Questo documento illustra concetti, principi, terminologia e architettura della migrazione dei database con tempi di inattività quasi nulli per gli architetti cloud che eseguono la migrazione dei database da Google Cloud ambienti on-premise o altri cloud.
Questo documento è la prima parte di due. La Parte 2 tratta della configurazione ed esecuzione del processo di migrazione, inclusi gli scenari di errore.
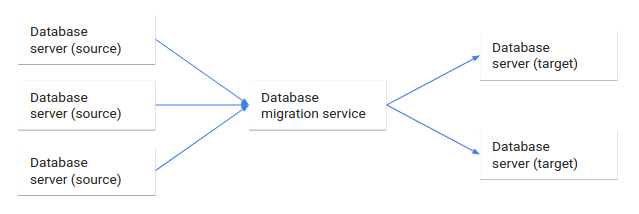
La migrazione del database è il processo di migrazione dei dati da uno o più database di origine a uno o più database di destinazione utilizzando un servizio di migrazione del database. Al termine di una migrazione, il set di dati nei database di origine risiede completamente, anche se eventualmente riorganizzato, nei database di destinazione. I client che hanno eseguito l'accesso ai database di origine vengono poi trasferiti ai database di destinazione e i database di origine vengono disattivati.
Il seguente diagramma illustra questa procedura di migrazione del database.
Questo documento descrive la migrazione del database dal punto di vista dell'architettura:
- I servizi e le tecnologie coinvolti nella migrazione del database.
- Le differenze tra la migrazione di database omogenei ed eterogenei.
- I compromessi e la selezione di una tolleranza al tempo di riposo della migrazione.
- Un'architettura di configurazione che supporta un piano di riserva se si verificano errori imprevisti durante una migrazione.
Questo documento non descrive come configurare una determinata tecnologia di migrazione del database. ma introduce la migrazione del database in termini fondamentali, concettuali e di principio.
Architettura
Il seguente diagramma mostra un'architettura generica di migrazione del database.
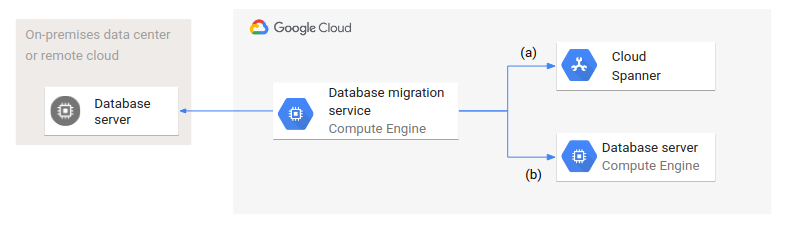
Un servizio di migrazione del database viene eseguito all'interno Google Cloud e accede ai database di origine e di destinazione. Sono rappresentate due varianti: (a) mostra la migrazione da un database di origine in un data center on-premise o in un cloud remoto a un database gestito come Spanner; (b) mostra una migrazione a un database su Compute Engine.
Anche se i database di destinazione sono diversi per tipo (gestiti e non gestiti) e configurazione, l'architettura e la configurazione della migrazione del database sono uguali per entrambi i casi.
Terminologia
I termini più importanti per la migrazione dei dati di questi documenti sono definiti come segue:
database di origine:un database contenente i dati di cui eseguire la migrazione in uno o più database di destinazione.
database di destinazione:un database che riceve i dati di cui è stata eseguita la migrazione da uno o più database di origine.
Migrazione del database:una migrazione dei dati dai database di origine ai database di destinazione con l'obiettivo di disattivare i sistemi di database di origine al termine della migrazione. Viene eseguita la migrazione dell'intero set di dati o di un sottoinsieme.
Migrazione omogenea:una migrazione dai database di origine ai database di destinazione in cui i database di origine e di destinazione appartengono allo stesso sistema di gestione del database dello stesso provider.
Migrazione eterogenea:una migrazione dai database di origine ai database di destinazione in cui i database di origine e di destinazione appartengono a sistemi di gestione dei database diversi di fornitori diversi.
