En este documento se describen técnicas para implementar y automatizar la integración continua (CI), la entrega continua (CD) y el entrenamiento continuo (CT) en sistemas de aprendizaje automático (ML). Este documento se aplica principalmente a los sistemas de IA predictiva.
La ciencia de datos y el aprendizaje automático se están convirtiendo en capacidades esenciales para resolver problemas complejos del mundo real, transformar sectores y aportar valor en todos los ámbitos. Actualmente, tienes a tu disposición los ingredientes para aplicar el aprendizaje automático de forma eficaz:
- Conjuntos de datos grandes
- Recursos de computación bajo demanda económicos
- Aceleradores especializados para el aprendizaje automático en varias plataformas en la nube
- Avances rápidos en diferentes campos de investigación de aprendizaje automático (como la visión artificial, la comprensión del lenguaje natural, la IA generativa y los sistemas de IA de recomendaciones).
Por eso, muchas empresas están invirtiendo en sus equipos de ciencia de datos y en sus capacidades de aprendizaje automático para desarrollar modelos predictivos que puedan aportar valor empresarial a sus usuarios.
Este documento está dirigido a científicos de datos e ingenieros de aprendizaje automático que quieran aplicar los principios de DevOps a los sistemas de aprendizaje automático (MLOps). MLOps es una cultura y una práctica de ingeniería de aprendizaje automático que tiene como objetivo unificar el desarrollo (Dev) y el funcionamiento (Ops) de los sistemas de aprendizaje automático. Practicar MLOps significa defender la automatización y la monitorización en todas las fases de la creación de sistemas de aprendizaje automático, como la integración, las pruebas, el lanzamiento, el despliegue y la gestión de la infraestructura.
Los científicos de datos pueden implementar y entrenar un modelo de aprendizaje automático con un rendimiento predictivo en un conjunto de datos de retención offline, siempre que dispongan de datos de entrenamiento relevantes para su caso práctico. Sin embargo, el verdadero reto no es crear un modelo de aprendizaje automático, sino desarrollar un sistema de aprendizaje automático integrado y mantenerlo en producción de forma continua. Gracias a la larga trayectoria de Google en la producción de servicios de aprendizaje automático, hemos aprendido que puede haber muchos problemas al operar sistemas basados en aprendizaje automático en producción. Algunos de estos problemas se resumen en el artículo Machine Learning: The High Interest Credit Card of Technical Debt (Aprendizaje automático: la tarjeta de crédito con intereses altos de la deuda técnica).
Como se muestra en el siguiente diagrama, solo una pequeña parte de un sistema de aprendizaje automático del mundo real está compuesta por el código de aprendizaje automático. Los elementos circundantes necesarios son amplios y complejos.
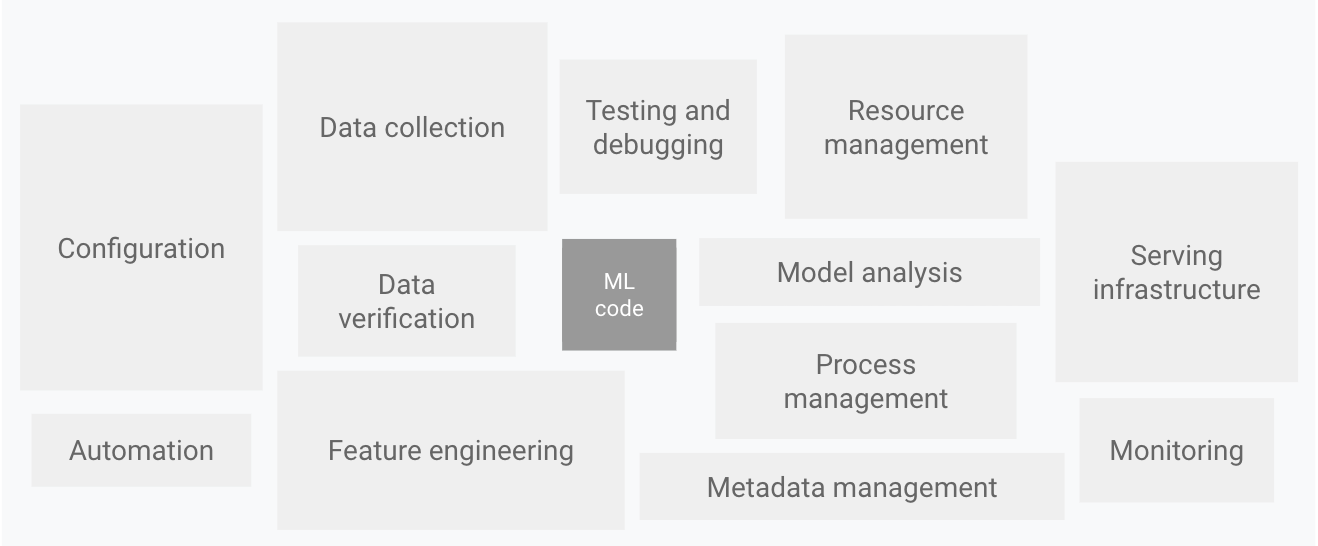
Imagen 1. Elementos para sistemas de aprendizaje automático. Adaptado de Hidden Technical Debt in Machine Learning Systems.
