L'archiviazione di file, nota anche come Network Attached Storage (NAS), fornisce l'accesso a livello di file alle applicazioni per leggere e aggiornare le informazioni che possono essere condivise su più macchine. Alcune soluzioni di archiviazione dei file on-premise hanno un'architettura di scalabilità verticale e aggiungono semplicemente spazio di archiviazione a una quantità fissa di risorse di calcolo. Altre soluzioni di archiviazione di file hanno un'architettura di scalabilità orizzontale in cui la capacità e il calcolo (prestazioni) possono essere aggiunti in modo incrementale a un file system esistente in base alle esigenze. In entrambe le architetture di archiviazione, una o più macchine virtuali (VM) possono accedere all'archiviazione.
Sebbene alcuni file system utilizzino un client POSIX nativo, molti sistemi di archiviazione utilizzano un protocollo che consente alle macchine client di montare un file system e accedere ai file come se fossero ospitati localmente. I protocolli più comuni per l'esportazione delle condivisioni file sono Network File System (NFS) per Linux (e in alcuni casi Windows) e Server Message Block (SMB) per Windows.
Questo documento descrive le seguenti opzioni per la condivisione dei file:
- Google Cloud Hyperdisk, Persistent Disk o SSD locale
- Soluzioni gestite:
- Soluzioni partner in Google Cloud Marketplace:
Un fattore alla base delle prestazioni e della prevedibilità di tutti i servizi Google Cloud è lo stack di rete che Google ha sviluppato nel corso di molti anni. Con Jupiter Fabric, Google ha creato uno stack di rete solido, scalabile e stabile che può continuare a evolversi senza influire sui tuoi carichi di lavoro. Man mano che Google migliora e rafforza le proprie capacità di rete internamente, la tua soluzione di condivisione dei file beneficia delle prestazioni aggiuntive.
Una funzionalità di Google Cloud che può aiutarti a ottenere il massimo dal tuo investimento è la possibilità di specificare tipi di VM personalizzati. Quando scegli le dimensioni del tuo filer, puoi selezionare il mix esatto di memoria e CPU, in modo che il filer funzioni con prestazioni ottimali senza essere sovrascritto.
Tieni presente che Cloud Storage è anche un ottimo modo per archiviare petabyte o exabyte di dati con elevati livelli di ridondanza a un costo ridotto, ma Cloud Storage ha un profilo di prestazioni e un'API diversi rispetto ai file server descritti qui.
Riepilogo delle soluzioni di file server
La tabella seguente riassume le soluzioni e le funzionalità del file server:
| Soluzione | Set di dati ottimale | Throughput | Assistenza gestita | Protocolli di esportazione |
|---|---|---|---|---|
| Filestore Basic | Da 1 TiB a 64 TiB | Fino a 1,2 GiB/s | Completamente gestito da Google | NFSv3 |
| Filestore Zonal | Da 1 TiB a 100 TiB | Fino a 26 GiB/s | Completamente gestito da Google | NFSv3, NFSv4.1 |
| Filestore a livello di regione | Da 1 TiB a 100 TiB | Fino a 26 GiB/s | Completamente gestito da Google | NFSv3, NFSv4.1 |
| Managed Lustre | Da 18 TiB a 8 PiB | Fino a 1 TB/s | Completamente gestito da Google | POSIX |
| NetApp Volumes | Da 1 GiB a 1 PiB | Da 1 MB/s a 30 GB/s | Completamente gestito da Google | NFSv3, NFSv4.1, SMB3 |
| Persistent Disk di sola lettura | < 64 TB | Da 240 a 1200 MBps | No | Allegato diretto |
Dischi durevoli e SSD locale
Se hai dati a cui deve accedere una sola VM o che non cambiano nel tempo, puoi evitare del tutto un file server utilizzando i dischi durevoli offerti da Compute Engine: Hyperdisk o Persistent Disk. Puoi formattare i volumi Hyperdisk e Persistent Disk con un file system come Ext4 o XFS e collegarli alle VM in modalità di lettura e scrittura o di sola lettura. Ciò significa che puoi prima collegare un volume a un'istanza, caricarlo con i dati che ti servono e poi collegarlo come disco di sola lettura a centinaia di VM contemporaneamente. L'utilizzo di dischi di sola lettura non funziona per tutti i casi d'uso, ma può ridurre notevolmente la complessità rispetto all'utilizzo di un file server.