Sistema di migrazione del database:un sistema o un servizio software che si connette ai database di origine e di destinazione ed esegue la migrazione dei dati dai database di origine ai database di destinazione.
Procedura di migrazione dei dati:una procedura configurata o implementata eseguita dal sistema di migrazione dei dati per trasferire i dati dai database di origine a quelli di destinazione, eventualmente trasformandoli durante il trasferimento.
Replica del database:un trasferimento continuo di dati dai database di origine ai database di destinazione senza lo scopo di disattivare i database di origine. La replica del database (a volte chiamata streaming del database) è un processo continuo.
Classificazione delle migrazioni dei database
Esistono diversi tipi di migrazioni del database che appartengono a classi diverse. Questa sezione descrive i criteri che definiscono queste classi.
Differenza tra replica e migrazione
In una migrazione di database, sposti i dati dai database di origine ai database di destinazione. Una volta completata la migrazione dei dati, elimina i database di origine e reindirizza l'accesso dei client ai database di destinazione. A volte è consigliabile conservare i database di origine come misura di riserva se si verificano problemi imprevisti con i database di destinazione. Tuttavia, una volta che i database di destinazione funzionano in modo affidabile, puoi eliminare i database di origine.
Con la replica del database, invece, trasferisci continuamente i dati dai database di origine ai database di destinazione senza eliminarli. A volte la replica del database è indicata come streaming del database. Sebbene sia stata definita un'ora di inizio, in genere non è stata definita un'ora di completamento. La replica potrebbe essere interrotta o diventare una migrazione.
Questo documento illustra solo la migrazione del database.
Migrazione parziale e completa
Per migrazione del database si intende un trasferimento completo e coerente dei dati. Il set di dati iniziale da trasferire viene definito come un database completo o parziale (un sottoinsieme di dati in un database) più ogni modifica committata successivamente nel sistema di database di origine.
Migrazione eterogenea e migrazione omogenea
Una migrazione di database omogenea è una migrazione tra i database di origine e di destinazione della stessa tecnologia di database, ad esempio la migrazione da un database MySQL a un database MySQL o da un database Oracle® a un database Oracle. Le migrazioni omogenee includono anche le migrazioni tra un sistema di database auto-in hosting come PostgreSQL a una versione gestita come Cloud SQL per PostgreSQL o AlloyDB per PostgreSQL.
In una migrazione omogenea del database, gli schemi dei database di origine e di destinazione sono probabilmente identici. Se gli schemi sono diversi, i dati dei database di origine devono essere trasformati durante la migrazione.
La migrazione eterogenea del database è una migrazione tra database di origine e di destinazione di tecnologie di database diverse, ad esempio da un database Oracle a Spanner. La migrazione di database eterogenea può avvenire tra gli stessi modelli di dati (ad esempio da relazionale a relazionale) o tra modelli di dati diversi (ad esempio da relazionale a chiave-valore).
La migrazione tra diverse tecnologie di database non comporta necessariamente modelli di dati diversi. Ad esempio, Oracle, MySQL, PostgreSQL e Spanner supportano tutti il modello di dati relazionale. Tuttavia, i database multimodello come Oracle, MySQL o PostgreSQL supportano diversi modelli di dati. È possibile eseguire la migrazione dei dati archiviati come documenti JSON in un database multimodello a MongoDB con poca o nessuna trasformazione necessaria, poiché il modello di dati è lo stesso nel database di origine e di destinazione.
Sebbene la distinzione tra migrazione omogenea ed eterogenea sia basata sulle tecnologie di database, una classificazione alternativa si basa sui modelli di database coinvolti. Ad esempio, una migrazione da un database Oracle a Spanner è omogenea quando entrambi utilizzano il modello di dati relazionale. Una migrazione è eterogenea se, ad esempio, i dati archiviati come oggetti JSON in Oracle vengono migrati a un modello relazionale in Spanner.
