This document describes a solution for exporting Cloud Monitoring metrics for long-term analysis. Cloud Monitoring provides a monitoring solution for Google Cloud. Cloud Monitoring maintains metrics for six weeks because the value in monitoring metrics is often time-bound. Therefore, the value of historical metrics decreases over time. After the six-week window, aggregated metrics might still hold value for long-term analysis of trends that might not be apparent with short-term analysis.
This solution provides a guide to understanding the metric details for export and a serverless reference implementation for metric export to BigQuery.
The State of DevOps reports identified capabilities that drive software delivery performance. This solution will help you with the following capabilities:
- Monitoring and observability
- Monitoring systems to inform business decisions
- Visual management capabilities
Exporting metrics use cases
Cloud Monitoring collects metrics and metadata from Google Cloud and app instrumentation. Monitoring metrics provide deep observability into performance, uptime, and overall health of cloud apps through an API, dashboards, and a metrics explorer. These tools provide a way to review the previous 6 weeks of metric values for analysis. If you have long-term metric analysis requirements, use the Cloud Monitoring API to export the metrics for long-term storage.
Cloud Monitoring maintains the latest 6 weeks of metrics. It is frequently used for operational purposes such as monitoring virtual machine infrastructure (CPU, memory, network metrics) and application performance metrics (request or response latency). When these metrics exceed preset thresholds, an operational process is triggered through alerting.
The captured metrics might also be useful for long-term analysis. For example, you might want to compare app performance metrics from Cyber Monday or other high-traffic events against metrics from the previous year to plan for the next high-traffic event. Another use case is to look at Google Cloud service usage over a quarter or year to better forecast cost. There might also be app performance metrics that you want to view across months or years.
In these examples, maintaining the metrics for analysis over a long-term timeframe is required. Exporting these metrics to BigQuery provides the necessary analytical capabilities to address these examples.
Requirements
To perform long-term analysis on Monitoring metric data, there are 3 main requirements:
- Export the data from Cloud Monitoring. You need to export
the Cloud Monitoring metric data as an aggregated metric value.
Metric aggregation is required because storing raw
timeseriesdata points, while technically feasible, doesn't add value. Most long-term analysis is performed at the aggregate level over a longer timeframe. The granularity of the aggregation is unique to your use case, but we recommend a minimum of 1 hour aggregation. - Ingest the data for analysis. You need to import the exported Cloud Monitoring metrics to an analytics engine for analysis.
- Write queries and build dashboards against the data. You need dashboards and standard SQL access to query, analyze, and visualize the data.
Functional steps
- Build a list of metrics to include in the export.
- Read metrics from the Monitoring API.
- Map the metrics from the exported JSON output from the Monitoring API to the BigQuery table format.
- Write the metrics to BigQuery.
- Create a programmatic schedule to regularly export the metrics.
Architecture
The design of this architecture leverages managed services to simplify your operations and management effort, reduces costs, and provides the ability to scale as required.

The diagram shows the following architecture implementation:
- Build metric list: Export metric data from the Cloud Monitoring API and build a list of metrics
by using the
project.metricsDescriptors.list()method. Exclude metrics list by using configurations. Schedule the task to run periodically (for example, once per hour). - Get
timeseries: Use theproject.timeseries.list()method to extract each metric from the Monitoring API. Aggregate to a 1-hour level by using API aggregation. - Store metrics: App Engine writes each metric to BigQuery.
- Aggregate metrics: Query the aggregated metrics by using BigQuery.
- Report metrics: Use Looker Studio for long-term analysis.
The following technologies are used in the architecture:
- App Engine - Scalable platform as a service (PaaS) solution used to call the Monitoring API and write to BigQuery.
- BigQuery - A fully-managed analytics engine used to
ingest and analyze the
timeseriesdata. - Pub/Sub - A fully-managed real-time messaging service used to provide scalable asynchronous processing.
- Cloud Storage - A unified object storage for developers and enterprises used to store the metadata about the export state.
- Cloud Scheduler - A cron-style scheduler used to execute the export process.
