En una malla de datos, una plataforma de datos de autoservicio permite a los usuarios generar valor a partir de los datos, ya que pueden crear, compartir y usar productos de datos de forma autónoma. Para aprovechar al máximo estas ventajas, te recomendamos que tu plataforma de datos de autoservicio ofrezca las funciones descritas en este documento.
Este documento forma parte de una serie en la que se describe cómo implementar una malla de datos en Google Cloud. Se da por hecho que has leído y conoces los conceptos descritos en Crea una malla de datos moderna y distribuida con Google Cloud y Arquitectura y funciones de una malla de datos.
La serie consta de las siguientes partes:
- Arquitectura y funciones de una malla de datos
- Diseñar una plataforma de datos de autoservicio para una malla de datos (este documento)
- Crear productos de datos en una malla de datos
- Descubrir y consumir productos de datos en una malla de datos
Los equipos de plataformas de datos suelen crear plataformas de datos de autoservicio centrales, tal como se describe en este documento. Este equipo crea las soluciones y los componentes que los equipos de dominio (tanto productores como consumidores de datos) pueden usar para crear y consumir productos de datos. Los equipos de dominio representan partes funcionales de una malla de datos. Al crear estos componentes, el equipo de la plataforma de datos ofrece una experiencia de desarrollo fluida y reduce la complejidad de crear, implementar y mantener productos de datos seguros e interoperables.
En última instancia, el equipo de la plataforma de datos debería permitir que los equipos de dominio avancen más rápido. Ayudan a aumentar la eficiencia de los equipos de dominio proporcionándoles un conjunto limitado de herramientas que satisfagan sus necesidades. Al proporcionar estas herramientas, el equipo de la plataforma de datos libera al equipo del dominio de la carga de tener que crear y obtener estas herramientas por su cuenta. Las opciones de herramientas deben ser personalizables para adaptarse a las diferentes necesidades y no imponer una forma de trabajar inflexible a los equipos del dominio de datos.
El equipo de la plataforma de datos no debería centrarse en crear soluciones personalizadas para orquestadores de flujos de datos ni para sistemas de integración continua y despliegue continuo (CI/CD). Las soluciones como los sistemas de CI/CD están disponibles como servicios en la nube gestionados, como Cloud Build. El uso de servicios en la nube gestionados puede reducir la sobrecarga operativa del equipo de la plataforma de datos y permitirle centrarse en las necesidades específicas de los equipos del dominio de datos como usuarios de la plataforma. Al reducir la sobrecarga operativa, el equipo de la plataforma de datos puede dedicar más tiempo a abordar las necesidades específicas de los equipos del dominio de datos.
Arquitectura
En el siguiente diagrama se muestran los componentes de la arquitectura de una plataforma de datos de autoservicio. El diagrama también muestra cómo pueden ayudar estos componentes a los equipos a medida que desarrollan y consumen productos de datos en la malla de datos.

Como se muestra en el diagrama anterior, la plataforma de datos de autoservicio proporciona lo siguiente:
Soluciones de plataforma: se trata de componentes combinables para aprovisionar Google Cloud proyectos y recursos, que los usuarios seleccionan y ensamblan en diferentes combinaciones para satisfacer sus requisitos específicos. En lugar de interactuar directamente con los componentes, los usuarios de la plataforma pueden interactuar con las soluciones de la plataforma para alcanzar un objetivo específico. Los equipos de dominio de datos deben diseñar soluciones de plataforma para resolver los problemas y las fricciones habituales que provocan retrasos en el desarrollo y el consumo de productos de datos. Por ejemplo, los equipos de dominio de datos que se incorporan a la malla de datos pueden usar una plantilla de infraestructura como código (IaC). Las plantillas de IaC les permiten crear rápidamente un conjunto deGoogle Cloud proyectos con permisos estándar de Gestión de Identidades y Accesos (IAM), redes, políticas de seguridad y APIs relevantes Google Cloudhabilitadas para el desarrollo de productos de datos. Te recomendamos que cada solución vaya acompañada de documentación, como guías para empezar y ejemplos de código. Las soluciones de plataforma de datos y sus componentes deben ser seguros y cumplir las normativas de forma predeterminada.
