En este artículo, se describe una solución de exportación de métricas de Cloud Monitoring para realizar un análisis a largo plazo. Cloud Monitoring ofrece una solución de supervisión paraGoogle Cloud y Amazon Web Services (AWS). Cloud Monitoring conserva las métricas durante seis semanas porque el valor de las métricas de supervisión tiene una duración limitada. Por lo tanto, el valor de las métricas históricas disminuye con el tiempo. Después del período de seis semanas, es posible que las métricas agregadas mantengan el valor para el análisis a largo plazo de las tendencias que podrían no ser evidentes con un análisis a corto plazo.
En esta solución, se proporciona una guía con el fin de que puedas comprender los detalles de las métricas para la exportación y una implementación de referencia sin servidores para la exportación de las métricas a BigQuery.
Los informes State of DevOps identificaron las capacidades que impulsan el rendimiento de la entrega de software. Esta solución te ayudará con las siguientes funciones:
- Supervisión y observabilidad
- Sistemas de supervisión para fundamentar las decisiones empresariales
- Funciones de administración visual
Casos de uso de exportación de métricas
Cloud Monitoring recopila métricas y metadatos de Google Cloud, AWS y la instrumentación de la app. Las métricas de supervisión brindan una observabilidad profunda del rendimiento, el tiempo de actividad y el estado general de las apps en la nube a través de una API, paneles y un explorador de métricas. Con estas herramientas, se pueden revisar las 6 semanas anteriores de valores de métricas para su análisis. Si tienes requisitos de análisis de métricas a largo plazo, usa la API de Cloud Monitoring a fin de exportar las métricas para el almacenamiento a largo plazo.
Cloud Monitoring conserva las métricas de las últimas 6 semanas. Se usa con frecuencia para fines operativos, como la supervisión de la infraestructura de la máquina virtual (métricas de red, CPU y memoria) y las métricas de rendimiento de la aplicación (latencia de la solicitud o de la respuesta). Cuando estas métricas exceden los límites de la configuración predeterminada, se activa un proceso operacional mediante alertas.
Las métricas capturadas también pueden ser útiles para el análisis a largo plazo. Por ejemplo, es posible que desees comparar las métricas de rendimiento de la app del Cyber Monday o de otros eventos de tráfico alto con las métricas del año anterior para planificar el próximo evento de tráfico alto. Otro caso de uso es observar el Google Cloud uso del servicio durante un trimestre o un año para prever mejor el costo. También puede haber métricas de rendimiento de la app que desees ver durante meses o años.
En estos ejemplos, es necesario mantener las métricas para el análisis durante un período prolongado. Exportar estas métricas a BigQuery proporciona las capacidades de estadísticas necesarias para abordar estos ejemplos.
Requisitos
A continuación, se detallan los 3 requisitos principales para realizar un análisis a largo plazo de los datos de métricas de Monitoring:
- Exportar los datos desde Cloud Monitoring. Debes exportar los datos de métricas de Cloud Monitoring en forma de valor de métrica agregado.
Es necesario agregar métricas porque almacenar datos
timeseriessin procesar no agrega valor, aunque técnicamente es posible. La mayoría de los análisis a largo plazo se realizan a nivel de la agregación durante un período más largo. El nivel de detalle de la agregación es exclusivo de tu caso práctico, pero recomendamos 1 hora de agregación como mínimo. - Transferir los datos para el análisis. Debes importar las métricas exportadas de Cloud Monitoring a un motor de estadísticas para su análisis.
- Escribir consultas y crear paneles con los datos. Necesitas paneles y acceso SQL estándar para consultar, analizar y visualizar los datos.
Pasos funcionales
- Crear una lista de métricas para incluir en la exportación
- Leer las métricas de la API de Monitoring
- Asignar las métricas del resultado JSON exportado de la API de Monitoring al formato de tabla de BigQuery
- Escribir las métricas en BigQuery
- Crear un cronograma programático para exportar las métricas con regularidad
Arquitectura
El diseño de esta arquitectura aprovecha los servicios administrados para simplificar las operaciones y el esfuerzo de administración, reduce los costos y brinda la capacidad de escalar según sea necesario.
