Este documento descreve uma arquitetura de referência que ajuda a criar um mecanismo de exportação de registos pronto para produção, escalável, tolerante a falhas e que transmite registos e eventos dos seus recursos no Google Cloud para o Splunk. O Splunk é uma ferramenta de estatísticas popular que oferece uma plataforma unificada de segurança e observabilidade. Na verdade, tem a opção de exportar os dados de registo para o Splunk Enterprise ou a Splunk Cloud Platform. Se for administrador, também pode usar esta arquitetura para exemplos de utilização de operações de TI ou de segurança.
Esta arquitetura de referência pressupõe uma hierarquia de recursos semelhante ao diagrama seguinte. Todos os registos de recursos dos níveis de organização, pasta e projeto são recolhidos num sink agregado. Google Cloud Em seguida, o destino agregado envia estes registos para um pipeline de exportação de registos, que processa os registos e os exporta para o Splunk.

Arquitetura
O diagrama seguinte mostra a arquitetura de referência que usa quando implementa esta solução. Este diagrama demonstra como os dados de registo fluem deGoogle Cloud para o Splunk.

Esta arquitetura inclui os seguintes componentes:
- Cloud Logging: para iniciar o processo, o Cloud Logging recolhe os registos num destino de registos agregado ao nível da organização e envia os registos para o Pub/Sub.
- Pub/Sub: o serviço Pub/Sub cria, em seguida, um único tópico e subscrição para os registos e encaminha-os para a pipeline do Dataflow principal.
- Dataflow: existem dois pipelines do Dataflow nesta arquitetura de referência:
- Pipeline do Dataflow principal: no centro do processo, o pipeline do Dataflow principal é um pipeline de streaming do Pub/Sub para o Splunk que extrai registos da subscrição do Pub/Sub e os envia para o Splunk.
- Pipeline do Dataflow secundário: em paralelo com o pipeline do Dataflow principal, o pipeline do Dataflow secundário é um pipeline de streaming do Pub/Sub para o Pub/Sub para repetir mensagens se uma entrega falhar.
- Splunk: no final do processo, o Splunk Enterprise ou a Splunk Cloud Platform atuam como um coletor de eventos de HTTP (HEC) e recebem os registos para análise mais detalhada. Pode implementar o Splunk nas instalações, na Google Cloud como SaaS ou através de uma abordagem híbrida.
Exemplo de utilização
Esta arquitetura de referência usa uma abordagem baseada na nuvem e de envio. Neste método baseado em push, usa o modelo do Dataflow do Pub/Sub para o Splunk para transmitir registos para um coletor de eventos de HTTP (HEC) do Splunk. A arquitetura de referência também aborda o planeamento da capacidade do pipeline do Dataflow e como processar potenciais falhas de entrega quando existem problemas transitórios de servidor ou de rede.
Embora esta arquitetura de referência se foque nos Google Cloud registos, a mesma arquitetura pode ser usada para exportar outros Google Cloud dados, como alterações de recursos em tempo real e conclusões de segurança. Ao integrar registos do Cloud Logging, pode continuar a usar serviços de parceiros existentes, como o Splunk, como uma solução de análise de registos unificada.
O método baseado em envio para transmitir Google Cloud dados para o Splunk tem as seguintes vantagens:
- Serviço gerido. Como serviço gerido, o Dataflow mantém os recursos necessários no Google Cloud para tarefas de processamento de dados, como a exportação de registos.
- Carga de trabalho distribuída. Este método permite distribuir cargas de trabalho por vários trabalhadores para processamento paralelo, pelo que não existe um único ponto de falha.
- Segurança. Uma vez que o Google Cloud envia os seus dados para o Splunk HEC, não existe o encargo de manutenção e segurança associado à criação e gestão de chaves de contas de serviço.
- Dimensionamento automático. O serviço Dataflow ajusta automaticamente a escala do número de trabalhadores em resposta a variações no volume de registos recebidos e na acumulação.
- Tolerância a falhas. Se existirem problemas transitórios de servidor ou de rede, o método baseado em push tenta automaticamente reenviar os dados para o Splunk HEC. Também suporta tópicos não processados (também conhecidos como tópicos de mensagens não entregues) para quaisquer mensagens de registo não entregues, de modo a evitar a perda de dados.
- Simplicidade. Evita a sobrecarga de gestão e o custo de executar um ou mais encaminhadores pesados no Splunk.
