Sebaiknya Anda mendesain mesh data Anda untuk mendukung berbagai kasus penggunaan pemakaian data. Kasus penggunaan pemakaian data paling umum dalam suatu organisasi akan dijelaskan dalam dokumen ini. Dokumen ini juga membahas tentang data informasi yang harus diperhatikan konsumen ketika menentukan produk data yang tepat bagi kasus penggunaan mereka, dan cara mereka dalam menemukan dan menggunakan produk data. Memahami faktor-faktor ini dapat membantu organisasi memastikan agar memiliki panduan dan solusi yang tepat dan siap untuk mendukung konsumen data.
Dokumen ini adalah bagian dari rangkaian yang menjelaskan cara menerapkan mesh data di Google Cloud. Dokumen ini mengasumsikan bahwa Anda telah membaca dan memahami konsep yang dijelaskan dalam Arsitektur dan fungsi dalam mesh data dan Membangun Mesh Data terdistribusi yang modern dengan Google Cloud.
Seri ini memiliki bagian-bagian sebagai berikut:
- Arsitektur dan fungsi dalam mesh data
- Mendesain platform data layanan mandiri untuk mesh data
- Membuat produk data dalam mesh data
- Menemukan dan memakai produk data dalam suatu mesh data (dokumen ini)
Desain lapisan konsumsi data, khususnya cara konsumen berbasis domain data menggunakan produk data, bergantung pada kebutuhan konsumen data. Sebagai prasyarat, diasumsikan bahwa konsumen sudah memikirkan kasus penggunaan. Diasumsikan bahwa konsumen telah mengidentifikasi data yang dibutuhkan, dan dapat menelusuri katalog produk data pusat untuk menemukannya. Jika data tersebut tidak ada di dalam katalog atau tidak dalam dalam keadaan yang diinginkan (misalnya, jika antarmukanya tidak sesuai, atau memiliki SLA yang tidak mencukupi), maka konsumen harus menghubungi produser data.
Jika tidak demikian, konsumen dapat menghubungi Center of Excellence (COE) untuk mendapatkan saran mengenai domain mana yang paling sesuai untuk menghasilkan produk data tersebut. Konsumen data juga dapat menanyakan cara membuat data permintaan mereka. Jika organisasi Anda besar, harus ada proses untuk membuat permintaan produk data secara layanan mandiri.
Konsumen data menggunakan produk data melalui aplikasi yang mereka jalankan. Jenis data yang diperlukan akan mendorong pilihan desain aplikasi yang memakai data. Saat mengembangkan desian aplikasi, konsumen data juga mengidentifikasi penggunaan produk data pilihan mereka di aplikasi. Konsumen data membangun keyakinan yang harus mereka miliki dalam kepercayaan dan keandalan data tersebut. Kemudian, konsumen data dapat menetapkan tampilan antarmuka produk data dan SLA yang diperlukan oleh aplikasi.
Kasus penggunaan konsumsi data
Untuk keperluan membuat aplikasi data bagi para konsumen data, sumber dapat dapat berupa satu atau beberapa produk data dan bisa jadi, data dari domain konsumen data sendiri. Sebagaimana dijelaskan dalam Mem-build produk data di suatu mesh data, produk data .
Meskipun konsumsi data dapat terjadi dalam domain yang sama, pola konsumsi yang paling lazim adalah pola konsumsi yang mencari produk data yang tepat, terlepas dari domain, sebagai sumber dari aplikasi. Jika produk data yang tepat berada di domain yang lain, pola konsumsi mengharuskan Anda untuk menyiapkan mekanisme berikutnya untuk akses dan pemakaian data di seluruh domain. Konsumsi produk data yang dibuat dalam domain selain domain yang dipakai dibahas dalam Langkah-langkah konsumsi data.
Arsitektur
Diagram berikut menunjukkan contoh skenario ketika konsumen memakai produk data melalui serangkaian antarmuka, meliputi set data dan API yang sudah diberi otorisasi.