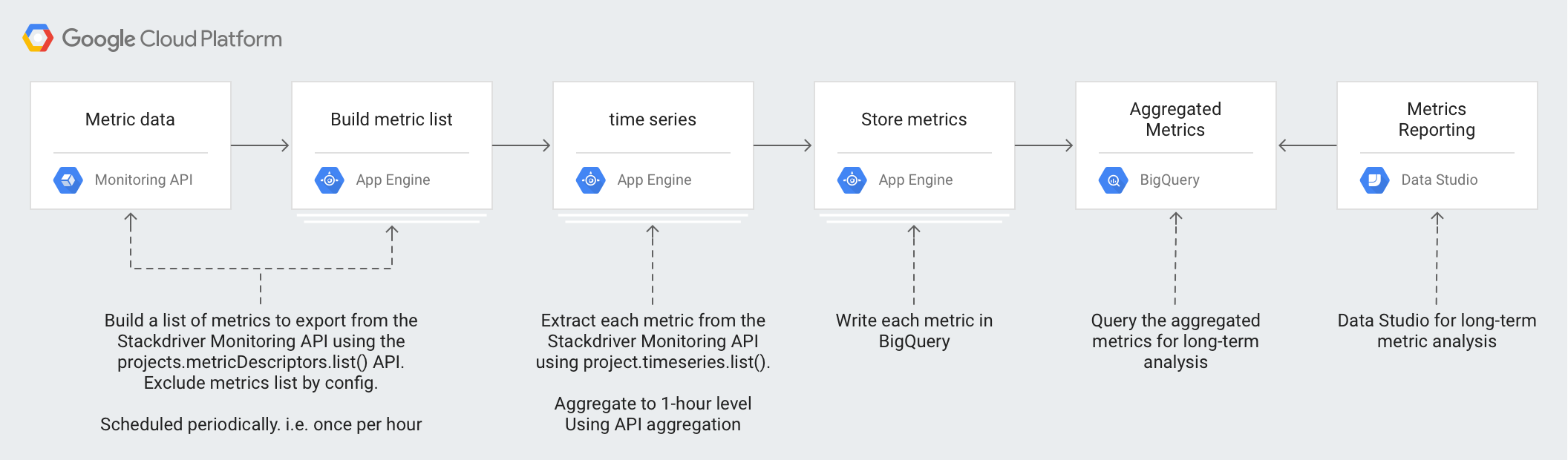
Las siguientes tecnologías se usan en la arquitectura:
- App Engine: Solución de plataforma como servicio escalable (PaaS) que se usa para llamar a la API de Monitoring y escribir en BigQuery
- BigQuery: Un motor de estadísticas completamente administrado que se usa para transferir y analizar los datos
timeseries - Pub/Sub: Un servicio de mensajería en tiempo real completamente administrado que se usa para brindar procesamiento asíncrono escalable
- Cloud Storage: Un almacenamiento unificado de objetos para desarrolladores y empresas que se usa con el fin de almacenar los metadatos sobre el estado de la exportación
- Cloud Scheduler: un programador estilo cron que se usa para ejecutar el proceso de exportación
Información sobre las métricas de Cloud Monitoring
Para comprender cómo exportar las métricas desde Cloud Monitoring con más eficiencia, es importante comprender cómo se almacenan.
Tipos de métricas
Existen 4 tipos principales de métricas en Cloud Monitoring que puedes exportar.
- La lista de métricas deGoogle Cloud son métricas de los servicios de Google Cloud , como Compute Engine y BigQuery.
- La lista de métricas de agentes contiene métricas de instancias de VM que ejecutan los agentes de Cloud Monitoring.
- La lista de métricas de AWS contiene métricas de servicios de AWS, como Amazon Redshift y Amazon CloudFront.
- Las métricas de fuentes externas son métricas de aplicaciones de terceros y métricas definidas por el usuario, incluidas las métricas personalizadas.
Cada uno de estos tipos de métricas tiene un descriptor de métrica, que incluye el tipo y otros metadatos de la métrica. La siguiente métrica es una lista de ejemplo de los descriptores de métrica del método projects.metricDescriptors.list de la API de Monitoring.
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
Los valores importantes que debes comprender del descriptor de métrica son los campos type, valueType y metricKind. Estos campos identifican la métrica y afectan la agregación que es posible para un descriptor de métrica.
Categorías de métricas
Cada métrica tiene una categoría de métrica y un tipo de valor. Para obtener más información, consulta Tipos de valores y categorías de métricas. La categoría de la métrica y el tipo de valor asociado son importantes porque su combinación afecta la forma en que se agregan las métricas.
En el ejemplo anterior, el tipo de métrica pubsub.googleapis.com/subscription/push_request_count metric tiene una categoría de métrica DELTA y un tipo de valor INT64.

En Cloud Monitoring, la categoría de métrica y los tipos de valor se almacenan en metricsDescriptors, que están disponibles en la API de Monitoring.
Timeseries
timeseries son mediciones regulares para cada tipo de métrica almacenado en el tiempo que contienen el tipo de métrica, los metadatos, las etiquetas y los datos medidos individuales. Monitoring recopila métricas de forma automática con regularidad, como las métricas deGoogle Cloud y AWS. Por ejemplo, la métrica appengine.googleapis.com/http/server/response_latencies se recopila cada 60 segundos.