Esta arquitetura de referência aplica-se a empresas em muitos setores verticais diferentes, incluindo os regulamentados, como os serviços farmacêuticos e financeiros. Quando opta por exportar os seus Google Cloud dados para o Splunk, pode fazê-lo pelos seguintes motivos:
- Estatísticas empresariais
- Operações de TI
- Monitorização do desempenho das aplicações
- Operações de segurança
- Conformidade
Alternativas de design
Um método alternativo para a exportação de registos para o Splunk é aquele em que extrai registos do Google Cloud. Neste método baseado na obtenção, usa as Google Cloud APIs para obter os dados através do suplemento do Splunk para Google Cloud. Pode optar por usar o método baseado na obtenção nas seguintes situações:
- A sua implementação do Splunk não oferece um ponto final do Splunk HEC.
- O volume do registo é baixo.
- Quer exportar e analisar métricas do Cloud Monitoring, objetos do Cloud Storage, metadados da API Cloud Resource Manager, dados do Cloud Billing ou registos de baixo volume.
- Já gere um ou mais encaminhadores pesados no Splunk.
- Usa o Gestor de dados de entradas para o Splunk Cloud alojado.
Além disso, tenha em atenção as considerações adicionais que surgem quando usa este método baseado em obtenção:
- Um único trabalhador processa a carga de trabalho de obtenção de dados, que não oferece capacidades de escalabilidade automática.
- No Splunk, a utilização de um encaminhador pesado para extrair dados pode causar um único ponto de falha.
- O método baseado na obtenção requer que crie e faça a gestão das chaves da conta de serviço que usa para configurar o suplemento do Splunk para o Google Cloud.
Antes de usar o suplemento do Splunk, as entradas de registo têm de ser encaminhadas primeiro para o Pub/Sub através de um destino de registo. Para criar um destino de registo com o tópico do Pub/Sub como destino, consulte o artigo criar um destino.
Certifique-se de que concede a função de publicador do Pub/Sub (roles/pubsub.publisher) à identidade do escritor do destino do tópico do Pub/Sub. Para mais
informações sobre a configuração das autorizações do destino de sincronização, consulte
Defina autorizações de destino.
Para ativar o suplemento do Splunk, siga estes passos:
- No Splunk, siga as instruções do Splunk para instalar o suplemento do Splunk para Google Cloud.
- Crie uma subscrição de obtenção do Pub/Sub para o tópico do Pub/Sub para onde os registos são encaminhados, se ainda não tiver uma.
- Crie uma conta de serviço.
- Crie uma chave de conta de serviço para a conta de serviço que acabou de criar.
- Conceda as funções de leitor do Pub/Sub (
roles/pubsub.viewer) e subscritor do Pub/Sub (roles/pubsub.subscriber) à conta de serviço para permitir que a conta receba mensagens da subscrição do Pub/Sub. No Splunk, siga as instruções do Splunk para configurar uma nova entrada do Pub/Sub no suplemento do Splunk para Google Cloud.
As mensagens do Pub/Sub da exportação de registos aparecem no Splunk.
Para verificar se o suplemento está a funcionar, siga estes passos:
- No Cloud Monitoring, abra o Explorador de métricas.
- No menu Recursos, selecione
pubsub_subscription. - Nas categorias de métricas, selecione
pubsub/subscription/pull_message_operation_count. - Monitorize o número de operações de obtenção de mensagens durante um a dois minutos.
Considerações de design
As seguintes diretrizes podem ajudar a desenvolver uma arquitetura que cumpra os requisitos da sua organização em termos de segurança, privacidade, conformidade, eficiência operacional, fiabilidade, tolerância a falhas, desempenho e otimização de custos.
Segurança, privacidade e conformidade
As secções seguintes descrevem as considerações de segurança para esta arquitetura de referência:
- Use endereços IP privados para proteger as VMs que suportam o pipeline do Dataflow
- Ative o acesso privado do Google
- Restrinja o tráfego de entrada do HEC do Splunk a endereços IP conhecidos usados pelo NAT da nuvem
- Armazene o token HEC do Splunk no Secret Manager
- Crie uma conta de serviço de worker do Dataflow personalizada para seguir as práticas recomendadas de privilégios mínimos
- Configure a validação SSL para um certificado de AC de raiz interno se usar uma AC privada
Use endereços IP privados para proteger as VMs que suportam o pipeline do Dataflow
Deve restringir o acesso às VMs de trabalho usadas no pipeline do Dataflow. Para restringir o acesso, implemente estas VMs com endereços IP privados. No entanto, estas VMs também têm de poder usar HTTPS para transmitir os registos exportados para o Splunk e aceder à Internet. Para fornecer este acesso HTTPS, precisa de um gateway Cloud NAT que atribua automaticamente endereços IP do Cloud NAT às VMs que os necessitam. Certifique-se de que mapeia a sub-rede que contém as VMs para o gateway Cloud NAT.
