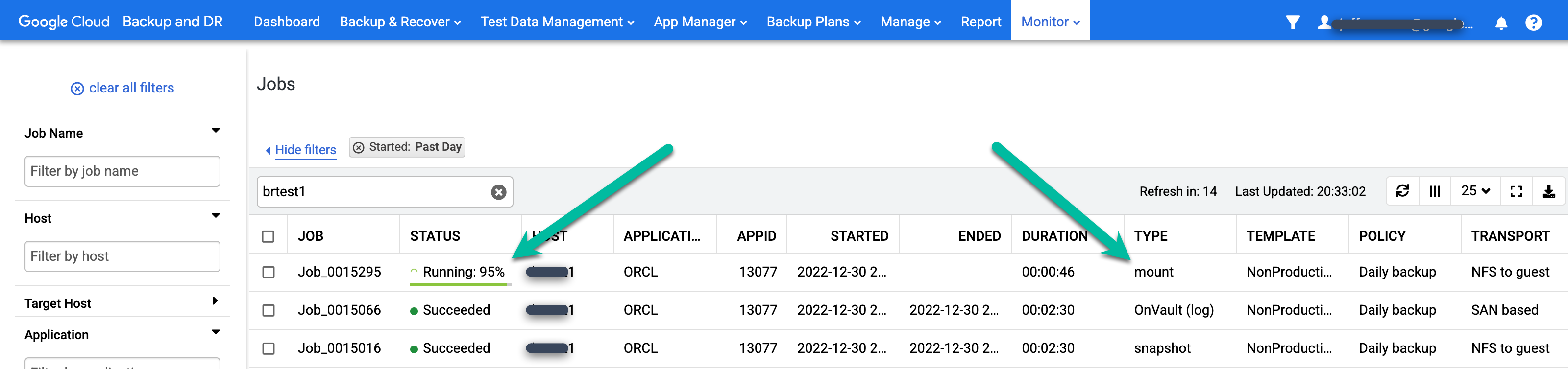
Pour surveiller l'état des tâches de sauvegarde, accédez au menu Surveiller > Tâches et consultez l'état des tâches. L'affichage d'une tâche dans la liste des tâches peut prendre entre 5 et 10 secondes. Voici un exemple de tâche en cours d'exécution :

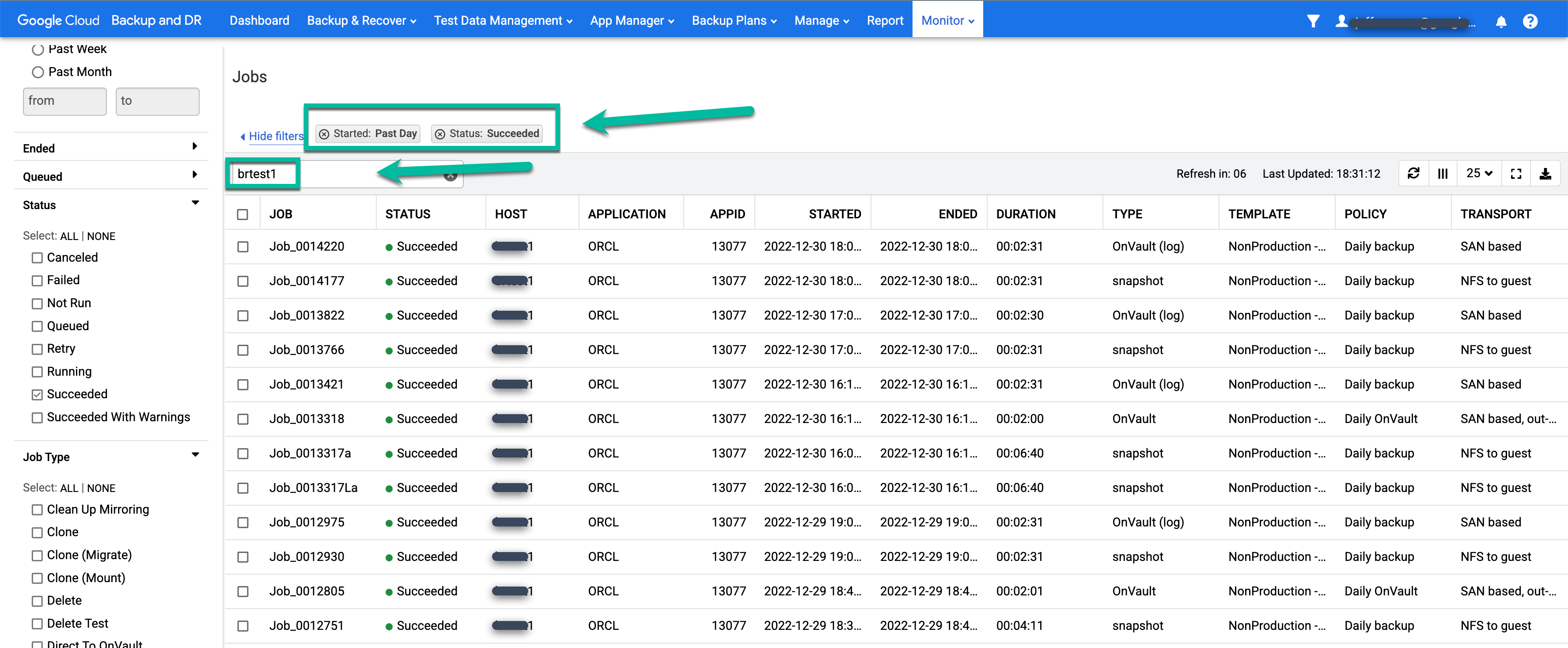
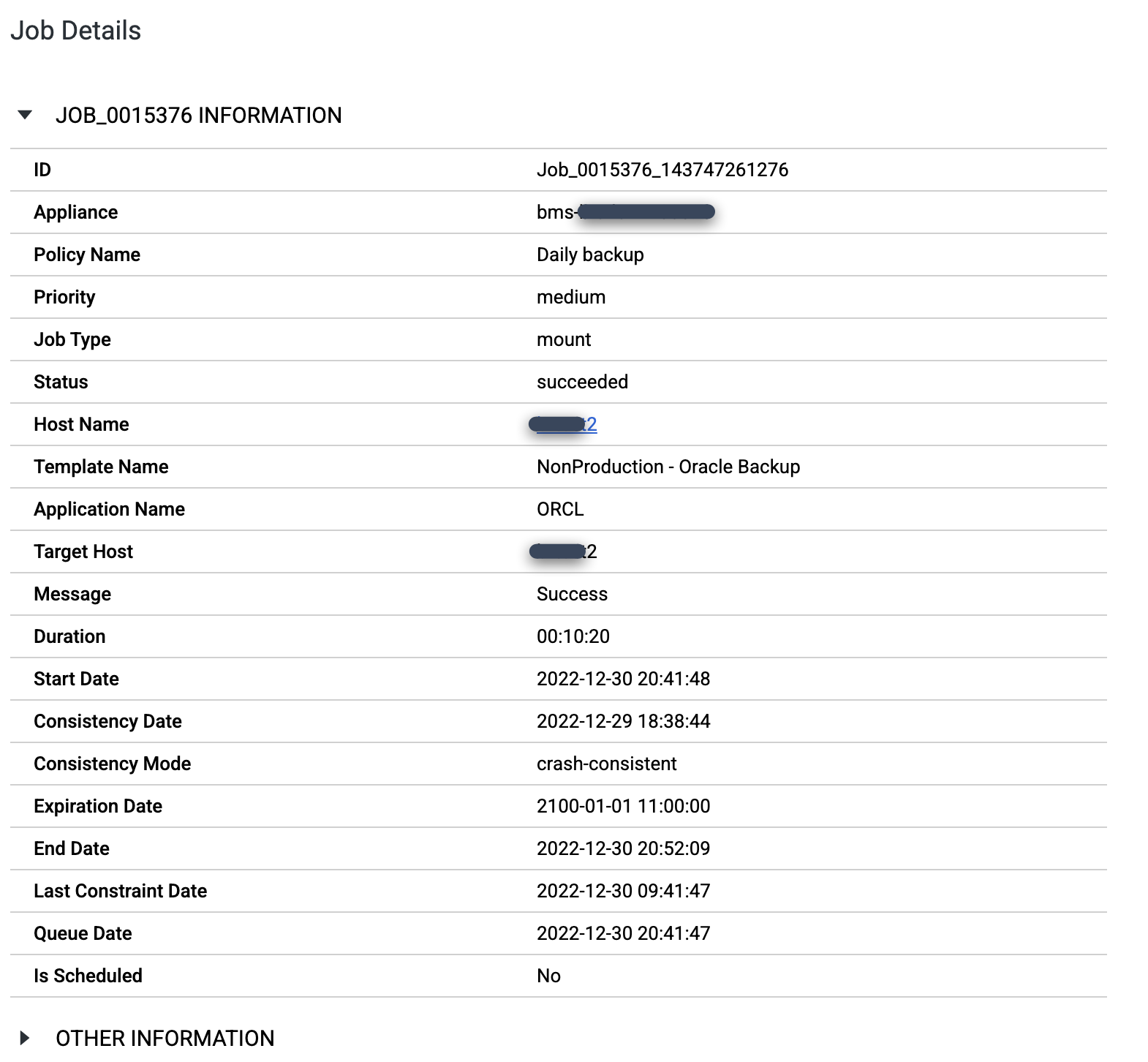
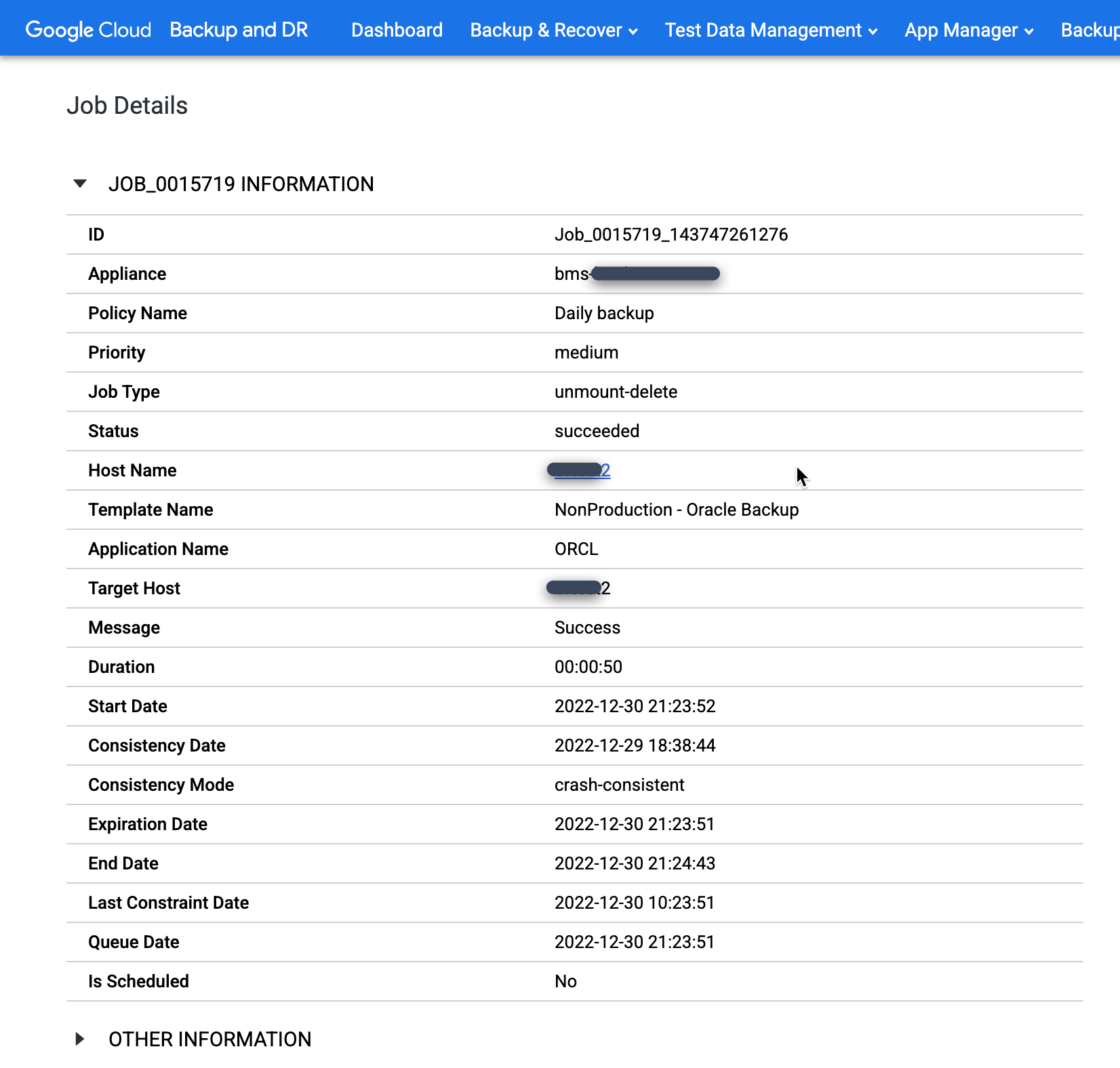
Lorsqu'un job est exécuté avec succès, vous pouvez utiliser les métadonnées pour afficher les détails d'un job spécifique.