I dischi durevoli offrono prestazioni costanti. Tutti i volumi Persistent Disk delle stesse dimensioni (e, per Persistent Disk SSD, lo stesso numero di vCPU) che colleghi all'istanza hanno le stesse caratteristiche di prestazioni. Non è necessario preparare o testare i dischi prima di utilizzarli in produzione.
Il costo dei dischi permanenti è facile da determinare perché non ci sono costi di I/O da considerare dopo il provisioning del volume. I dischi permanenti possono anche essere ridimensionati quando necessario. In questo modo puoi iniziare con un volume a basso costo e bassa capacità e non devi creare istanze o dischi aggiuntivi per scalare la capacità.
Se la capacità di archiviazione totale è il requisito principale, puoi utilizzare Persistent Disk standard a basso costo. Per ottenere le migliori prestazioni e al contempo una maggiore durata, puoi utilizzare i dischi permanenti SSD.
Inoltre, è importante scegliere la capacità del disco permanente di Compute Engine e il numero di vCPU corretti per garantire che i dispositivi di archiviazione del file server ricevano la larghezza di banda di archiviazione, le IOPS e la larghezza di banda di rete richieste. La larghezza di banda di rete per le VM dipende dal tipo di macchina che scegli. Ad esempio, le VM A4 hanno una larghezza di banda di rete massima fino a 3600 Gbps. Per saperne di più, consulta la guida alle risorse e al confronto per le famiglie di macchine. Per informazioni sull'ottimizzazione dei dischi permanenti, consulta Informazioni sulle prestazioni di un disco permanente.
Se i tuoi dati sono temporanei e richiedono una latenza inferiore al millisecondo e un numero elevato di operazioni di I/O al secondo (IOPS), puoi sfruttare fino a 9 TB di SSD locali per prestazioni estreme. Gli SSD locali forniscono GB/s di larghezza di banda e milioni di IOPS, il tutto senza utilizzare la larghezza di banda di rete assegnata alle istanze. È importante ricordare, tuttavia, che gli SSD locali presentano alcuni compromessi in termini di disponibilità, durata e flessibilità.
Per saperne di più sulle opzioni di archiviazione per Compute Engine, vedi Progetta una strategia di archiviazione ottimale per il tuo carico di lavoro cloud.
Considerazioni per la scelta di una soluzione di archiviazione dei file
La scelta di una soluzione di archiviazione di file richiede compromessi in termini di gestibilità, costi, prestazioni e scalabilità. Prendere la decisione è più facile se hai un workload ben definito, il che non è spesso il caso. Nei casi in cui i carichi di lavoro si evolvono nel tempo o sono molto variabili, è prudente scambiare il risparmio sui costi con flessibilità ed elasticità, in modo da poter crescere nella tua soluzione. D'altra parte, se hai un workload temporale e ben noto, puoi creare un'architettura di archiviazione di file appositamente creata che puoi smantellare e ricostruire per soddisfare le tue esigenze di archiviazione immediate.
Una delle prime decisioni da prendere è se vuoi pagare per un servizio di archiviazione gestito, una soluzione che include l'assistenza per il prodotto o una soluzione non supportata.
- I servizi di archiviazione di file gestiti sono i più semplici da utilizzare, perché Google o un partner gestiscono tutte le operazioni. Questi servizi potrebbero persino fornire un accordo sul livello del servizio (SLA) per la disponibilità, come la maggior parte degli altri Google Cloud servizi.
- Le soluzioni non gestite, ma supportate, offrono maggiore flessibilità. I partner possono aiutarti a risolvere eventuali problemi, ma il funzionamento quotidiano della soluzione di archiviazione è lasciato all'utente.
- Le soluzioni non supportate richiedono il massimo impegno per l'implementazione e la manutenzione, lasciando tutti i problemi all'utente. Queste soluzioni non sono trattate in questo documento.
La decisione successiva riguarda la determinazione dei requisiti di durabilità e disponibilità della soluzione. La maggior parte delle soluzioni di file sono zonali e non forniscono protezione per impostazione predefinita in caso di errore della zona. Pertanto, è importante valutare se è necessaria una soluzione di ripristino di emergenza (RE) che protegga da eventuali errori a livello di zona. È anche importante comprendere i requisiti dell'applicazione per durabilità e disponibilità. Ad esempio, la scelta di SSD locali o dischi permanenti nel deployment ha un grande impatto, così come la configurazione del software della soluzione di file. Ogni soluzione richiede un'attenta pianificazione per ottenere elevati livelli di durabilità, disponibilità e persino protezione da errori zonali e regionali.