Ative o acesso privado à Google
Quando cria um gateway Cloud NAT, o acesso privado à Google é ativado automaticamente. No entanto, para permitir que os trabalhadores do Dataflow com endereços IP privados acedam aos endereços IP externos que as APIs e os serviços da Google Cloud usam, também tem de ativar manualmente o acesso privado à Google para a sub-rede.
Restrinja o tráfego de entrada do Splunk HEC a endereços IP conhecidos usados pelo Cloud NAT
Se quiser restringir o tráfego para o Splunk HEC a um subconjunto de endereços IP conhecidos, pode reservar endereços IP estáticos e atribuí-los manualmente ao gateway Cloud NAT. Consoante a sua implementação do Splunk, pode configurar as regras da firewall de entrada do HEC do Splunk com estes endereços IP estáticos. Para mais informações sobre o Cloud NAT, consulte o artigo Configure e faça a gestão da tradução de endereços de rede com o Cloud NAT.
Armazene o token do HEC do Splunk no Secret Manager
Quando implementa o pipeline do Dataflow, pode transmitir o valor do token de uma das seguintes formas:
- Texto simples
- Texto cifrado encriptado com uma chave do Cloud Key Management Service
- Versão do Secret encriptada e gerida pelo Secret Manager
Nesta arquitetura de referência, usa a opção Secret Manager porque esta opção oferece a forma menos complexa e mais eficiente de proteger o token HEC do Splunk. Esta opção também impede a fuga do token HEC do Splunk da consola do Dataflow ou dos detalhes da tarefa.
Um Secret no Secret Manager contém uma coleção de versões do Secret. Cada versão do segredo armazena os dados secretos reais, como o token HEC do Splunk. Se optar por rodar o seu token HEC do Splunk como uma medida de segurança adicional, pode adicionar o novo token como uma nova versão secreta a este segredo. Para obter informações gerais sobre a rotação de segredos, consulte Acerca dos horários de rotação.
Crie uma conta de serviço de worker do Dataflow personalizada para seguir as práticas recomendadas de privilégios mínimos
Os trabalhadores no pipeline do Dataflow usam a conta de serviço do trabalhador do Dataflow para aceder a recursos e executar operações. Por predefinição, os trabalhadores usam a conta de serviço predefinida do Compute Engine do seu projeto como a conta de serviço do trabalhador, o que lhes concede amplas autorizações a todos os recursos no seu projeto. No entanto, para executar tarefas do Dataflow em produção, recomendamos que crie uma conta de serviço personalizada com um conjunto mínimo de funções e autorizações. Em seguida, pode atribuir esta conta de serviço personalizada aos trabalhadores do pipeline do Dataflow.
O diagrama seguinte lista as funções necessárias que tem de atribuir a uma conta de serviço para permitir que os trabalhadores do Dataflow executem uma tarefa do Dataflow com êxito.