Un conjunto de puntos recopilados para una timeseries determinada puede crecer con el tiempo, según la frecuencia de los datos informados y las etiquetas asociadas con el tipo de métrica. Si exportas los datos timeseries sin procesar, esto podría generar una gran exportación. Para reducir la cantidad de datos timeseries mostrados, puedes agregar las métricas durante un período de alineación determinado. Por ejemplo, si usas la agregación, puedes mostrar un dato por hora para una métrica timeseries determinada que tenga un dato por minuto. Esto reduce la cantidad de datos exportados y el procesamiento de estadísticas necesario en el motor de estadísticas. En este artículo, se muestran timeseries para cada tipo de métrica seleccionado.
Agregación de métricas
Puedes usar la agregación para combinar datos de varias timeseries en una única timeseries. La API de Monitoring proporciona funciones potentes de alineación y agregación de modo que no tengas que realizar la agregación por tu cuenta y pasar los parámetros de alineación y agregación a la llamada a la API. Si quieres obtener más detalles sobre cómo funciona la agregación para la API de Monitoring, lee Filtrado y agregación y esta entrada de blog.
Le asignas metric type a aggregation type para garantizar que las métricas estén alineadas y que timeseries se reduzca a fin de satisfacer tus necesidades de estadísticas.
Hay listas de alineadores y reductores que puedes usar para agregar la timeseries. Los alineadores y reductores tienen un conjunto de métricas que puedes usar para alinear o reducir según las categorías de métrica y los tipos de valores. Por ejemplo, si agregas más de 1 hora, el resultado de la agregación es 1 punto mostrado por hora para la timeseries.
Otra forma de mejorar tu agregación es usar la función Group By, que te permite agrupar los valores en listas de timeseries agregadas. Por ejemplo, puedes elegir agrupar las métricas de App Engine en función del módulo de App Engine. Agrupar según el módulo de App Engine en combinación con los alineadores y reductores que agregan cada 1 hora, produce 1 dato por cada módulo de App Engine por hora.
La agregación de métricas equilibra el costo mayor del registro de datos individuales con la necesidad de retener suficientes datos para un análisis detallado a largo plazo.
Detalles de la implementación de referencia
La implementación de referencia contiene los mismos componentes que se describen en el diagrama de diseño de la arquitectura. A continuación, se describen los detalles funcionales y relevantes de la implementación en cada paso.
Crea una lista de métricas
Cloud Monitoring define más de mil tipos de métricas para ayudarte a supervisar Google Cloud, AWS y software de terceros. La API de Monitoring proporciona el método projects.metricDescriptors.list, que muestra una lista de las métricas disponibles para un proyecto de Google Cloud. La API de Monitoring brinda un mecanismo de filtrado a fin de que puedas filtrar una lista de métricas que deseas exportar para su almacenamiento y análisis a largo plazo.
En la implementación de referencia en GitHub, se usa una app de App Engine en Python con el fin de obtener una lista de métricas y, luego, escribir cada mensaje en un tema de Pub/Sub por separado. La exportación se inicia mediante un Cloud Scheduler que genera una notificación de Pub/Sub para ejecutar la app.
Hay muchas formas de llamar a la API de Monitoring y, en este caso, las APIs de Cloud Monitoring y Pub/Sub se llaman mediante la biblioteca cliente de la API de Google para Python debido a su acceso flexible a las APIs de Google.
Obtén timeseries
Extrae la timeseries para la métrica y, luego, escribe cada timeseries en Pub/Sub. Con la API de Monitoring, puedes agregar los valores de las métricas en un período de alineación determinado con el método project.timeseries.list. Agregar datos reduce tu carga de procesamiento, los requisitos de almacenamiento, los tiempos de consulta y los costos de análisis. La agregación de datos es una práctica recomendada para llevar a cabo un análisis de las métricas a largo plazo de manera eficiente.
En la implementación de referencia en GitHub, se usa una app de App Engine en Python a fin de suscribirse al tema, en la que cada métrica para la exportación se envía como un mensaje independiente. Pub/Sub envía cada mensaje recibido a la app de App Engine. La app obtiene la timeseries para una métrica agregada determinada según la configuración de entrada. En este caso, se llama a las API de Cloud Monitoring y Pub/Sub mediante la biblioteca cliente de la API de Google.