- Appliquez des filtres et ajoutez des termes de recherche pour trouver les emplois qui vous intéressent. L'exemple suivant utilise les filtres Réussie et Jour précédent, ainsi qu'une recherche de l'hôte test1.
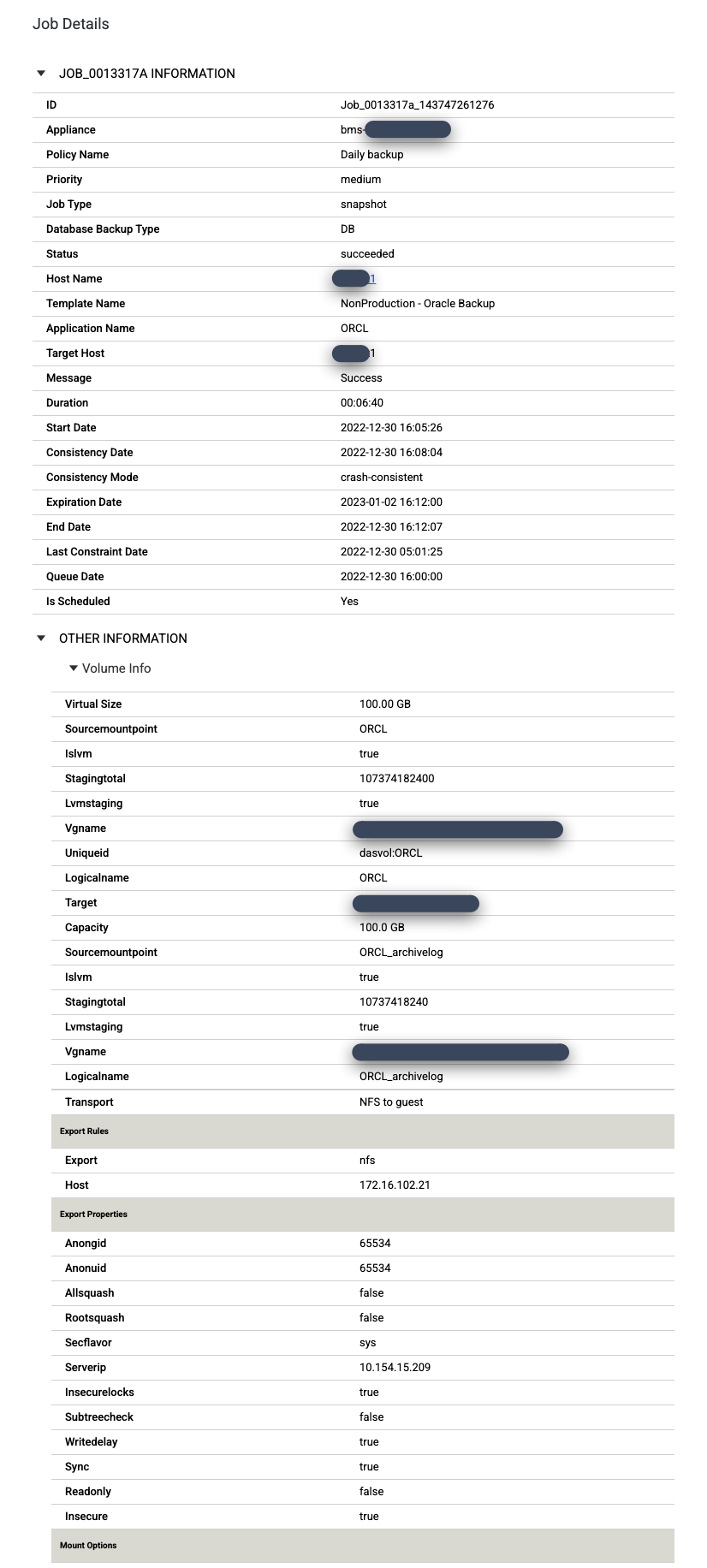
Pour examiner une tâche spécifique plus en détail, cliquez dessus dans la colonne Tâche. Dans la fenêtre qui s'ouvre, Comme vous pouvez le voir dans l'exemple suivant, chaque job de sauvegarde capture une grande quantité d'informations.
Monter et restaurer une base de données Oracle
Google Cloud Backup and DR propose plusieurs fonctionnalités permettant d'accéder à une copie d'une base de données Oracle. Voici les deux principales méthodes :
- Supports compatibles avec les applications
- Restaurations (montage et migration, et restauration traditionnelle)
Chacune de ces méthodes présente des avantages différents. Vous devez donc sélectionner celle que vous souhaitez utiliser en fonction de votre cas d'utilisation, de vos exigences en termes de performances et de la durée pendant laquelle vous devez conserver la copie de la base de données. Les sections suivantes contiennent des recommandations pour chaque fonctionnalité.
Supports compatibles avec les applications
Vous utilisez des montages pour accéder rapidement à une copie virtuelle d'une base de données Oracle. Vous pouvez configurer un montage lorsque les performances ne sont pas critiques et que la copie de la base de données n'est conservée que pendant quelques heures ou quelques jours.
L'avantage principal d'un montage est qu'il ne consomme pas de grandes quantités de stockage supplémentaire. Au lieu de cela, le montage utilise un instantané du pool de disques de sauvegarde, qui peut être un pool d'instantanés sur un disque persistant ou un pool OnVault dans Cloud Storage. L'utilisation de la fonctionnalité d'instantané de copie virtuelle minimise le temps d'accès aux données, car celles-ci n'ont pas besoin d'être copiées au préalable. Le disque de sauvegarde gère toutes les lectures, et un disque du pool d'instantanés stocke toutes les écritures. Par conséquent, les copies virtuelles montées sont rapidement accessibles et n'écrasent pas la copie du disque de sauvegarde. Les montages sont idéaux pour les activités de développement, de test et d'administrateur de base de données, où les modifications ou mises à jour de schéma doivent être validées avant d'être déployées en production.
Monter une base de données Oracle
Dans la console de gestion Backup and DR, accédez à la page Sauvegarder et restaurer > Restaurer.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
Dans la liste Application, recherchez la base de données que vous souhaitez associer, effectuez un clic droit sur son nom, puis cliquez sur Suivant :
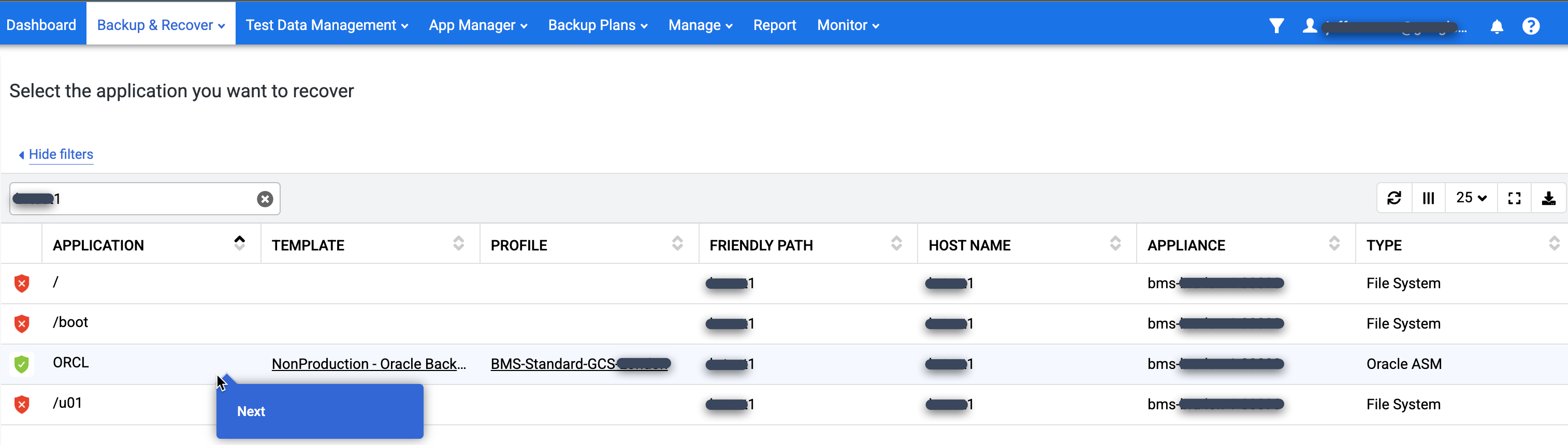
