Cet article constitue la troisième partie d'une série qui traite de la reprise après sinistre (DR, Disaster Recovery) dans Google Cloud. Cette partie traite des scénarios de sauvegarde et de récupération de données.
La série comprend les éléments suivants :
- Guide de planification de reprise après sinistre
- Structure de la reprise après sinistre
- Scénarios de reprise après sinistre pour les données (ce document)
- Scénarios de reprise après sinistre pour les applications
- Concevoir une solution de reprise après sinistre pour des charges de travail limitées à la localité
- Cas d'utilisation de reprise après sinistre : applications d'analyse de données limitées à la localité
- Concevoir une solution de reprise après sinistre pour les pannes d'infrastructure cloud
Introduction
Vos plans de reprise après sinistre doivent spécifier comment vous pouvez éviter de perdre des données en cas de sinistre. Le terme données fait ici référence à deux scénarios. La sauvegarde et la récupération de bases de données, de données de journal et d'autres types de données peuvent s'effectuer dans le cadre de l'un des scénarios suivants :
- Sauvegardes de données : la sauvegarde de données consiste à copier un nombre discret de données d'un emplacement vers un autre. Les sauvegardes sont effectuées dans le cadre d'un plan de reprise, soit dans l'optique de restaurer les données dans un état correct connu directement dans l'environnement de production à la suite d'une corruption de données, soit dans l'optique de restaurer les données dans l'environnement de reprise après sinistre si l'environnement de production est arrêté. En règle générale, les sauvegardes de données sont associées à un objectif de durée maximale d'interruption admissible (DMIA) faible à moyen, et à un objectif de perte de données maximale admissible (PDMA) faible.
- Sauvegardes de bases de données : les sauvegardes de base de données sont légèrement plus complexes à mettre en œuvre, car elles doivent permettre de restaurer les données dans l'état où elles se trouvaient à un instant T. Par conséquent, outre le fait de définir un processus de sauvegarde de la base de données (et de restauration des sauvegardes) et de vous assurer que le système de base de données de récupération reflète la configuration de production (même version, configuration des disques en miroir), vous devez également définir un processus de sauvegarde des journaux de transactions. Lors de la récupération, une fois que le fonctionnement de la base de données est rétabli, vous devez appliquer la dernière sauvegarde de la base de données. Ensuite, vous devez importer les journaux de transactions qui ont été sauvegardés à l'issue de la dernière sauvegarde de la base de données. En raison des facteurs de complexité inhérents aux systèmes de base de données (par exemple, la nécessité de faire correspondre les versions entre les systèmes de production et de récupération), nous vous recommandons d'adopter une approche focalisée sur la haute disponibilité afin de minimiser le temps de récupération à la suite d'une indisponibilité du serveur de base de données. Cela vous permettra de définir et d'atteindre des objectifs plus élevés (valeurs RTO et RPO plus faibles).
Lorsque vous exécutez des charges de travail de production sur Google Cloud, vous pouvez utiliser un système distribué à l'échelle mondiale. Ainsi, en cas de problème dans une région, l'application continue de fournir le service, même s'il est moins disponible. Fondamentalement, cette application exploite son plan de reprise après sinistre.
La suite de ce document décrit des exemples de conception de scénarios de sauvegarde et récupération efficaces pour les données et les bases de données. Ces conseils peuvent vous aider à atteindre vos objectifs en termes de RTO et de RPO.
L'environnement de production est déployé sur site
Dans ce scénario, votre environnement de production est déployé sur site et votre plan de reprise après sinistre implique l'utilisation de Google Cloud en tant que site de récupération.
Sauvegarde et récupération de données
Vous pouvez utiliser un certain nombre de stratégies pour mettre en œuvre un processus permettant de sauvegarder régulièrement des données hébergées sur site dans Google Cloud. Cette section présente deux des solutions les plus courantes.
Solution 1 : Sauvegarde sur Cloud Storage à l'aide d'une tâche planifiée
Ce modèle utilise les composants fondamentaux de reprise après sinistre suivants :
- Cloud Storage
Pour sauvegarder des données, vous pouvez créer une tâche planifiée qui exécute un script ou une application dont le rôle est de transférer les données vers Cloud Storage. Vous pouvez automatiser un processus de sauvegarde sur Cloud Storage à l'aide de la commande gcloud storage de la Google Cloud CLI ou de l'une des bibliothèques clientes Cloud Storage.
Par exemple, la commande gcloud storage suivante permet de copier tous les fichiers d'un répertoire source vers un bucket spécifique.
gcloud storage cp -r SOURCE_DIRECTORY gs://BUCKET_NAME
Remplacez SOURCE_DIRECTORY par le chemin d'accès à votre répertoire source et BUCKET_NAME par le nom de votre choix pour le bucket.