En el diagrama anterior se muestran los siguientes componentes del sistema:
- Configuración
- Automatización
- Recogida de datos
- Verificación de datos
- Pruebas y depuración
- Gestión de recursos
- Análisis de modelos
- Gestión de procesos y metadatos
- Infraestructura de servicio
- Supervisión
Para desarrollar y gestionar sistemas complejos como estos, puedes aplicar los principios de DevOps a los sistemas de aprendizaje automático (MLOps). En este documento se explican los conceptos que debes tener en cuenta al configurar un entorno de MLOps para tus prácticas de ciencia de datos, como la integración continua, la entrega continua y las pruebas continuas en el aprendizaje automático.
Se tratan los siguientes temas:
- DevOps y MLOps
- Pasos para desarrollar modelos de aprendizaje automático
- Niveles de desarrollo de MLOps
- MLOps para la IA generativa
DevOps y MLOps
DevOps es una práctica habitual en el desarrollo y el funcionamiento de sistemas de software a gran escala. Esta práctica ofrece ventajas como acortar los ciclos de desarrollo, aumentar la velocidad de implementación y lanzar versiones fiables. Para conseguir estas ventajas, se introducen dos conceptos en el desarrollo del sistema de software:
Un sistema de aprendizaje automático es un sistema de software, por lo que se aplican prácticas similares para garantizar que puedas crear y operar sistemas de aprendizaje automático a gran escala de forma fiable.
Sin embargo, los sistemas de aprendizaje automático se diferencian de otros sistemas de software en los siguientes aspectos:
Habilidades del equipo: en un proyecto de aprendizaje automático, el equipo suele incluir científicos de datos o investigadores de aprendizaje automático, que se centran en el análisis exploratorio de datos, el desarrollo de modelos y la experimentación. Es posible que estos miembros no sean ingenieros de software con experiencia que puedan crear servicios de clase de producción.
Desarrollo: el aprendizaje automático es experimental por naturaleza. Deberías probar diferentes funciones, algoritmos, técnicas de modelado y configuraciones de parámetros para encontrar lo que mejor se adapte al problema lo antes posible. El reto consiste en hacer un seguimiento de lo que ha funcionado y lo que no, y en mantener la reproducibilidad al tiempo que se maximiza la reutilización del código.
Pruebas: probar un sistema de aprendizaje automático es más complejo que probar otros sistemas de software. Además de las pruebas unitarias y de integración habituales, necesitas validar los datos, evaluar la calidad del modelo entrenado y validar el modelo.
Despliegue: en los sistemas de aprendizaje automático, el despliegue no es tan sencillo como desplegar un modelo de aprendizaje automático entrenado sin conexión como servicio de predicción. Los sistemas de aprendizaje automático pueden requerir que implementes una canalización de varios pasos para volver a entrenar y desplegar modelos automáticamente. Esta canalización añade complejidad y requiere que automatices los pasos que los científicos de datos realizan manualmente antes de la implementación para entrenar y validar nuevos modelos.
Producción: el rendimiento de los modelos de aprendizaje automático puede verse afectado no solo por una codificación inadecuada, sino también por los perfiles de datos en constante evolución. En otras palabras, los modelos pueden deteriorarse de más formas que los sistemas de software convencionales, y debes tener en cuenta este deterioro. Por lo tanto, debe hacer un seguimiento de las estadísticas de resumen de sus datos y monitorizar el rendimiento online de su modelo para enviar notificaciones o revertir los cambios cuando los valores se desvíen de sus expectativas.
El aprendizaje automático y otros sistemas de software son similares en cuanto a la integración continua del control de versiones, las pruebas unitarias, las pruebas de integración y la entrega continua del módulo o paquete de software. Sin embargo, en el aprendizaje automático hay algunas diferencias notables:
- La integración continua no solo se centra en probar y validar el código y los componentes, sino también en probar y validar los datos, los esquemas de datos y los modelos.