La vue de la rampe chronologique s'affiche et présente toutes les images ponctuelles disponibles. Vous pouvez également faire défiler l'écran vers le bas pour afficher les images de conservation à long terme si elles n'apparaissent pas dans la vue en rampe. Le système sélectionne la dernière image par défaut.
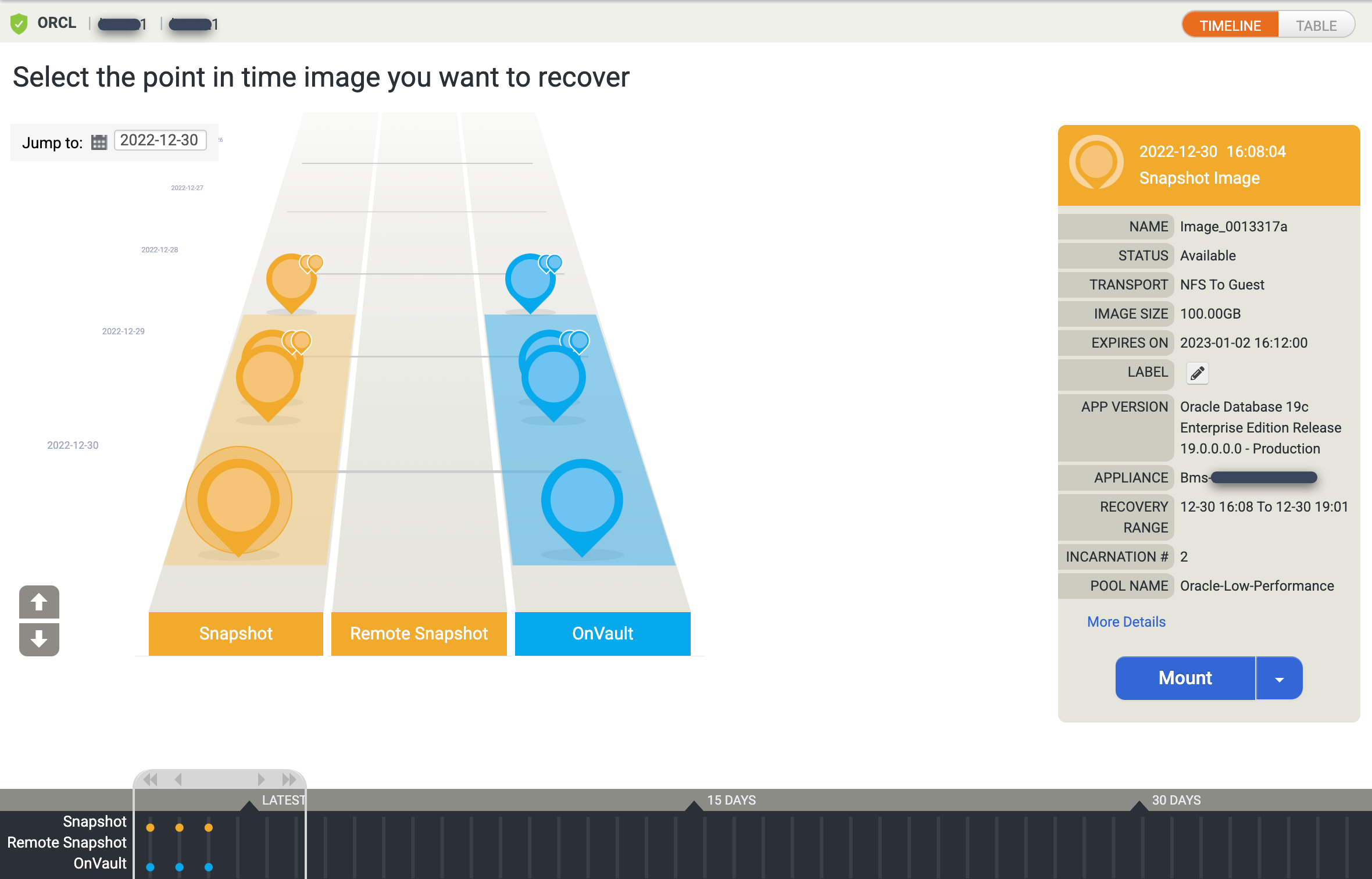
Si vous préférez afficher les images ponctuelles sous forme de vue Tableau, cliquez sur l'option Table pour modifier la vue :
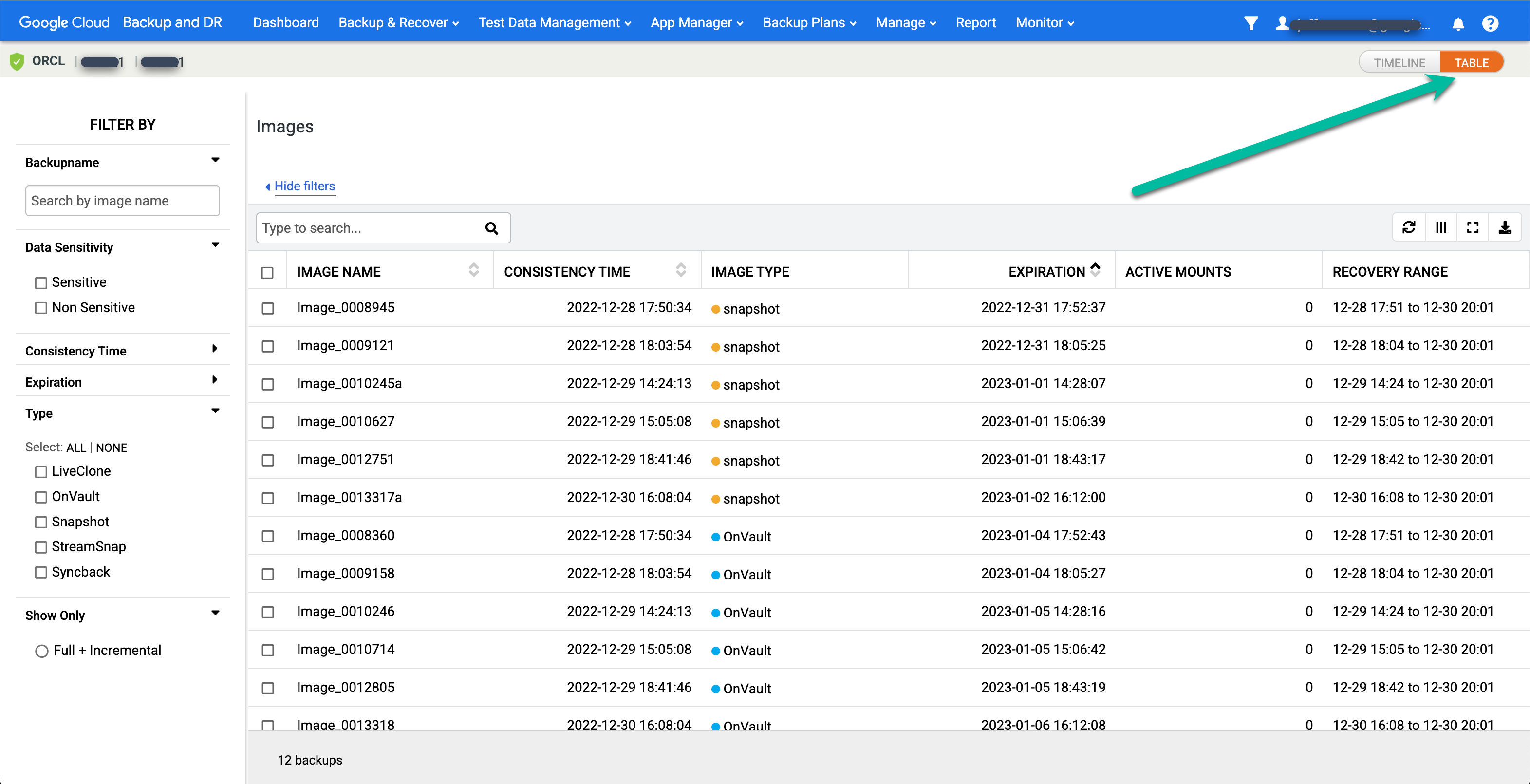
Recherchez l'image de votre choix, puis sélectionnez Monter :
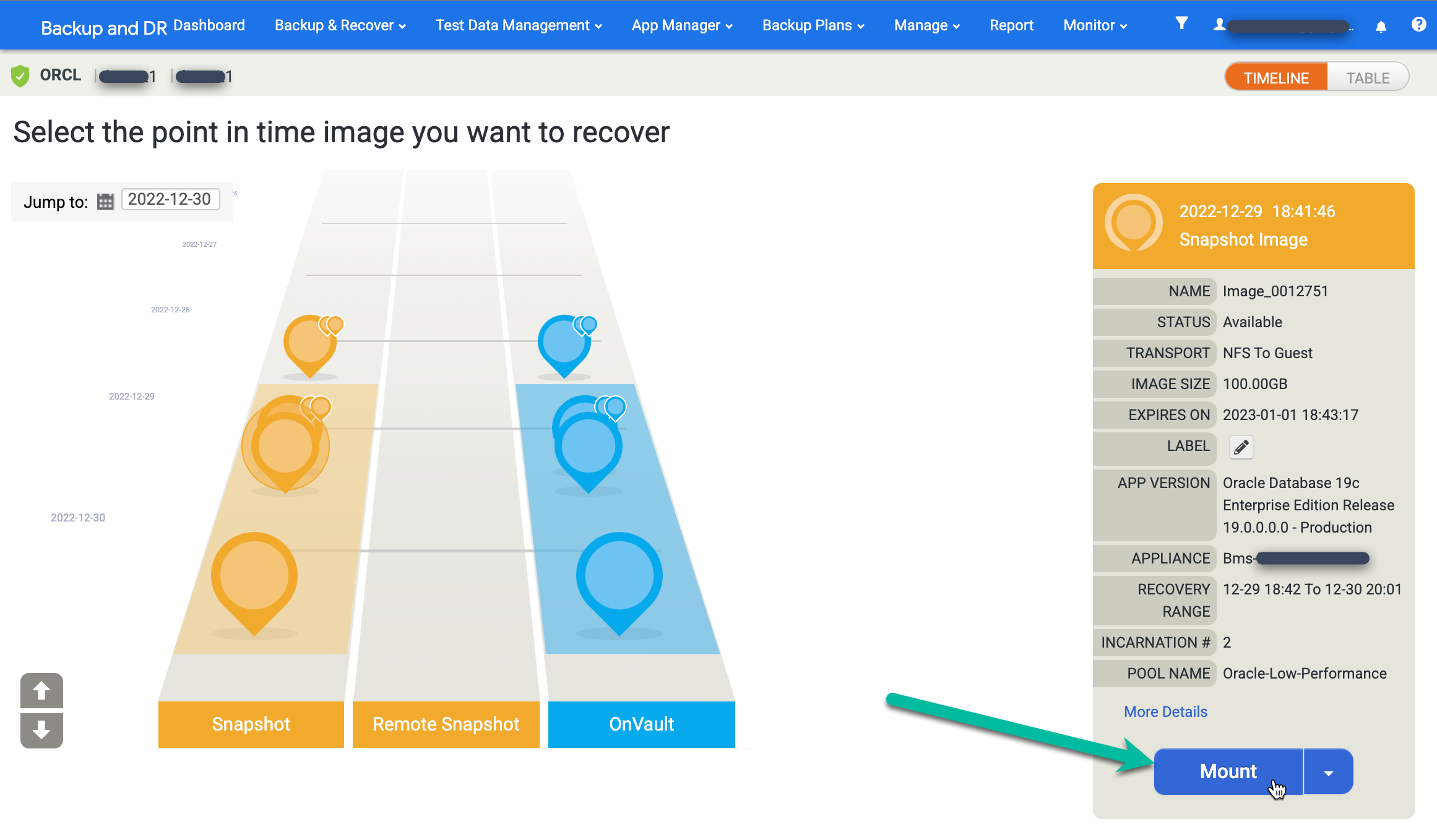
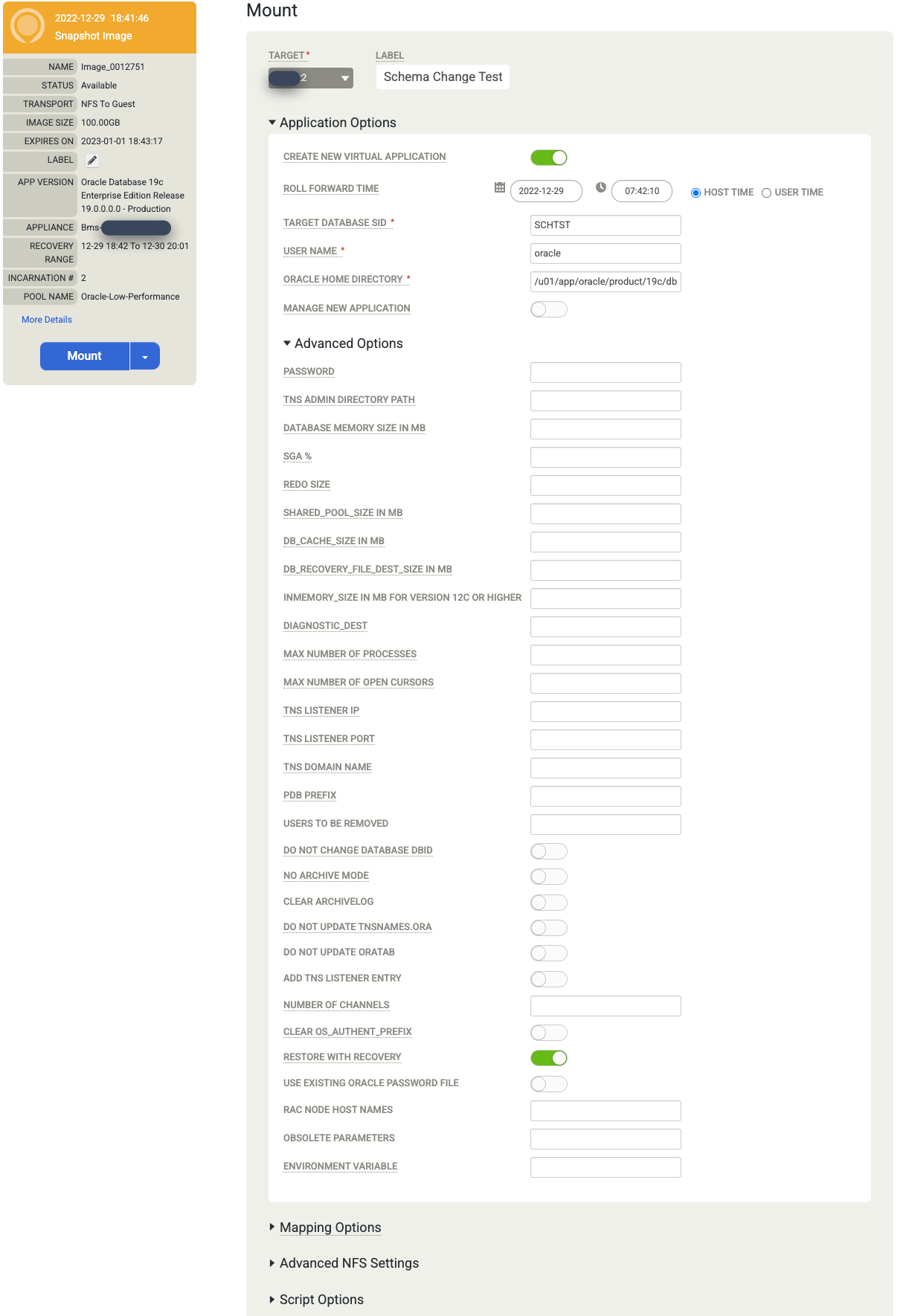
Choisissez les options d'application pour la base de données que vous installez.
- Sélectionnez l'hôte cible dans le menu déroulant. Les hôtes apparaissent dans cette liste si vous les avez ajoutés précédemment.
- (Facultatif) Saisissez un libellé.
- Dans le champ Target Database SID (SID de la base de données cible), saisissez l'identifiant de la base de données cible.
- Définissez le nom d'utilisateur sur "oracle". Ce nom devient le nom d'utilisateur de l'OS pour l'authentification.
- Saisissez le répertoire de base Oracle. Pour cet exemple, utilisez
/u01/app/oracle/product/19c/dbhome_1. - Si vous configurez la sauvegarde des journaux de base de données, l'option Roll Forward Time (Heure de restauration) devient disponible. Cliquez sur le sélecteur d'horloge/de date et choisissez le point de report.
- L'option Restaurer avec la récupération est activée par défaut. Cette option monte et ouvre la base de données pour vous.
Lorsque vous avez terminé de saisir les informations, cliquez sur Envoyer pour lancer le processus de montage.
Surveiller la progression et la réussite des tâches
Vous pouvez surveiller le job en cours d'exécution en accédant à la page Surveiller > Jobs.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
La page affiche l'état et le type de tâche.
Une fois la tâche de montage terminée, vous pouvez afficher ses détails en cliquant sur le numéro de tâche :
Pour afficher les processus pmon pour le SID que vous avez créé, connectez-vous à l'hôte cible et exécutez la commande
ps -ef |grep pmon. Dans l'exemple de sortie suivant, la base de données SCHTEST est opérationnelle et possède un ID de processus de 173953.[root@test2 ~]# ps -ef |grep pmon oracle 1382 1 0 Dec23 ? 00:00:28 asm_pmon_+ASM oracle 56889 1 0 Dec29 ? 00:00:06 ora_pmon_ORCL oracle 173953 1 0 09:51 ? 00:00:00 ora_pmon_SCHTEST root 178934 169484 0 10:07 pts/0 00:00:00 grep --color=auto pmon
Démonter une base de données Oracle
Une fois que vous avez fini d'utiliser la base de données, vous devez la démonter et la supprimer. Il existe deux méthodes pour trouver une base de données associée :
Accédez à la page Gestionnaire d'applications > Montages actifs.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#activemounts
Cette page contient une vue globale de toutes les applications montées (systèmes de fichiers et bases de données) actuellement utilisées.