Cada métrica puede mostrar 1 o más timeseries.. Además, cada una se envía mediante un mensaje de Pub/Sub diferente para insertar en BigQuery. La asignación de las métricas type-to-aligner y type-to-reducer está incorporada en la implementación de referencia. En la siguiente tabla, se resume la asignación usada en la implementación de referencia según las clases de categorías de métricas y tipos de valores compatibles con los alineadores y reductores.
| Tipo de valor | GAUGE |
Alineador | Reductor | DELTA |
Alineador | Reductor | CUMULATIVE2 |
Alineador | Reductor |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
Sí |
ALIGN_FRACTION_TRUE
|
Ninguno | No | No aplica | No aplica | No | No aplica | No aplica |
INT64 |
Sí |
ALIGN_SUM
|
Ninguno | Sí |
ALIGN_SUM
|
Ninguno | Sí | Ninguno | Ninguno |
DOUBLE |
Sí |
ALIGN_SUM
|
Ninguno | Sí |
ALIGN_SUM
|
Ninguno | Sí | Ninguno | Ninguno |
STRING |
Sí | Excluido | Excluido | No | No aplica | No aplica | No | No aplica | No aplica |
DISTRIBUTION |
Sí |
ALIGN_SUM
|
Ninguno | Sí |
ALIGN_SUM
|
Ninguno | Sí | Ninguno | Ninguno |
MONEY |
No | No aplica | No aplica | No | No aplica | No aplica | No | No aplica | No aplica |
Es importante considerar la asignación de valueType a alineadores y reductores porque la agregación solo se puede aplicar a valueTypes y metricKinds específicos para cada alineador y reductor.
Por ejemplo, considera el tipo pubsub.googleapis.com/subscription/push_request_count metric. Según la categoría de la métrica DELTA y el tipo de valor INT64, puedes agregar la métrica de la siguiente manera:
- Período de alineación: 3,600 s (1 hora)
Aligner = ALIGN_SUM: El dato resultante en el período de alineación es la suma de todos los datos del período de alineación.Reducer = REDUCE_SUM: Reduce mediante el cálculo de la suma en unatimeseriespara cada período de alineación.
Junto con los valores del período de alineación, del alineador y del reductor, el método project.timeseries.list necesita las siguientes entradas:
filter: Selecciona la métrica que se mostrará.startTime: Selecciona el punto de partida en el momento en el que se mostrarátimeseries.endTime: Selecciona el último momento en el que se mostrarátimeseries.groupBy: Ingresa los campos en los que se agrupará la respuesta detimeseries.alignmentPeriod: Ingresa los períodos en los que deseas alinear las métricas.perSeriesAligner: Alinea los puntos en intervalos regulares definidos por unalignmentPeriod.crossSeriesReducer: Combina varios puntos con diferentes valores de etiqueta en un solo punto por intervalo.
La solicitud GET a la API incluye todos los parámetros descritos en la lista anterior.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
Con la siguiente solicitud HTTP GET, se proporciona una llamada de ejemplo al método de la API projects.timeseries.list mediante los parámetros de entrada:
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
La llamada a la API de Monitoring anterior incluye un crossSeriesReducer=REDUCE_SUM, lo que significa que las métricas se contraen y se reducen a una sola suma, como se muestra en el ejemplo siguiente.
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
Este nivel de agregación incorpora datos a un único dato y lo convierte en una métrica ideal para tu proyecto general de Google Cloud . Sin embargo, no te permite analizar qué recursos contribuyeron a la métrica. En el ejemplo anterior, no puedes saber qué suscripción de Pub/Sub contribuyó más al recuento de solicitudes.
Si deseas revisar los detalles de los componentes individuales que generan la timeseries, puedes quitar el parámetro crossSeriesReducer.
Sin el crossSeriesReducer, la API de Monitoring no combina las diferentes timeseries para crear un valor único.
En la siguiente HTTP GET, se proporciona una llamada de ejemplo al método de la API projects.timeseries.list mediante los parámetros de entrada. El crossSeriesReducer no está incluido.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
En la siguiente respuesta JSON, las metric.labels.keys son las mismas en ambos resultados porque la timeseries está agrupada. Por cada uno de los valores resource.labels.subscription_ids, se muestran puntos por separado. Revisa los valores metric_export_init_pub y metrics_list en la respuesta JSON que aparece a continuación. Se recomienda este nivel de agregación porque te permite usar productos deGoogle Cloud , incluidos como etiquetas de recursos, en tus consultas de BigQuery.
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
Cada métrica en el resultado JSON de la llamada a la API projects.timeseries.list se escribe directamente en Pub/Sub como un mensaje independiente. Podría ocurrir un fan-out en el que 1 métrica de entrada genera 1 o más timeseries.
Pub/Sub ofrece la habilidad de absorber un posible fan-out grande sin exceder el tiempo de espera.