- La entrega continua ya no se centra en un único paquete de software o servicio, sino en un sistema (un flujo de procesamiento de entrenamiento de aprendizaje automático) que debe implementar automáticamente otro servicio (servicio de predicción de modelos).
- CT es una propiedad nueva y exclusiva de los sistemas de aprendizaje automático que se ocupa de volver a entrenar y servir los modelos automáticamente.
En la siguiente sección se describen los pasos habituales para entrenar y evaluar un modelo de aprendizaje automático que se usará como servicio de predicción.
Pasos de la ciencia de datos para el aprendizaje automático
En cualquier proyecto de aprendizaje automático, después de definir el caso práctico y establecer los criterios de éxito, el proceso de implementación de un modelo de aprendizaje automático en producción implica los siguientes pasos. Estos pasos se pueden completar manualmente o mediante una canalización automática.
- Extracción de datos: selecciona e integra los datos relevantes de varias fuentes de datos para la tarea de aprendizaje automático.
- Análisis de datos: realizas un análisis de datos de exploración (EDA) para comprender los datos disponibles para crear el modelo de aprendizaje automático. Este proceso conlleva lo siguiente:
- Conocer el esquema de datos y las características que espera el modelo.
- Identificar la preparación de datos y la ingeniería de funciones necesarias para el modelo.
- Preparación de datos: los datos se preparan para la tarea de aprendizaje automático. Esta preparación implica la limpieza de datos, en la que divides los datos en conjuntos de entrenamiento, validación y prueba. También aplicas transformaciones de datos y la ingeniería de funciones al modelo que resuelve la tarea objetivo. El resultado de este paso son las divisiones de datos en el formato preparado.
- Entrenamiento del modelo: el científico de datos implementa diferentes algoritmos con los datos preparados para entrenar varios modelos de aprendizaje automático. Además, puedes someter los algoritmos implementados al ajuste de hiperparámetros para obtener el modelo de aprendizaje automático con el mejor rendimiento. El resultado de este paso es un modelo entrenado.
- Evaluación del modelo: el modelo se evalúa en un conjunto de pruebas reservado para evaluar su calidad. El resultado de este paso es un conjunto de métricas para evaluar la calidad del modelo.
- Validación del modelo: se confirma que el modelo es adecuado para la implementación, es decir, que su rendimiento predictivo es mejor que un valor de referencia determinado.
- Servicio de modelos: el modelo validado se despliega en un entorno de destino para ofrecer predicciones. Esta implementación puede ser una de las siguientes:
- Microservicios con una API REST para ofrecer predicciones online.
- Un modelo insertado en un dispositivo perimetral o móvil.
- Forma parte de un sistema de predicción por lotes.
- Monitorización de modelos: se monitoriza el rendimiento predictivo del modelo para invocar potencialmente una nueva iteración en el proceso de aprendizaje automático.
El nivel de automatización de estos pasos define la madurez del proceso de aprendizaje automático, que refleja la velocidad de entrenamiento de nuevos modelos con nuevos datos o de entrenamiento de nuevos modelos con nuevas implementaciones. En las siguientes secciones se describen tres niveles de MLOps, desde el más habitual, que no implica ninguna automatización, hasta la automatización de las canalizaciones de aprendizaje automático y de CI/CD.
Nivel 0 de MLOps: proceso manual
Muchos equipos cuentan con científicos de datos e investigadores de aprendizaje automático que pueden crear modelos de última generación, pero su proceso de creación y despliegue de modelos de aprendizaje automático es totalmente manual. Este es el nivel de madurez básico o nivel 0. En el siguiente diagrama se muestra el flujo de trabajo de este proceso.

Imagen 2. Pasos manuales de aprendizaje automático para ofrecer el modelo como servicio de predicción.
Características
En la siguiente lista se destacan las características del proceso de MLOps de nivel 0, tal como se muestra en la figura 2:
Proceso manual, basado en secuencias de comandos e interactivo: cada paso es manual, incluidos el análisis de datos, la preparación de datos, el entrenamiento de modelos y la validación. Requiere la ejecución manual de cada paso y la transición manual de un paso a otro. Este proceso suele llevarse a cabo mediante código experimental que los científicos de datos escriben y ejecutan de forma interactiva en cuadernos hasta que se obtiene un modelo viable.
Desconexión entre el aprendizaje automático y las operaciones: el proceso separa a los científicos de datos que crean el modelo de los ingenieros que lo ofrecen como servicio de predicción. Los científicos de datos entregan un modelo entrenado como artefacto al equipo de ingeniería para que lo despliegue en su infraestructura de APIs. Esta transferencia puede incluir colocar el modelo entrenado en una ubicación de almacenamiento, registrar el objeto del modelo en un repositorio de código o subirlo a un registro de modelos. Después, los ingenieros que implementan el modelo deben poner las funciones necesarias a disposición en producción para que el servicio tenga una latencia baja, lo que puede provocar desviaciones entre el entrenamiento y el servicio.
