Este documento é a segunda parte de uma série que aborda a recuperação de desastres (RD) no Google Cloud. Esta parte aborda os serviços e os produtos que pode usar como bases para o seu plano de DR, tanto Google Cloud produtos como produtos que funcionam em várias plataformas.
A série é composta por estas partes:
- Guia de planeamento de recuperação de desastres
- Bases de recuperação de desastres (este artigo)
- Cenários de recuperação de desastres para dados
- Cenários de recuperação de desastres para aplicações
- Arquitetar a recuperação de desastres para cargas de trabalho restritas por localidade
- Exemplos de utilização de recuperação de desastres: aplicações de estatísticas de dados restritas à localidade
- Criar arquiteturas de recuperação de desastres para interrupções da infraestrutura na nuvem
Google Cloud tem uma vasta gama de produtos que pode usar como parte da sua arquitetura de recuperação de desastres. Esta secção aborda as funcionalidades relacionadas com a recuperação de desastres dos produtos mais usados como elementos básicos de recuperação de desastres. Google Cloud
Muitos destes serviços têm funcionalidades de alta disponibilidade (AA). A AD não se sobrepõe totalmente à RD, mas muitos dos objetivos da AD também se aplicam à criação de um plano de RD. Por exemplo, ao tirar partido das funcionalidades de HA, pode criar arquiteturas que otimizam o tempo de atividade e que podem mitigar os efeitos de falhas de pequena escala, como a falha de uma única VM. Para saber mais sobre a relação entre a recuperação de desastres e a alta disponibilidade, consulte o Guia de planeamento de recuperação de desastres.
As secções seguintes descrevem estes componentes fundamentais de Google Cloud RD e como ajudam a implementar os seus objetivos de RD.
Computação e armazenamento
A tabela seguinte apresenta um resumo das funcionalidades nos serviços de computação e armazenamento do Google Cloud que servem de base para a recuperação de desastres:
| Produto | Funcionalidade |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine (GKE) |
|
Para mais informações sobre como as funcionalidades e o design destes e de outros Google Cloud produtos podem influenciar a sua estratégia de recuperação de desastres, consulte o artigo Arquitetar a recuperação de desastres para interrupções da infraestrutura na nuvem: referência do produto.
Compute Engine
O Compute Engine fornece instâncias de máquinas virtuais (VMs) e é o motor do Google Cloud. Além de configurar, iniciar e monitorizar instâncias do Compute Engine, normalmente, usa uma variedade de funcionalidades relacionadas para implementar um plano de DR.
Para cenários de recuperação de desastres, pode impedir a eliminação acidental de VMs definindo a flag de proteção contra eliminação. Isto é particularmente útil quando aloja serviços com estado, como bases de dados.
Para obter informações sobre como cumprir valores de RTO e RPO baixos, consulte o artigo Conceber sistemas resilientes.
Modelos de instâncias
Pode usar modelos de instâncias do Compute Engine para guardar os detalhes de configuração da VM e, em seguida, criar instâncias do Compute Engine a partir de modelos de instâncias existentes. Pode usar o modelo para iniciar quantas instâncias precisar, configuradas exatamente da forma que quiser quando precisar de configurar o seu ambiente de destino de recuperação de desastres. Os modelos de instâncias são replicados globalmente, pelo que pode recriar a instância em qualquer lugar com a mesma configuração. Google Cloud
Para obter mais informações, consulte os seguintes recursos:
Para ver detalhes sobre a utilização de imagens do Compute Engine, consulte a secção Equilibrar a configuração da imagem e a velocidade de implementação mais adiante neste documento.
Grupos de instâncias geridas
Os grupos de instâncias geridos funcionam com o Cloud Load Balancing (abordado mais adiante neste documento) para distribuir tráfego para grupos de instâncias configuradas de forma idêntica que são copiadas entre zonas. Os grupos de instâncias geridas permitem funcionalidades como o dimensionamento automático e a autorrecuperação, em que o grupo de instâncias geridas pode eliminar e recriar instâncias automaticamente.