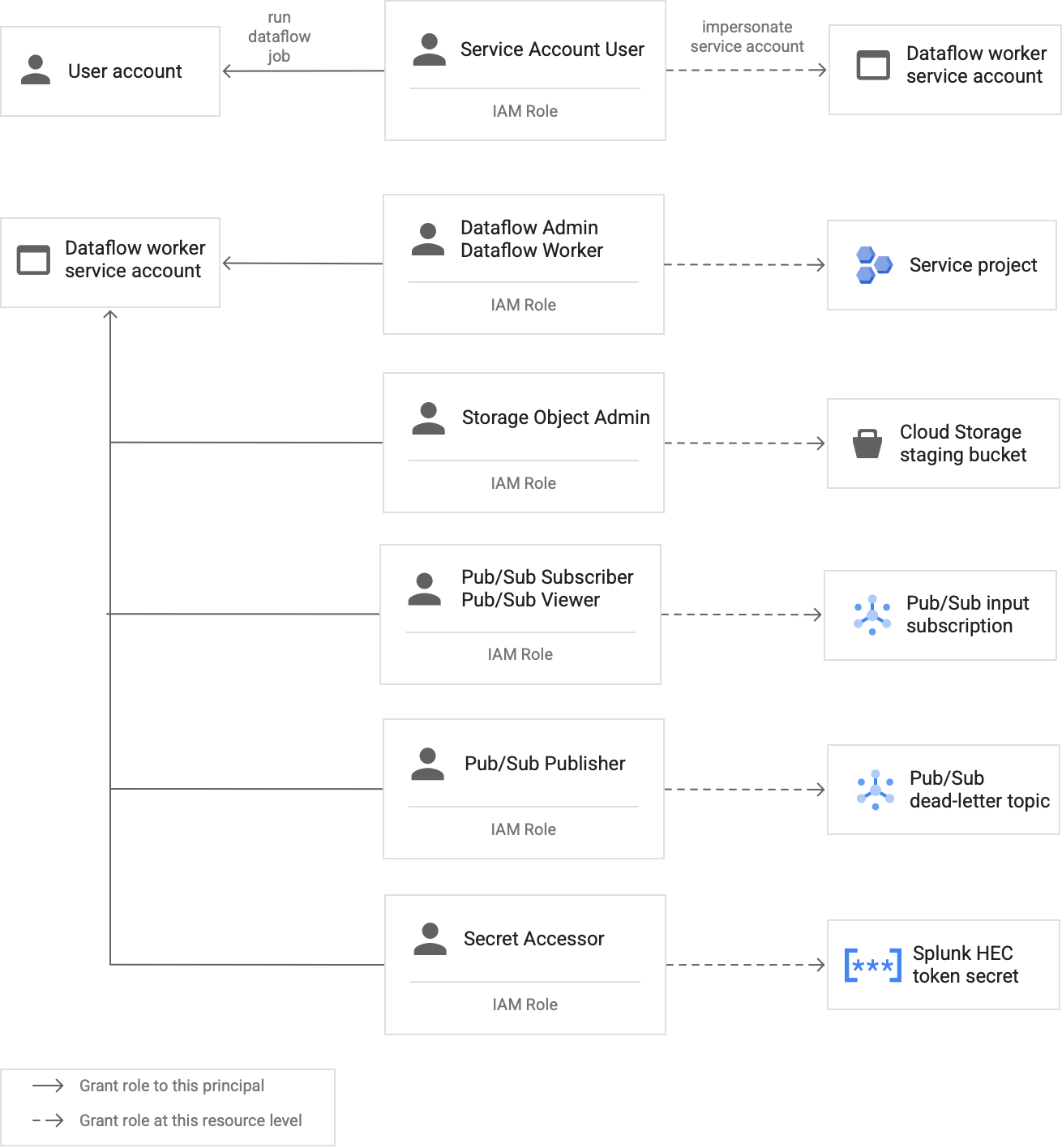
Conforme mostrado no diagrama, tem de atribuir as seguintes funções à conta de serviço do seu worker do Dataflow:
- Administrador do Dataflow
- Dataflow Worker
- Administrador de objetos de armazenamento
- Subscritor do Pub/Sub
- Visualizador do Pub/Sub
- Publicador do Pub/Sub
- Acesso a segredos
Configure a validação SSL com um certificado de AC de raiz interno se usar uma AC privada
Por predefinição, o pipeline do Dataflow usa o repositório fidedigno predefinido do trabalhador do Dataflow para validar o certificado SSL do seu ponto final HEC do Splunk. Se usar uma autoridade de certificação (AC) privada para assinar um certificado SSL usado pelo ponto final do Splunk HEC, pode importar o certificado de AC raiz interno para o repositório fidedigno. Os trabalhadores do Dataflow podem, em seguida, usar o certificado importado para a validação do certificado SSL.
Pode usar e importar o seu próprio certificado de CA de raiz interno para implementações do Splunk com certificados autoassinados ou assinados de forma privada. Também pode desativar completamente a validação de SSL apenas para fins de desenvolvimento e testes internos. Este método de AC raiz interno funciona melhor para implementações do Splunk internas que não estão viradas para a Internet.