Servicios comunes: estos servicios proporcionan detección, gestión, uso compartido y observabilidad de productos de datos. Estos servicios fomentan la confianza de los consumidores de datos en los productos de datos y son una forma eficaz de que los productores de datos alerten a los consumidores de datos sobre problemas con sus productos de datos.
Las soluciones de plataforma de datos y los servicios comunes pueden incluir lo siguiente:
- Plantillas de IaC para configurar espacios de trabajo de desarrollo de productos de datos básicos, que incluyen lo siguiente:
- Gestión de identidades y accesos
- Almacenamiento de registros y monitorización
- Redes
- Medidas de protección de seguridad y cumplimiento
- Etiquetado de recursos para la atribución de facturación
- Almacenamiento, transformación y publicación de productos de datos
- Registro, catalogación y etiquetado de metadatos de productos de datos
- Plantillas de IaC que siguen las medidas de protección de seguridad y las prácticas recomendadas de la organización, y que se pueden usar para desplegar recursos en espacios de trabajo de desarrollo de productos de datos. Google Cloud
- Plantillas de aplicaciones y de pipelines de datos que se pueden usar para iniciar nuevos proyectos o como referencia para proyectos ya creados. Estos son algunos ejemplos de plantillas:
- Uso de bibliotecas y frameworks comunes
- Integración con herramientas de registro, monitorización y observabilidad de la plataforma
- Herramientas de compilación y pruebas
- Gestión de la configuración
- Empaquetado y flujos de procesamiento de CI/CD para la implementación
- Autenticación, implementación y gestión de credenciales
- Servicios habituales para proporcionar observabilidad y gobernanza de productos de datos, que pueden incluir lo siguiente:
- Comprobaciones de disponibilidad para mostrar el estado general de los productos de datos.
- Métricas personalizadas para proporcionar indicadores útiles sobre los productos de datos.
- El equipo central ofrece asistencia operativa para que los equipos que consumen datos reciban alertas sobre los cambios en los productos de datos que utilizan.
- Tarjetas de resultados de productos para mostrar el rendimiento de los productos de datos.
- Un catálogo de metadatos para descubrir productos de datos.
- Conjunto de políticas computacionales definidas de forma centralizada que se pueden aplicar de forma global en toda la malla de datos.
- Un mercado de datos para facilitar el intercambio de datos entre los equipos de dominio.
En Crear componentes y soluciones de plataforma con plantillas de IaC se explican las ventajas de las plantillas de IaC para exponer e implementar productos de datos. En Proporcionar servicios comunes se explica por qué es útil proporcionar a los equipos de dominio componentes de infraestructura comunes que haya creado y gestione el equipo de la plataforma de datos.
Crear componentes y soluciones de plataforma con plantillas de IaC
El objetivo de los equipos de plataformas de datos es configurar plataformas de datos de autoservicio para obtener más valor de los datos. Para crear estas plataformas, se crean y se proporcionan plantillas de infraestructura verificadas, seguras y de autoservicio a los equipos de dominio. Los equipos de dominio usan estas plantillas para implementar sus entornos de desarrollo y consumo de datos. Las plantillas de IaC ayudan a los equipos de plataformas de datos a alcanzar ese objetivo y a habilitar la escalabilidad. El uso de plantillas de IaC verificadas y de confianza simplifica el proceso de implementación de recursos para los equipos de dominio, ya que les permite reutilizar las canalizaciones de CI/CD. Este enfoque permite que los equipos de dominio empiecen a trabajar rápidamente y sean productivos en la malla de datos.