Understanding Cloud Monitoring metrics details
To understand how to best export metrics from Cloud Monitoring, it's important to understand how it stores metrics.
Types of metrics
There are 4 main types of metrics in Cloud Monitoring that you can export.
- Google Cloud metrics list are metrics from Google Cloud services, such as Compute Engine and BigQuery.
- Agent metrics list are metrics from VM instances running the Cloud Monitoring agents.
- Metrics from external sources are metrics from third-party applications, and user-defined metrics, including custom metrics.
Each of these metric types have a
metric descriptor,
which includes the metric type, as well as other metric metadata. The following
metric is an example listing of the metric descriptors from the
Monitoring API
projects.metricDescriptors.list
method.
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
The important values to understand from the metric descriptor are the type,
valueType, and metricKind fields. These fields identify the metric and
impact the aggregation that is possible for a metric descriptor.
Kinds of metrics
Each metric has a metric kind and a value type. For more information, read Value types and metric kinds. The metric kind and the associated value type are important because their combination affects the way the metrics are aggregated.
In the preceding example, the
pubsub.googleapis.com/subscription/push_request_count metric
metric type has a DELTA metric kind and an INT64 value type.

In Cloud Monitoring, the metric kind and value types are stored in
metricsDescriptors, which are available in the Monitoring API.
Timeseries
timeseries are regular measurements for each metric type stored over time
that contain the metric type, metadata, labels and the individual measured data
points. Metrics collected automatically by Monitoring, such as
Google Cloud metrics, are collected regularly. As an example, the
appengine.googleapis.com/http/server/response_latencies
metric is collected every 60 seconds.
A collected set of points for a given timeseries might grow over time, based
on the frequency of the data reported and any labels associated with the metric
type. If you export the raw timeseries data points, this might result in a
large export. To reduce the number of timeseries data points returned, you can
aggregate the metrics over a given alignment period. For example, by using
aggregation you can return one data point per hour for a given metric
timeseries that has one data point per minute. This reduces the number of
exported data points and reduces the analytical processing required in the
analytics engine. In this article, timeseries are returned for each metric
type selected.
Metric aggregation
You can use aggregation to combine data from several timeseries into a single
timeseries. The Monitoring API provides powerful alignment and
aggregation functions so that you don't have to perform the aggregation
yourself, passing the alignment and aggregation parameters to the API call. For
more details about how aggregation works for the Monitoring API,
read
Filtering and aggregation
and this
blog post.
You map metric typeto aggregation type to ensure that the metrics are
aligned and that the timeseries is reduced to meet your analytical needs.
There are lists of
aligners
and
reducers,
that you can use to aggregate the timeseries. Aligners and reducers have a set
of metrics that you can use to align or reduce based on the metric kinds
and value types. As an example, if you aggregate over 1 hour, then the result of
the aggregation is 1 point returned per hour for the
timeseries.
Another way to fine-tune your aggregation is to use the Group By function,
which lets you group the aggregated values into lists of aggregated
timeseries. For example, you can choose to group App Engine metrics
based on the App Engine module. Grouping by the App Engine
module in combination with the aligners and reducers aggregating to 1 hour,
produces 1 data point per App Engine module per hour.
Metric aggregation balances the increased cost of recording individual data points against the need to retain enough data for a detailed long-term analysis.
Reference implementation details
The reference implementation contains the same components as described in the Architecture design diagram. The functional and relevant implementation details in each step are described in the following sections.
Build metric list
Cloud Monitoring defines over a thousand metric types to help you
monitor Google Cloud and third-party software. The
Monitoring API provides the
projects.metricDescriptors.list
method, which returns a list of metrics available to a Google Cloud
project. The Monitoring API provides a filtering mechanism so that you
can filter to a list of metrics that you want to export for long-term storage
and analysis.
The reference implementation in GitHub uses a Python App Engine app to get a list of metrics and then writes each message to a Pub/Sub topic separately. The export is initiated by a Cloud Scheduler that generates a Pub/Sub notification to run the app.
There are many ways to call the Monitoring API and in this case, the Cloud Monitoring and Pub/Sub APIs are called by using the Google API Client Library for Python because of its flexible access to the Google APIs.