Para mais informações, consulte os
parâmetros do modelo do Dataflow do Pub/Sub para o Splunk
rootCaCertificatePath e disableCertificateValidation.
Eficiência operacional
As secções seguintes descrevem as considerações de eficiência operacional para esta arquitetura de referência:
Use a FDU para transformar registos ou eventos em tempo real
O modelo do Dataflow do Pub/Sub para Splunk suporta funções definidas pelo utilizador (UDF) para a transformação de eventos personalizados. Exemplos de utilizações incluem o enriquecimento de registos com campos adicionais, a ocultação de alguns campos sensíveis ou a filtragem de registos indesejados. A FDU permite-lhe alterar o formato de saída do pipeline do Dataflow sem ter de recompilar nem manter o próprio código do modelo. Esta arquitetura de referência usa uma UDF para processar mensagens que o pipeline não consegue entregar ao Splunk.
Repita mensagens não processadas
Por vezes, o pipeline recebe erros de entrega e não tenta entregar a mensagem novamente. Neste caso, o Dataflow envia estas mensagens não processadas para um tópico não processado, conforme mostrado no diagrama seguinte. Depois de corrigir a causa principal da falha de entrega, pode reproduzir as mensagens não processadas.
Os passos seguintes descrevem o processo apresentado no diagrama anterior:
- O pipeline de entrega principal do Pub/Sub para o Splunk encaminha automaticamente as mensagens não entregáveis para o tópico não processado para investigação do utilizador.
O operador ou o engenheiro de fiabilidade do site (SRE) investiga as mensagens com falhas na subscrição não processada. O operador resolve o problema e corrige a causa principal da falha de entrega. Por exemplo, corrigir uma configuração incorreta do token do HEC pode permitir a entrega das mensagens.
O operador aciona o pipeline de mensagens de repetição com falha. Este pipeline Pub/Sub para Pub/Sub (realçado na secção com pontos do diagrama anterior) é um pipeline temporário que move as mensagens com falhas da subscrição não processada de volta para o tópico do coletor de registos original.
O pipeline de entrega principal processa novamente as mensagens com falhas anteriores. Este passo requer que o pipeline use uma FDU para a deteção e descodificação corretas de payloads de mensagens com falhas. O código seguinte é uma função de exemplo que implementa esta lógica de descodificação condicional, incluindo uma contagem das tentativas de entrega para fins de acompanhamento:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
Fiabilidade e tolerância a falhas
No que diz respeito à fiabilidade e à tolerância a falhas, a tabela seguinte, Tabela 1, apresenta alguns possíveis erros de entrega do Splunk. A tabela também lista os atributos errorMessage correspondentes que o pipeline regista com cada mensagem antes de encaminhar estas mensagens para o tópico não processado.
Tabela 1: tipos de erros de entrega do Splunk
| Tipo de erro de entrega | A nova tentativa é feita automaticamente pelo pipeline? | Exemplo de atributo errorMessage |
|---|---|---|
Erro de rede temporário |
Sim |
ou
|
Erro 5xx do servidor Splunk |
Sim |
|
Erro 4xx do servidor Splunk |
Não |
|
Servidor do Splunk indisponível |
Não |
|
Certificado SSL do Splunk inválido |
Não |
|
Erro de sintaxe do código JavaScript na função definida pelo utilizador (FDU) |
Não |
|
Em alguns casos, o pipeline aplica um
recuo exponencial e tenta automaticamente entregar a mensagem novamente. Por exemplo, quando o servidor Splunk gera um código de erro 5xx, o pipeline tem de voltar a enviar a mensagem. Estes códigos de erro ocorrem quando o ponto final do HEC do Splunk está sobrecarregado.
Em alternativa, pode existir um problema persistente que impeça o envio de uma mensagem para o ponto final HEC. Para problemas persistentes, o pipeline não tenta entregar a mensagem novamente. Seguem-se exemplos de problemas persistentes:
- Um erro de sintaxe na função UDF.
- Um token HEC inválido que faz com que o servidor Splunk gere uma resposta do servidor "Proibido".
4xx
Otimização do desempenho e dos custos
No que diz respeito à otimização do desempenho e dos custos, tem de determinar o tamanho e o débito máximos do pipeline do Dataflow. Tem de calcular os valores de tamanho e débito corretos para que o pipeline possa processar o volume de registos diário máximo (GB/dia) e a taxa de mensagens de registo (eventos por segundo ou EPS) da subscrição do Pub/Sub a montante.