Reservas
O Compute Engine permite a reserva de instâncias de VMs numa zona específica, usando tipos de máquinas personalizados ou predefinidos, com ou sem GPUs adicionais ou SSDs locais. Para garantir a capacidade das suas cargas de trabalho críticas para a empresa para a recuperação de desastres, deve criar reservas nas zonas de destino de recuperação de desastres. Sem reservas, existe a possibilidade de não obter a capacidade a pedido de que precisa para cumprir o seu objetivo de tempo de recuperação. As reservas podem ser úteis em cenários de RD frios, quentes ou muito quentes. Permitem-lhe manter os recursos de recuperação disponíveis para a comutação por falha para satisfazer as necessidades de RTO mais baixas, sem ter de os configurar e implementar totalmente com antecedência.
Discos persistentes e instantâneos
Os discos persistentes são dispositivos duradouros de armazenamento de rede aos quais as suas instâncias podem aceder. São independentes das suas instâncias, pelo que pode desanexar e mover discos persistentes para manter os seus dados mesmo depois de eliminar as instâncias.
Pode fazer cópias de segurança incrementais ou instantâneos de VMs do Compute Engine que pode copiar entre regiões e usar para recriar discos persistentes em caso de desastre. Além disso, pode criar capturas de ecrã de discos persistentes para se proteger contra a perda de dados devido a erro do utilizador. Os instantâneos são incrementais e demoram apenas alguns minutos a criar, mesmo que os discos de instantâneos estejam anexados a instâncias em execução.
Os discos persistentes têm redundância incorporada para proteger os seus dados contra falhas de equipamento e garantir a disponibilidade dos dados através de eventos de manutenção do centro de dados. Os discos persistentes são zonais ou regionais. Os discos persistentes regionais replicam as gravações em duas zonas numa região. Em caso de uma indisponibilidade zonal, uma instância de VM de cópia de segurança pode forçar a associação de um disco persistente regional na zona secundária. Para saber mais, consulte o artigo Opções de alta disponibilidade com discos persistentes regionais.
Manutenção transparente
A Google faz regularmente a manutenção da sua infraestrutura através da aplicação de patches aos sistemas com o software mais recente, da realização de testes de rotina e manutenção preventiva, e do trabalho para garantir que a infraestrutura da Google é o mais rápida e eficiente possível.
Por predefinição, todas as instâncias do Compute Engine estão configuradas para que estes eventos de manutenção sejam transparentes para as suas aplicações e cargas de trabalho. Para mais informações, consulte Manutenção transparente.
Quando ocorre um evento de manutenção, o Compute Engine usa a migração em direto para migrar automaticamente as suas instâncias em execução para outro anfitrião na mesma zona. A migração em direto permite à Google realizar manutenção essencial para manter a infraestrutura protegida e fiável sem interromper nenhuma das suas VMs.
Ferramenta de importação de discos virtuais
A ferramenta de importação de discos virtuais permite-lhe importar formatos de ficheiros, incluindo VMDK, VHD e RAW, para criar novas máquinas virtuais do Compute Engine. Com esta ferramenta, pode criar máquinas virtuais do Compute Engine com a mesma configuração das suas máquinas virtuais no local. Esta é uma boa abordagem quando não consegue configurar imagens do Compute Engine a partir dos binários de origem do software já instalado nas suas imagens.
Cópias de segurança automáticas
Pode automatizar as cópias de segurança das suas instâncias do Compute Engine através de etiquetas. Por exemplo, pode criar um modelo de plano de cópia de segurança através do serviço de cópia de segurança e recuperação de desastres e aplicar automaticamente o modelo às suas instâncias do Compute Engine.
Para mais informações, consulte o artigo Automatize a proteção de novas instâncias do Compute Engine.
Cloud Storage
O Cloud Storage é um local de armazenamento de objetos ideal para armazenar ficheiros de cópia de segurança. Oferece diferentes classes de armazenamento adequadas para exemplos de utilização específicos, conforme descrito no diagrama seguinte.

Em cenários de recuperação de desastres, o Nearline, o Coldline e o Archive Storage são de particular interesse. Estas classes de armazenamento reduzem o custo de armazenamento em comparação com o armazenamento padrão. No entanto, existem custos adicionais associados à obtenção de dados ou metadados armazenados nestas classes, bem como durações mínimas de armazenamento que lhe são cobradas. O Nearline foi concebido para cenários de cópia de segurança em que o acesso é, no máximo, uma vez por mês, o que é ideal para lhe permitir realizar testes de esforço de DR regulares, mantendo os custos baixos.