El período de alineación proporcionado como entrada significa que los valores de ese período se agregan en un solo valor como se muestra en la respuesta del ejemplo anterior. El período de alineación también define con qué frecuencia se debe ejecutar la exportación. Por ejemplo, si tu período de alineación es de 3,600 s o 1 hora, la exportación se ejecuta cada hora para exportar el timeseries con regularidad.
Almacena métricas
En la implementación de referencia en GitHub, se usa una app de App Engine en Python para leer cada timeseries y, luego, insertar los registros en la tabla de BigQuery. Pub/Sub envía cada mensaje recibido a la app de App Engine. El mensaje de Pub/Sub contiene datos de métricas exportados desde la API de Monitoring en formato JSON y deben asignarse a una estructura de tabla en BigQuery. En este caso, se llama a las API de BigQuery mediante la biblioteca cliente de la API de Google.
El esquema de BigQuery está diseñado para asignar a los datos JSON exportados desde la API de Monitoring. Cuando se crea el esquema de tabla de BigQuery, hay que considerar el escalamiento de los tamaños de los datos, ya que aumentan con el tiempo.
En BigQuery, se recomienda que particiones la tabla según un campo de fecha, porque esto puede hacer que las consultas sean más eficientes, ya que se seleccionan períodos sin incurrir en un análisis completo de la tabla. Si planeas ejecutar la exportación con regularidad, es seguro usar la partición predeterminada según la fecha de transferencia.
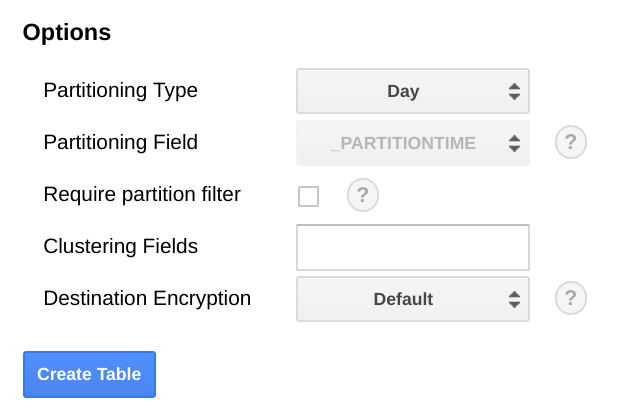
Si planeas subir métricas de forma masiva o si no ejecutas la exportación con frecuencia, realiza la partición en el end_time,, lo que requiere cambios en el esquema de BigQuery. Puedes mover el end_time a un campo de nivel superior en el esquema, en el que puedes usarlo para particionar o puedes agregar un campo nuevo al esquema. Mover el campo end_time es obligatorio porque el campo se encuentra en un registro de BigQuery y la partición debe realizarse en un campo de nivel superior. Para obtener más información, lee la documentación sobre la partición en BigQuery.
BigQuery también te permite establecer un vencimiento para los conjuntos de datos, tablas y particiones de tablas.
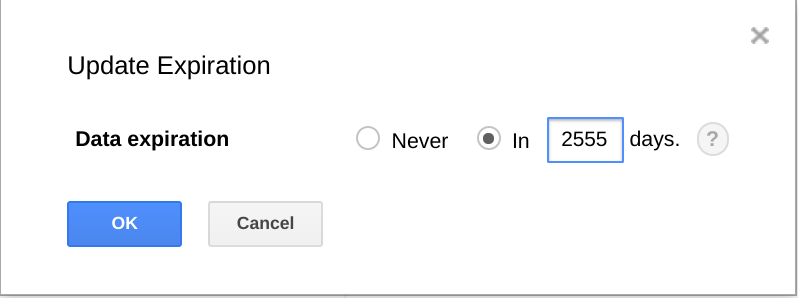
Usar esta función es una forma práctica de borrar definitivamente los datos más antiguos cuando ya no son útiles. Por ejemplo, si tu análisis cubre un período de 3 años, puedes agregar una política para borrar datos de más de 3 años.
Programa la exportación
Cloud Scheduler es un programador de trabajos cron completamente administrado. Cloud Scheduler te permite usar el formato de programación cron estándar para activar una app de App Engine, enviar un mensaje mediante Pub/Sub o enviar un mensaje a un extremo HTTP arbitrario.
En la implementación de referencia en GitHub, Cloud Scheduler activa la app list-metrics de App Engine cada hora mediante el envío de un mensaje de Pub/Sub con un token que coincide con la configuración de App Engine. El período de agregación predeterminado en la configuración de la app es de 3,600 s o 1 hora, que se correlaciona con la frecuencia con la que se activa la app. Se recomienda un mínimo de 1 hora de agregación porque proporciona un equilibrio entre la reducción de los volúmenes de datos y la retención de datos de alta fidelidad. Si usas un período de alineación diferente, cambia la frecuencia de la exportación para que se corresponda con el período de alineación. La implementación de referencia almacena el último valor end_time en Cloud Storage y usa ese valor como el start_time posterior, a menos que se pase un start_time como parámetro.