Get timeseries
You extract the timeseries for the metric and then write each timeseries to
Pub/Sub. With the Monitoring API you can aggregate the
metric values across a given alignment period by using the
project.timeseries.list
method. Aggregating data reduces your processing load, storage requirements,
query times, and analysis costs. Data aggregation is a best practice for
efficiently conducting long-term metric analysis.
The reference implementation in GitHub uses a Python App Engine app to
subscribe to the topic, where each metric for export is sent as a separate
message. For each message that is received, Pub/Sub pushes the
message to the App Engine app. The app gets the timeseries for a given
metric aggregated based on the input configuration. In this case, the
Cloud Monitoring and Pub/Sub APIs are called by using the
Google API Client Library.
Each metric can return 1 or more timeseries. Each metric is sent by a separate
Pub/Sub message to insert into BigQuery. The
metric type-to-aligner and metric type-to-reducer mapping is built into the
reference implementation. The following table captures the mapping used in the
reference implementation based on the classes of metric kinds and value types
supported by the aligners and reducers.
| Value type | GAUGE |
Aligner | Reducer | DELTA |
Aligner | Reducer | CUMULATIVE2 |
Aligner | Reducer |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
yes |
ALIGN_FRACTION_TRUE
|
none | no | N/A | N/A | no | N/A | N/A |
INT64 |
yes |
ALIGN_SUM
|
none | yes |
ALIGN_SUM
|
none | yes | none | none |
DOUBLE |
yes |
ALIGN_SUM
|
none | yes |
ALIGN_SUM
|
none | yes | none | none |
STRING |
yes | excluded | excluded | no | N/A | N/A | no | N/A | N/A |
DISTRIBUTION |
yes |
ALIGN_SUM
|
none | yes |
ALIGN_SUM
|
none | yes | none | none |
MONEY |
no | N/A | N/A | no | N/A | N/A | no | N/A | N/A |
It's important to consider the mapping of valueType to aligners and reducers
because aggregation is only possible for specific valueTypes and metricKinds
for each aligner and reducer.
For example, consider the
pubsub.googleapis.com/subscription/push_request_count metric
type. Based on the DELTA metric kind and INT64 value type, one way that you
can aggregate the metric is:
- Alignment Period - 3600s (1 hour)
Aligner = ALIGN_SUM- The resulting data point in the alignment period is the sum of all data points in the alignment period.Reducer = REDUCE_SUM- Reduce by computing the sum across atimeseriesfor each alignment period.
Along with the alignment period, aligner, and reducer values, the
project.timeseries.list
method requires several other inputs:
filter- Select the metric to return.startTime- Select the starting point in time for which to returntimeseries.endTime- Select the last time point in time for which to returntimeseries.groupBy- Enter the fields upon which to group thetimeseriesresponse.alignmentPeriod- Enter the periods of time into which you want the metrics aligned.perSeriesAligner- Align the points into even time intervals defined by analignmentPeriod.crossSeriesReducer- Combine multiple points with different label values down to one point per time interval.
The GET request to the API includes all the parameters described in the preceding list.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
The following HTTP GET provides an example call to the
projects.timeseries.list API method by using the input parameters:
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
The preceding Monitoring API call includes a
crossSeriesReducer=REDUCE_SUM, which means that the metrics are collapsed and
reduced into a single sum as shown in the following example.
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
This level of aggregation aggregates data into a single data point, making it an ideal metric for your overall Google Cloud project. However, it doesn't let you drill into which resources contributed to the metric. In the preceding example, you can't tell which Pub/Sub subscription contributed the most to the request count.
If you want to review the details of the individual components generating the
timeseries, you can remove the crossSeriesReducer parameter.
Without the crossSeriesReducer, the Monitoring API doesn't combine
the various timeseries to create a single value.
The following HTTP GET provides an example call to the
projects.timeseries.list API method by using the input parameters. The
crossSeriesReducer isn't included.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
In the following JSON response, the metric.labels.keys are the same across
both of the results because the timeseries is grouped. Separate points are
returned for each of the resource.labels.subscription_ids values. Review the
metric_export_init_pub and metrics_list values in the following
JSON. This level of aggregation is recommended because it allows you to use
Google Cloud products, included as resource labels, in your
BigQuery queries.