Infine, considera le posizioni (ovvero zone, regioni, data center on-premise) in cui devi accedere ai dati. Le posizioni delle farm di calcolo che accedono ai tuoi dati influenzano la scelta della soluzione di archiviazione perché solo alcune soluzioni consentono l'accesso ibrido on-premise e nel cloud.
Soluzioni di archiviazione di file gestite
Questa sezione descrive le soluzioni gestite da Google per l'archiviazione dei file.
Filestore Basic
Le istanze Filestore Basic sono adatte alla condivisione di file, allo sviluppo di software e ai carichi di lavoro GKE. Puoi scegliere HDD o SSD per archiviare i dati. L'SSD offre prestazioni migliori. Con entrambe le opzioni, la capacità viene aumentata in modo incrementale e puoi proteggere i dati utilizzando i backup.
Filestore Zonal
Filestore Zonal semplifica l'archiviazione aziendale e la gestione dei dati su Google Cloud e nei cloud ibridi. Filestore Zonal offre un accesso parallelo conveniente e ad alte prestazioni ai dati globali, mantenendo una coerenza rigorosa grazie a un file system distribuito e scalabile in modo dinamico. Con Filestore zonale, le applicazioni NFS e i flussi di lavoro NAS esistenti possono essere eseguiti nel cloud senza richiedere il refactoring, mantenendo comunque i vantaggi dei servizi di dati aziendali (ad esempio, snapshot e backup). Il driver CSI di Filestore consente la persistenza, la portabilità e la condivisione dei dati senza problemi per i carichi di lavoro in container.
Puoi scalare le istanze Filestore zonali on demand. In questo modo puoi creare ed espandere l'infrastruttura del file system in base alle esigenze, assicurandoti che le prestazioni e la capacità di archiviazione siano sempre in linea con i requisiti dinamici del tuo flusso di lavoro. Man mano che un cluster Filestore zonale si espande, le prestazioni di metadati e I/O vengono scalate in modo lineare. Questo scaling ti consente di migliorare e accelerare un'ampia gamma di workflow che richiedono un uso intensivo dei dati, tra cui computing ad alte prestazioni, analisi, aggregazione dei dati cross-site, DevOps e molti altri. Di conseguenza, Filestore Zonal è ideale per l'utilizzo in settori incentrati sui dati, come le scienze biologiche (ad esempio, il sequenziamento del genoma), i servizi finanziari e i media e l'intrattenimento.
Per proteggere ulteriormente i dati critici, Filestore Zonal ti consente anche di eseguire e conservare snapshot periodici, creare backup e replicare in un'altra regione. Con Filestore, puoi recuperare un singolo file o un intero file system in meno di 10 minuti da uno qualsiasi dei punti di recupero precedenti.
Filestore a livello di regione
Filestore regionale
è una soluzione NFS cloud-native completamente gestita che ti consente di eseguire il deployment di applicazioni critiche basate su file in Google Cloud, supportata da un SLA che offre una disponibilità a livello di regione del 99,99%. Con uno SLA (accordo sul livello del servizio) con disponibilità a livello di regione del 99,99%,
Filestore Regional è progettato per applicazioni che richiedono
alta disponibilità. Con pochi clic del mouse (o pochi comandi gcloud o chiamate API), puoi eseguire il provisioning di condivisioni NFS replicate in modo sincrono in tre zone all'interno di una regione. Se una zona all'interno della regione non è più disponibile,
Filestore regionale continua a fornire dati in modo trasparente all'applicazione
senza alcun intervento operativo.
Per proteggere ulteriormente i dati critici, Filestore regionale consente anche di eseguire e conservare snapshot periodici, creare backup ed eseguire la replica in un'altra regione. Con Filestore, puoi recuperare un singolo file o un intero file system in meno di 10 minuti da uno qualsiasi dei punti di recupero precedenti.
Per proteggere ulteriormente i dati critici, Filestore consente anche di creare e conservare snapshot periodici del file system. Con Filestore, puoi recuperare un singolo file o un intero file system in meno di 10 minuti da uno qualsiasi dei punti di recupero precedenti.