La classificazione delle migrazioni in base al modello di dati esprime in modo più accurato la complessità e lo sforzo necessari per eseguire la migrazione dei dati rispetto alla classificazione in base al sistema di database interessato. Tuttavia, poiché la classificazione comunemente utilizzata nel settore si basa sui sistemi di database coinvolti, le sezioni rimanenti si basano su questa distinzione.
Tempo di inattività della migrazione: zero, minimo o significativo
Dopo aver eseguito correttamente la migrazione di un set di dati dal database di origine al database di destinazione, trasferisci l'accesso client al database di destinazione ed elimina il database di origine.
Il trasferimento dei clienti dai database di origine ai database di destinazione comporta diverse procedure:
- Per continuare l'elaborazione, i client devono chiudere le connessioni esistenti ai database di origine e creare nuove connessioni ai database di destinazione. Idealmente, la chiusura delle connessioni avviene in modo corretto, il che significa che non viene eseguito il rollback delle transazioni in corso inutilmente.
- Dopo aver chiuso le connessioni ai database di origine, devi eseguire la migrazione delle modifiche rimanenti dai database di origine ai database di destinazione (operazione chiamata svuotamento) per assicurarti che tutte le modifiche vengano acquisite.
- Potresti dover testare i database di destinazione per assicurarti che siano funzionali e che i client funzionino e operino entro gli obiettivi del livello di servizio (SLO) definiti.
In una migrazione, è impossibile ottenere un tempo di riposo completamente nullo per i client; a volte i client non possono elaborare le richieste. Tuttavia, puoi ridurre al minimo la durata in cui i client non sono in grado di elaborare le richieste in diversi modi (tempo di riposo quasi nullo):
- Puoi avviare i client di test in modalità di sola lettura per i database di destinazione molto prima di eseguire il passaggio dei client. Con questo approccio, i test vengono eseguiti contemporaneamente alla migrazione.
- Quando si avvicina il periodo di transizione, puoi configurare la quantità di dati di cui viene eseguita la migrazione (ovvero in transito tra i database di origine e di destinazione) in modo che sia il più piccola possibile. Questo passaggio riduce il tempo di svuotamento perché le differenze tra i database di origine e quelli di destinazione sono minori.
- Se i nuovi client che operano sui database di destinazione possono essere avviati contemporaneamente ai client esistenti che operano sui database di origine, puoi ridurre il tempo di transizione nel tempo perché i nuovi client sono pronti per essere eseguiti non appena tutti i dati sono stati trasferiti.
Sebbene non sia realistico ottenere un tempo di riposo nullo durante il passaggio, puoi minimizzare il tempo di riposo avviando le attività contemporaneamente alla migrazione dei dati in corso, se possibile.
In alcuni scenari di migrazione del database, sono accettabili tempi di inattività significativi. In genere, questa tolleranza è il risultato dei requisiti aziendali. In questi casi, puoi semplificare il tuo approccio. Ad esempio, con una migrazione di database omogenea, potresti non dover modificare i dati. L'esportazione e l'importazione o il backup e il ripristino sono approcci perfetti. Con le migrazioni eterogenee, il sistema di migrazione del database non deve gestire gli aggiornamenti dei sistemi di database di origine durante la migrazione.
Tuttavia, devi stabilire che il tempo di inattività accettabile sia sufficiente per la migrazione del database e per i test di follow-up. Se questo tempo di riposo non può essere stabilito con chiarezza o è inaccettabilmente lungo, devi pianificare una migrazione che preveda un tempo di riposo minimo.
Cardinalità della migrazione del database
In molti casi la migrazione del database avviene tra un singolo database di origine e un singolo database di destinazione. In questi casi, la cardinalità è 1:1 (mappatura diretta). In altre parole, viene eseguita la migrazione di un database di origine senza modifiche a un database di destinazione.
Tuttavia, una mappatura diretta non è l'unica possibilità. Altre cardinalità include:
- Raggruppamento (n:1). In un consolidamento, esegui la migrazione dei dati da diversi database di origine a un numero inferiore di database di destinazione (o anche a un solo target). Potresti utilizzare questo approccio per semplificare la gestione del database o impiegare un database di destinazione scalabile.