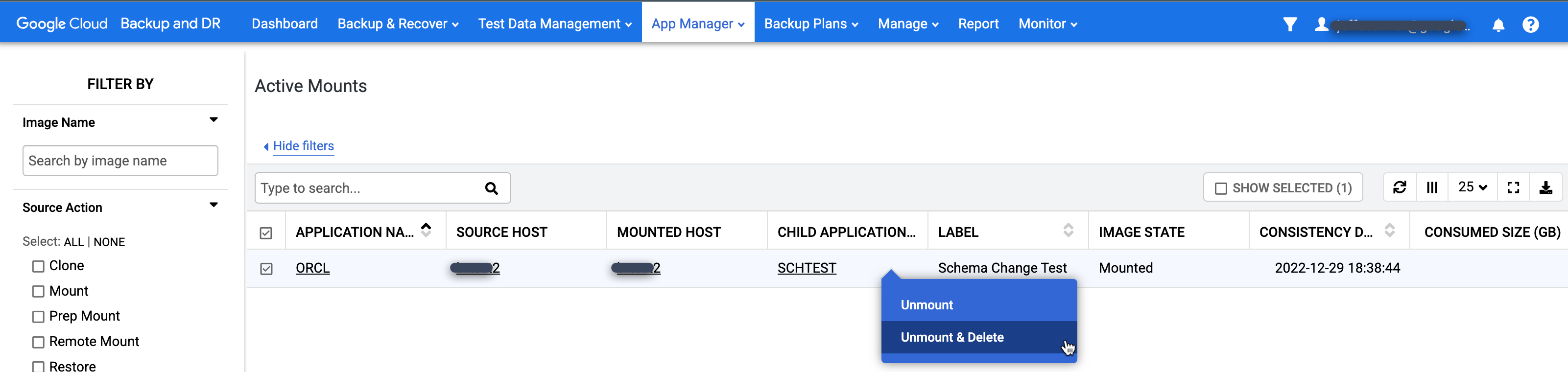
Effectuez un clic droit sur le montage que vous souhaitez supprimer, puis sélectionnez Démonter et supprimer dans le menu. Cette action ne supprimera pas les données de sauvegarde. Il ne supprime que la base de données virtuelle montée de l'hôte cible et le disque de cache d'instantané qui contenait les écritures stockées pour la base de données.
Accédez à la page Gestionnaire d'applications > Applications.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
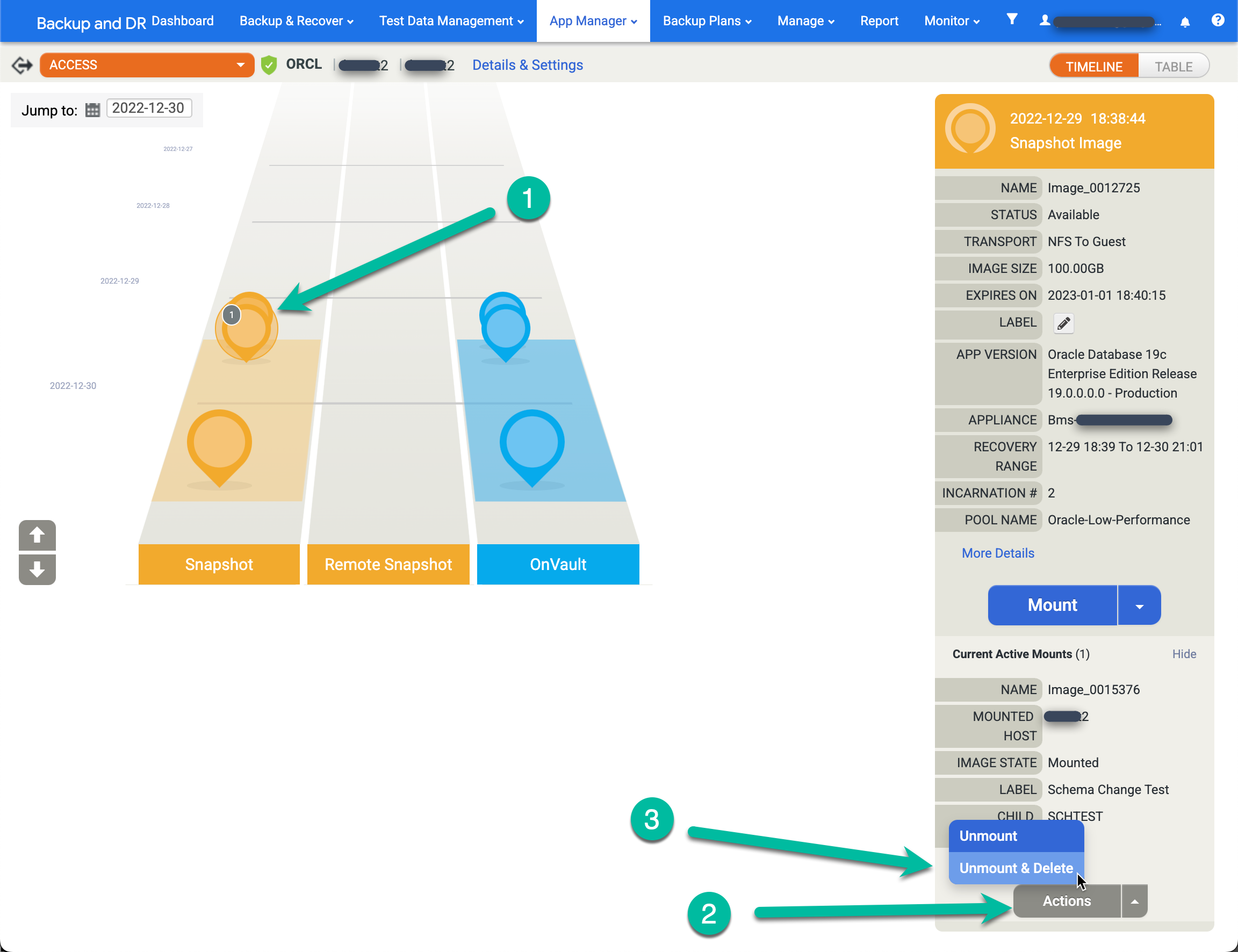
- Effectuez un clic droit sur l'application source (base de données), puis sélectionnez Accès.
- Sur la rampe de gauche, vous voyez un cercle gris avec un nombre à l'intérieur qui indique le nombre de supports actifs à partir de ce moment. Cliquez sur cette image pour faire apparaître un nouveau menu.
- Cliquez sur Actions.
- Cliquez sur Démonter et supprimer.
- Cliquez sur Envoyer, puis confirmez cette action sur l'écran suivant.
Quelques minutes plus tard, le système supprime la base de données de l'hôte cible, puis nettoie et supprime tous les disques. Cette action libère l'espace disque du pool de snapshots utilisé pour les écritures sur le disque de redo pour les montages actifs.
Vous pouvez surveiller les tâches non montées comme n'importe quelle autre tâche. Accédez au menu Surveillance > Jobs pour surveiller la progression du job de démontage et confirmer qu'il se termine.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
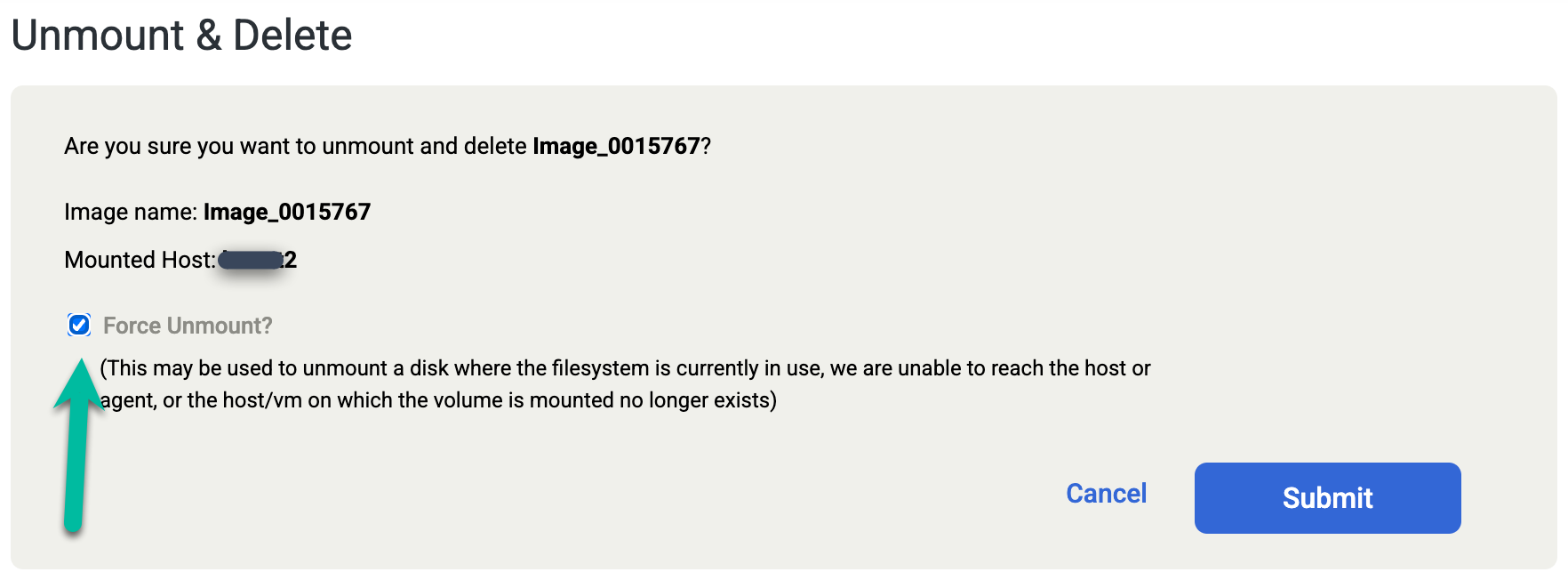
Si vous supprimez accidentellement la base de données Oracle manuellement ou si vous l'arrêtez avant d'exécuter le job Démonter et supprimer, exécutez à nouveau le job Démonter et supprimer et sélectionnez l'option Forcer le démontage sur l'écran de confirmation. Cette action supprime de force le disque de préparation de la rétablissement de l'hôte cible et supprime le disque du pool d'instantanés.
Restaurations
Vous utilisez les restaurations pour récupérer les bases de données de production en cas de problème ou de corruption. Vous devez alors copier tous les fichiers de la base de données sur un hôte local à partir d'une copie de sauvegarde. Vous effectuez normalement une restauration après un événement de type sinistre ou pour des copies de test non destinées à la production. Dans ce cas, vos clients doivent généralement attendre que vous copiez les fichiers précédents sur l'hôte source avant de redémarrer leurs bases de données. Toutefois, la sauvegarde et la reprise après sinistre de Google Cloud sont également compatibles avec une fonctionnalité de restauration (copie de fichiers et démarrage de la base de données), ainsi qu'avec une fonctionnalité de montage et de migration, qui vous permet de monter la base de données (le temps d'accès est rapide) et de copier les fichiers de données sur la machine locale pendant que la base de données est montée et accessible. La fonctionnalité Installer et migrer est utile pour les scénarios à faible objectif de temps de récupération (RTO).
Monter et migrer
La récupération basée sur le montage et la migration comporte deux phases :
- Phase 1 : la phase d'installation de la restauration permet d'accéder instantanément à la base de données en commençant par la copie installée.
- Phase 2 : la phase de migration de la restauration migre la base de données vers l'emplacement de stockage de production lorsque la base de données est en ligne.
Restaurer le montage : phase 1
Cette phase vous donne un accès instantané à la base de données à partir d'une image sélectionnée présentée par l'appliance de sauvegarde/restauration.
- Une copie de l'image de sauvegarde sélectionnée est mappée sur le serveur de base de données cible et présentée à la couche ASM ou du système de fichiers en fonction du format de l'image de sauvegarde de la base de données source.
- Utilisez l'API RMAN pour effectuer les tâches suivantes :
- Restaurez le fichier de contrôle et le fichier journal de rétablissement à l'emplacement local spécifié pour le fichier de contrôle et le fichier de rétablissement (groupe de disques ASM ou système de fichiers).
- Basculez la base de données vers la copie de l'image présentée par l'appliance de sauvegarde/récupération.
- Effectue une restauration de tous les journaux d'archive disponibles jusqu'au point de récupération spécifié.
- Ouvrez la base de données en mode lecture et écriture.
- La base de données s'exécute à partir de la copie mappée de l'image de sauvegarde présentée par l'appliance de sauvegarde/restauration.
- Le fichier de contrôle et le fichier journal de rétablissement de la base de données sont placés dans l'emplacement de stockage de production local sélectionné (groupe de disques ASM ou système de fichiers) sur la cible.
- Une fois l'opération de restauration et de montage terminée, la base de données devient disponible pour les opérations de production. Vous pouvez utiliser l'API Oracle de déplacement en ligne des fichiers de données pour déplacer les données vers l'emplacement de stockage de production (groupe de disques ASM ou système de fichiers) pendant que la base de données et l'application sont en cours d'exécution.
Restauration de la migration : phase 2
Déplace le fichier de données de la base de données en ligne vers le stockage de production :
- La migration des données s'exécute en arrière-plan. Utilisez l'API Oracle de déplacement en ligne des fichiers de données pour migrer les données.
- Vous déplacez les fichiers de données de la copie de l'image de sauvegarde présentée par Backup and DR vers le stockage de la base de données cible sélectionnée (groupe de disques ASM ou système de fichiers).
- Une fois le job de migration terminé, le système supprime et dissocie la copie de l'image de sauvegarde présentée par Backup and DR (groupe de disques ASM ou système de fichiers) de la cible, et la base de données s'exécute à partir de votre stockage de production.