En la siguiente captura de pantalla de Cloud Scheduler, se muestra cómo puedes usar la consola de Google Cloud para configurar Cloud Scheduler con el fin de que invoque a la app de App Engine list-metrics cada hora.
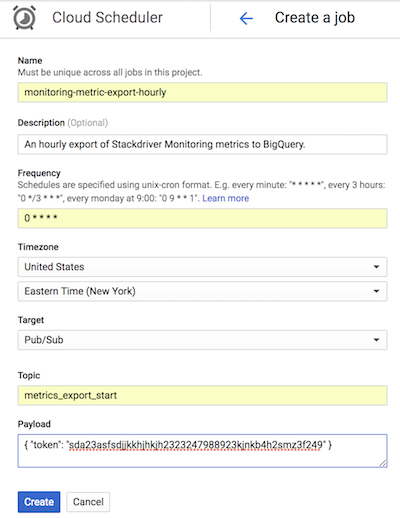
En el campo Frecuencia (Frequency), se usa la sintaxis de estilo cron para indicar a Cloud Scheduler con qué frecuencia debe ejecutar la aplicación. En el Destino (Target), se especifica un mensaje de Pub/Sub que se genera y, en el campo Carga útil (Payload), están los datos que contiene el mensaje de Pub/Sub.
Usa las métricas exportadas
Con los datos exportados en BigQuery, ahora puedes usar SQL estándar para consultar los datos o compilar paneles a fin de visualizar tendencias en tus métricas a lo largo del tiempo.
Consulta de muestra: latencias de App Engine
Con la consulta siguiente, se encuentra el mínimo, el máximo y el promedio de los valores medios de métrica de latencia para una app de App Engine. El metric.type identifica la métrica de App Engine, y las etiquetas identifican la app de App Engine en función del valor de la etiqueta project_id. Se usa point.value.distribution_value.mean porque esta métrica es un valor de DISTRIBUTION en la API de Monitoring, que se asigna al objeto de campo distribution_value en BigQuery. Con el campo end_time, se revisan los valores de los últimos 30 días.
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
Consulta de muestra: recuentos de consultas de BigQuery
Con la siguiente consulta, se muestra la cantidad de consultas en BigQuery por día en un proyecto. El campo int64_value se usa porque esta métrica es un valor INT64 en la API de Monitoring, que se asigna al campo int64_value en BigQuery. El metric.type identifica la métrica de BigQuery, y las etiquetas identifican al proyecto en función del valor de la etiqueta project_id. Con el campo end_time, se revisan los valores de los últimos 30 días.
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
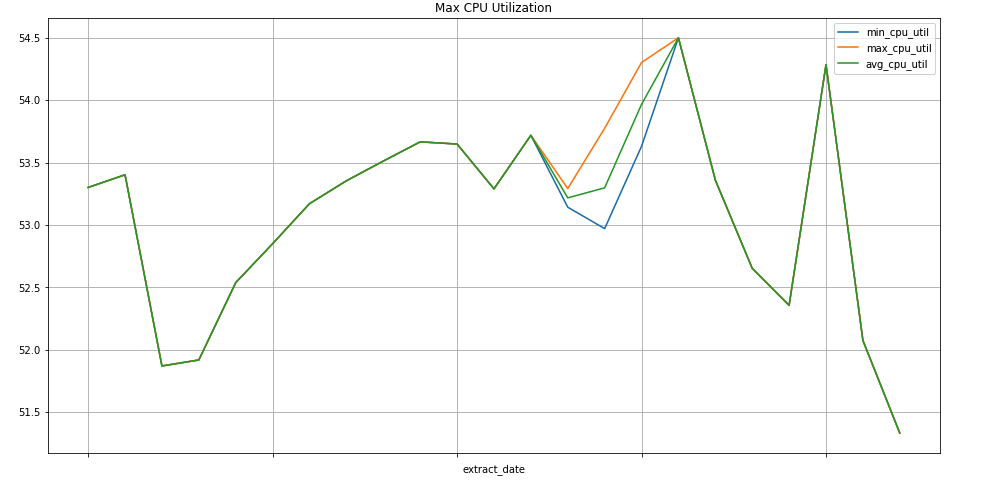
Consulta de muestra: instancias de Compute Engine
Con la siguiente consulta, se encuentra el valor mínimo, máximo y promedio semanal de los valores de métricas de uso de CPU para las instancias de Compute Engine de un proyecto. El metric.type identifica la métrica de Compute Engine, y las etiquetas identifican las instancias en función del valor de la etiqueta project_id. Con el campo end_time, se revisan los valores de los últimos 30 días.