Iteraciones de lanzamiento poco frecuentes: el proceso presupone que tu equipo de ciencia de datos gestiona algunos modelos que no cambian con frecuencia, ya sea cambiando la implementación del modelo o volviendo a entrenarlo con datos nuevos. Se implementa una nueva versión del modelo solo un par de veces al año.
Sin CI: como se asumen pocos cambios en la implementación, se ignora la CI. Por lo general, la prueba del código forma parte de la ejecución de los cuadernos o de las secuencias de comandos. Las secuencias de comandos y los cuadernos que implementan los pasos del experimento se controlan mediante código fuente y producen artefactos, como modelos entrenados, métricas de evaluación y visualizaciones.
Sin CD: como no se implementan versiones del modelo con frecuencia, no se tiene en cuenta la CD.
El despliegue hace referencia al servicio de predicción: el proceso solo se ocupa de desplegar el modelo entrenado como servicio de predicción (por ejemplo, un microservicio con una API REST), en lugar de desplegar todo el sistema de aprendizaje automático.
Falta de monitorización activa del rendimiento: el proceso no registra ni monitoriza las predicciones y las acciones del modelo, que son necesarias para detectar la degradación del rendimiento del modelo y otros cambios en su comportamiento.
El equipo de ingeniería puede tener su propia configuración compleja para la configuración, las pruebas y la implementación de APIs, incluidas las pruebas de seguridad, regresión, carga y canary. Además, el despliegue en producción de una nueva versión de un modelo de aprendizaje automático suele someterse a pruebas A/B o a experimentos online antes de que el modelo se promueva para atender todo el tráfico de solicitudes de predicción.
Retos
El nivel 0 de MLOps es habitual en muchas empresas que están empezando a aplicar el aprendizaje automático a sus casos prácticos. Este proceso manual, basado en la experiencia de los científicos de datos, puede ser suficiente cuando los modelos se cambian o entrenan con poca frecuencia. En la práctica, los modelos suelen fallar cuando se implementan en el mundo real. Los modelos no se adaptan a los cambios en la dinámica del entorno ni a los cambios en los datos que describen el entorno. Para obtener más información, consulta el artículo Why Machine Learning Models Crash and Burn in Production (Por qué los modelos de aprendizaje automático fallan en producción).
Para superar estos retos y mantener la precisión de tu modelo en producción, debes hacer lo siguiente:
Monitoriza activamente la calidad de tu modelo en producción: la monitorización te permite detectar el deterioro del rendimiento y la obsolescencia del modelo. Actúa como señal para una nueva iteración de la experimentación y para volver a entrenar (manualmente) el modelo con datos nuevos.
Vuelve a entrenar tus modelos de producción con frecuencia: para detectar los patrones cambiantes y emergentes, debes volver a entrenar tu modelo con los datos más recientes. Por ejemplo, si tu aplicación recomienda productos de moda mediante el aprendizaje automático, sus recomendaciones deben adaptarse a las últimas tendencias y productos.
Experimenta continuamente con nuevas implementaciones para producir el modelo: para aprovechar las últimas ideas y los avances tecnológicos, debes probar nuevas implementaciones, como la ingeniería de funciones, la arquitectura del modelo y los hiperparámetros. Por ejemplo, si usas la visión artificial en la detección de caras, los patrones faciales son fijos, pero las nuevas técnicas pueden mejorar la precisión de la detección.
Para hacer frente a los problemas de este proceso manual, son útiles las prácticas de MLOps para la integración continua y la entrega continua, así como para las pruebas continuas. Si despliegas un flujo de procesamiento de entrenamiento de aprendizaje automático, puedes habilitar CT y configurar un sistema de CI/CD para probar, compilar y desplegar rápidamente nuevas implementaciones del flujo de procesamiento de aprendizaje automático. Estas funciones se describen con más detalle en las secciones siguientes.
Nivel 1 de MLOps: automatización del flujo de procesamiento de aprendizaje automático
El objetivo del nivel 1 es entrenar el modelo de forma continua automatizando el flujo de procesamiento del aprendizaje automático. De esta forma, podrás disfrutar de la entrega continua del servicio de predicción de modelos. Para automatizar el uso de nuevos datos con el objetivo de volver a entrenar modelos en entornos de producción, debes incorporar datos automatizados y pasos de validación de modelos en el flujo de procesamiento, así como activadores del flujo y procesos de gestión de los metadatos.