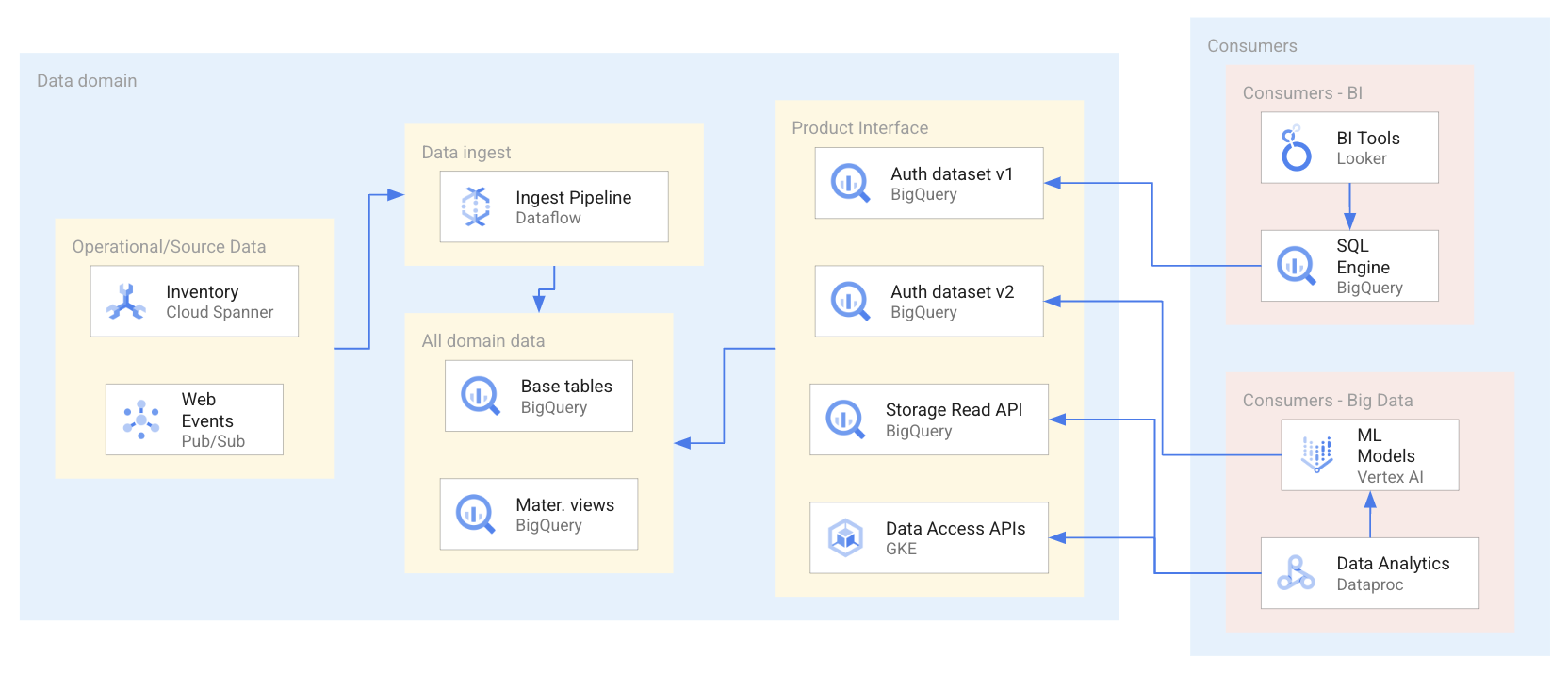
Sebagaimana yang ditunjukkan dalam diagram, produser data telah mengekspos empat antarmuka produk data: dua set data BigQuery yang diberi otorisasi, satu set data BigQuery yang diekspos dengan API baca penyimpanan BigQuery, dan API akses data yang dihostingkan di Google Kubernetes Engine. Dalam menggunakan produk data, konsumen data menggunakan serangkaian aplikasi yang membuat kueri atau mengakses secara langsung resource data di dalam produk data. Dalam skenario ini, konsumen data mengakses resource data menggunakan satu dari dua cara yang berbeda berdasarkan kebutuhan akses data khusus mereka. Dalam cara pertama, Looker menggunakan BigQuery SQL untuk memberi kueri pada set data yang sudah diberi otorisasi. Dalam cara kedua, Dataproc mengakses set data secara langsung melalui BigQuery API lalu memproses data yang diserap tersebut guna melatih model pembelajaran mesin (ML).
Penggunaan aplikasi konsumsi data mungkin terkadang menghasilkan laporan business intelligence (BI) atau dasbor BI. Konsumsi data dari suatu domain juga dapat mengakibatkan model ML yang lebih memperkaya produk analisis, digunakan dalam analisis data, atau merupakan bagian dari proses operasional, misalnya, deteksi penipuan.
Beberapa kasus penggunaan konsumsi produk data yang umum digunakan antara lain sebagai berikut:
- Pelaporan BI dan analisis data: Dalam hal ini, aplikasi data dibuat untuk memakai data dari beberapa produk data. Misalnya, konsumen data dari tim pengelolaan hubungan pelanggan (CRM) membutuhkan akses ke data dari beberapa domain seperti penjualan, pelanggan, dan keuangan. Aplikasi CRM yang dikembangkan melalui konsumen data ini mungkin harus memberi kueri untuk tampilan BigQuery yang diberi otorisasi di salah satu domain, kemudian ekstrak data dari API Read Cloud Storage di domain lainnya. Bagi konsumen data, faktor pengoptimalan yang memengaruhi antarmuka konsumsi pilihan mereka adalah biaya komputasi dan setiap pemrosesan data tambahan yang mengharuskan wajib ada setelah konsumen data membuat kueri produk data. Dalam kasus penggunaan BI dan analisis data, tampilan yang diberi otorisasi oleh BigQuery antara lain kemungkinan menjadi yang paling umum digunakan.