Tem de selecionar os valores de tamanho e débito para que o sistema não incorra em nenhum dos seguintes problemas:
- Atrasos causados por acumulação de mensagens ou limitação de mensagens.
- Custos adicionais devido ao aprovisionamento excessivo de um pipeline.
Depois de fazer os cálculos de tamanho e débito, pode usar os resultados para configurar um pipeline ideal que equilibre o desempenho e o custo. Para configurar a capacidade do pipeline, use as seguintes definições:
- Os flags Machine type e Machine count fazem parte do comando gcloud que implementa a tarefa do Dataflow. Estas flags permitem-lhe definir o tipo e o número de VMs a usar.
- Os parâmetros Paralelismo e Quantidade de lotes fazem parte do modelo do Dataflow do Pub/Sub para o Splunk. Estes parâmetros são importantes para aumentar o EPS e evitar sobrecarregar o ponto final HEC do Splunk.
As secções seguintes explicam estas definições. Quando aplicável, estas secções também fornecem fórmulas e exemplos de cálculos que usam cada fórmula. Estes cálculos de exemplo e os valores resultantes pressupõem uma organização com as seguintes caraterísticas:
- Gera 1 TB de registos diariamente.
- Tem um tamanho médio da mensagem de 1 KB.
- Tem uma taxa de mensagens de pico sustentada que é duas vezes superior à taxa média.
Uma vez que o seu ambiente do Dataflow é único, substitua os valores de exemplo por valores da sua própria organização à medida que avança nos passos.
Tipo de máquina
Prática recomendada: defina a flag --worker-machine-type como n2-standard-4 para selecionar um tamanho de máquina que ofereça a melhor relação entre desempenho e custo.
Uma vez que o tipo de máquina n2-standard-4 pode processar 12 mil EPS, recomendamos que use este tipo de máquina como base para todos os seus trabalhadores do Dataflow.
Para esta arquitetura de referência, defina a flag --worker-machine-type para um valor de n2-standard-4.
Quantidade de máquinas
Prática recomendada: defina a flag --max-workers para controlar o número máximo de trabalhadores necessários para processar o EPS máximo esperado.
A escala automática do Dataflow permite que o serviço altere de forma adaptativa o número de trabalhadores usados para executar a sua pipeline de streaming quando existem alterações à utilização de recursos e à carga. Para evitar o aprovisionamento excessivo quando usar a escalabilidade automática, recomendamos que defina sempre o número máximo de máquinas virtuais que são usadas como trabalhadores do Dataflow. Define o número máximo de máquinas virtuais com a flag --max-workers quando implementa o pipeline do Dataflow.
O Dataflow aprovisiona estaticamente o componente de armazenamento da seguinte forma:
Um pipeline de escalamento automático implementa um disco persistente de dados para cada potencial worker de streaming. O tamanho predefinido do disco persistente é de 400 GB e define o número máximo de trabalhadores com a flag
--max-workers. Os discos são montados nos trabalhadores em execução em qualquer altura, incluindo no arranque.Uma vez que cada instância de trabalhador está limitada a 15 discos persistentes, o número mínimo de trabalhadores de início é
⌈--max-workers/15⌉. Assim, se o valor predefinido for--max-workers=20, a utilização (e o custo) do pipeline é a seguinte:- Armazenamento: estático com 20 discos persistentes.
- Computação: dinâmica com um mínimo de 2 instâncias de trabalho (⌈20/15⌉ = 2) e um máximo de 20.
Este valor é equivalente a 8 TB de um disco persistente. Este tamanho do disco persistente pode incorrer em custos desnecessários se os discos não forem totalmente usados, especialmente se apenas um ou dois trabalhadores estiverem a executar a maioria do tempo.
Para determinar o número máximo de trabalhadores de que precisa para o seu pipeline, use as seguintes fórmulas em sequência:
Determine a média de eventos por segundo (EPS) através da seguinte fórmula:
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)Exemplo de cálculo: tendo em conta os valores de exemplo de 1 TB de registos por dia com um tamanho médio de mensagem de 1 KB, esta fórmula gera um valor de EPS médio de 11,5 mil EPS.
Determine o EPS máximo sustentado através da seguinte fórmula, em que o multiplicador N representa a natureza intermitente do registo:
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)Exemplo de cálculo: dado um valor de exemplo de N=2 e o valor médio de EPS de 11,5 mil que calculou no passo anterior, esta fórmula gera um valor de EPS de pico sustentado de 23 mil EPS.