Las plantillas de IaC se pueden crear con una herramienta de IaC. Aunque hay varias herramientas de IaC, como Config Connector de Cloud, Pulumi, Chef y Ansible, en este documento se proporcionan ejemplos de herramientas de IaC basadas en Terraform. Terraform es una herramienta de IaC de código abierto que permite al equipo de la plataforma de datos crear de forma eficiente componentes y soluciones de plataforma combinables paraGoogle Cloud recursos. Con Terraform, el equipo de la plataforma de datos escribe código que especifica el estado final elegido y permite que la herramienta determine cómo alcanzar ese estado. Este enfoque declarativo permite al equipo de la plataforma de datos tratar los recursos de infraestructura como artefactos inmutables para implementarlos en diferentes entornos. También ayuda a reducir el riesgo de que se produzcan incoherencias entre los recursos implementados y el código declarado en el control de versiones (lo que se conoce como desfase de configuración). La deriva de la configuración causada por cambios ad hoc y manuales en la infraestructura dificulta la implementación segura y repetible de componentes de IaC en entornos de producción.
Entre las plantillas de IaC habituales para componentes de plataforma combinables se incluye el uso de módulos de Terraform para implementar recursos como un conjunto de datos de BigQuery, un segmento de Cloud Storage o una base de datos de Cloud SQL. Los módulos de Terraform se pueden combinar en soluciones integrales para implementar proyectos completos, incluidos los recursos pertinentes, que se implementan mediante los módulos componibles. Google Cloud Puedes encontrar módulos de Terraform de ejemplo en los planos de Terraform Google Cloud.
De forma predeterminada, cada módulo de Terraform debe cumplir las medidas de protección de seguridad y las políticas de cumplimiento que utilice tu organización. Estas medidas de protección y políticas también se pueden expresar como código y automatizar mediante herramientas de verificación del cumplimiento automatizadas, como la Google Cloud herramienta de validación de políticas.
Tu organización debe probar continuamente los módulos de Terraform proporcionados por la plataforma. Para ello, debe usar las mismas medidas de protección de cumplimiento automatizadas que utiliza para implementar los cambios en el entorno de producción.
Para que los componentes y las soluciones de IaC sean detectables y consumibles para los equipos de dominio que tengan poca experiencia con Terraform, te recomendamos que utilices servicios como Service Catalog. Los usuarios que tengan requisitos de personalización significativos deberían poder crear sus propias soluciones de implementación a partir de las mismas plantillas de Terraform combinables que usan las soluciones actuales.
Cuando uses Terraform, te recomendamos que sigas las Google Cloud prácticas recomendadas que se describen en el artículo Prácticas recomendadas para usar Terraform.
Para ilustrar cómo se puede usar Terraform para crear componentes de la plataforma, en las siguientes secciones se muestran ejemplos de cómo se puede usar Terraform para exponer interfaces de consumo y para consumir un producto de datos.
Exponer una interfaz de consumo
Una interfaz de consumo de un producto de datos es un conjunto de garantías sobre la calidad de los datos y los parámetros operativos que proporciona el equipo del dominio de datos para que otros equipos puedan descubrir y usar sus productos de datos. Cada interfaz de consumo también incluye un modelo de asistencia para productos y documentación de productos. Un producto de datos puede tener diferentes tipos de interfaces de consumo, como APIs o streams, tal como se describe en el artículo Crear productos de datos en una malla de datos. La interfaz de consumo más habitual puede ser un conjunto de datos, una vista o una función autorizados de BigQuery. Esta interfaz expone una tabla virtual de solo lectura, que se expresa como una consulta en la malla de datos. La interfaz no concede permisos de lectura para acceder directamente a los datos subyacentes.
Google proporciona un módulo de Terraform de ejemplo para crear vistas autorizadas
sin conceder permisos a los equipos para acceder a los conjuntos de datos autorizados subyacentes. El siguiente código de este módulo de Terraform concede estos permisos de gestión de identidades y accesos en la vista autorizada dataset_id:
module "add_authorization" {
source = "terraform-google-modules/bigquery/google//modules/authorization"
version = "~> 4.1"
dataset_id = module.dataset.bigquery_dataset.dataset_id
project_id = module.dataset.bigquery_dataset.project
roles = [
{
role = "roles/bigquery.dataEditor"
group_by_email = "ops@mycompany.com"
}
]
authorized_views = [
{
project_id = "view_project"
dataset_id = "view_dataset"
table_id = "view_id"
}
]
authorized_datasets = [
{
project_id = "auth_dataset_project"
dataset_id = "auth_dataset"
}
]
}
Si necesitas conceder acceso a varios usuarios a varias vistas, conceder acceso a cada vista autorizada puede llevar mucho tiempo y ser más difícil de mantener. En lugar de crear varias vistas autorizadas, puede usar un conjunto de datos autorizado para autorizar automáticamente cualquier vista creada en el conjunto de datos autorizado.