En la siguiente figura se muestra una representación esquemática de un flujo de procesamiento automatizado del aprendizaje automático para el entrenamiento continuo.

Imagen 3. Automatización del flujo de procesamiento del aprendizaje automático para el entrenamiento continuo.
Características
En la siguiente lista se destacan las características de la configuración de MLOps de nivel 1, tal como se muestra en la figura 3:
Experimento rápido: se organizan los pasos del experimento de aprendizaje automático. La transición entre pasos es automática, lo que permite iterar rápidamente los experimentos y preparar mejor toda la canalización para la producción.
Entrenamiento continuo del modelo en producción: el modelo se entrena automáticamente en producción con datos actualizados en función de los activadores del flujo de procesamiento activos, que se explican en la siguiente sección.
Simetría entre la fase experimental y la operativa: la implementación de la canalización que se usa en el entorno de desarrollo o de experimentación se utiliza en el entorno de preproducción y de producción, lo que es un aspecto clave de la práctica de MLOps para unificar DevOps.
Código modularizado para componentes y flujos de procesamiento: para crear flujos de procesamiento de aprendizaje automático, los componentes deben ser reutilizables, componibles y, posiblemente, compartibles entre flujos de procesamiento de aprendizaje automático. Por lo tanto, aunque el código de EDA se puede seguir usando en cuadernos, el código fuente de los componentes debe modularizarse. Además, los componentes deberían estar en contenedores para hacer lo siguiente:
- Desacopla el entorno de ejecución del tiempo de ejecución del código personalizado.
- Hacer que el código sea reproducible entre los entornos de desarrollo y producción.
- Aísla cada componente de la canalización. Los componentes pueden tener su propia versión del entorno de tiempo de ejecución y usar diferentes lenguajes y bibliotecas.
Entrega continua de modelos: un flujo de procesamiento de aprendizaje automático en producción ofrece continuamente servicios de predicción a los nuevos modelos que se entrenan con datos nuevos. El paso de despliegue del modelo, que ofrece el modelo entrenado y validado como un servicio de predicción para las predicciones online, se automatiza.
Despliegue de la canalización: en el nivel 0, se despliega un modelo entrenado como servicio de predicción en producción. En el nivel 1, se despliega un flujo de procesamiento de entrenamiento completo que se ejecuta de forma automática y recurrente para ofrecer el modelo entrenado como servicio de predicción.
Componentes adicionales
En esta sección se describen los componentes que debe añadir a la arquitectura para habilitar el entrenamiento continuo de aprendizaje automático.
Validación de datos y modelos
Cuando despliegues tu flujo de procesamiento de aprendizaje automático en producción, uno o varios de los activadores que se describen en la sección Activadores de flujos de procesamiento de aprendizaje automático ejecutarán automáticamente el flujo de procesamiento. El flujo de procesamiento espera datos nuevos y activos para generar una nueva versión del modelo entrenada con los nuevos datos (como se muestra en la figura 3). Por lo tanto, se requieren pasos de validación de datos y validación de modelos automatizados en el flujo de procesamiento de producción para asegurar el comportamiento esperado:
Validación de datos: este paso es obligatorio antes de entrenar el modelo para decidir si debes volver a entrenarlo o detener la ejecución de la canalización. Esta decisión se toma automáticamente si la canalización identifica lo siguiente.
- Desviaciones del esquema de datos: estas desviaciones se consideran anomalías en los datos de entrada. Por lo tanto, los pasos de la canalización posteriores reciben los datos de entrada que no cumplen el esquema esperado, incluidos los pasos de procesamiento de datos y de entrenamiento del modelo. En este caso, debes detener la canalización para que el equipo de ciencia de datos pueda investigar el problema. El equipo puede lanzar una corrección o una actualización de la canalización para gestionar estos cambios en el esquema. Los sesgos de esquema incluyen recibir funciones inesperadas, no recibir todas las funciones esperadas o recibir funciones con valores inesperados.
- Sesgos en los valores de los datos: se trata de cambios significativos en las propiedades estadísticas de los datos, lo que significa que los patrones de datos están cambiando y que debes activar un reentrenamiento del modelo para registrar estos cambios.
Validación del modelo: este paso se produce después de que entrenes correctamente el modelo con los nuevos datos. Evalúas y validas el modelo antes de que se promueva a producción. Este paso de validación del modelo offline consta de lo siguiente:
- Generar valores de métricas de evaluación usando el modelo entrenado en un conjunto de datos de prueba para evaluar la calidad predictiva del modelo.