Determine o número máximo necessário de vCPUs através da seguinte fórmula:
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)Exemplo de cálculo: usando o valor de EPS máximo sustentado de 23 mil que calculou no passo anterior, esta fórmula gera um máximo de ⌈23 / 3⌉ = 8 núcleos de vCPU.
Determine o número máximo de trabalhadores do Dataflow através da seguinte fórmula:
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)Exemplo de cálculo: usando o valor máximo de vCPUs de 8 do exemplo que foi calculado no passo anterior, esta fórmula [8/4] gera um número máximo de 2 para um tipo de máquina
n2-standard-4.
Para este exemplo, definiria a flag --max-workers para um valor de 2
com base no conjunto anterior de cálculos de exemplo. No entanto, lembre-se de usar os seus
próprios valores e cálculos exclusivos quando implementar esta arquitetura de referência
no seu ambiente.
Paralelismo
Prática recomendada: defina o parâmetro
parallelism no modelo do Dataflow do Pub/Sub para o Splunk para o dobro do número de vCPUs usadas pelo número máximo de trabalhadores do Dataflow.
O parâmetro parallelism ajuda a maximizar o número de ligações paralelas do Splunk HEC, o que, por sua vez, maximiza a taxa de EPS para o seu pipeline.
O valor parallelism predefinido de 1 desativa o paralelismo e limita a taxa de saída. Tem de substituir esta definição predefinida para ter em conta 2 a 4 ligações paralelas por vCPU, com o número máximo de trabalhadores implementados. Por regra, calcula o valor de substituição para esta definição multiplicando o número máximo de trabalhadores do Dataflow pelo número de vCPUs por trabalhador e, em seguida, duplicando este valor.
Para determinar o número total de ligações paralelas ao Splunk HEC em todos os trabalhadores do Dataflow, use a seguinte fórmula:
Exemplo de cálculo: usando o exemplo de CPUs virtuais máximas de 8 que foi calculado anteriormente para a contagem de máquinas, esta fórmula gera o número de ligações paralelas, que é 8 x 2 = 16.
Para este exemplo, definiria o parâmetro parallelism com um valor de 16
com base no cálculo do exemplo anterior. No entanto, lembre-se de usar os seus próprios valores e cálculos únicos quando implementar esta arquitetura de referência no seu ambiente.
Contagem de lotes
Prática recomendada: para permitir que o Splunk HEC processe eventos em lotes em vez de um de cada vez, defina o parâmetro batchCount para um valor entre 10 e 50 eventos/pedido de registos.
A configuração da contagem de lotes ajuda a aumentar o EPS e a reduzir a carga no ponto final do HEC do Splunk. A definição combina vários eventos num único lote para um processamento mais eficiente. Recomendamos que defina o parâmetro batchCount
para um valor entre 10 e 50 eventos/pedido para registos, desde que o atraso máximo
de armazenamento em buffer de dois segundos seja aceitável.
Uma vez que o tamanho médio da mensagem de registo é de 1 KB neste exemplo, recomendamos que
agrupe, pelo menos, 10 eventos por pedido. Para este exemplo, definiria o parâmetro batchCount com um valor de 10. No entanto, lembre-se de usar os seus próprios valores e cálculos únicos quando implementar esta arquitetura de referência no seu ambiente.
Para mais informações sobre estas recomendações de otimização de custos e desempenho, consulte o artigo Planeie o seu pipeline do Dataflow.
O que se segue?
- Para ver uma lista completa dos parâmetros do modelo do Dataflow do Pub/Sub para o Splunk, consulte a documentação do Dataflow do Pub/Sub para o Splunk.
- Para os modelos do Terraform correspondentes que ajudam a implementar esta arquitetura de referência, consulte o repositório do GitHub
terraform-splunk-log-export. Inclui um painel de controlo do Cloud Monitoring pré-criado para monitorizar o seu pipeline do Splunk Dataflow. - Para mais detalhes sobre as métricas personalizadas e o registo do Splunk Dataflow para ajudar a monitorizar e resolver problemas das suas pipelines do Splunk Dataflow, consulte este blogue: Novas funcionalidades de observabilidade para as suas pipelines de streaming do Splunk Dataflow.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.