O Nearline, o Coldline e o Archive estão otimizados para acesso pouco frequente, e o modelo de preços foi concebido tendo isto em conta. Por conseguinte, são-lhe cobrados períodos mínimos de armazenamento, e existem custos adicionais para obter dados ou metadados nestas classes antes do período mínimo de armazenamento da classe.
Para proteger os seus dados num contentor do Cloud Storage contra a eliminação acidental ou maliciosa, pode usar a funcionalidade de eliminação temporária para preservar objetos eliminados e substituídos durante um período especificado, e a funcionalidade de retenções de objetos para impedir a eliminação ou as atualizações de objetos.
O Serviço de transferência de armazenamento permite-lhe importar dados do Amazon S3, do Azure Blob Storage ou de origens de dados no local para o Cloud Storage. Em cenários de recuperação de desastres, pode usar o serviço de transferência de armazenamento para fazer o seguinte:
- Fazer uma cópia de segurança de dados de outros fornecedores de armazenamento num contentor do Cloud Storage.
- Mova dados de um contentor numa região dupla ou multirregião para um contentor numa região para reduzir os custos de armazenamento de cópias de segurança.
Filestore
As instâncias do Filestore são servidores de ficheiros NFS totalmente geridos para utilização com aplicações em execução em instâncias do Compute Engine ou clusters do GKE.
Os níveis Básico e zonal do Filestore são recursos zonais e não suportam a replicação entre zonas, enquanto as instâncias do nível empresarial do Filestore são recursos regionais. Para ajudar a aumentar a resiliência do seu ambiente do Filestore, recomendamos que use instâncias do nível Enterprise.
Google Kubernetes Engine
O GKE é um ambiente gerido e pronto para produção para implementar aplicações contentorizadas. O GKE permite-lhe orquestrar sistemas de HA e inclui as seguintes funcionalidades:
- Reparação automática de nós. Se um nó falhar verificações de estado consecutivas durante um período prolongado (aproximadamente 10 minutos), o GKE inicia um processo de reparação para esse nó.
- Sondas de atividade e disponibilidade. Pode especificar uma sondagem de atividade, que indica periodicamente ao GKE que o pod está em execução. Se o pod falhar na sondagem, pode ser reiniciado.
- Clusters regionais e de várias zonas. Pode distribuir recursos do Kubernetes por várias zonas numa região.
- O Multi-cluster Gateway permite-lhe configurar recursos de equilíbrio de carga partilhados em vários clusters do GKE em diferentes regiões.
- A cópia de segurança do GKE permite-lhe fazer cópias de segurança e restaurar cargas de trabalho em clusters do GKE.
Redes e transferência de dados
A tabela seguinte apresenta um resumo das funcionalidades nos serviços de Google Cloud rede e de transferência de dados que servem de base para a DR:
| Produto | Funcionalidade |
|---|---|
| Cloud Load Balancing |
|
| Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
O Cloud Load Balancing oferece HA para Google Cloud produtos de computação através da distribuição do tráfego de utilizadores por várias instâncias das suas aplicações. Pode configurar o Cloud Load Balancing com verificações de estado que determinam se as instâncias estão disponíveis para trabalhar, para que o tráfego não seja encaminhado para instâncias com falhas.
O Cloud Load Balancing fornece um único endereço IP anycast para apresentar as suas aplicações. As suas aplicações podem ter instâncias em execução em diferentes regiões (por exemplo, na Europa e nos EUA), e os utilizadores finais são direcionados para o conjunto de instâncias mais próximo. Além de fornecer balanceamento de carga para serviços expostos à Internet, pode configurar o balanceamento de carga interno para os seus serviços através de um endereço IP de balanceamento de carga privado. Este endereço IP só é acessível a instâncias de VM internas à sua nuvem virtual privada (VPC).
Para mais informações, consulte a Vista geral do Cloud Load Balancing.