- Comparar los valores de las métricas de evaluación que genera el modelo recién entrenado con los del modelo actual (por ejemplo, el modelo de producción, el modelo de referencia u otros modelos que cumplan los requisitos de la empresa). Te aseguras de que el nuevo modelo tenga un mejor rendimiento que el actual antes de pasarlo a producción.
- Asegurarse de que el rendimiento del modelo sea coherente en varios segmentos de los datos. Por ejemplo, el modelo de abandono de clientes que acabas de entrenar puede producir una precisión predictiva general mejor que el modelo anterior, pero los valores de precisión por región de cliente pueden tener una gran varianza.
- Asegúrate de probar el modelo para el despliegue, incluida la compatibilidad de la infraestructura y la coherencia con la API del servicio de predicción.
Además de la validación de modelos sin conexión, un modelo recién desplegado se somete a una validación de modelos online (en una implementación canaria o en una configuración de pruebas A/B) antes de ofrecer predicciones para el tráfico online.
Feature Store
Un componente adicional opcional para la automatización del flujo de procesamiento del aprendizaje automático de nivel 1 es un almacén de características. Un almacén de características es un repositorio centralizado en el que se estandarizan la definición, el almacenamiento y el acceso a las características para el entrenamiento y el servicio. Un almacén de características debe proporcionar una API para el servicio por lotes de alto rendimiento y el servicio en tiempo real de baja latencia de los valores de las características, así como admitir cargas de trabajo de entrenamiento y de servicio.
El almacén de características ayuda a los científicos de datos a hacer lo siguiente:
- Descubrir y reutilizar los conjuntos de funciones disponibles para sus entidades, en lugar de volver a crear conjuntos iguales o similares.
- Evita tener funciones similares con definiciones diferentes manteniendo las funciones y sus metadatos relacionados.
- Publicar valores de características actualizados desde el almacén de características.
Evita la desviación entre el entrenamiento y el servicio usando Feature Store como fuente de datos para la experimentación, el entrenamiento continuo y el servicio online. De esta forma, se asegura de que las funciones usadas para el entrenamiento sean las mismas que las usadas durante el servicio:
- Para realizar experimentos, los científicos de datos pueden obtener un extracto sin conexión de la tienda de características para llevar a cabo sus experimentos.
- En el caso del entrenamiento continuo, el flujo de procesamiento de entrenamiento del aprendizaje automático puede obtener un lote de los valores de las características actualizados del conjunto de datos que se usan en la tarea de entrenamiento.
- En el caso de la predicción online, el servicio de predicción puede obtener en un lote los valores de las características relacionadas con la entidad solicitada, como las características demográficas de los clientes, las características de los productos y las características de agregación de la sesión actual.
- En el caso de la predicción online y la obtención de características, el servicio de predicción identifica las características relevantes de una entidad. Por ejemplo, si la entidad es un cliente, las características relevantes pueden incluir la edad, el historial de compras y el comportamiento de navegación. El servicio agrupa estos valores de características y obtiene todas las características necesarias de la entidad a la vez, en lugar de hacerlo de forma individual. Este método de recuperación ayuda a mejorar la eficiencia, sobre todo cuando necesitas gestionar varias entidades.
Gestión de metadatos
Se registra información sobre cada ejecución de la canalización de AA para ayudar con el linaje de datos y artefactos, la reproducibilidad y las comparaciones. También te ayuda a depurar errores y anomalías. Cada vez que ejecutas la canalización, el almacén de metadatos de AA registra los siguientes metadatos:
- Las versiones del flujo de procesamiento y del componente que se han ejecutado.
- La fecha y la hora de inicio y de finalización, así como el tiempo que ha tardado en completarse cada paso del flujo de trabajo.
- El ejecutor del flujo de procesamiento.
- Los argumentos de los parámetros que se han transferido a la canalización.
- Los punteros a los artefactos producidos por cada paso de la canalización, como la ubicación de los datos preparados, las anomalías de validación, las estadísticas calculadas y el vocabulario extraído de las características categóricas. El seguimiento de estos resultados intermedios te ayuda a reanudar el flujo de trabajo desde el paso más reciente si se ha detenido debido a un error, sin tener que volver a ejecutar los pasos que ya se han completado.
- Un puntero al modelo entrenado anterior si necesitas volver a una versión anterior del modelo o si necesitas generar métricas de evaluación de una versión anterior del modelo cuando se proporcionan nuevos datos de prueba al flujo de procesamiento durante el paso de validación del modelo.
- Las métricas de evaluación del modelo que se han generado durante el paso de evaluación del modelo para los conjuntos de entrenamiento y de prueba. Estas métricas te ayudan a comparar el rendimiento de un modelo recién entrenado con el rendimiento registrado del modelo anterior durante el paso de validación del modelo.