Consumir un producto de datos
En la mayoría de los casos prácticos de analíticas, los patrones de consumo se determinan en función de la aplicación en la que se usen los datos. El uso principal de un entorno de consumo proporcionado de forma centralizada es la exploración de datos antes de que se utilicen en la aplicación de consumo. Como se explica en el artículo Descubrir y consumir productos en una malla de datos, SQL es el método más habitual para consultar productos de datos. Por este motivo, la plataforma de datos debe proporcionar a los consumidores de datos una aplicación SQL para explorar los datos.
En función del caso práctico de analíticas, puede usar Terraform para desplegar el entorno de consumo de los consumidores de datos. Por ejemplo, la ciencia de datos es un caso de uso habitual para los consumidores de datos. Puedes usar Terraform para desplegar cuadernos gestionados por el usuario de Vertex AI que se utilizarán como entorno de desarrollo de ciencia de datos. Desde los cuadernos de ciencia de datos, los consumidores de datos pueden usar sus credenciales para iniciar sesión en la malla de datos, explorar los datos a los que tienen acceso y desarrollar modelos de aprendizaje automático basados en estos datos.
Para saber cómo usar Terraform para desplegar y proteger un entorno de cuaderno en Google Cloud, consulta Compilar y desplegar modelos de IA generativa y aprendizaje automático en una empresa.
Proporcionar servicios comunes
Además de los componentes y las soluciones de IaC de autoservicio, el equipo de la plataforma de datos también puede encargarse de crear y operar servicios de plataforma compartidos comunes que utilicen varios equipos de dominio de datos. Algunos ejemplos habituales de servicios de plataforma compartida son el software de terceros autohospedado, como las herramientas de visualización de inteligencia empresarial o un clúster de Kafka. En Google Cloud, el equipo de la plataforma de datos puede gestionar recursos como Dataplex Universal Catalog y los receptores de Cloud Logging en nombre de los equipos de dominio de datos. Gestionar los recursos de los equipos del dominio de datos permite al equipo de la plataforma de datos facilitar la gestión y la auditoría de políticas centralizadas en toda la organización.
En las siguientes secciones se muestra cómo usar Dataplex Universal Catalog para gestionar y gobernar de forma centralizada una malla de datos en Google Cloud, así como para implementar funciones de observabilidad de datos en una malla de datos.
Dataplex Universal Catalog para la gobernanza de datos
Dataplex Universal Catalog proporciona una plataforma de gestión de datos que te ayuda a crear dominios de datos independientes en una malla de datos que abarca toda la organización. Dataplex Universal Catalog te permite mantener controles centrales para gobernar y monitorizar los datos de todos los dominios.
Con Dataplex Universal Catalog, una organización puede organizar de forma lógica sus datos (fuentes de datos admitidas) y los artefactos relacionados, como código, cuadernos y registros, en un lago de Dataplex Universal Catalog que representa un dominio de datos. En el siguiente diagrama, un dominio de ventas usa Dataplex Universal Catalog para organizar sus recursos, incluidas las métricas y los registros de calidad de los datos, en zonas de Dataplex Universal Catalog.