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
Visualización de datos
BigQuery está integrado a muchas herramientas que puedes usar para visualizar datos.
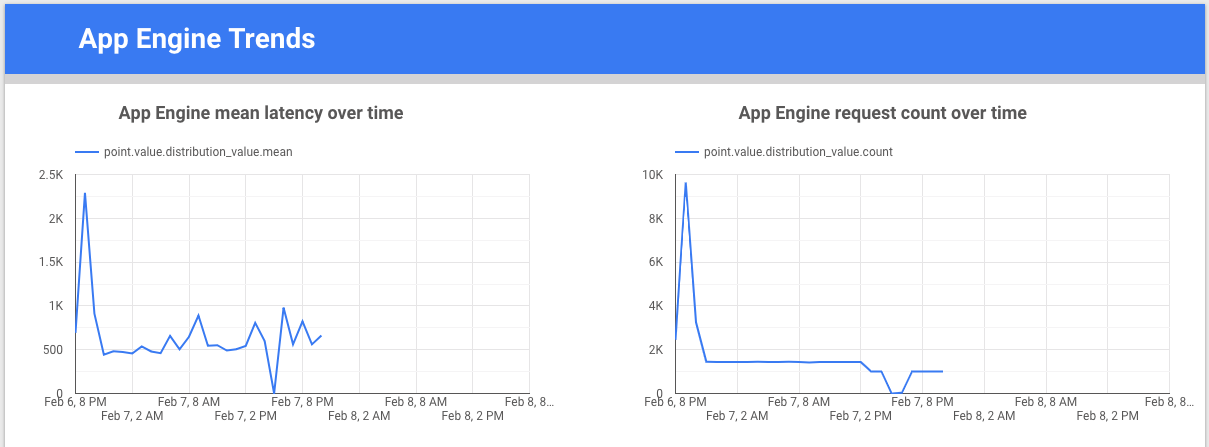
Looker Studio es una herramienta gratuita creada por Google que te permite compilar gráficos y paneles de datos para visualizar los datos de las métricas y compartirlos con tu equipo. En el siguiente ejemplo, se muestra un gráfico de línea de tendencia de la latencia y el recuento de la métrica appengine.googleapis.com/http/server/response_latencies a lo largo del tiempo.
Colaboratory es una herramienta de investigación para la educación y la investigación en el campo del aprendizaje automático. Es un entorno de notebook de Jupyter alojado que no requiere configuración para usar y acceder a datos en BigQuery. Con un notebook de Colaboratory, comandos de Python y consultas de SQL, puedes desarrollar análisis y visualizaciones detallados.
Supervisa la implementación de referencia de la exportación
Cuando se ejecuta la exportación, debes supervisarla. Para decidir qué métricas supervisar, puedes establecer un objetivo de nivel de servicio (SLO). Un SLO es un valor objetivo o un rango de valores para un nivel de servicio que se mide mediante una métrica. En el libro sobre ingeniería de confiabilidad de sitios, se describen 4 áreas principales para los SLO: disponibilidad, capacidad de procesamiento, tasa de error y latencia. Para una exportación de datos, la capacidad de procesamiento y la tasa de error son dos consideraciones principales, y puedes supervisarlas a través de las métricas siguientes:
- Capacidad de procesamiento:
appengine.googleapis.com/http/server/response_count - Tasa de error:
logging.googleapis.com/log_entry_count
Por ejemplo, puedes supervisar la tasa de error con la métrica log_entry_count y con filtros para las apps de App Engine (list-metrics, get-timeseries, write-metrics) con una gravedad de ERROR. Luego, puedes usar las políticas de alertas en Cloud Monitoring para recibir avisos de errores encontrados en la app de exportación.