Per le applicazioni critiche come SAP, sia il livello del database che quello dell'applicazione devono essere a disponibilità elevata. Per soddisfare questo requisito, puoi eseguire il deployment del livello del database SAP su Google Cloud Hyperdisk Extreme, in più zone utilizzando l'alta disponibilità del database integrata. Allo stesso modo, il livello applicativo NetWeaver, che richiede eseguibili condivisi su più VM, può essere implementato in Filestore regionale, che replica i dati Netweaver in più zone all'interno di una regione. Il risultato finale è un'architettura di applicazione mission critical a tre livelli ad alta disponibilità.
Le organizzazioni IT eseguono sempre più spesso il deployment di applicazioni stateful in container su Google Kubernetes Engine (GKE). Questo spesso li porta a ripensare quale infrastruttura di archiviazione utilizzare per supportare queste applicazioni. Puoi utilizzare l'archiviazione a blocchi (Hyperdisk o Persistent Disk), l'archiviazione di file (Filestore Basic, zonale o regionale) o l'archiviazione di oggetti (Cloud Storage). Filestore Basic HDD per GKE e Filestore Multishares per GKE in combinazione con il driver CSI di Filestore consente alle organizzazioni che richiedono più pod GKE di avere accesso ai file condivisi, fornendo un maggiore livello di disponibilità per i carichi di lavoro mission critical.
Managed Lustre
Managed Lustre è un servizio gestito da Google che fornisce spazio di archiviazione a velocità effettiva elevata e bassa latenza per carichi di lavoro HPC strettamente accoppiati. Accelera notevolmente i carichi di lavoro HPC e l'addestramento e l'inferenza dell'AI fornendo un accesso a bassa latenza e ad alta velocità effettiva a enormi set di dati. Per informazioni sull'utilizzo di Managed Lustre per i workload AI e ML, consulta Progettare l'archiviazione per i workload AI e ML in Google Cloud. Managed Lustre distribuisce i dati su più nodi di archiviazione, il che consente l'accesso simultaneo da parte di molte VM. Questo accesso parallelo elimina i colli di bottiglia che si verificano con i file system convenzionali e consente ai carichi di lavoro di importare ed elaborare rapidamente le grandi quantità di dati richieste.
NetApp Volumes
NetApp Volumes è un servizio Google completamente gestito che ti consente di montare rapidamente l'archiviazione di file condivisi sulle tue istanze di calcolo Google Cloud . NetApp Volumes supporta l'accesso SMB, NFS e multiprotocollo. NetApp Volumes offre prestazioni elevate alle tue applicazioni con bassa latenza e solide funzionalità di protezione dei dati: snapshot, copie, replica tra regioni e backup. Il servizio è adatto per applicazioni che richiedono workload sequenziali e casuali, scalabili su centinaia o migliaia di istanze Compute Engine. In pochi secondi, i volumi di dimensioni comprese tra GiB e PiB possono essere sottoposti a provisioning e protetti con solide funzionalità di protezione dei dati. Con più livelli di servizio (Flex, Standard, Premium ed Extreme), NetApp Volumes offre le prestazioni appropriate per il tuo workload, senza influire sulla disponibilità.
Soluzioni partner in Cloud Marketplace
Le seguenti soluzioni fornite dai partner sono disponibili in Cloud Marketplace.
NetApp Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP (NetApp CVO) è una soluzione basata sul cloud e gestita dal cliente che porta l'intero set di funzionalità di ONTAP, il principale sistema operativo di gestione dei dati di NetApp, su Google Cloud. NetApp CVO viene implementato all'interno del tuo VPC, con fatturazione e assistenza da parte di Google. Il software ONTAP viene eseguito su una VM Compute Engine e utilizza una combinazione di dischi permanenti e bucket Cloud Storage (se il tiering è abilitato) per archiviare i dati NAS. Il filer integrato ospita i volumi NAS utilizzando il thin provisioning, in modo da pagare solo lo spazio di archiviazione che utilizzi. Man mano che i dati aumentano, vengono aggiunti dischi permanenti aggiuntivi al pool di capacità aggregata.
NetApp CVO astrae l'infrastruttura sottostante e ti consente di creare volumi di dati virtuali ricavati dal pool aggregato coerenti con tutti gli altri volumi ONTAP in qualsiasi ambiente cloud o on-premise. I volumi di dati che crei supportano tutte le versioni di NFS, SMB, NFS/SMB multiprotocollo e iSCSI. Supportano un'ampia gamma di carichi di lavoro basati su file, inclusi contenuti web e multimediali avanzati, utilizzati in molti settori come l'automazione della progettazione elettronica (EDA) e i media e l'intrattenimento.