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
Each metric in the JSON output of the projects.timeseries.list API call is
written directly to Pub/Sub as a separate message. There is a
potential fan-out where 1 input metric generates 1 or more timeseries.
Pub/Sub provides the ability to absorb a potentially large fan-out
without exceeding timeouts.
The alignment period provided as input means that the values over that
timeframe are aggregated into a single value as shown in the preceding example
response. The alignment period also defines how often to run the export. For
example, if your alignment period is 3600s, or 1 hour, then the export runs
every hour to regularly export the timeseries.
Store metrics
The reference implementation in GitHub uses a Python App Engine app to
read each timeseries and then insert the records into the
BigQuery table. For each message that is received,
Pub/Sub pushes the message to the App Engine app. The
Pub/Sub message contains metric data exported from the
Monitoring API in a JSON format and needs to be mapped to a table
structure in BigQuery. In this case, the BigQuery APIs are
called using the Google API Client Library..
The BigQuery schema is designed to map closely to the JSON exported from the Monitoring API. When building the BigQuery table schema, one consideration is the scale of the data sizes as they grow over time.
In BigQuery, we recommend that you partition the table based on a date field because it can make queries more efficient by selecting date ranges without incurring a full table scan. If you plan to run the export regularly, you can safely use the default partition based on ingestion date.
If you plan to upload metrics in bulk or don't run the export periodically,
partition on the end_time, which does require changes to the
BigQuery schema. You can either move the end_time to a
top-level field in the schema, where you can use it for partitioning, or add a
new field to the schema. Moving the end_time field is required because the
field is contained in a BigQuery record and
partitioning must be done on a top-level field. For more information, read the
BigQuery partitioning documentation.
BigQuery also provides the ability to expire datasets, tables, and table partitions after an amount of time.
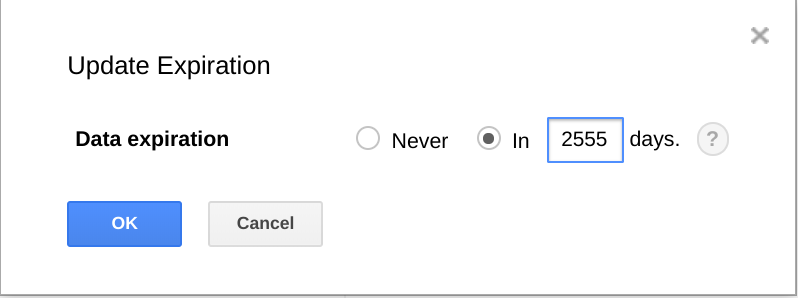
Using this feature is a useful way to purge older data when the data is no longer useful. For example, if your analysis covers a 3-year time period, you can add a policy to delete data older than 3 years old.
Schedule export
Cloud Scheduler is a fully-managed cron job scheduler. Cloud Scheduler lets you use the standard cron schedule format to trigger an App Engine app, send a message by using Pub/Sub, or send a message to an arbitrary HTTP endpoint.
In the reference implementation in GitHub, Cloud Scheduler triggers
the list-metrics App Engine app every hour by sending a
Pub/Sub message with a token that matches the App Engine's
configuration. The default aggregation period in the app configuration is 3600s,
or 1 hour, which correlates to how often the app is triggered. A minimum of 1
hour aggregation is recommended because it provides a balance between reducing
data volumes and still retaining high fidelity data. If you use a different
alignment period, change the frequency of the export to correspond to the
alignment period. The reference implementation stores the last end_time value
in Cloud Storage and uses that value as the subsequent start_time
unless a start_time is passed as a parameter.
The following screenshot from Cloud Scheduler demonstrates how you can
use the Google Cloud console to configure the Cloud Scheduler to
invoke the list-metrics App Engine app every hour.