Pour en savoir plus sur la récupération par montage et migration, consultez Monter et migrer une image de sauvegarde Oracle pour une récupération instantanée vers n'importe quelle cible.
Restaurer une base de données Oracle
Dans la console de gestion Backup and DR, accédez à la page Sauvegarde et récupération > Récupérer.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
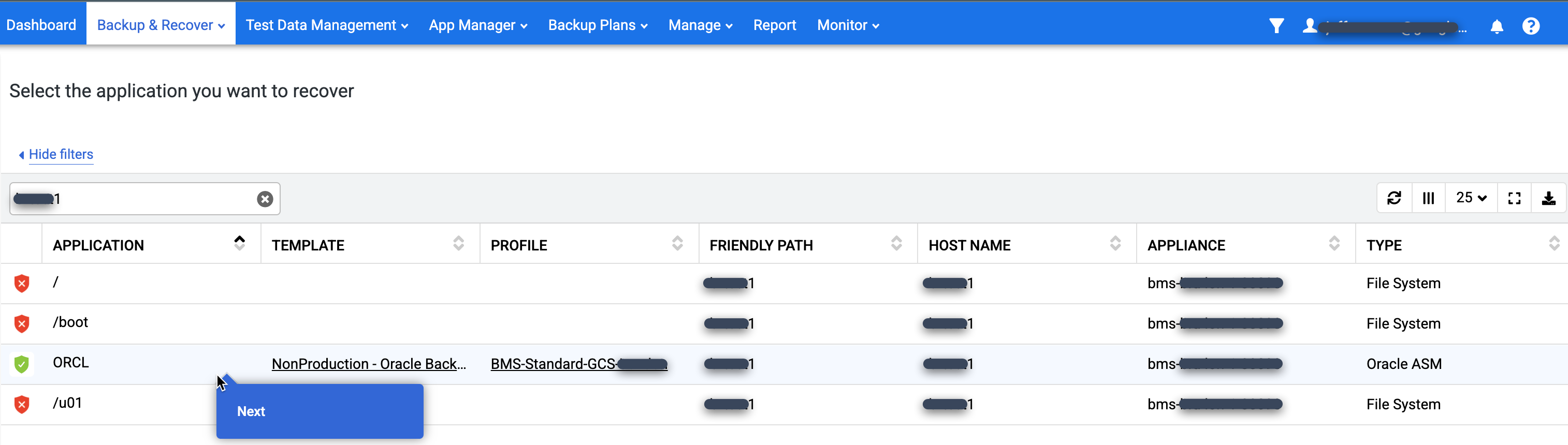
Dans la liste Application, effectuez un clic droit sur le nom de la base de données que vous souhaitez restaurer, puis sélectionnez Suivant :
La vue de la rampe chronologique s'affiche et présente toutes les images ponctuelles disponibles. Vous pouvez également faire défiler l'écran vers le haut si vous devez afficher les images de conservation à long terme qui n'apparaissent pas dans la rampe. Le système sélectionne toujours la dernière image par défaut.
Pour restaurer une image, cliquez sur le menu Monter et sélectionnez Restaurer :
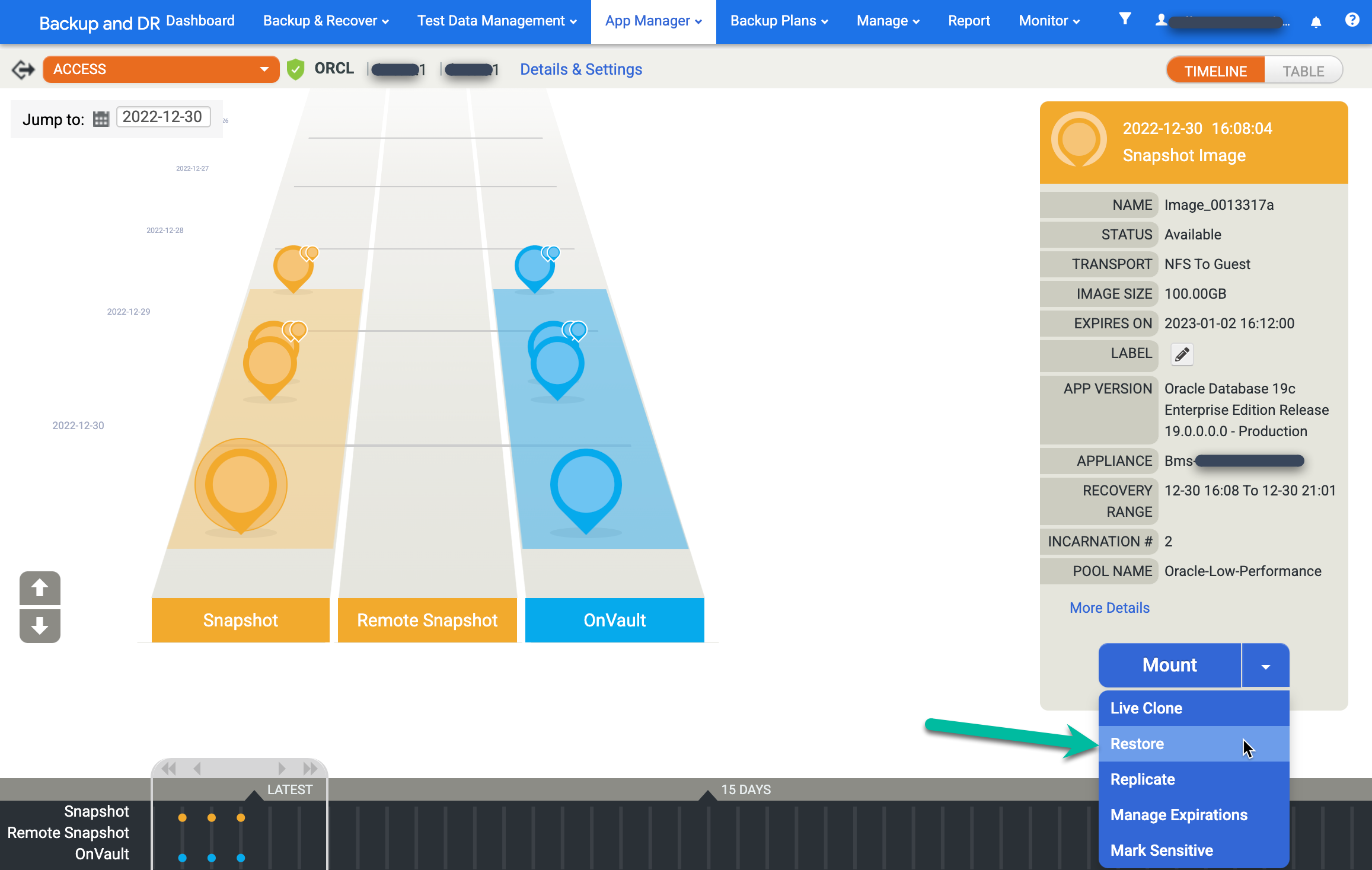
Choisissez vos options de restauration.
- Sélectionnez Heure de report. Cliquez sur l'horloge et sélectionnez le point dans le temps souhaité.
- Saisissez le nom d'utilisateur que vous prévoyez d'utiliser pour Oracle.
- Si votre système utilise l'authentification par base de données, saisissez un mot de passe.
Pour démarrer le job, cliquez sur Envoyer.
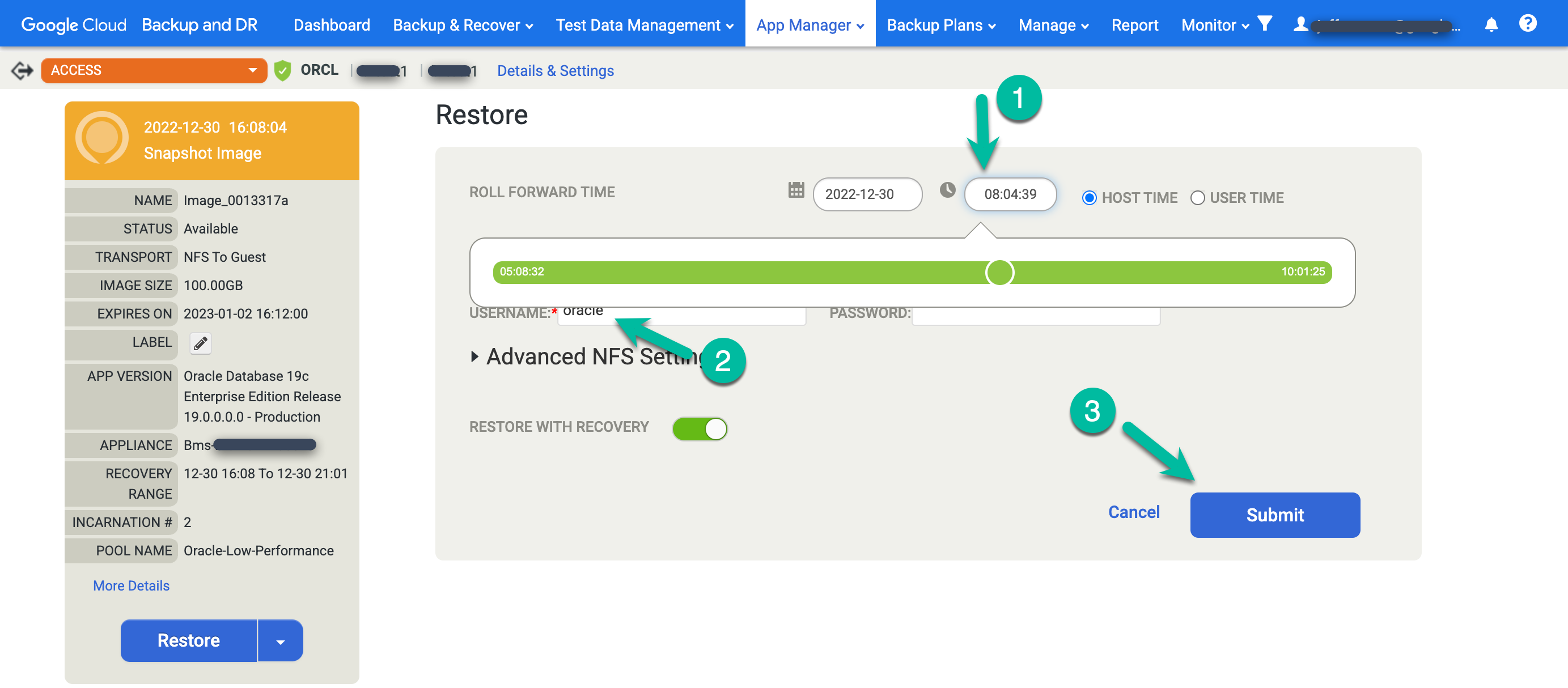
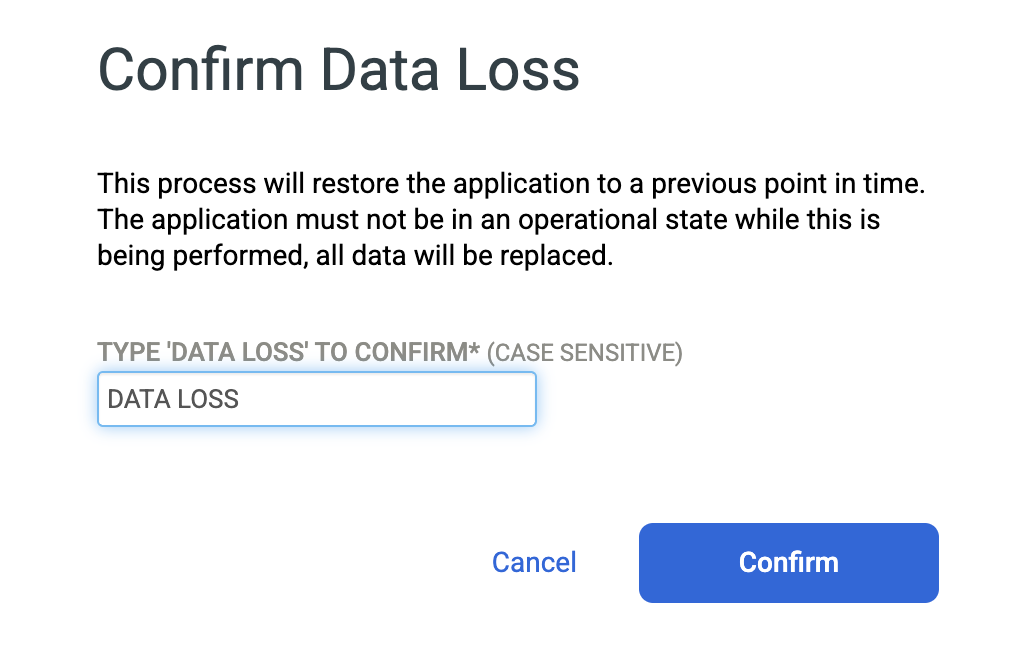
Saisissez PERTE DE DONNÉES pour confirmer que vous souhaitez écraser la base de données source, puis cliquez sur Confirmer.