Le nom doit respecter les exigences concernant les noms de buckets.
Pour mettre en œuvre un processus de sauvegarde et de récupération à l'aide de la commande gcloud storage, procédez comme suit :
- Installez
gcloud CLIsur la machine sur site à partir de laquelle vous importez vos fichiers de données. - Créez un bucket qui fera office de cible pour la sauvegarde de données.
- Créez un compte de service.
- Créez une stratégie IAM pour limiter l'accès au bucket et à ses objets. Veillez à inclure le compte de service créé spécifiquement à cet effet. Pour en savoir plus sur les autorisations d'accès à Cloud Storage, consultez Autorisations IAM pour
gcloud storage. - Utilisez l'emprunt d'identité de compte de service pour permettre à votre utilisateur Google Cloudlocal (ou compte de service) d'emprunter l'identité du compte de service que vous venez de créer. Vous pouvez également créer un utilisateur spécifiquement à cet effet.
- Vérifiez que vous pouvez importer et télécharger des fichiers dans le bucket cible.
- Configurez un calendrier pour le script que vous utilisez pour importer vos sauvegardes à l'aide d'outils tels que Linux
crontabet le Planificateur de tâches Windows. - Configurez un processus de récupération utilisant la commande
gcloud storagepour récupérer vos données dans votre environnement de reprise après sinistre sur Google Cloud.
Vous pouvez également utiliser la commande gcloud storage rsync pour effectuer des synchronisations incrémentielles en temps réel entre vos données et un bucket Cloud Storage.
Par exemple, la commande gcloud storage rsync suivante rend le contenu présent dans un bucket Cloud Storage identique à celui du répertoire source en copiant tous les fichiers ou objets manquants, ou ceux dont les données ont été modifiées. Si le volume de données modifié entre les sessions de sauvegarde successives est faible par rapport au volume total des données sources, l'utilisation de gcloud storage rsync peut s'avérer plus efficace que l'utilisation de la commande gcloud storage cp. En utilisant gcloud storage rsync, vous pouvez définir une programmation de sauvegarde plus fréquente et obtenir un RPO plus faible.
gcloud storage rsync -r SOURCE_DIRECTORY gs:// BUCKET_NAME
Pour en savoir plus, consultez la section Commande gcloud storage pour les transferts de données peu volumineux sur site.
Solution 2 : Sauvegarde sur Cloud Storage à l'aide du service de transfert des données sur site
Ce modèle utilise les composants fondamentaux de reprise après sinistre suivants :
- Cloud Storage
- Service de transfert des données sur site
Le transfert d'un volume important de données sur un réseau nécessite souvent une planification minutieuse et des stratégies d'exécution robustes. Il s'agit d'une tâche complexe visant à développer des scripts personnalisés évolutifs, fiables et faciles à gérer. Les scripts personnalisés conduisent souvent à des valeurs RPO plus faibles, voire à une augmentation des risques de perte de données.
Pour obtenir des conseils sur le transfert de grands volumes de données depuis des emplacements sur site vers Cloud Storage, consultez Déplacer ou sauvegarder des données depuis un espace de stockage sur site.
Solution 3 : Sauvegarde sur Cloud Storage à l'aide d'une solution de passerelle partenaire
Ce modèle utilise les composants fondamentaux de reprise après sinistre suivants :
- Cloud Interconnect
- Stockage Cloud Storage à plusieurs niveaux
Les applications sur site sont souvent intégrées à des solutions tierces pouvant être utilisées dans le cadre de votre stratégie de sauvegarde et de récupération de données. Ces solutions utilisent souvent un modèle de stockage à plusieurs niveaux. Les sauvegardes les plus récentes sont stockées sur le système de stockage le plus rapide. Les anciennes sauvegardes sont progressivement déplacées vers un système de stockage moins onéreux (et plus lent). Lorsque vous utilisez Google Cloud comme cible, plusieurs options de classe de stockage sont disponibles, équivalentes à celles du niveau le plus lent.
Pour mettre en œuvre ce modèle et faciliter le transfert des données vers Cloud Storage, vous pouvez utiliser une passerelle partenaire entre votre stockage sur site et Google Cloud . Le diagramme suivant illustre cette configuration, dans laquelle une solution partenaire gère le transfert des données à partir du dispositif NAS ou du réseau SAN sur site.