Activadores de flujos de procesamiento de aprendizaje automático
Puedes automatizar los flujos de producción de aprendizaje automático para volver a entrenar los modelos con datos nuevos, en función de tu caso práctico:
- Bajo demanda: ejecución manual ad hoc del flujo de procesamiento.
- De forma programada: los datos nuevos etiquetados están disponibles sistemáticamente para el sistema de aprendizaje automático cada día, semana o mes. La frecuencia de reentrenamiento también depende de la frecuencia con la que cambien los patrones de datos y de lo caro que sea reentrenar los modelos.
- Disponibilidad de nuevos datos de entrenamiento: los datos nuevos no están disponibles de forma sistemática para el sistema de aprendizaje automático, sino que se ofrecen de forma puntual cuando se recogen y se ponen a disposición en las bases de datos de origen.
- Sobre el deterioro del rendimiento del modelo: el modelo se vuelve a entrenar cuando se produce un deterioro notable del rendimiento.
- Sobre cambios significativos en las distribuciones de datos (deriva de conceptos). Es difícil evaluar el rendimiento completo del modelo online, pero observas cambios significativos en las distribuciones de datos de las funciones que se usan para hacer la predicción. Estos cambios sugieren que tu modelo se ha quedado obsoleto y que debe volver a entrenarse con datos actualizados.
Retos
Si las nuevas implementaciones de la canalización no se despliegan con frecuencia y solo gestionas unas pocas canalizaciones, normalmente pruebas la canalización y sus componentes de forma manual. Además, puedes implementar manualmente nuevas implementaciones de la canalización. También envía el código fuente probado de la canalización al equipo de TI para que lo despliegue en el entorno de destino. Esta configuración es adecuada cuando despliegas modelos nuevos basados en datos nuevos, en lugar de en nuevas ideas de aprendizaje automático.
Sin embargo, debes probar nuevas ideas de aprendizaje automático y desplegar rápidamente nuevas implementaciones de los componentes de aprendizaje automático. Si gestionas muchos flujos de procesamiento de aprendizaje automático en producción, necesitas una configuración de CI/CD para automatizar la compilación, la prueba y el despliegue de estos flujos.
MLOps de nivel 2: automatización del flujo de procesamiento de CI/CD
Para actualizar flujos de procesamiento en entornos de producción de forma rápida y fiable, necesitas un sistema de CI/CD automático de calidad. Este sistema de CI/CD automático permite a tus científicos de datos investigar rápidamente nuevas ideas sobre ingeniería de funciones, arquitectura de modelos e hiperparámetros. Además, pueden implementar esas ideas y desarrollar, probar y desplegar nuevos componentes de flujo de procesamiento en el entorno de destino.
En el siguiente diagrama se muestra la implementación del flujo de procesamiento de aprendizaje automático mediante CI/CD, que tiene las características de la configuración de los flujos de procesamiento de aprendizaje automático automatizados, además de las rutinas de CI/CD automatizadas.

Imagen 4. Flujo de procesamiento automatizado de CI/CD y de aprendizaje automático.
Esta configuración de MLOps incluye los siguientes componentes:
- Control de origen
- Probar y crear servicios
- Servicios de implementación
- Registro de modelos
- Feature Store
- Almacén de metadatos de aprendizaje automático
- Orquestador de flujos de procesamiento de aprendizaje automático
Características
En el siguiente diagrama se muestran las fases del flujo de procesamiento de automatización de CI/CD de aprendizaje automático:

Imagen 5. Fases del flujo de procesamiento automatizado de CI/CD y de aprendizaje automático.
La canalización consta de las siguientes fases:
Desarrollo y experimentación: pruebas de forma iterativa nuevos algoritmos de aprendizaje automático y nuevos modelos en los que se coordinan los pasos del experimento. El resultado de esta fase es el código fuente de los pasos de la canalización de AA, que se insertan en un repositorio de origen.
Integración continua de la canalización: compila el código fuente y ejecuta varias pruebas. Los resultados de esta fase son componentes de la canalización (paquetes, ejecutables y artefactos) que se desplegarán en una fase posterior.
Entrega continua de la canalización: implementa los artefactos producidos por la fase de integración continua en el entorno de destino. El resultado de esta fase es una canalización implementada con la nueva implementación del modelo.
Activación automática: la canalización se ejecuta automáticamente en producción según una programación o en respuesta a un activador. El resultado de esta fase es un modelo entrenado que se envía al registro de modelos.