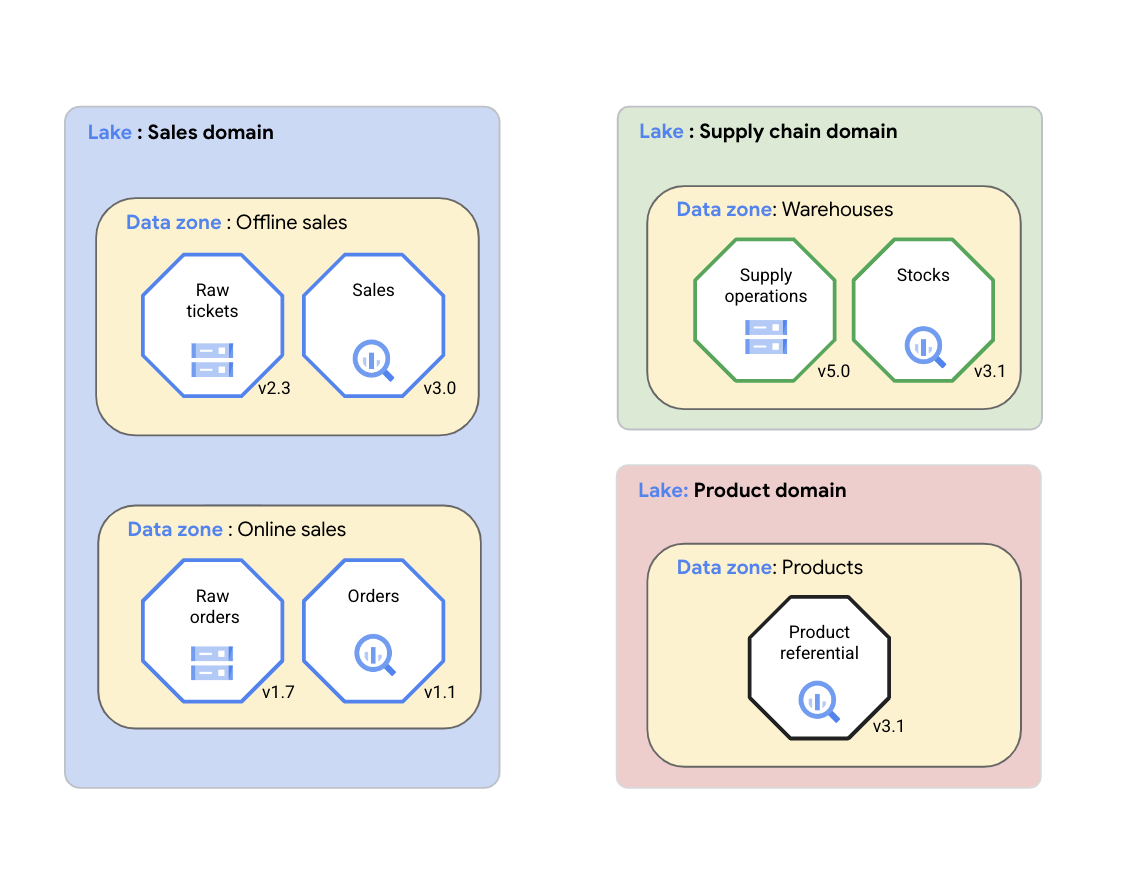
Como se muestra en el diagrama anterior, Dataplex Universal Catalog se puede usar para gestionar los datos de dominio en los siguientes recursos:
- Dataplex Universal Catalog permite a los equipos de dominio de datos gestionar de forma coherente sus recursos de datos en un grupo lógico denominado lago de Dataplex Universal Catalog. El equipo del dominio de datos puede organizar sus recursos de Universal Catalog de Dataplex en el mismo lago de Universal Catalog de Dataplex sin mover los datos físicamente ni almacenarlos en un único sistema de almacenamiento. Los recursos de Dataplex Universal Catalog pueden hacer referencia a los buckets de Cloud Storage y a los conjuntos de datos de BigQuery almacenados en varios Google Cloud proyectos que no sean elGoogle Cloud proyecto que contiene el lago de Dataplex Universal Catalog. Los recursos de Dataplex Universal Catalog pueden ser estructurados o no estructurados, o bien almacenarse en un lago o almacén de datos analíticos. En el diagrama, hay lagos de datos para el dominio de ventas, el dominio de la cadena de suministro y el dominio de productos.