En cas de défaillance, les données en cours de sauvegarde doivent être récupérées dans votre environnement de reprise après sinistre. L'environnement de reprise après sinistre est utilisé pour assurer le trafic de production jusqu'à ce que vous puissiez revenir à l'environnement de production. La méthode à privilégier dépend de votre application, de la solution partenaire employée et de l'architecture de cette dernière. Certains scénarios de bout en bout sont décrits dans l'article Scénarios de reprise après sinistre pour les applications.
Vous pouvez également utiliser des bases de données Google Cloud gérées comme destinations de reprise après sinistre. Par exemple, Cloud SQL pour SQL Server est compatible avec les importations de journaux des transactions. Vous pouvez exporter les journaux des transactions depuis votre instance SQL Server sur site, les importer dans Cloud Storage, puis les importer dans Cloud SQL pour SQL Server.
Pour en savoir plus sur les méthodes permettant de transférer des données hébergées sur site versGoogle Cloud, consultez Transférer des ensembles de données volumineux vers Google Cloud.
Pour en savoir plus sur les solutions partenaires, consultez la page Partenaires sur le site Web Google Cloud .
Sauvegarde et récupération de base de données
Vous pouvez utiliser un certain nombre de stratégies pour mettre en œuvre un processus permettant de récupérer un système de base de données sur site dans Google Cloud. Cette section présente deux des solutions les plus courantes.
L'objet de ce document n'est pas de présenter en détail les divers mécanismes de sauvegarde et de récupération intégrés dans les solutions de bases de données tierces. Cette section fournit des instructions d'ordre général, qui sont mises en œuvre dans les solutions abordées ici.
Solution 1 : Sauvegarde et récupération à l'aide d'un serveur de récupération sur Google Cloud
- Créez une sauvegarde de la base de données à l'aide des mécanismes de sauvegarde internes du système de gestion de base de données.
- Connectez votre réseau sur site et votre réseau Google Cloud .
- Créez un bucket Cloud Storage qui fera office de cible pour la sauvegarde de données.
- Copiez les fichiers de sauvegarde vers Cloud Storage à l'aide de
gcloud storagegcloud CLI ou d'une solution de passerelle partenaire (reportez-vous à la procédure décrite précédemment dans la section "Sauvegarde et récupération des données"). Pour en savoir plus, consultez Migrer vers Google Cloud : transférer vos ensembles de données volumineux. - Copiez les journaux de transactions vers votre site de récupération sur Google Cloud. Le fait de disposer d'une sauvegarde des journaux de transactions vous aide à conserver des valeurs RPO faibles.
Après avoir configuré cette topologie de sauvegarde, vous devez vous assurer que vous pouvez récupérer le système qui se trouve sur Google Cloud. Cette étape implique généralement non seulement la restauration du fichier de sauvegarde dans la base de données cible, mais également la relecture des journaux de transactions dans l'optique d'atteindre la valeur RTO la plus faible possible. Une séquence de récupération se déroule typiquement de la façon suivante :
- Créez une image personnalisée de votre serveur de base de données sur Google Cloud. La configuration doit être identique pour les deux serveurs de base de données (image personnalisée et serveur sur site).
- Mettez en œuvre un processus de copie des fichiers de sauvegarde et des fichiers journaux de transactions locaux (sur site) vers Cloud Storage. Reportez-vous à la solution 1 pour découvrir un exemple de mise en œuvre.
- Démarrez une instance de taille minimale à partir de l'image personnalisée et connectez tous les disques persistants nécessaires.
- Définissez l'indicateur de suppression automatique sur "false" pour les disques persistants.
- Appliquez le dernier fichier de sauvegarde copié sur Cloud Storage. Pour ce faire, suivez les instructions de récupération des fichiers de sauvegarde spécifiques à votre système de base de données.
- Appliquez le dernier ensemble de fichiers journaux de transactions copié dans Cloud Storage.
- Remplacez l'instance minimale par une instance de taille plus importante, qui sera en mesure d'accepter le trafic de production.
- Basculez les clients pour qu'ils pointent vers la base de données récupérée dans Google Cloud.
Lorsque votre environnement de production est à nouveau en cours d'exécution et capable d'accepter des charges de travail de production, vous devez répéter la procédure que vous avez suivie pour basculer vers l'environnement de récupérationGoogle Cloud , mais en inversant les étapes. Une séquence de retour à l'environnement de production se déroule typiquement de la façon suivante :
- Effectuez une sauvegarde de la base de données exécutée sur Google Cloud.
- Copiez le fichier de sauvegarde dans l'environnement de production.
- Appliquez le fichier de sauvegarde à votre système de base de données de production.
- Empêchez les clients de se connecter au système de base de données dansGoogle Cloud(par exemple, en arrêtant le service système de la base de données). À compter de ce moment, votre application sera indisponible jusqu'à la restauration de l'environnement de production.