NetApp CVO supporta snapshot istantanei e salvaspazio point-in-time, backup incrementali a livello di blocco integrati per sempre in Cloud Storage e replica asincrona tra regioni per il ripristino di emergenza. L'opzione per selezionare il tipo di istanza Compute Engine e dischi permanenti ti consente di ottenere le prestazioni che desideri per i tuoi carichi di lavoro. Anche quando opera in una configurazione ad alte prestazioni, NetApp CVO implementa efficienze di archiviazione come deduplicazione, compattazione e compressione, nonché il tiering automatico dei dati utilizzati di rado nel bucket Cloud Storage, consentendoti di archiviare petabyte di dati riducendo significativamente i costi di archiviazione complessivi.
DDN Infinia
Se hai bisogno di un'orchestrazione avanzata dei dati AI, puoi utilizzare DDN Infinia, disponibile in Google Cloud Marketplace. Infinia fornisce una soluzione di data intelligence incentrata sull'AI e ottimizzata per inferenza, addestramento e analisi in tempo reale. Consente l'importazione dati ultra rapida, l'indicizzazione ricca di metadati e l'integrazione perfetta con framework di AI come TensorFlow e PyTorch.
Di seguito sono riportate le funzionalità principali di DDN Infinia:
- Rendimento elevato: offre una latenza inferiore al millisecondo e un throughput di più TB/s.
- Scalabilità: supporta la scalabilità da terabyte a exabyte e può ospitare fino a oltre 100.000 GPU e un milione di client simultanei in un'unica implementazione.
- Multitenancy con qualità del servizio (QoS) prevedibile: offre ambienti sicuri e isolati per più tenant con QoS prevedibile per prestazioni coerenti tra i carichi di lavoro.
- Accesso unificato ai dati: consente l'integrazione perfetta con applicazioni e flussi di lavoro esistenti tramite il supporto multiprotocollo integrato, incluso per Amazon S3 compatibile, CSI e Cinder.
- Sicurezza avanzata: funzionalità di crittografia integrate, codifica di cancellazione consapevole del dominio di errore e snapshot che contribuiscono a garantire la protezione e la conformità dei dati.
Nasuni Cloud File Storage
Nasuni sostituisce i file server aziendali e i dispositivi NAS e tutte le infrastrutture associate, inclusi hardware di backup e RE, con un'alternativa cloud più semplice ed economica. Nasuni utilizza l'archiviazione di oggetti per fornire una soluzione di archiviazione software-as-a-service (SaaS) più efficiente che si adatta per gestire la crescita rapida e non strutturata dei dati dei file. Google Cloud Nasuni è progettato per gestire le condivisioni di file e i flussi di lavoro delle applicazioni di reparti, progetti e organizzazioni per ogni dipendente, ovunque lavori.
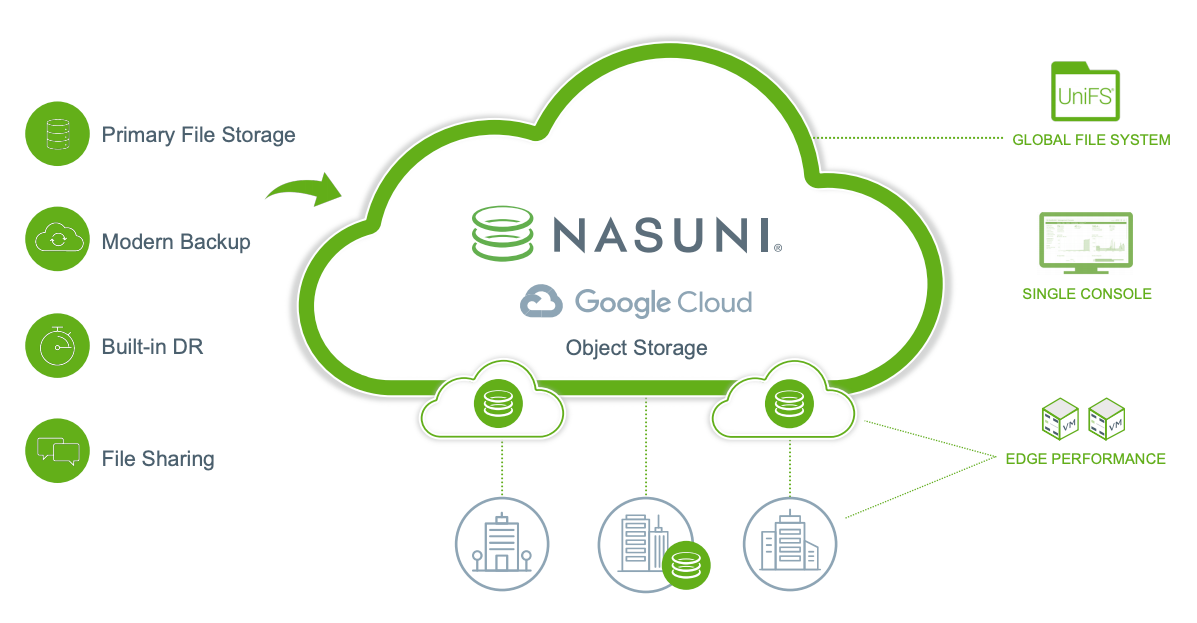
Nasuni offre tre pacchetti, con prezzi per aziende e organizzazioni di tutte le dimensioni, in modo che possano crescere ed espandersi in base alle necessità.