- Las zonas de Dataplex Universal Catalog permiten al equipo del dominio de datos organizar los recursos de datos en subgrupos más pequeños dentro del mismo lago de Dataplex Universal Catalog y añadir estructuras que capturen aspectos clave del subgrupo. Por ejemplo, las zonas de Dataplex Universal Catalog se pueden usar para agrupar recursos de datos asociados en un producto de datos. Agrupar los recursos de datos en una sola zona de Dataplex Universal Catalog permite a los equipos del dominio de datos gestionar las políticas de acceso y las políticas de gobierno de datos de forma coherente en toda la zona como un único producto de datos. En el diagrama, hay zonas de datos para las ventas offline, las ventas online, los almacenes de la cadena de suministro y los productos.
Los lagos y las zonas de Dataplex Universal Catalog permiten a las organizaciones unificar los datos distribuidos y organizarlos en función del contexto empresarial. Esta configuración sienta las bases para actividades como la gestión de metadatos, la configuración de políticas de gobierno y la monitorización de la calidad de los datos. Estas actividades permiten a la organización gestionar sus datos distribuidos a gran escala, como en una malla de datos.
Observabilidad de los datos
Cada dominio de datos debe implementar sus propios mecanismos de monitorización y alertas, preferiblemente con un enfoque estandarizado. Cada dominio puede aplicar las prácticas de monitorización descritas en Conceptos de la monitorización de servicios, haciendo los ajustes necesarios en los dominios de datos. La observabilidad es un tema amplio que no se trata en este documento. En esta sección solo se tratan los patrones que son útiles en las implementaciones de malla de datos.
En el caso de los productos con varios consumidores de datos, proporcionar información oportuna a cada consumidor sobre el estado del producto puede convertirse en una carga operativa. Las soluciones básicas, como las distribuciones de correo gestionadas manualmente, suelen ser propensas a errores. Pueden ser útiles para notificar a los consumidores sobre interrupciones programadas, próximos lanzamientos de productos y retiradas, pero no proporcionan información operativa en tiempo real.
Los servicios centrales pueden desempeñar un papel importante en la monitorización del estado y la calidad de los productos de la malla de datos. Aunque no es un requisito indispensable para implementar correctamente una malla de datos, la implementación de funciones de observabilidad puede mejorar la satisfacción de los productores y consumidores de datos, así como reducir los costes operativos y de asistencia generales. En el siguiente diagrama se muestra una arquitectura de observabilidad de malla de datos basada en Cloud Monitoring.

En las siguientes secciones se describen los componentes que se muestran en el diagrama, que son los siguientes:
- Comprobaciones de tiempo de actividad para mostrar el estado general de los productos de datos.
- Métricas personalizadas para proporcionar indicadores útiles sobre los productos de datos.
- Asistencia operativa del equipo de la plataforma de datos central para alertar a los consumidores de datos sobre los cambios en los productos de datos que utilizan.
- Tarjetas de resultados de productos y paneles de control para mostrar el rendimiento de los productos de datos.
Comprobaciones de disponibilidad del servicio
Los productos de datos pueden crear aplicaciones personalizadas sencillas que implementen comprobaciones de tiempo de actividad. Estas comprobaciones pueden servir como indicadores generales del estado del producto. Por ejemplo, si el equipo de productos de datos detecta una caída repentina en la calidad de los datos de su producto, puede marcarlo como no apto. Las comprobaciones de tiempo de actividad que se realizan casi en tiempo real son especialmente importantes para los consumidores de datos que han derivado productos que dependen de la disponibilidad constante de los datos en el producto de datos upstream. Los productores de datos deben crear sus comprobaciones de tiempo de actividad para incluir la comprobación de sus dependencias upstream, lo que proporciona una imagen precisa del estado de su producto a sus consumidores de datos.