- Kasus penggunaan data science dan pelatihan model: Dalam hal ini, tim yang yang memakai data sedang menggunakan produk data dari domain lain untuk memperkaya produk data analisis mereka sendiri seperti model ML. Dengan menggunakan Google Cloud Serverless for Apache Spark untuk Spark, Google Cloud menyediakan kemampuan prapemrosesan data dan rekayasa fitur untuk memungkinkan pengayaan data sebelum menjalankan tugas ML. Pertimbangan utamanya adalah ketersediaan cukupnya jumlah ketersedian data dengan biaya yang wajar dan keyakinan bahwa data pelatihan merupakan data yang sesuai. Untuk menghemat biaya, antarmuka konsumsi pilihan kemungkinan akan dijadikan dibaca langsung oleh API. Sangat memungkinkan bagi suatu tim pemakai data untuk mem-build model ML sebagai produk data, dan sebagai gantinya, tim pemakai data juga menjadi tim produksi data baru.
- Proses operator: Konsumsi merupakan bagian dari proses operasional dalam domain konsumsi data. Misalnya, seorang konsumen data di suatu tim yang menangani penipuan mungkin menggunakan data transaksi yang berasal dari sumber data operasional di domain penjual. Dengan menggunakan metode integrasi data seperti pengambilan data perubahan, data transaksi ini ditangkap mendekati real time. Kemudian, Anda dapat menggunakan Pub/Sub guna mendefinisikan skema untuk keperluan data dan mengekspos ini sebagai peristiwa. Dalam kasus ini, antarmuka yang sesuai akan diekspos terhadap data sebagai topik Pub/Sub.
Langkah-langkah konsumsi data
Produsen data mendokumentasikan produknya di dalam katalog pusat, meliputi panduan tentang cara memakai data. Untuk suatu organisasi dengan beberapa domain, pendekatan dokumentasi ini membuat suatu arsitektur yang berbeda dari pipeline ELT/ETL tradisional yang dibuat secara terpusat, di tempat pemroses membuat output tanpa batasan dari domain bisnis. Konsumen data di suatu mesh data harus memiliki penemuan dan lapisan konsumsi yang dirancang dengan baik untuk menciptakan siklus proses konsumsi. Lapisan harus mencakup hal berikut:
Langkah 1: Temukan produk data melalui penelusuran deklaratif dan penjelajahan spesifikasi produk data: Konsumen data bebas menelusuri setiap produk data yang telah dicantumkan oleh produsen data di katalog terpusat. Untuk semua produk data, tag produk dalam menentukan cara mengizinkan permintaan akses data dan mode untuk menggunakan data dari antarmuka produk data yang diperlukan. Bidang di tag produk data dapat ditelusuri menggunakan aplikasi penelusuran. Antarmuka produk data menerapkan URI data, yang berarti data tidak perlu dipindahkan ke zona konsumsi terpisah untuk melayani konsumen. Dalam keadaan jika data real-time tidak diperlukan, konsumen dapat membuat kueri produk data dan membuat laporan dengan hasil dengan hasil yang dibuat.
Langkah 2: Menjelajahi data melalui akses data dan pembuatan prototipe interaktif: Konsumen data menggunakan alat interaktif seperti BigQuery Studio dan Jupyter Notebooks untuk menafsirkan dan bereksperimen dengan data guna meningkatkan kualitas kueri yang mereka buat. Kueri interaktif memungkinkan menjelajahi dimensi data yang lebih baru dan meningkatkan ketepatan insight yang dihasilkan dalam skenario produksi.
Langkah 3: Memakai produk data melalui aplikasi dengan akses terprogram dan produksi:
- Laporan BI. Laporan dan dasbor batch maupun mendekati real-time merupakan kelompok kasus penggunaan yang diminta oleh konsumen data . Laporan mungkin memerlukan akses produk lintas data untuk membantu memudahkan pengambilan keputusan. Misalnya, suatu platform data pelanggan memerlukan kueri secara terprogram Baik untuk pesanan maupun produk data CRM secara terjadwal. Hasil dari pendekatan tersebut memberikan pandangan pelanggan yang menyeluruh kepada pengguna bisnis yang memakai data.
- Model AI/ML untuk prediksi batch dan real-time. Data scientists menggunakan prinsip MLOp umum untuk membuat dan melayani model ML yang memakai produk kita yang juga disediakan oleh tim produk kita. Model ML menyediakan kemampuan inferensi real-time untuk kasus penggunaan transaksional misalnya deteksi penipuan. Demikian pula dengan analisis data eksploratif, konsumen data dapat meningkatkan kualitas data sumber. Misalnya, analisis data eksploratif pada data kampanye penjualan dan pemasaran menunjukkan segmen pelanggan demografis di mana penjualan yang diperkirakan menjadi yang paling tinggi dan karenanya kampanye harus berjalan.
Langkah berikutnya
- Lihat penerapan referensi arsitektur mesh data.
- Pelajari lebih lanjut tentang BigQuery.
- Baca selengkapnya tentang Vertex AI.
- Pelajari data science di Dataproc.
- Untuk referensi arsitektur, diagram, dan praktik terbaik lebih lanjut, jelajahi Pusat Arsitektur Cloud.