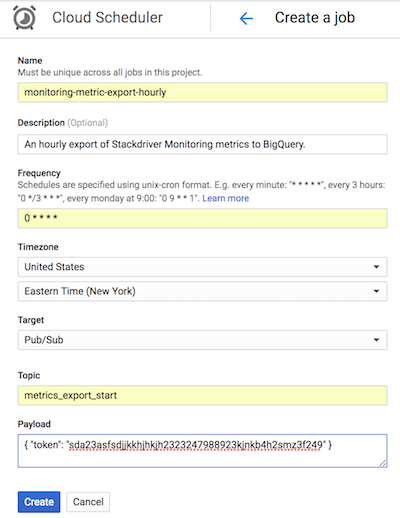
The Frequency field uses the cron-style syntax to tell Cloud Scheduler how frequently to execute the app. The Target specifies a Pub/Sub message that is generated, and the Payload field contains the data contained in the Pub/Sub message.
Using the exported metrics
With the exported data in BigQuery, you can now use standard SQL to query the data or build dashboards to visualize trends in your metrics over time.
Sample query: App Engine latencies
The following query finds the minimum, maximum, and average of the mean latency
metric values for an App Engine app. The metric.type identifies the
App Engine metric, and the labels identify the App Engine app
based on the project_id label value. The point.value.distribution_value.mean
is used because this metric is a DISTRIBUTION value in the
Monitoring API, which is mapped to the distribution_value field
object in BigQuery. Theend_time field looks back over the
values for the past 30 days.
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
Sample query: BigQuery query counts
The following query returns the number of queries against
BigQuery per day in a project. The int64_value field is used
because this metric is an INT64 value in the Monitoring API, which
is mapped to the int64_value field in BigQuery. The
metric.typeidentifies the BigQuery metric, and the labels
identify the project based on the project_id label value. The end_time field
looks back over the values for the past 30 days.
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
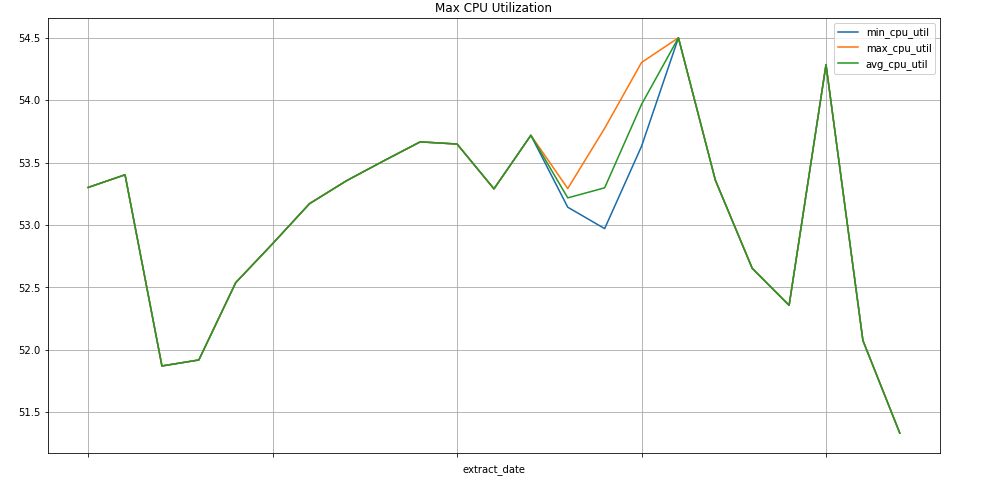
Sample query: Compute Engine instances
The following query finds the weekly minimum, maximum, and average of the CPU
usage metric values for Compute Engine instances of a project. The
metric.type identifies the Compute Engine metric, and the labels
identify the instances based on the project_id label value. The end_time
field looks back over the values for the past 30 days.
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
Data visualization
BigQuery is integrated with many tools that you can use for data visualization.