Surveiller la progression et la réussite des tâches
Pour surveiller le job, accédez à la page Surveiller > Jobs.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
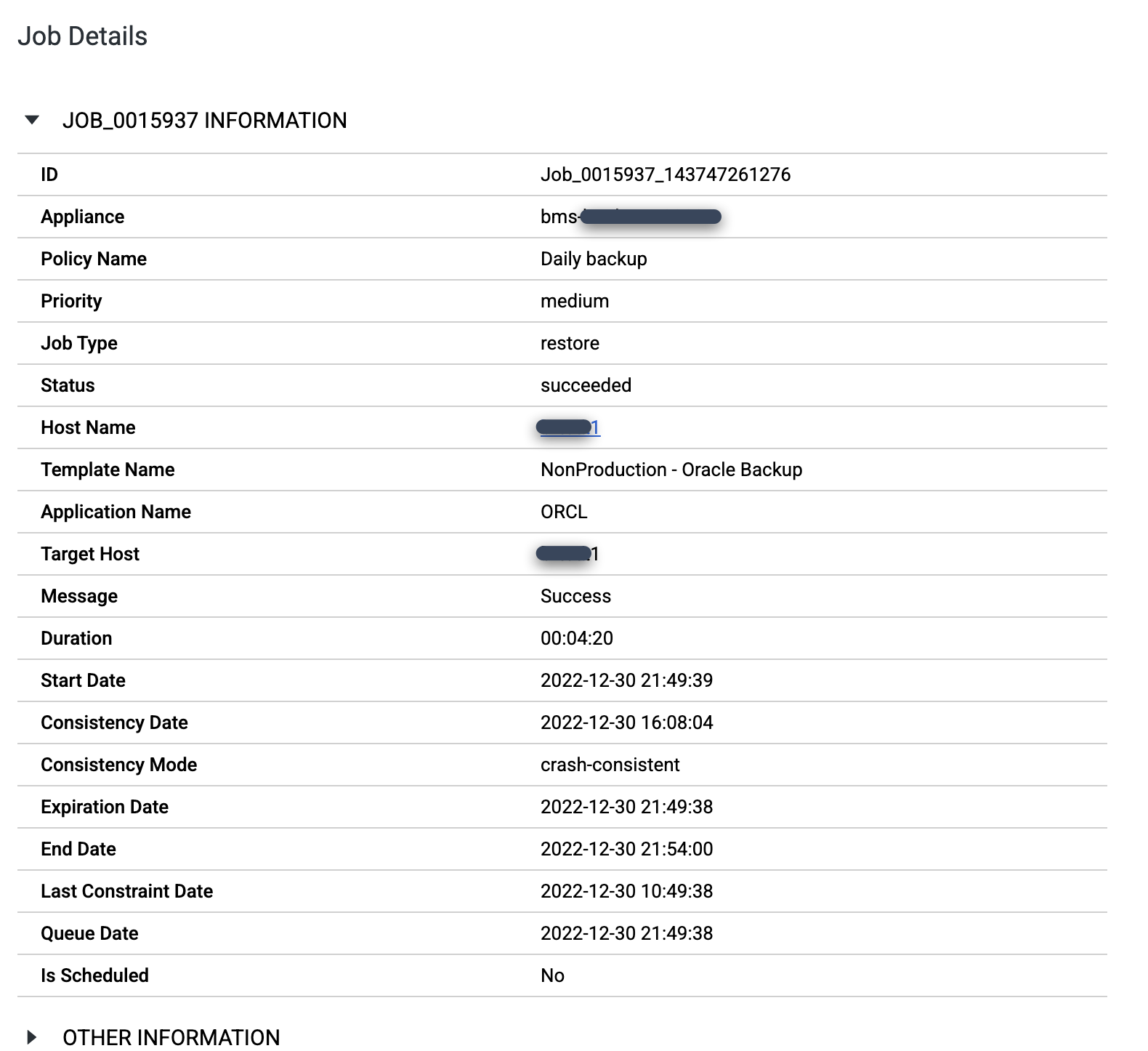
Lorsque la tâche est terminée, cliquez sur le numéro de tâche pour examiner les détails et les métadonnées de la tâche.
Protéger la base de données restaurée
Une fois le job de restauration de la base de données terminé, le système ne sauvegarde pas automatiquement la base de données après sa restauration. En d'autres termes, lorsque vous restaurez une base de données qui disposait auparavant d'un plan de sauvegarde, celui-ci ne s'active pas par défaut.
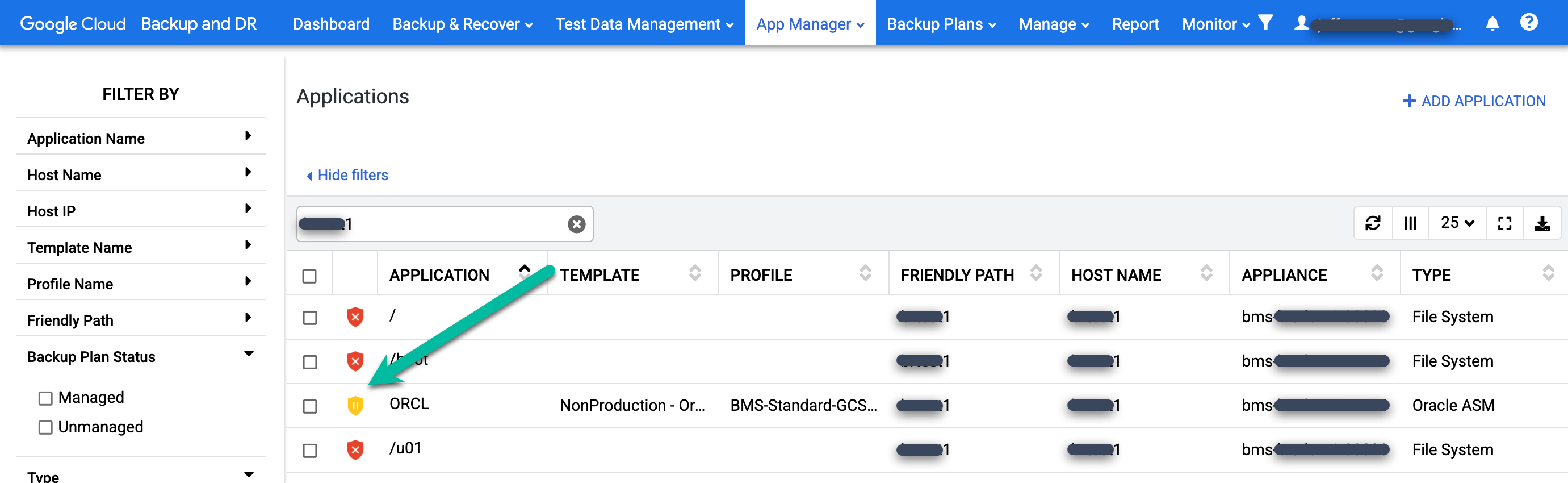
Pour vérifier que le plan de sauvegarde n'est pas en cours d'exécution, accédez à la page Gestionnaire d'applications > Applications.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Recherchez la base de données restaurée dans la liste. L'icône de protection passe du vert au jaune, ce qui indique que le système n'est pas programmé pour exécuter des tâches de sauvegarde pour la base de données.
Pour protéger la base de données restaurée, recherchez la base de données que vous souhaitez protéger dans la colonne Application. Effectuez un clic droit sur le nom de la base de données, puis sélectionnez Gérer le plan de sauvegarde.
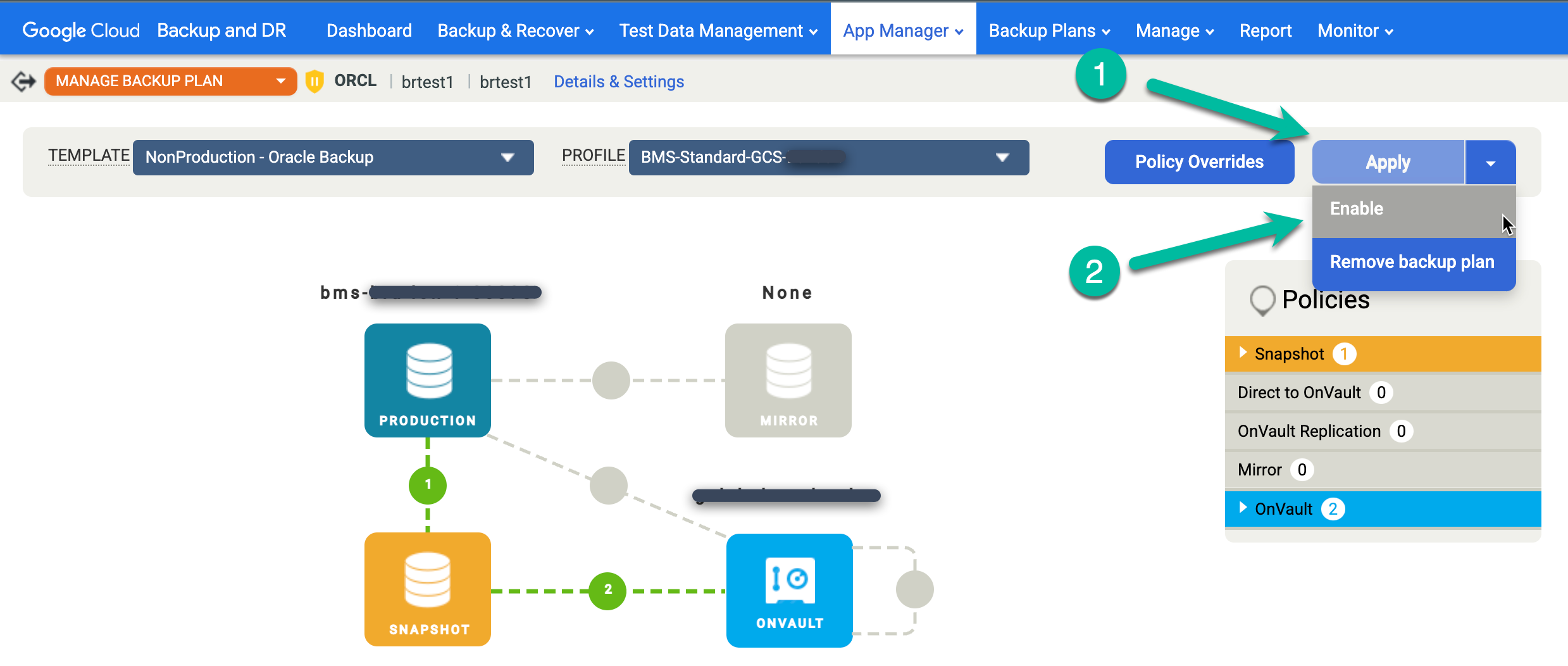
Réactivez le job de sauvegarde planifiée pour la base de données restaurée.
- Cliquez sur le menu Appliquer, puis sélectionnez Activer.
Confirmez les paramètres avancés Oracle, puis cliquez sur Activer le plan de sauvegarde.
Dépannage et optimisation
Cette section fournit quelques conseils utiles pour vous aider à résoudre les problèmes liés à vos sauvegardes Oracle, à optimiser votre système et à envisager des ajustements pour les environnements RAC et Data Guard.
Résoudre les problèmes de sauvegarde Oracle
Les configurations Oracle contiennent un certain nombre de dépendances pour garantir la réussite de la tâche de sauvegarde. Les étapes suivantes fournissent plusieurs suggestions pour configurer les instances, les écouteurs et les bases de données Oracle afin d'assurer le succès de la migration.