- Distribuzione (1:n). In una distribuzione, esegui la migrazione dei dati da un database di origine a più database di destinazione. Ad esempio, potresti utilizzare questo approccio quando devi eseguire la migrazione di un grande database centralizzato contenente dati regionali in diversi database di destinazione regionali.
- Ridistribuzione (n:m). In una ridistribuzione, esegui la migrazione dei dati da diversi database di origine a diversi database di destinazione. Potresti utilizzare questo approccio se hai database di origine suddivisi in parti con dimensioni molto diverse. La ridistribuzione distribuisce uniformemente i dati suddivisi in più database di destinazione che rappresentano gli shard.
La migrazione del database offre l'opportunità di riprogettare e implementare l'architettura del database, oltre a eseguire la semplice migrazione dei dati.
Coerenza della migrazione
Si presume che una migrazione del database sia coerente. Nel contesto della migrazione, coerente significa quanto segue:
- Completato. Tutti i dati per i quali è specificata la migrazione vengono effettivamente sottoposti a migrazione. I dati specificati possono essere tutti i dati di un database di origine o un sottoinsieme di dati.
- Senza duplicati. La migrazione di ogni dato viene eseguita una sola volta. Nel database di destinazione non vengono introdotti dati duplicati.
- Ordine effettuato. Le modifiche ai dati nel database di origine vengono applicate al database di destinazione nello stesso ordine in cui sono state apportate nel database di origine. Questo aspetto è essenziale per garantire la coerenza dei dati.
Un modo alternativo per descrivere la coerenza della migrazione è che al termine di una migrazione lo stato dei dati tra i database di origine e di destinazione è equivalente. Ad esempio, in una migrazione omogenea che prevede il mapping diretto di un database relazionale, le stesse tabelle e righe devono esistere nei database di origine e di destinazione.
Questo modo alternativo di descrivere la coerenza della migrazione è importante perché non tutte le migrazioni dei dati si basano sull'applicazione sequenziale delle transazioni nel database di origine al database di destinazione. Ad esempio, puoi eseguire il backup del database di origine e utilizzare il backup per ripristinare i contenuti del database di origine nel database di destinazione (quando è possibile un tempo di riposo significativo).
Migrazione attiva/passiva e migrazione attiva/attiva
Una distinzione importante è se i database di origine e di destinazione sono entrambi disponibili per la modifica dell'elaborazione delle query. In una migrazione di database attivo-passivo, i database di origine possono essere modificati durante la migrazione, mentre i database di destinazione consentono solo l'accesso di sola lettura.
Una migrazione attiva-attiva supporta i client che scrivono sia nel database di origine sia nel database di destinazione durante la migrazione. In questo tipo di migrazione possono verificarsi conflitti. Ad esempio, se lo stesso elemento dati nel database di origine e di destinazione viene modificato in modo da essere in conflitto semanticamente, potrebbe essere necessario eseguire regole di risoluzione dei conflitti per risolvere il problema.
In una migrazione attiva-attiva, devi essere in grado di risolvere tutti i conflitti di dati utilizzando le regole di risoluzione dei conflitti. In caso contrario, potresti riscontrare incoerenze nei dati.
Architettura di migrazione del database
Un'architettura di migrazione del database descrive i vari componenti necessari per eseguire una migrazione del database. Questa sezione introduce un'architettura di deployment generica e tratta il sistema di migrazione del database come un componente separato. Vengono inoltre descritte le funzionalità di un sistema di gestione del database che supportano la migrazione dei dati, nonché le proprietà non funzionali importanti per molti casi d'uso.
Architettura di deployment
Una migrazione del database può avvenire tra database di origine e di destinazione situati in qualsiasi ambiente, ad esempio on-premise o in cloud diversi. Ogni database di origine e di destinazione può trovarsi in un ambiente diverso; non è necessario che tutti siano collocati nello stesso ambiente.