Los consumidores de datos pueden incluir comprobaciones del tiempo de actividad de los productos en su tratamiento. Por ejemplo, un trabajo de compositor que genera un informe basado en los datos proporcionados por un producto de datos puede, como primer paso, validar si el producto está en el estado "running" (en ejecución). Te recomendamos que tu aplicación de comprobación del tiempo de actividad devuelva una carga útil estructurada en el cuerpo del mensaje de su respuesta HTTP. Esta carga útil estructurada debe indicar si hay algún problema, la causa raíz del problema en un formato legible para humanos y, si es posible, el tiempo estimado para restaurar el servicio. Esta carga útil estructurada también puede proporcionar información más detallada sobre el estado del producto. Por ejemplo, puede contener la información sanitaria de cada una de las vistas del conjunto de datos autorizado expuesta como producto.
Métricas personalizadas
Los productos de datos pueden tener varias métricas personalizadas para medir su utilidad. Los equipos de productores de datos pueden publicar estas métricas personalizadas en los proyectos específicos de dominio que hayan designado. Google Cloud Para crear una experiencia de monitorización unificada en todos los productos de datos, se puede dar acceso a esos proyectos específicos de dominio a un proyecto de monitorización de malla de datos central.
Cada tipo de interfaz de consumo de productos de datos tiene métricas diferentes para medir su utilidad. Las métricas también pueden ser específicas del dominio de la empresa. Por ejemplo, las métricas de las tablas de BigQuery expuestas a través de vistas o de la API Storage Read pueden ser las siguientes:
- Número de filas.
- Actualización de datos (expresada como el número de segundos antes de la hora de medición).
- La puntuación de calidad de los datos.
- Los datos que están disponibles. Esta métrica puede indicar que los datos se pueden consultar. Otra opción es usar las comprobaciones de tiempo de actividad que se han mencionado anteriormente en este documento.
Estas métricas se pueden ver como indicadores de nivel de servicio (SLI) de un producto concreto.
En el caso de los flujos de datos (implementados como temas de Pub/Sub), esta lista puede ser la de las métricas estándar de Pub/Sub, que están disponibles a través de los temas.
Asistencia operativa del equipo de la plataforma de datos central
El equipo de la plataforma de datos central puede exponer paneles de control personalizados para mostrar diferentes niveles de detalle a los consumidores de datos. Un panel de control de estado sencillo que muestre los productos de la malla de datos y el estado de tiempo de actividad de esos productos puede ayudar a responder a varias solicitudes de usuarios finales.
El equipo central también puede actuar como centro de distribución de notificaciones para informar a los consumidores de datos sobre varios eventos de los productos de datos que utilizan. Normalmente, este centro se crea mediante políticas de alertas. Centralizar esta función puede reducir el trabajo que debe realizar cada equipo productor de datos. Para crear estas políticas no es necesario tener conocimientos sobre los dominios de datos, y deberían ayudar a evitar los cuellos de botella en el consumo de datos.
El estado final ideal para la monitorización de la malla de datos es que la plantilla de etiqueta de producto de datos exponga los indicadores de nivel de servicio (SLIs) y los objetivos de nivel de servicio (SLOs) que admite el producto cuando esté disponible. El equipo central puede desplegar automáticamente las alertas correspondientes mediante la monitorización de servicios con la API Monitoring.
Tarjetas de resultados de productos
Como parte del acuerdo de gobernanza central, las cuatro funciones de una malla de datos pueden definir los criterios para crear tarjetas de resultados de los productos de datos. Estas tarjetas de resultados pueden convertirse en una medición objetiva del rendimiento de los productos de datos.
Muchas de las variables que se usan para calcular las tarjetas de resultados son el porcentaje de tiempo que los productos de datos cumplen su SLO. Entre los criterios útiles se encuentran el porcentaje de tiempo de actividad, las puntuaciones medias de calidad de los datos y el porcentaje de productos con datos actualizados que no estén por debajo de un umbral. Para calcular estas métricas automáticamente con Prometheus Query Language (PromQL), las métricas personalizadas y los resultados de las comprobaciones de tiempo de actividad del proyecto de monitorización central deberían ser suficientes.
Siguientes pasos
- BigQuery
- Consulta información sobre Dataplex.
- Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.