Pour vérifier que l'écouteur Oracle du service et de l'instance que vous souhaitez protéger est configuré et en cours d'exécution, exécutez la commande
lsnrctl status:[oracle@test2 lib]$ lsnrctl status LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:43:37 Copyright (c) 1991, 2021, Oracle. All rights reserved. Connecting to (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521)) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 23-DEC-2022 20:34:17 Uptime 5 days 11 hr. 9 min. 20 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/19c/grid/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/test2/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=test2.localdomain)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Services Summary... Service "+ASM" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "+ASM_DATADG" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "ORCL" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "ORCLXDB" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "f085620225d644e1e053166610ac1c27" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "orclpdb" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... The command completed successfully
Vérifiez que vous avez configuré la base de données Oracle en mode ARCHIVELOG. Si la base de données s'exécute dans un autre mode, il est possible que des tâches échouent et que le message Code d'erreur 5556 s'affiche comme suit :
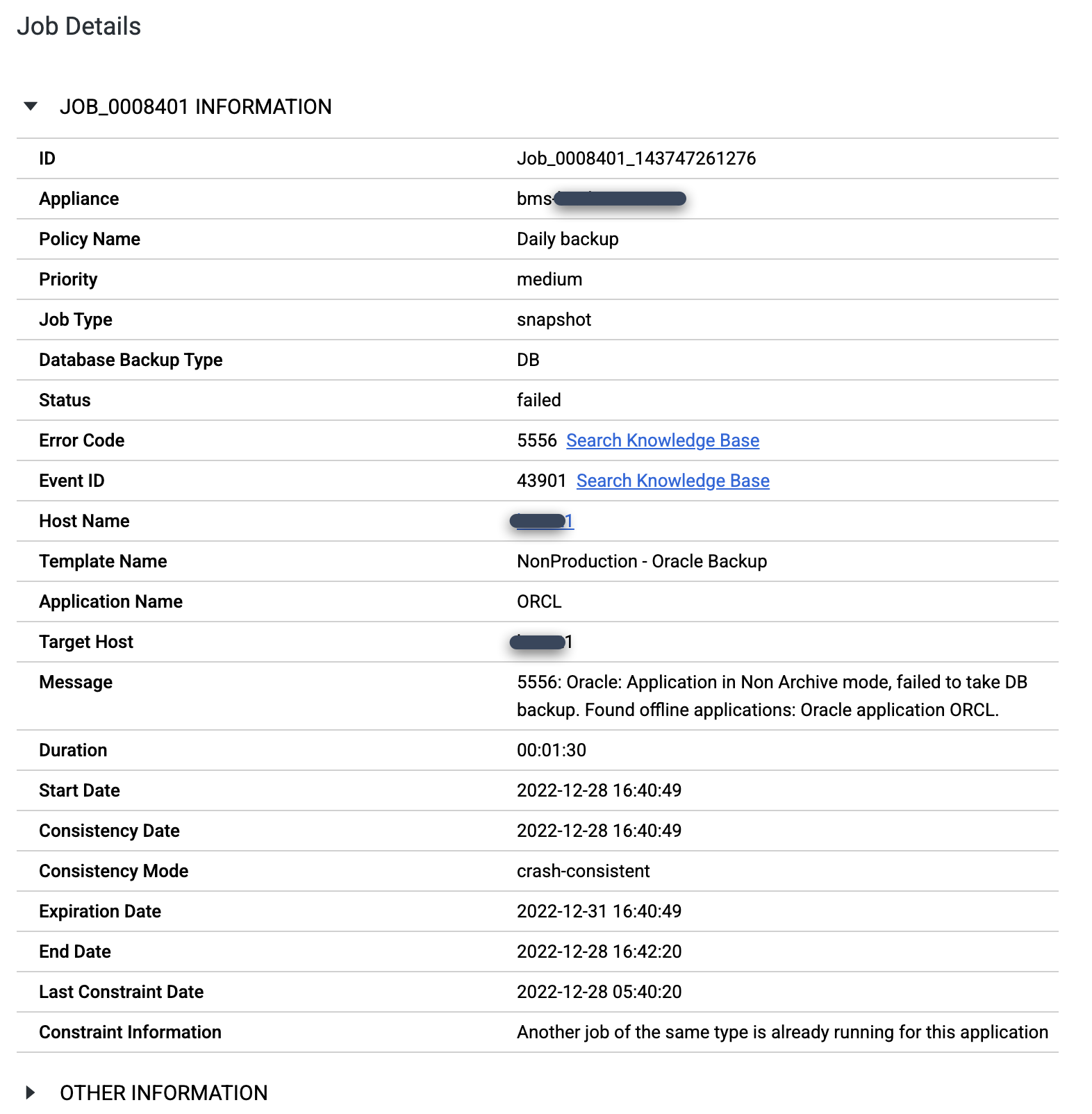
export ORACLE_HOME=ORACLE_HOME_PATH export ORACLE_SID=DATABASE_INSTANCE_NAME export PATH=$ORACLE_HOME/bin:$PATH sqlplus / as sysdba SQL> set tab off SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination +FRA Oldest online log sequence 569 Next log sequence to archive 570 Current log sequence 570
Activez le suivi des modifications de blocs sur la base de données Oracle. Bien que cela ne soit pas obligatoire pour que la solution fonctionne, l'activation du suivi des blocs modifiés évite d'avoir à effectuer une quantité importante de travail de post-traitement pour calculer les blocs modifiés et permet de réduire la durée des jobs de sauvegarde :
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Vérifiez que la base de données utilise
spfile:sqlplus / as sysdba SQL> show parameter spfile NAME TYPE VALUE ------------------ ----------- ------------ spfile string +DATA/ctdb/spfilectdb.ora
Activez Direct NFS (dnfs) pour les hôtes de base de données Oracle. Bien que ce ne soit pas obligatoire, si vous avez besoin de la méthode la plus rapide pour sauvegarder et restaurer les bases de données Oracle, dnfs est le choix privilégié. Pour améliorer encore le débit, vous pouvez modifier le disque de préparation pour chaque hôte et activer dnfs pour Oracle.
Configurez tnsnames pour la résolution des hôtes de base de données Oracle. Si vous n'incluez pas ce paramètre, les commandes RMAN échouent souvent. Voici un exemple de résultat :
[oracle@test2 lib]$ tnsping ORCL TNS Ping Utility for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:55:18 Copyright (c) 1997, 2021, Oracle. All rights reserved. Used parameter files: Used TNSNAMES adapter to resolve the alias Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = test2.localdomain)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ORCL))) OK (0 msec)
Le champ
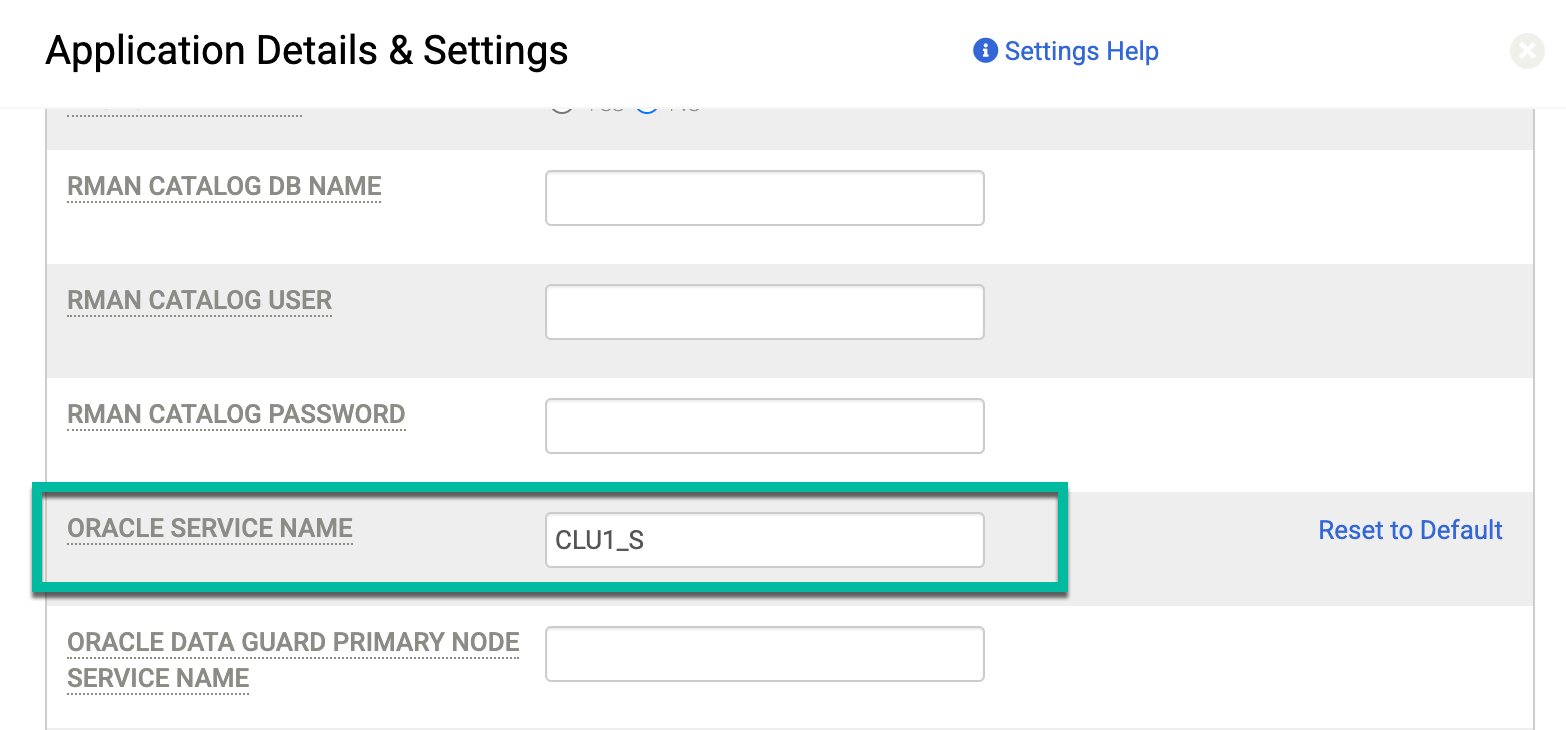
SERVICE_NAMEest important pour les configurations RAC. Le nom de service représente l'alias utilisé pour annoncer le système aux ressources externes qui communiquent avec le cluster. Dans les options Détails et paramètres de la base de données protégée, utilisez le paramètre avancé pour le nom du service Oracle. Saisissez le nom de service spécifique que vous souhaitez utiliser sur les nœuds qui exécutent le job de sauvegarde.La base de données Oracle utilise le nom de service uniquement pour l'authentification de la base de données. La base de données n'utilise pas le nom du service pour l'authentification de l'OS. Par exemple, le nom de la base de données peut être CLU1_S et le nom de l'instance peut être CLU1_S.
Si le nom du service Oracle n'est pas listé, créez une entrée de nom de service sur le ou les serveurs dans le fichier tnsnames.ora situé à l'emplacement
$ORACLE_HOME/network/adminou$GRID_HOME/network/adminen ajoutant l'entrée suivante :CLU1_S = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST =
)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = CLU1_S) ) ) Si le fichier tnsnames.ora se trouve dans un emplacement non standard, indiquez le chemin d'accès absolu au fichier sur la page Détails et paramètres de l'application décrite dans Configurer les détails et les paramètres de l'application pour les bases de données Oracle.
Vérifiez que vous avez correctement configuré l'entrée du nom de service pour la base de données. Connectez-vous à Oracle Linux et configurez l'environnement Oracle :
TNS_ADMIN=TNSNAMES.ORA_FILE_LOCATION tnsping CLU1_S
Examinez le compte utilisateur de la base de données pour vous assurer que la connexion à l'application Backup and DR a réussi :
sqlplus act_rman_user/act_rman_user@act_svc_dbstd as sysdba
Sur la page Application Details and Settings (Détails et paramètres de l'application) décrite dans Application Details and Settings for Oracle Databases (Détails et paramètres de l'application pour les bases de données Oracle), saisissez le nom du service que vous avez créé (CLU1_S) dans le champ Oracle Service Name (Nom du service Oracle) :
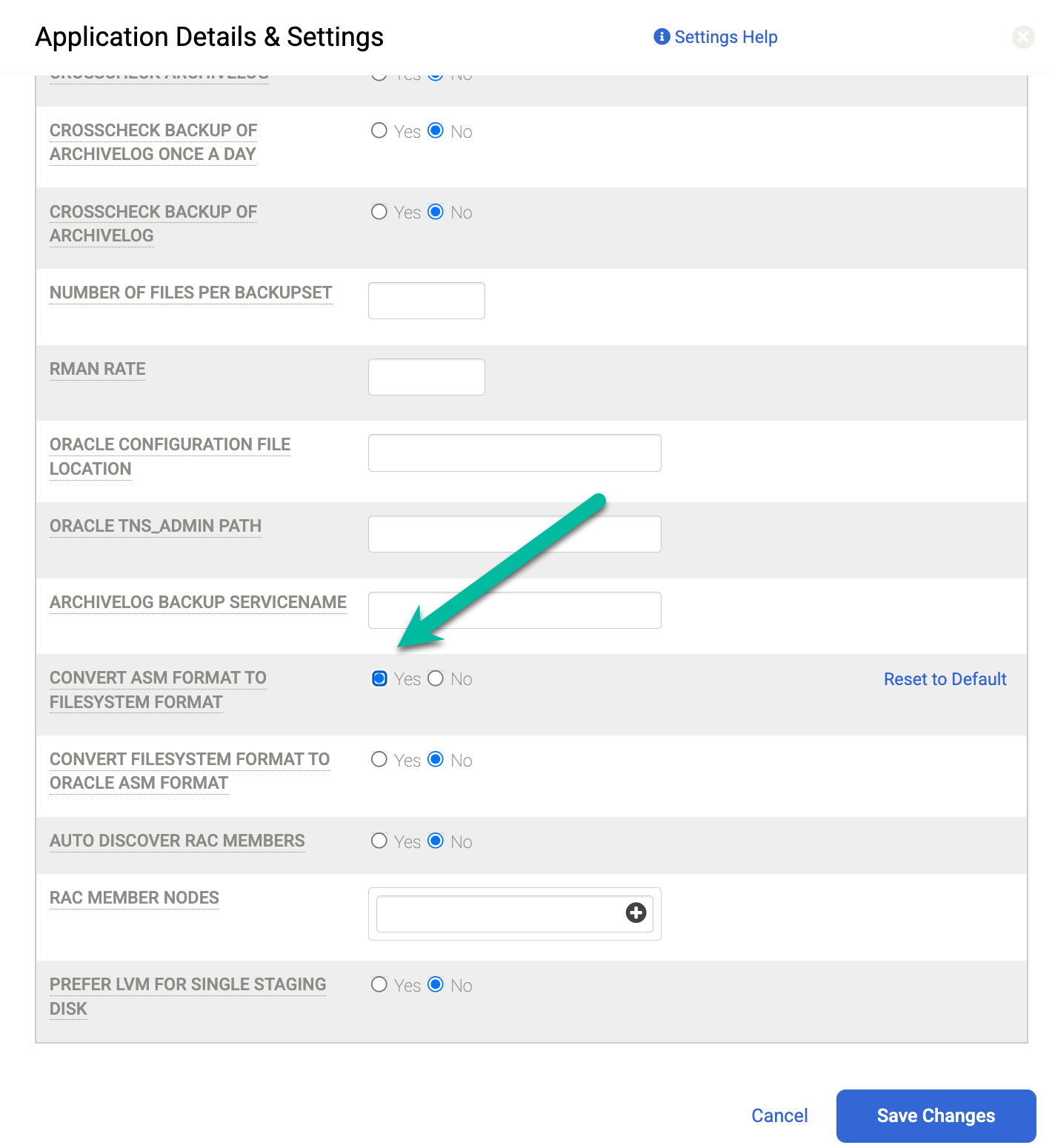
Le code d'erreur 870 indique que "les sauvegardes ASM avec ASM sur les disques de préparation NFS ne sont pas acceptées". Si vous recevez cette erreur, cela signifie que vous n'avez pas configuré le paramètre approprié dans Détails et paramètres pour l'instance que vous souhaitez protéger. Dans cette configuration incorrecte, l'hôte utilise NFS pour le disque de préparation, mais la base de données source s'exécute sur ASM.