Cloud Service Mesh
O Cloud Service Mesh é uma malha de serviços gerida pela Google que está disponível no Google Cloud. O Cloud Service Mesh fornece telemetria detalhada para ajudar a recolher estatísticas detalhadas sobre as suas aplicações. Suporta serviços que são executados numa variedade de infraestruturas de computação.
A Cloud Service Mesh também suporta a gestão avançada de tráfego e funcionalidades de encaminhamento, como a interrupção de circuitos e a injeção de falhas. Com a interrupção de circuito, pode aplicar limites a pedidos para um serviço específico. Quando os limites de interrupção de circuito são atingidos, os pedidos são impedidos de chegar ao serviço, o que impede que o serviço se degrade ainda mais. Com a injeção de falhas, a malha de serviços do Google Cloud pode introduzir atrasos ou anular uma fração dos pedidos a um serviço. A injeção de falhas permite-lhe testar a capacidade do seu serviço de sobreviver a atrasos nos pedidos ou a pedidos anulados.
Para mais informações, consulte a vista geral da Cloud Service Mesh.
Cloud DNS
O Cloud DNS oferece uma forma programática de gerir as suas entradas de DNS como parte de um processo de recuperação automatizado. O Cloud DNS usa a rede global de servidores de nomes Anycast da Google para publicar as suas zonas DNS a partir de localizações redundantes em todo o mundo, oferecendo elevada disponibilidade e menor latência aos seus utilizadores.
Se optou por gerir as entradas DNS no local, pode ativar as VMs no Google Cloud para resolver estes endereços através do encaminhamento do Cloud DNS.
O Cloud DNS suporta políticas para configurar a forma como responde aos pedidos de DNS. Por exemplo, pode configurar políticas de encaminhamento de DNS para direcionar o tráfego com base em critérios específicos, como ativar a comutação por falha para uma configuração de cópia de segurança para oferecer elevada disponibilidade ou encaminhar pedidos de DNS com base na respetiva localização geográfica.
Cloud Interconnect
O Cloud Interconnect oferece formas de mover informações de outras fontes para o Google Cloud. Abordamos este produto mais tarde na secção Transferir dados para e a partir de Google Cloud.
Gestão e monitorização
A tabela seguinte apresenta um resumo das funcionalidades nos Google Cloud serviços de gestão e monitorização que servem de base para a recuperação de desastres:
| Produto | Funcionalidade |
|---|---|
| Painel de controlo de estado do Google Cloud |
|
| Observabilidade do Google Cloud |
|
| Google Cloud Managed Service for Prometheus |
|
Painel de controlo de estado do Google Cloud
O Painel de controlo de estado da nuvem mostra a disponibilidade atual dos Google Cloud serviços. Pode ver o estado na página e subscrever um feed RSS que é atualizado sempre que há notícias sobre um serviço.
Cloud Monitoring
O Cloud Monitoring recolhe métricas, eventos e metadados de Google Cloud, AWS, testes de atividade alojados, instrumentação de aplicações e uma variedade de outros componentes de aplicações. Pode configurar os alertas para enviar notificações para ferramentas de terceiros como o Slack ou o Pagerduty, de forma a fornecer atualizações atempadas aos administradores.
O Cloud Monitoring permite-lhe criar verificações de tempo de atividade para pontos finais disponíveis publicamente e para pontos finais nas suas VPCs. Por exemplo, pode monitorizar URLs, instâncias do Compute Engine, revisões do Cloud Run e recursos de terceiros, como instâncias do Amazon Elastic Compute Cloud (EC2).
Google Cloud Managed Service for Prometheus
O Google Cloud Managed Service for Prometheus é uma solução multicloud e entre projetos gerida pela Google para métricas do Prometheus. Permite-lhe monitorizar e receber alertas globalmente sobre as suas cargas de trabalho, usando o Prometheus, sem ter de gerir e operar manualmente o Prometheus à escala.
Para mais informações, consulte o Google Cloud Managed Service for Prometheus.
Bases de DR multiplataforma
Quando executa cargas de trabalho em mais do que uma plataforma, uma forma de reduzir as despesas gerais operacionais é selecionar ferramentas que funcionem com todas as plataformas que está a usar. Esta secção aborda algumas ferramentas e serviços independentes da plataforma e, por conseguinte, suportam cenários de DR multiplataforma.