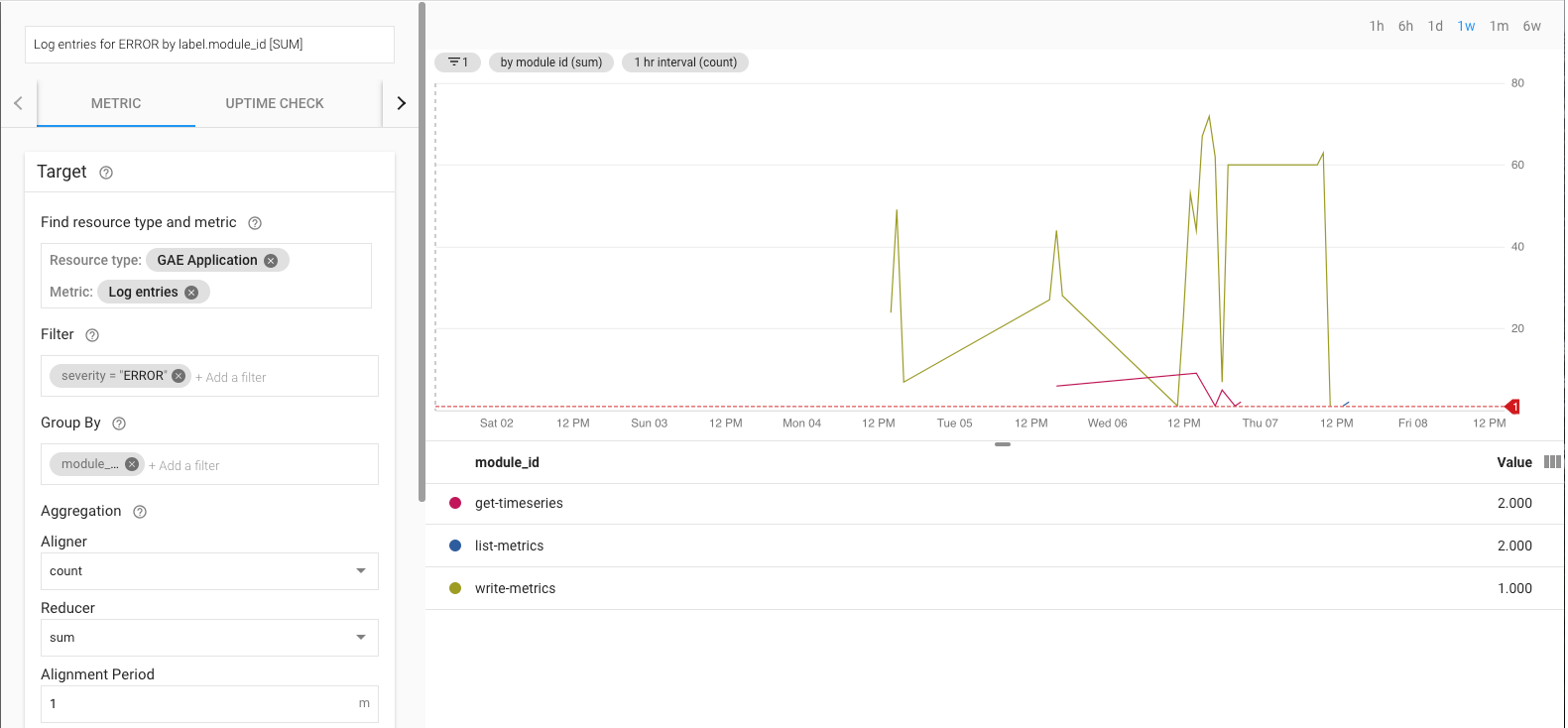
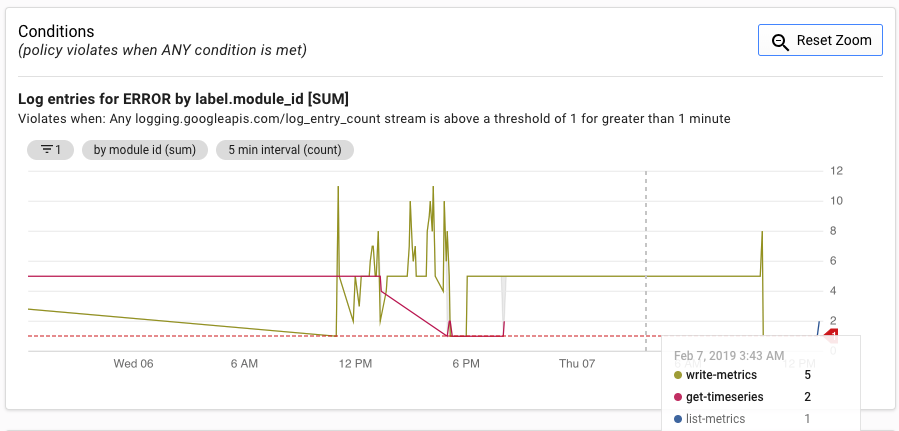
En la IU de alertas, se muestra un grafo de la métrica log_entry_count en comparación con el límite para generar la alerta.
¿Qué sigue?
- Ve la implementación de referencia en GitHub.
- Consulta los documentos de Cloud Monitoring.
- Consulta los documentos de la API de Cloud Monitoring v3.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.
- Lee nuestros recursos sobre DevOps.
Obtén más información sobre las funciones de DevOps relacionadas con esta solución:
Realiza la verificación rápida de DevOps para comprender cuál es tu posición en comparación con el resto de la industria.