Pour résoudre ce problème, définissez le champ Convertir le format ASM au format du système de fichiers sur Oui. Une fois ce paramètre modifié, réexécutez le job de sauvegarde.
Le code d'erreur 15 indique que le système Backup and DR n'a pas pu se connecter à l'hôte de sauvegarde. Si cette erreur s'affiche, cela indique l'un des trois problèmes suivants :
- Le pare-feu entre l'appliance de sauvegarde/récupération et l'hôte sur lequel vous avez installé l'agent n'autorise pas le port TCP 5106 (port d'écoute de l'agent).
- Vous n'avez pas installé l'agent.
- L'agent n'est pas en cours d'exécution.
Pour résoudre ce problème, reconfigurez les paramètres du pare-feu si nécessaire et assurez-vous que l'agent fonctionne. Une fois la cause sous-jacente corrigée, exécutez la commande
service udsagent status. L'exemple de résultat suivant montre que le service de l'agent Backup and DR s'exécute correctement :[root@test2 ~]# service udsagent status Redirecting to /bin/systemctl status udsagent.service udsagent.service - Google Cloud Backup and DR service Loaded: loaded (/usr/lib/systemd/system/udsagent.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2022-12-28 05:05:45 UTC; 2 days ago Process: 46753 ExecStop=/act/initscripts/udsagent.init stop (code=exited, status=0/SUCCESS) Process: 46770 ExecStart=/act/initscripts/udsagent.init start (code=exited, status=0/SUCCESS) Main PID: 46789 (udsagent) Tasks: 8 (limit: 48851) Memory: 74.0M CGroup: /system.slice/udsagent.service ├─46789 /opt/act/bin/udsagent start └─60570 /opt/act/bin/udsagent start Dec 30 05:11:30 test2 su[150713]: pam_unix(su:session): session closed for user oracle Dec 30 05:11:30 test2 su[150778]: (to oracle) root on none
Les messages du journal de vos sauvegardes peuvent vous aider à diagnostiquer les problèmes. Vous pouvez accéder aux journaux sur l'hôte source où les jobs de sauvegarde sont exécutés. Pour les sauvegardes de bases de données Oracle, deux fichiers journaux principaux sont disponibles dans le répertoire
/var/act/log:- UDSAgent.log : journal de l'agent Backup and DR qui enregistre les requêtes d'API, les statistiques sur les tâches en cours d'exécution et d'autres informations.Google Cloud
- SID_rman.log : journal Oracle RMAN qui enregistre toutes les commandes RMAN.
Autres considérations concernant Oracle
Lorsque vous implémentez Backup and DR pour les bases de données Oracle, tenez compte des points suivants lorsque vous déployez Data Guard et RAC.
Points à prendre en compte concernant Data Guard
Vous pouvez sauvegarder les nœuds Data Guard principaux et de secours. Toutefois, si vous choisissez de protéger les bases de données uniquement à partir des nœuds de secours, vous devez utiliser l'authentification de la base de données Oracle plutôt que l'authentification du système d'exploitation lorsque vous sauvegardez la base de données.
Points à prendre en compte concernant RAC
La solution Backup and DR n'est pas compatible avec la sauvegarde simultanée à partir de plusieurs nœuds dans une base de données RAC si le disque de préparation est défini sur le mode NFS. Si votre système nécessite une sauvegarde simultanée à partir de plusieurs nœuds RAC, utilisez Block (iSCSI) comme mode de disque intermédiaire et définissez-le pour chaque hôte.
Pour une base de données Oracle RAC utilisant ASM, vous devez placer le fichier de contrôle de l'instantané dans les disques partagés. Pour vérifier cette configuration, connectez-vous à RMAN et exécutez la commande show all :
rman target / RMAN> show all
CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default CONFIGURE BACKUP OPTIMIZATION OFF; # default CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default CONFIGURE CONTROLFILE AUTOBACKUP OFF; # default CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '%F'; # default CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/mnt/ctdb/snapcf_ctdb.f';
Dans un environnement RAC, vous devez mapper le fichier de contrôle du snapshot à un groupe de disques ASM partagé. Pour attribuer le fichier au groupe de disques ASM, utilisez la commande Configure Snapshot Controlfile Name :
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '+/snap_ .f';
Recommandations
Selon vos besoins, vous devrez peut-être prendre des décisions concernant certaines fonctionnalités qui ont un impact sur la solution globale. Certaines décisions peuvent affecter le prix, qui à son tour peut affecter les performances. Par exemple, le choix de disques persistants standards (pd-standard) ou de disques persistants de performance (pd-ssd) pour les pools d'instantanés de l'appliance de sauvegarde/récupération.
Dans cette section, nous vous recommandons des choix pour vous aider à garantir un débit de sauvegarde optimal pour la base de données Oracle.
Sélectionner le type de machine et le type de disque persistant optimaux
Lorsque vous utilisez un dispositif de sauvegarde/récupération avec une application telle qu'un système de fichiers ou une base de données, vous pouvez mesurer les performances en fonction de la rapidité avec laquelle les données de l'instance hôte sont transférées entre les instances Compute Engine.
- Les vitesses des périphériques Persistent Disk Compute Engine dépendent de trois facteurs : le type de machine, la quantité totale de mémoire associée à l'instance et le nombre de processeurs virtuels de l'instance.
- Le nombre de processeurs virtuels d'une instance détermine la vitesse du réseau allouée à une instance Compute Engine. La vitesse varie de 1 Gbit/s pour un processeur virtuel partagé à 16 Gbit/s pour 8 processeurs virtuels ou plus.
- En combinant ces limites,la sauvegarde et la reprise après sinistre utilisent par défaut un type de machine de taille standard e2-standard-16 pour un dispositif de sauvegarde/récupération. Google Cloud À partir de ce point de départ, vous avez trois choix pour l'allocation de disque :
Choix |
Pool Disk |
Écritures soutenues maximales |
Lectures soutenues maximales |
Minimum |
10 Go |
N/A |
N/A |
Standard |
4 096 Go |
400 Mio/s |
1 200 Mio/s |
SSD |
4 096 Go |
1 000 Mio/s |
1 200 Mio/s |
Les instances Compute Engine utilisent jusqu'à 60 % de leur réseau alloué pour les E/S vers leurs disques persistants associés et réservent 40 % pour d'autres utilisations. Pour en savoir plus, consultez Autres facteurs ayant une incidence sur les performances.
Recommandation : La sélection d'un type de machine e2-standard-16 et d'un minimum de 4 096 Go de PD-SSD offre les meilleures performances pour les appliances de sauvegarde/restauration. Vous pouvez également sélectionner un type de machine n2-standard-16 pour votre appliance de sauvegarde/récupération. Cette option vous offre des avantages supplémentaires en termes de performances (de 10 à 20 %), mais entraîne des coûts supplémentaires. Si cela correspond à votre cas d'utilisation, contactez Cloud Customer Care pour effectuer cette modification.
Optimiser vos instantanés
Pour augmenter la productivité d'une seule appliance de sauvegarde/récupération, vous pouvez exécuter des tâches d'instantané simultanées à partir de plusieurs sources. La vitesse de chaque tâche individuelle diminue. Toutefois, avec suffisamment de jobs, vous pouvez atteindre la limite d'écriture soutenue pour les volumes de disque persistant du pool d'instantanés.
Lorsque vous utilisez iSCSI pour le disque de préproduction, vous pouvez sauvegarder une seule grande instance sur un dispositif de sauvegarde/récupération avec une vitesse d'écriture soutenue d'environ 300 à 330 Mo/s. Lors de nos tests, nous avons constaté que cela était vrai pour toutes les capacités, de 2 To à 80 To dans un instantané, à condition que vous configuriez l'hôte source et l'appliance de sauvegarde/récupération à une taille optimale, et qu'ils se trouvent dans la même région et zone.
Choisir le bon disque intermédiaire
Si vous avez besoin de performances et d'un débit importants, Direct NFS peut apporter un avantage considérable par rapport à iSCSI en tant que choix de disque de préparation à utiliser pour les sauvegardes de bases de données Oracle. Direct NFS consolide le nombre de connexions TCP, ce qui améliore l'évolutivité et les performances réseau.
Lorsque vous activez Direct NFS pour une base de données Oracle, configurez suffisamment de processeurs sources (par exemple, huit processeurs virtuels et huit canaux RMAN), et établissez un lien de 10 Go entre votre extension régionale solution Bare Metal et Google Cloud. Vous pouvez ainsi sauvegarder une seule base de données Oracle avec un débit accru de 700 à 900 Mo/s et plus. Les vitesses de restauration RMAN bénéficient également de Direct NFS, où les niveaux de débit peuvent atteindre 850 Mo/s et plus.
Équilibrer les coûts et le débit
Il est également important de comprendre que toutes les données de sauvegarde sont stockées dans un format compressé dans le pool d'instantanés de l'appliance de sauvegarde/récupération, ce qui permet de réduire les coûts. Les frais généraux de performances pour ce bénéfice de compression sont marginaux. Toutefois, pour les données chiffrées (TDE) ou les ensembles de données fortement compressés, il y aura probablement un impact mesurable, bien que marginal, sur vos chiffres de débit.
Comprendre les facteurs qui ont un impact sur les performances du réseau et de vos serveurs de sauvegarde
Les éléments suivants ont une incidence sur les E/S réseau entre Oracle sur la solution Bare Metal et vos serveurs de sauvegarde dans Google Cloud :
Mémoire flash
Comme pour les disques persistants Google Cloud , les baies de stockage flash qui fournissent le stockage pour les systèmes de solution Bare Metal augmentent les capacités d'E/S en fonction de la quantité de stockage que vous attribuez à l'hôte. Plus vous allouez d'espace de stockage, meilleures sont les E/S. Pour obtenir des résultats cohérents, nous vous recommandons de provisionner au moins 8 To de stockage flash.
Latence du réseau
Google Cloud Les tâches de sauvegarde Backup and DR sont sensibles à la latence réseau entre les hôtes de la solution Bare Metal et l'appliance de sauvegarde/récupération dans Google Cloud. De petites augmentations de la latence peuvent entraîner des changements importants dans les temps de sauvegarde et de restauration. Différentes zones Compute Engine offrent différentes latences réseau aux hôtes solution Bare Metal. Il est recommandé de tester chaque zone pour déterminer l'emplacement optimal de l'appliance de sauvegarde/récupération.
Nombre de processeurs utilisés
Les serveurs de la solution Bare Metal sont disponibles en plusieurs tailles. Nous vous recommandons d'adapter vos canaux RMAN aux processeurs disponibles, les systèmes plus grands offrant une vitesse potentielle plus élevée.
Cloud Interconnect
L'interconnexion hybride entre la solution Bare Metal et Google Cloud est disponible en plusieurs tailles, telles que 5 Gbit/s, 10 Gbit/s et 2x10 Gbit/s, avec des performances optimales pour l'option double 10 Gbit/s. Il est également possible de configurer un lien d'interconnexion dédié qui sera utilisé exclusivement pour les opérations de sauvegarde et de restauration. Cette option est recommandée pour les clients qui souhaitent isoler leur trafic de sauvegarde du trafic de base de données ou d'application qui peut transiter par le même lien, ou garantir une bande passante complète lorsque les opérations de sauvegarde et de restauration sont essentielles pour respecter l'objectif de point de récupération (RPO) et l'objectif de temps de récupération (RTO).
Étape suivante
Voici quelques liens et informations supplémentaires sur Google Cloud Backup and DR qui pourraient vous être utiles.
- Pour en savoir plus sur la configuration de Google Cloud Backup and DR, consultez la documentation produit Backup and DR.
- Pour voir des démonstrations de l'installation et des fonctionnalités du produit, consultez la playlist de vidéos sur Google Cloud Backup and DR.
- Pour afficher des informations sur la compatibilité de Google Cloud Backup and DR, consultez la matrice de compatibilité Backup and DR. Il est important de vérifier que vous exécutez des versions compatibles de Linux et des instances de base de données Oracle.
- Pour connaître les étapes supplémentaires concernant la protection des bases de données Oracle, consultez Backup and DR pour les bases de données Oracle et Protéger une base de données Oracle détectée.
- Les systèmes de fichiers tels que NFS, CIFS, ext3 et ext4 peuvent également être protégés avecGoogle Cloud Backup and DR. Pour afficher les options disponibles, consultez Appliquer un plan de sauvegarde pour protéger un système de fichiers.
- Pour activer les alertes pour Google Cloud Backup and DR, consultez Configurer une alerte basée sur les journaux et regardez la vidéo Configurer les notifications d'alerte Backup and DR Google Cloud.
- Pour ouvrir une demande d'assistance, contactez l'assistance Cloud Customer Care.