I vantaggi includono:
Archiviazione di file principale basata su cloud fino al 70% in meno. L'architettura di Nasuni sfrutta le policy di gestione del ciclo di vita degli oggetti integrate. Queste norme consentono la massima flessibilità di utilizzo con le classi Cloud Storage, tra cui Standard, Nearline, Coldline e Archive. Utilizzando la classe di archiviazione ad accesso immediato per l'archiviazione primaria con Nasuni, puoi ottenere un risparmio sui costi fino al 70%.
Condivisioni file di reparti e organizzazioni nel cloud. L'architettura basata sul cloud di Nasuni offre un unico spazio dei nomi globale in tutte le regioniGoogle Cloud , senza limiti al numero di file, alle dimensioni dei file o agli snapshot, consentendoti di archiviare i file direttamente dal desktop in Google Cloud tramite protocolli di mappatura delle unità NAS (SMB) standard.
Backup e ripristino di emergenza integrati. Le operazioni "imposta e dimentica " di Nasuni semplificano la gestione dell'archiviazione di file globale. Backup e RE sono inclusi e un'unica console di gestione ti consente di supervisionare e controllare l'ambiente ovunque e in qualsiasi momento.
Sostituisce i file server obsoleti. Nasuni semplifica la migrazione dei file server Microsoft Windows e di altri sistemi di archiviazione di file esistenti a Google Cloud, riducendo i costi e la complessità di gestione di questi ambienti.
Per ulteriori informazioni, consulta le seguenti risorse:
- Tour guidato di Nasuni
- Partnership tra Nasuni e Google Cloud
- Nasuni Enterprise File Storage per Google Cloud solution brief (PDF)
- Nasuni Cloud File Storage in Cloud Marketplace
- Nasuni e Google Cloud blog
Sycomp Intelligent Data Storage Platform
La Sycomp Intelligent Data Storage Platform, disponibile in Google Cloud Marketplace, ti consente di eseguire i carichi di lavoro di computing ad alte prestazioni (HPC), AI e ML e big data in Google Cloud. Con Sycomp Storage puoi accedere contemporaneamente ai dati di migliaia di VM, ridurre i costi gestendo automaticamente i livelli di archiviazione ed eseguire l'applicazione on-premise o in Google Cloud. Sycomp Storage può essere implementato rapidamente e supporta l'accesso ai tuoi dati tramite NFS e il client IBM Storage Scale.
IBM Storage Scale è un file system parallelo che consente di gestire in modo sicuro grandi volumi (PB) di dati. Sycomp Storage Scale è un file system parallelo adatto a HPC, AI, ML, big data e altre applicazioni che richiedono un file system condiviso conforme a POSIX. Grazie alla capacità di archiviazione adattabile e al dimensionamento delle prestazioni, Sycomp Storage può supportare workload HPC, AI e ML di piccole e grandi dimensioni.
Dopo aver eseguito il deployment di un cluster in Google Cloud, decidi come vuoi utilizzarlo. Scegli se utilizzare il cluster solo nel cloud o in modalità ibrida connettendoti a cluster IBM Storage Scale on-premise esistenti, a soluzioni NAS NFS di terze parti o ad altre soluzioni di archiviazione basate su oggetti.
Collaboratori
Autore: Sean Derrington | Group Product Manager, Storage
Altri collaboratori:
- Dean Hildebrand | Technical Director, Office of the CTO
- Kumar Dhanagopal | Sviluppatore di soluzioni cross-prodotto