Infraestrutura como código
Ao definir a sua infraestrutura através de código, em vez de interfaces gráficas ou scripts, pode adotar ferramentas de modelos declarativos e automatizar o aprovisionamento e a configuração da infraestrutura em várias plataformas. Por exemplo, pode usar o Terraform e o Infrastructure Manager para acionar a configuração declarativa da infraestrutura.
Ferramentas de gestão da configuração
Para uma infraestrutura de recuperação de desastres grande ou complexa, recomendamos ferramentas de gestão de software independentes da plataforma, como o Chef e o Ansible. Estas ferramentas garantem que as configurações reproduzíveis podem ser aplicadas independentemente da localização da sua carga de trabalho de computação.
Ferramentas de orquestração
Os contentores também podem ser considerados um elemento essencial da recuperação de desastres. Os contentores são uma forma de agrupar serviços e introduzir consistência nas plataformas.
Se trabalhar com contentores, usa normalmente um orquestrador. O Kubernetes funciona não só para gerir contentores no Google Cloud (através do GKE), mas também oferece uma forma de orquestrar cargas de trabalho baseadas em contentores em várias plataformas. Google Cloud, A AWS e o Microsoft Azure oferecem versões geridas do Kubernetes.
Para distribuir tráfego para clusters do Kubernetes em execução em diferentes plataformas de nuvem, pode usar um serviço DNS que suporte registos ponderados e incorpore a verificação de estado.
Também tem de garantir que consegue transferir a imagem para o ambiente de destino. Isto significa que tem de conseguir aceder ao seu registo de imagens em caso de desastre. Uma boa opção que também é independente da plataforma é o Artifact Registry.
Transferência de dados
A transferência de dados é um componente essencial dos cenários de DR multiplataforma. Certifique-se de que concebe, implementa e testa os seus cenários de DR em várias plataformas usando simulações realistas do que o cenário de transferência de dados de DR exige. Abordamos cenários de transferência de dados na secção seguinte.
Serviço de cópias de segurança e RD
O serviço de cópia de segurança e RD é uma solução de cópia de segurança e RD para cargas de trabalho na nuvem. Ajuda a recuperar dados e retomar a operação empresarial crítica, e suporta vários Google Cloud produtos e bases de dados de terceiros e sistemas de armazenamento de dados.
Para mais informações, consulte a Vista geral do serviço de cópia de segurança e recuperação de desastres.
Padrões para RD
Esta secção aborda alguns dos padrões mais comuns para arquiteturas de recuperação de desastres com base nos blocos de construção abordados anteriormente.
A transferir dados de e para Google Cloud
Um aspeto importante do seu plano de DR é a rapidez com que os dados podem ser transferidos para e a partir do Google Cloud. Isto é fundamental se o seu plano de recuperação de desastres se basear na transferência de dados de local para Google Cloud ou de outro fornecedor de nuvem para Google Cloud. Esta secção aborda as redes e os Google Cloud serviços que podem garantir um bom débito.
Quando usa o Google Cloud como o site de recuperação para cargas de trabalho que estão nas instalações ou noutro ambiente na nuvem, considere os seguintes itens principais:
- Como se liga ao Google Cloud?
- Qual é a largura de banda entre si e o fornecedor de interconexão?
- Qual é a largura de banda fornecida diretamente pelo fornecedor Google Cloud?
- Que outros dados são transferidos através dessa associação?
Para mais informações sobre a transferência de dados para o Google Cloud, consulte o artigo Migrar para o Google Cloud: transfira os seus grandes conjuntos de dados.
Equilibrar a configuração da imagem e a velocidade de implementação
Quando configurar uma imagem de máquina para implementar novas instâncias, considere o efeito que a sua configuração terá na velocidade de implementação. Existe uma compensação entre a quantidade de pré-configuração da imagem, os custos de manutenção da imagem e a velocidade de implementação. Por exemplo, se uma imagem de máquina estiver configurada ao mínimo, as instâncias que a usam demoram mais tempo a iniciar, porque têm de transferir e instalar dependências. Por outro lado, se a imagem da máquina estiver altamente configurada, as instâncias que a usam são iniciadas mais rapidamente, mas tem de atualizar a imagem com mais frequência. O tempo necessário para lançar uma instância totalmente operacional tem uma correlação direta com o seu RTO.