- Copiez tous les fichiers journaux de transactions dans l'environnement de production et appliquez-les.
- Redirigez les connexions clientes vers l'environnement de production.
Solution 2 : Réplication vers un serveur de secours sur Google Cloud
Pour atteindre des valeurs RTO et RPO faibles, vous pouvez répliquer (pas simplement sauvegarder) des données et, dans certains cas, l'état de la base de données en temps réel sur une réplique de votre serveur de base de données.
- Connectez votre réseau sur site et votre réseau Google Cloud .
- Créez une image personnalisée de votre serveur de base de données sur Google Cloud. La configuration doit être identique pour les deux serveurs de base de données (image personnalisée et serveur sur site).
- Démarrez une instance à partir de l'image personnalisée et connectez tous les disques persistants nécessaires.
- Définissez l'indicateur de suppression automatique sur "false" pour les disques persistants.
- Configurez la réplication entre votre serveur de base de données sur site et le serveur de base de données cible dans Google Cloud en suivant les instructions spécifiques au logiciel de base de données.
- En mode de fonctionnement normal, les clients sont configurés pour pointer vers le serveur de base de données hébergé sur site.
Après avoir configuré cette topologie de réplication, basculez les clients pour qu'ils pointent vers le serveur de secours exécuté sur votre réseau Google Cloud .
Lorsque votre environnement de production est sauvegardé et à nouveau capable d'accepter des charges de travail de production, vous devez resynchroniser le serveur de base de données de production avec le serveur de base de donnéesGoogle Cloud , puis basculer les clients pour qu'ils pointent à nouveau vers l'environnement de production.
L'environnement de production est Google Cloud
Dans ce scénario, votre environnement de production et votre environnement de reprise après sinistre s'exécutent tous deux sur Google Cloud.
Sauvegarde et récupération de données
Pour les sauvegardes de données, il est courant d'utiliser un modèle de stockage à plusieurs niveaux. Lorsque votre charge de travail de production est exécutée sur Google Cloud, le système de stockage à plusieurs niveaux correspond au diagramme présenté ci-dessous. Nous vous recommandons de transférer les données que vous souhaitez sauvegarder vers un niveau de stockage de coût inférieur, dans la mesure où vous aurez certainement moins besoin d'accéder à ces données.
Ce modèle utilise les composants fondamentaux de reprise après sinistre suivants :
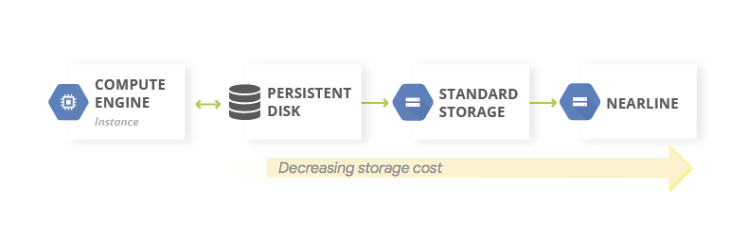
Dans la mesure où les classes de stockage Nearline, Coldline et Archive sont destinées à stocker des données rarement consultées, des coûts supplémentaires sont associés à la récupération des données ou des métadonnées stockées dans ces classes, et des durées minimales de stockage vous sont facturées.
Sauvegarde et récupération de base de données
Lorsque vous utilisez une base de données autogérée (par exemple, si vous avez installé MySQL, PostgreSQL ou SQL Server sur une instance Compute Engine), les problématiques opérationnelles inhérentes à la gestion de bases de données de production sur site sont toujours présentes, à la différence près que vous n'avez plus besoin de gérer l'infrastructure sous-jacente.
Le service Backup and DR est une solution centralisée et cloud native de sauvegarde et de reprise après sinistre pour les charges de travail cloud et hybrides. Elle permet de récupérer rapidement les données et de reprendre rapidement les opérations commerciales essentielles.
Pour en savoir plus sur l'utilisation de Backup and DR pour les scénarios de bases de données autogérées sur Google Cloud, consultez les documents suivants :
Vous pouvez également définir des configurations de haute disponibilité en utilisant des composants fondamentaux de reprise après sinistre appropriés afin de maintenir une valeur RTO faible. Vous pouvez concevoir la configuration de votre base de données de façon à pouvoir effectuer la récupération dans un état aussi proche que possible de l'état antérieur au sinistre. Cela vous aidera à maintenir une valeur RPO faible. Google Cloud propose un large éventail d'options pour ce scénario.