Entrega continua de modelos: el modelo entrenado se ofrece como servicio de predicción para las predicciones. El resultado de esta fase es un servicio de predicción de modelos desplegado.
Monitorización: recoges estadísticas sobre el rendimiento del modelo a partir de datos activos. El resultado de esta fase es un activador para ejecutar la canalización o para ejecutar un nuevo ciclo de experimento.
El paso de análisis de datos sigue siendo un proceso manual para los científicos de datos antes de que la canalización inicie una nueva iteración del experimento. El paso de análisis del modelo también es un proceso manual.
Integración continua
En esta configuración, la canalización y sus componentes se compilan, prueban y empaquetan cuando se confirma o se envía código nuevo al repositorio de código fuente. Además de compilar paquetes, imágenes de contenedor y ejecutables, el proceso de integración continua puede incluir las siguientes pruebas:
Pruebas unitarias de la lógica de ingeniería de funciones.
Pruebas unitarias de los diferentes métodos implementados en tu modelo. Por ejemplo, tienes una función que acepta una columna de datos categóricos y codificas la función como una característica one-hot.
Comprobar que el entrenamiento del modelo converge (es decir, que la pérdida del modelo disminuye por iteraciones y que se ajusta en exceso a algunos registros de muestra).
Comprobar que el entrenamiento del modelo no produce valores NaN debido a que se divide por cero o se manipulan valores pequeños o grandes.
Prueba que cada componente de la canalización genere los artefactos esperados.
Prueba de la integración entre componentes de la canalización.
Entrega continua
En este nivel, tu sistema ofrece continuamente nuevas implementaciones de la canalización al entorno de destino, que a su vez ofrece servicios de predicción del modelo recién entrenado. Para disfrutar de una entrega continua rápida y fiable de flujos de procesamiento y modelos, debes tener en cuenta lo siguiente:
Verificar la compatibilidad del modelo con la infraestructura de destino antes de implementarlo. Por ejemplo, debes verificar que los paquetes que requiere el modelo estén instalados en el entorno de servicio y que los recursos de memoria, computación y acelerador necesarios estén disponibles.
Probar el servicio de predicción llamando a la API de servicio con las entradas esperadas y asegurándose de que obtiene la respuesta que espera. Esta prueba suele detectar problemas que pueden producirse al actualizar la versión del modelo y espera una entrada diferente.
Probar el rendimiento del servicio de predicción, lo que implica probar la carga del servicio para obtener métricas como las consultas por segundo (QPS) y la latencia del modelo.
Validar los datos para volver a entrenar el modelo o para la predicción por lotes.
Verificar que los modelos cumplen los objetivos de rendimiento predictivo antes de implementarlos.
Despliegue automatizado en un entorno de prueba, por ejemplo, un despliegue que se activa al enviar código a la rama de desarrollo.
Implementación semiautomática en un entorno de preproducción, por ejemplo, una implementación que se activa al combinar código en la rama principal después de que los revisores aprueben los cambios.
Despliegue manual en un entorno de producción después de varias ejecuciones correctas de la canalización en el entorno de preproducción.
En resumen, implementar el aprendizaje automático en un entorno de producción no significa solo desplegar el modelo como una API para la predicción. En su lugar, significa desplegar una canalización de AA que pueda automatizar el reentrenamiento y el despliegue de nuevos modelos. Configurar un sistema de CI/CD te permite probar y desplegar automáticamente nuevas implementaciones de flujos de procesamiento. Este sistema te permite hacer frente a los cambios rápidos en tus datos y en tu entorno empresarial. No tienes que mover todos tus procesos de un nivel a otro de inmediato. Puedes implementar estas prácticas de forma gradual para mejorar la automatización del desarrollo y la producción de tu sistema de aprendizaje automático.
Siguientes pasos
- Consulta más información sobre la arquitectura de MLOps con TensorFlow Extended, Vertex AI Pipelines y Cloud Build.
- Consulta la guía profesional de operaciones de aprendizaje automático (MLOps).
- Consulta las prácticas recomendadas de MLOps Google Cloud (Cloud Next '19) en YouTube.
- Para obtener una descripción general de los principios y las recomendaciones de arquitectura específicos de las cargas de trabajo de IA y aprendizaje automático en Google Cloud, consulta la sección Perspectiva de IA y aprendizaje automático del framework Well-Architected.
- Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.
Colaboradores
Autores:
- Jarek Kazmierczak | Arquitecto de soluciones
- Khalid Salama | Ingeniero de software para empleados, aprendizaje automático
- Valentín Huerta | Ingeniero de IA
Otro colaborador: Sunil Kumar Jang Bahadur | Ingeniero de clientes