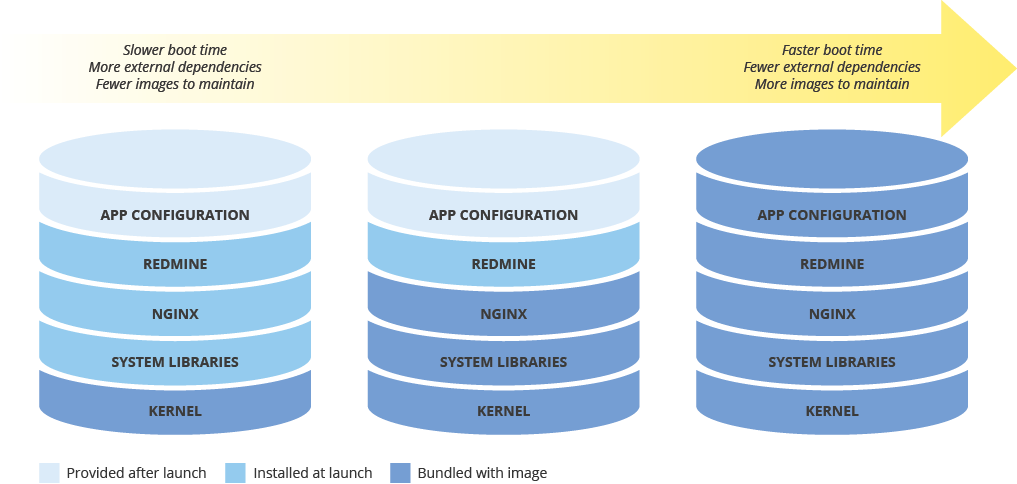
Manter a consistência das imagens da máquina em ambientes híbridos
Se implementar uma solução híbrida (no local para a nuvem ou da nuvem para a nuvem), tem de encontrar uma forma de manter a consistência das imagens nos ambientes de produção.
Se for necessária uma imagem totalmente configurada, considere usar algo como o Packer, que pode criar imagens de máquinas idênticas para várias plataformas. Pode usar os mesmos scripts com ficheiros de configuração específicos da plataforma. No caso do Packer, pode colocar o ficheiro de configuração no controlo de versões para acompanhar a versão implementada na produção.
Em alternativa, pode usar ferramentas de gestão de configuração, como Chef, Puppet, Ansible ou Saltstack, para configurar instâncias com maior detalhe, criando imagens de base, imagens com configuração mínima ou imagens totalmente configuradas, conforme necessário.
Também pode converter e importar manualmente imagens existentes, como AMIs da Amazon, imagens do Virtualbox e imagens de disco RAW, para o Compute Engine.
Implementar armazenamento hierárquico
O padrão de armazenamento hierárquico é normalmente usado para cópias de segurança em que a cópia de segurança mais recente está num armazenamento mais rápido e migra lentamente as cópias de segurança mais antigas para um armazenamento de custo mais baixo (mas lento). Ao aplicar este padrão, migra as cópias de segurança entre contentores de diferentes classes de armazenamento, normalmente de Standard para classes de armazenamento de custo inferior, como Nearline e Coldline.
Para implementar este padrão, pode usar a gestão do ciclo de vida de objetos. Por exemplo, pode alterar automaticamente a classe de armazenamento de objetos com mais de um determinado período para Coldline.
O que se segue?
- Leia mais sobre Google Cloud geografia e regiões.
Leia outros artigos desta série de DR:
- Guia de planeamento de recuperação de desastres
- Cenários de recuperação de desastres para dados
- Cenários de recuperação de desastres para aplicações
- Arquitetar a recuperação de desastres para cargas de trabalho restritas por localidade
- Exemplos de utilização de recuperação de desastres: aplicações de estatísticas de dados restritas à localidade
- Criar arquiteturas de recuperação de desastres para interrupções da infraestrutura na nuvem
Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.
Colaboradores
Autores:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Arquiteto de soluções na nuvem