Cette section présente deux approches courantes pour la conception de votre architecture de récupération de base de données pour des bases de données autogérées déployées sur Google Cloud .
Récupération d'un serveur de base de données sans état de synchronisation
Un modèle courant consiste à permettre la récupération d'un serveur de base de données sans qu'il soit nécessaire de synchroniser l'état du système avec une instance répliquée de secours à jour.
Ce modèle utilise les composants fondamentaux de reprise après sinistre suivants :
- Compute Engine
- Groupes d'instances gérés
- Cloud Load Balancing (équilibrage de la charge interne)
Le schéma suivant illustre un exemple d'architecture prenant en compte ce scénario. En mettant en œuvre cette architecture, vous disposez d'un plan de reprise après sinistre qui réagit automatiquement en cas de panne. Aucune opération de récupération manuelle n'est requise.

Pour configurer ce scénario, procédez comme suit :
- Créez un réseau VPC.
Créez une image personnalisée configurée avec le serveur de base de données. Pour ce faire, procédez comme suit :
- Configurez le serveur pour que les fichiers de base de données et les fichiers journaux soient écrits sur un disque persistant standard associé.
- Créez un instantané à partir du disque persistant associé.
- Configurez un script de démarrage pour créer un disque persistant à partir de l'instantané et installer les partitions du disque.
- Créez une image personnalisée du disque de démarrage.
Créez un modèle d'instance qui utilise l'image.
À l'aide du modèle d'instance, configurez un groupe d'instances géré avec une taille cible de 1.
Configurez la vérification de l'état à l'aide de métriques Cloud Monitoring.
Configurez l'équilibrage de charge interne à l'aide du groupe d'instances géré.
Configurez une tâche planifiée pour créer des instantanés réguliers du disque persistant.
Dans le cas où une instance de base de données de remplacement est nécessaire, cette configuration va automatiquement :
- mettre en service un autre serveur de base de données exécutant la bonne version dans la même zone ;
- associer un disque persistant contenant la dernière sauvegarde et les fichiers journaux de transactions les plus récents à la nouvelle instance de serveur de base de données créée ;
- minimiser le nombre d'opérations requises pour reconfigurer les clients qui communiquent avec votre serveur de base de données en réponse à un événement ;
- vérifier que les contrôles de sécurité Google Cloud (stratégies IAM, paramètres de pare-feu) qui s'appliquent au serveur de base de données de production s'appliquent également au serveur de base de données récupéré.
Comme l'instance de remplacement est créée à partir d'un modèle d'instance, les contrôles appliqués à l'instance d'origine s'appliquent aussi à l'instance de remplacement.
Ce scénario exploite certaines des fonctionnalités de haute disponibilité offertes parGoogle Cloud. Vous n'avez pas besoin d'effectuer d'opérations de basculement, car elles sont exécutées automatiquement en cas de sinistre. L'équilibreur de charge interne permet de s'assurer que l'adresse IP utilisée pour le serveur de base de données ne change jamais, même dans le cas où une instance de remplacement est nécessaire. Le modèle d'instance et l'image personnalisée garantissent que l'instance de remplacement est configurée de la même manière que l'instance qu'elle remplace. En prenant des instantanés réguliers des disques persistants, vous vous assurez que lorsque des disques sont recréés à partir des instantanés et associés à l'instance de remplacement, cette dernière utilise des données récupérées qui sont conformes à la valeur PDMA dictée par la fréquence des instantanés. Dans cette architecture, les derniers fichiers journaux de transactions écrits sur le disque persistant sont également restaurés automatiquement.
Le groupe d'instances géré fournit une haute disponibilité en profondeur. Il fournit des mécanismes qui réagissent aux défaillances survenant au niveau des applications ou des instances. Vous n'avez pas à intervenir manuellement si l'un de ces scénarios se produit. En définissant une taille cible de 1, vous n'aurez qu'une seule instance active qui s'exécutera dans le groupe d'instances géré et diffusera le trafic.
Les disques persistants standards sont de type zonal. Par conséquent, en cas de défaillance d'une zone, des instantanés sont nécessaires pour recréer les disques. Notez également que les instantanés sont disponibles dans toutes les régions. Vous pouvez donc restaurer un disque aussi bien dans la même région que dans une région différente.
Une variante de cette configuration consiste à utiliser des disques persistants régionaux plutôt que des disques persistants standards. Dans ce cas, vous n'avez pas besoin de restaurer l'instantané dans le cadre du processus de récupération.
La variante que vous choisissez est déterminée par votre budget et les valeurs des indicateurs DMIA et PDMA.