Looker Studio
is a free tool built by Google where you can build data charts and dashboards to
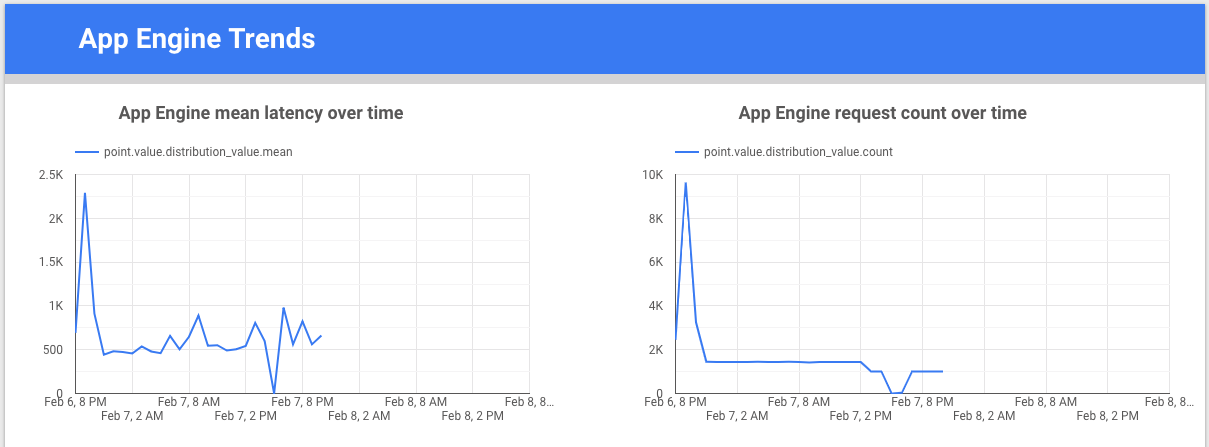
visualize the metric data, and then share them with your team. The following
example shows a trendline chart of the latency and count for the
appengine.googleapis.com/http/server/response_latencies metric over time.
Colaboratory is a research tool for machine learning education and research. It's a hosted Jupyter notebook environment that requires no set up to use and access data in BigQuery. Using a Colab notebook, Python commands, and SQL queries, you can develop detailed analysis and visualizations.
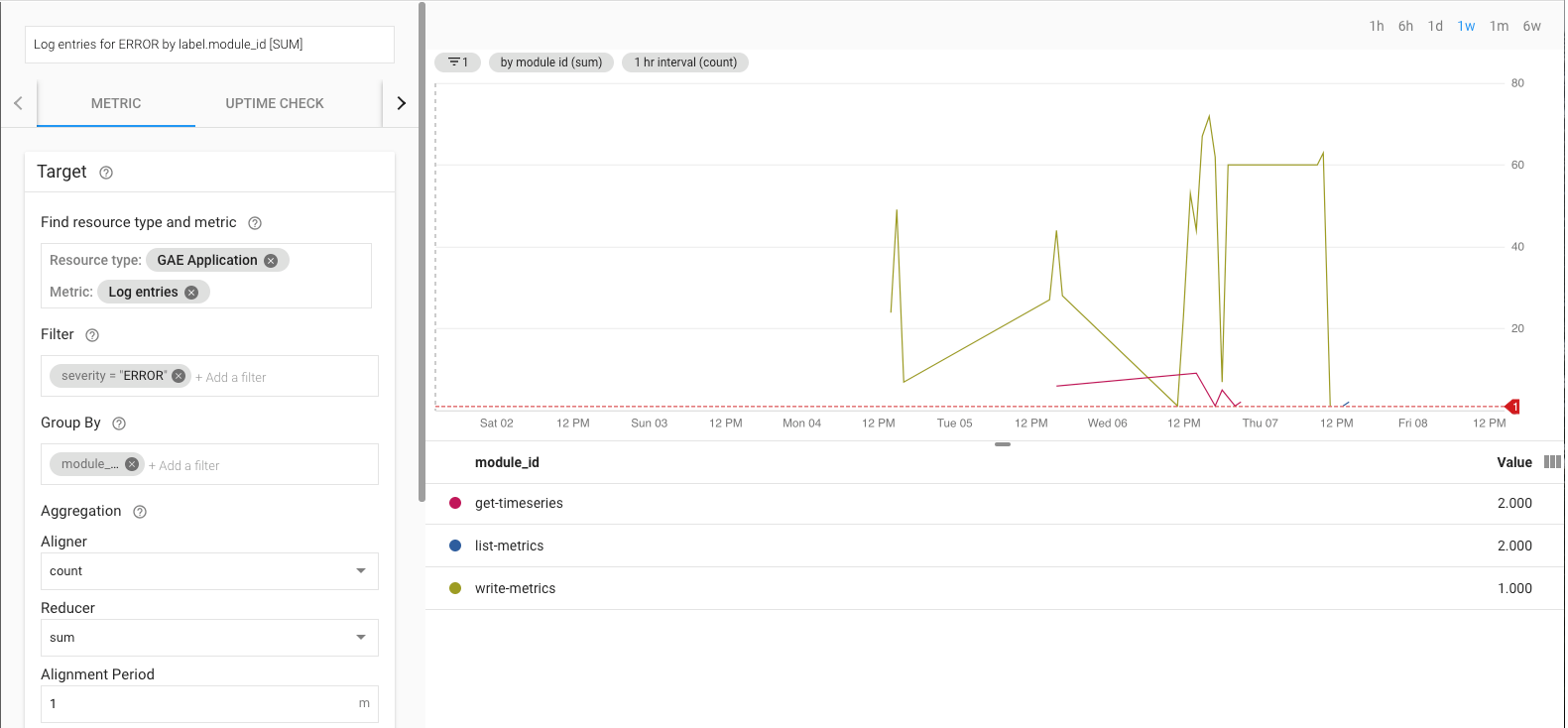
Monitoring the export reference implementation
When the export is running, you need to monitor the export. One way to decide which metrics to monitor is to set a Service Level Objective (SLO). An SLO is a target value or range of values for a service level that is measured by a metric. The Site reliability engineering book describes 4 main areas for SLOs: availability, throughput, error rate, and latency. For a data export, throughput and error rate are two major considerations and you can monitor them through the following metrics:
- Throughput -
appengine.googleapis.com/http/server/response_count - Error rate -
logging.googleapis.com/log_entry_count
For example, you can monitor the error rate by using the log_entry_count
metric and filtering it for the App Engine apps (list-metrics,
get-timeseries, write-metrics) with a severity of ERROR. You can then use the
Alerting policies
in Cloud Monitoring to alert you of errors encountered in the export
app.
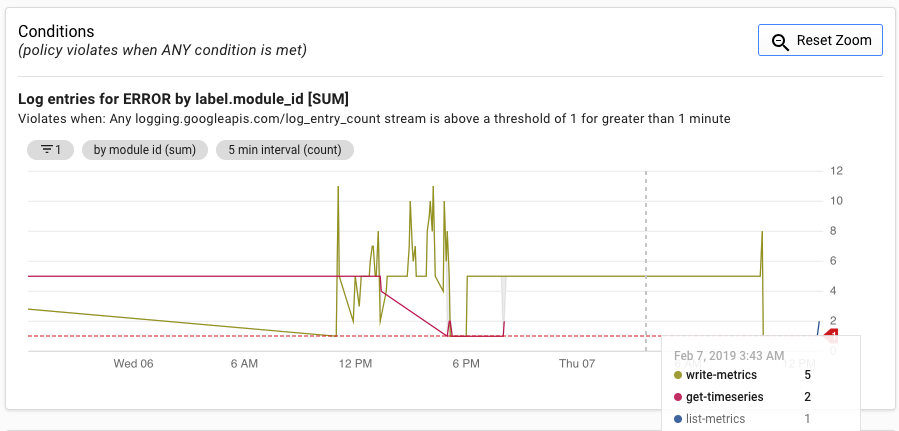
The Alerting UI displays a graph of the log_entry_count metric as compared to
the threshold for generating the alert.
What's next
- View the reference implementation on GitHub.
- Read the Cloud Monitoring docs.
- Explore the Cloud Monitoring v3 API docs.
- For more reference architectures, diagrams, and best practices, explore the Cloud Architecture Center.
- Read our resources about DevOps.
Learn more about the DevOps capabilities related to this solution:
Take the DevOps quick check to understand where you stand in comparison with the rest of the industry.