Récupération à la suite d'une corruption partielle dans des bases de données très volumineuses
La réplication asynchrone sur disque persistant offre une réplication de stockage de blocs à faibles RPO et RTO pour la reprise après sinistre active/passive interrégionale. Cette option de stockage vous permet de gérer la réplication pour les charges de travail Compute Engine au niveau de l'infrastructure, et non au niveau de la charge de travail.
Si vous utilisez une base de données capable de stocker des pétaoctets de données, il se peut qu'une panne affecte certaines données, mais pas toutes. En pareil cas, vous souhaiterez certainement minimiser la quantité de données à restaurer, car vous n'avez pas besoin de récupérer l'intégralité de la base de données pour restaurer seulement certaines données (ou parce que vous ne voulez pas procéder ainsi).
Vous pouvez adopter un certain nombre de "stratégies de réduction" pour cela :
- Vous pouvez stocker vos données dans différentes tables pour des périodes spécifiques. Avec cette méthode, vous n'aurez besoin de restaurer qu'un sous-ensemble de données dans une nouvelle table, et non un ensemble de données complet.
Vous pouvez stocker les données d'origine dans Cloud Storage. Cette approche vous permet de créer une table et de recharger les données qui ne sont pas corrompues. Ensuite, vous pouvez ajuster vos applications pour qu'elles pointent vers la nouvelle table.
De plus, si votre DMIA le permet, vous pouvez empêcher l'accès à la table contenant les données corrompues en laissant vos applications hors ligne jusqu'à ce que les données non corrompues soient restaurées dans une nouvelle table.
Services de base de données gérés sur Google Cloud
Cette section présente certaines méthodes que vous pouvez utiliser pour mettre en œuvre des mécanismes de sauvegarde et de récupération appropriés pour les services de base de données gérés surGoogle Cloud.
Les bases de données gérées sont conçues pour être déployées à grande échelle, ce qui implique que les mécanismes de sauvegarde et de restauration associés aux SGBDR traditionnels ne sont généralement pas disponibles. Comme dans le cas des bases de données autogérées, si vous utilisez une base de données capable de stocker des pétaoctets de données, vous souhaitez certainement réduire la quantité de données qu'il sera nécessaire de restaurer dans le cadre d'une reprise après sinistre. Il existe un certain nombre de stratégies pouvant vous aider à atteindre cet objectif pour chaque service de base de données géré.
Bigtable inclut un mécanisme de réplication. Une base de données Bigtable répliquée offre une disponibilité plus élevée qu'un cluster unique, un débit en lecture plus conséquent, ainsi qu'une durabilité et une résilience plus importantes en cas de défaillance d'une zone ou d'une région.
Les sauvegardes Bigtable constituent un service entièrement géré qui vous permet d'enregistrer une copie du schéma et des données d'une table, puis d'effectuer une restauration depuis la sauvegarde vers une nouvelle table ultérieurement.
Vous pouvez également exporter des tables depuis Bigtable sous la forme d'une série de fichiers séquentiels Hadoop. Vous pouvez ensuite stocker ces fichiers dans Cloud Storage ou les utiliser pour réimporter les données dans une autre instance de Bigtable. Vous pouvez répliquer votre ensemble de données Bigtable de manière asynchrone entre les différentes zones d'une région Google Cloud .
BigQuery. Si vous souhaitez archiver des données, vous pouvez exploiter le stockage à long terme offert par BigQuery. Si aucune modification n'est apportée à une table sur une période de 90 jours consécutifs, le prix de stockage de cette table diminue automatiquement de 50 %. Lorsqu'une table est considérée comme un espace de stockage à long terme, cela n'a aucune incidence sur les performances, la durabilité, la disponibilité ni sur toute autre fonctionnalité. Notez toutefois que si la table est modifiée, le prix de stockage normal s'applique à nouveau et le compte à rebours de 90 jours redémarre.
BigQuery est répliqué dans deux zones d'une même région, mais cela n'aidera pas à empêcher la corruption de vos tables. Par conséquent, vous devez définir un plan pour vous assurer de pouvoir récupérer les données de vos tables en cas de corruption. Par exemple, vous pouvez effectuer les opérations suivantes :
- Si vous détectez une corruption dans les 7 jours, vous pouvez utiliser les décorateurs d'instantanés pour effectuer une requête pointant vers une date antérieure afin de récupérer la table telle qu'elle était avant la corruption.
- Vous pouvez exporter les données à partir de BigQuery, puis créer une table contenant les données exportées, mais pas les données corrompues.
- Vous pouvez stocker vos données dans différentes tables pour des périodes spécifiques. Avec cette méthode, vous n'aurez besoin de restaurer qu'un sous-ensemble de données dans une nouvelle table, et non un ensemble de données complet.
- Effectuez des copies de votre ensemble de données à des périodes spécifiques. Vous pouvez utiliser ces copies si un événement de corruption des données s'est produit au-delà de ce qu'une requête à un moment précis peut capturer (par exemple, il y a plus de sept jours). Vous pouvez également copier un ensemble de données d'une région à une autre pour garantir la disponibilité des données en cas de défaillance de la région.
- Stockez les données d'origine dans Cloud Storage afin de pouvoir créer une table et de recharger les données qui ne sont pas corrompues. Ensuite, vous pouvez ajuster vos applications pour qu'elles pointent vers la nouvelle table.
Firestore. Le service d'exportation et d'importation géré vous permet d'importer et d'exporter des entités Firestore à l'aide d'un bucket Cloud Storage. Vous pouvez ensuite implémenter un processus permettant de récupérer les données en cas de suppression accidentelle.
Cloud SQL. Si vous utilisez Cloud SQL, la base de donnéesGoogle Cloud MySQL entièrement gérée, vous devez activer les sauvegardes automatiques et la journalisation binaire pour vos instances Cloud SQL. Cette approche vous permet d'effectuer une récupération à un moment précis, et ainsi de restaurer votre base de données à partir d'une sauvegarde et de la déployer sur une nouvelle instance Cloud SQL. Pour en savoir plus, consultez À propos des sauvegardes Cloud SQL et À propos de la reprise après sinistre dans Cloud SQL.
Vous pouvez également configurer Cloud SQL dans une configuration haute disponibilité et des instances répliquées interrégionales afin d'optimiser le temps d'activité en cas de défaillance d'une zone ou d'une région.
Si vous avez activé la maintenance planifiée avec un temps d'arrêt quasiment nul pour Cloud SQL, vous pouvez évaluer l'impact des événements de maintenance sur vos instances en simulant des événements de maintenance planifiée avec un temps d'arrêt quasiment nul sur Cloud SQL pour MySQL et Cloud SQL pour PostgreSQL.
Pour l'édition Cloud SQL Enterprise Plus, vous pouvez utiliser la reprise après sinistre avancée pour simplifier les processus de récupération et de repli sans perte de données après avoir effectué un basculement interrégional.
Spanner. Vous pouvez utiliser des modèles Dataflow pour effectuer une exportation complète de votre base de données vers un ensemble de fichiers Avro stockés dans un bucket Cloud Storage, puis utiliser un autre modèle pour réimporter les fichiers exportés dans une nouvelle base de données Spanner.
Si vous souhaitez disposer d'un plus grand contrôle sur les sauvegardes, le connecteur Dataflow vous offre la possibilité d'écrire du code pour lire et écrire des données sur Spanner dans un pipeline Dataflow. Par exemple, vous pouvez utiliser le connecteur pour copier des données stockées sur Spanner et définir Cloud Storage en tant que cible pour la sauvegarde de ces données. La vitesse à laquelle les données stockées sur Spanner peuvent être lues (ou réécrites sur Spanner) dépend du nombre de nœuds configurés. Elle exerce un impact direct sur vos valeurs RTO.
La fonctionnalité d'horodatage de commits de Spanner peut être utile pour les sauvegardes incrémentielles, car elle permet de ne sélectionner que les lignes ajoutées ou modifiées depuis la dernière sauvegarde complète.
Pour les sauvegardes gérées, la fonctionnalité Sauvegarde et restauration de Spanner vous permet de créer des sauvegardes cohérentes pouvant être conservées pendant une durée maximale d'un an. La valeur RTO est inférieure par rapport à l'opération d'exportation, car l'opération de restauration installe directement la sauvegarde sans copier les données.
Pour des valeurs RTO faibles, vous pouvez configurer une instance Spanner de secours semi-automatique (warm standby) offrant le nombre minimal de nœuds requis pour répondre aux exigences de stockage et de débit en lecture et écriture.
La récupération à un moment précis (PITR) de Spanner vous permet de récupérer des données à partir d'un moment précis. Par exemple, si un opérateur écrit par inadvertance des données ou qu'un déploiement d'application corrompt la base de données, vous pouvez, avec PITR, récupérer les données à un moment antérieur précis (au maximum sept jours).
Cloud Composer. Vous pouvez utiliser Cloud Composer (une version gérée d'Apache Airflow) pour planifier des sauvegardes régulières de plusieurs bases de donnéesGoogle Cloud . Vous pouvez créer un graphe orienté acyclique (DAG) à exécuter selon le planning défini (par exemple, quotidiennement) pour copier les données dans un autre projet, un autre ensemble de données ou une autre table (selon la solution utilisée), ou encore pour exporter les données vers Cloud Storage.
L'exportation ou la copie de données peut être effectuée à l'aide des différents opérateurs Cloud Platform.
Par exemple, vous pouvez créer un DAG pour effectuer l'une des opérations suivantes :
- Exporter une table BigQuery vers Cloud Storage à l'aide de l'opérateur BigQueryToCloudStorageOperator
- Exporter Firestore en mode Datastore (Datastore) vers Cloud Storage à l'aide de l'opérateur DatastoreExportOperator
- Exporter des tables MySQL vers Cloud Storage à l'aide de l'opérateur MySqlToGoogleCloudStorageOperator
- Exporter des tables Postgres vers Cloud Storage à l'aide de l'opérateur PostgresToGoogleCloudStorageOperator
L'environnement de production est déployé sur une autre infrastructure cloud
Dans ce scénario, votre environnement de production utilise un autre fournisseur cloud, et votre plan de reprise après sinistre implique l'utilisation de Google Cloud en tant que site de récupération.
Sauvegarde et récupération de données
Le transfert de données entre solutions de stockage d'objets est un cas d'utilisation courant pour les scénarios de reprise après sinistre. Le service de transfert de stockage est compatible avec Amazon S3. C'est la solution que nous vous recommandons pour transférer des objets d'Amazon S3 vers Cloud Storage.
Vous pouvez configurer une tâche de transfert pour planifier une synchronisation périodique entre la source de données et le récepteur de données. Vous pouvez appliquer des filtres avancés basés sur les dates de création des fichiers, des filtres sur les noms de fichiers, ainsi que spécifier les plages horaires de votre choix pour le transfert des données. Pour atteindre la valeur RPO souhaitée, vous devez prendre en compte les facteurs suivants :
Taux de changement. Quantité de données générées ou mises à jour pendant un certain temps. Plus le taux de changement est élevé, plus vous avez besoin de ressources pour transférer les modifications vers la destination à chaque période de transfert incrémentielle.
Performances des transferts. Temps nécessaire pour transférer des fichiers. Pour les transferts de fichiers volumineux, cette opération est généralement déterminée par la bande passante disponible entre la source et la destination. Toutefois, si une tâche de transfert comprend un grand nombre de petits fichiers, le taux RPS peut devenir un facteur limitant. Dans ce cas, vous pouvez planifier plusieurs tâches simultanées afin de faire évoluer les performances tant que la bande passante disponible est suffisante. Nous vous recommandons de mesurer les performances de transfert à l'aide d'un sous-ensemble représentatif de vos données réelles.
Frequence. Intervalle entre les tâches de sauvegarde. La fraîcheur des données à l'emplacement de destination correspond à la dernière fois qu'une tâche de transfert a été planifiée. Par conséquent, il est important que les intervalles entre les tâches de transfert successives ne soient pas supérieurs à votre objectif RPO. Par exemple, si l'objectif RPO est un jour, la tâche de transfert doit être planifiée au moins une fois par jour.
Surveillance et alertes. Le service de transfert de stockage fournit des notifications Pub/Sub pour divers événements. Nous vous recommandons de vous abonner à ces notifications pour gérer les défaillances ou les changements inattendus des temps d'exécution des tâches.
Sauvegarde et récupération de base de données
L'objet de ce document n'est pas de présenter en détail les divers mécanismes de sauvegarde et de récupération intégrés dans les solutions de bases de données tierces, ni de décrire les techniques de sauvegarde et de récupération proposées par les autres fournisseurs de services cloud. Si vous exploitez des bases de données non gérées sur des services de calcul, vous pouvez tirer parti des infrastructures haute disponibilité proposées par votre fournisseur de services cloud de production. Vous pouvez renforcer leurs capacités en déployant une solution haute disponibilité dans Google Cloud, ou utiliser Cloud Storage comme "destination finale" pour le stockage à froid de vos fichiers de sauvegarde de base de données.
Étape suivante
- En savoir plus sur les zones géographiques et régionsGoogle Cloud
Consultez d'autres documents de cette série sur la reprise après sinistre :
- Guide de planification de reprise après sinistre
- Structure de la reprise après sinistre
- Scénarios de reprise après sinistre pour les applications
- Concevoir une solution de reprise après sinistre pour des charges de travail limitées à la localité
- Cas d'utilisation de reprise après sinistre : applications d'analyse de données limitées à la localité
- Concevoir une solution de reprise après sinistre pour les pannes d'infrastructure cloud
- Architectures haute disponibilité pour les clusters MySQL sur Compute Engine
Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.