Il seguente diagramma mostra un esempio di architettura di deployment che coinvolge diversi ambienti.
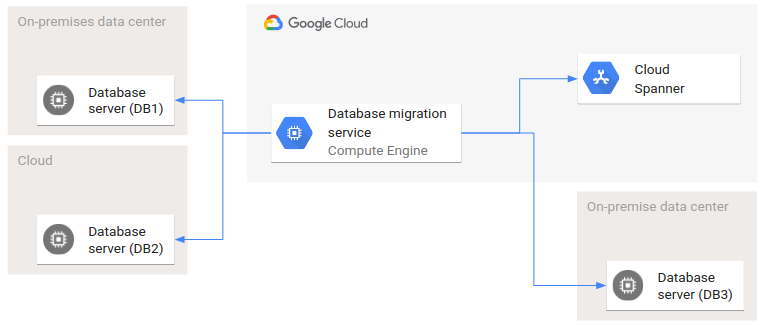
DB1 e DB2 sono due database di origine, mentre DB3 e Spanner sono i database di destinazione. In questa migrazione del database sono coinvolti due cloud e due data center on-premise. Le frecce rappresentano le relazioni di chiamata: il servizio di migrazione del database richiama le interfacce di tutti i database di origine e di destinazione.
Un caso speciale non trattato qui è la migrazione dei dati da un database allo stesso database. Questo caso speciale utilizza il sistema di migrazione del database solo per la trasformazione dei dati, non per la migrazione dei dati tra sistemi diversi in ambienti diversi.
Fondamentalmente, esistono tre approcci alla migrazione del database, che vengono descritti in questa sezione:
- Utilizzo di un sistema di migrazione del database
- Utilizzo della funzionalità di replica del sistema di gestione del database
- Utilizzo della funzionalità di migrazione del database personalizzata
Sistema di migrazione del database
Il sistema di migrazione del database è al centro della migrazione del database. Il sistema esegue l'estrazione effettiva dei dati dai database di origine, trasporta i dati nei database di destinazione e, facoltativamente, li modifica durante il transito. Questa sezione illustra le funzionalità di base del sistema di migrazione del database in generale. Alcuni esempi di sistemi di migrazione del database sono Database Migration Service, Striim, Debezium, tcVision e Cloud Data Fusion.
Processo di migrazione dei dati
Il componente tecnico di base di un sistema di migrazione del database è il processo di migrazione dei dati. Il processo di migrazione dei dati viene specificato da uno sviluppatore e definisce i database di origine da cui vengono estratti i dati, i database di destinazione in cui viene eseguita la migrazione dei dati e qualsiasi logica di modifica dei dati applicata ai dati durante la migrazione.
Puoi specificare una o più procedure di migrazione dei dati ed eseguirle in sequenza o contemporaneamente, a seconda delle esigenze della migrazione. Ad esempio, se esegui la migrazione di database indipendenti, le relative procedure di migrazione dei dati possono essere eseguite in parallelo.
Estrazione e inserimento di dati
Puoi rilevare le modifiche (inserimenti, aggiornamenti ed eliminazioni) in un sistema di database in due modi: tramite Change Data Capture (CDC) supportato dal database in base a un log delle transazioni e tramite query differenziali dei dati stessi utilizzando l'interfaccia di query di un sistema di gestione del database.
CDC basata su un log delle transazioni
La funzionalità CDC supportata dal database si basa su funzionalità di gestione del database separate dall'interfaccia di query. Un approccio si basa sui log delle transazioni (ad esempio il log binario in MySQL). Un log delle transazioni contiene le modifiche apportate ai dati nell'ordine corretto. Il log delle transazioni viene letto continuamente, pertanto è possibile osservare ogni modifica. Per la migrazione del database, questo logging è estremamente utile, in quanto il CDC garantisce che ogni modifica sia visibile e venga successivamente migrata al database di destinazione senza perdita e nell'ordine corretto.
CDC è l'approccio preferito per acquisire le modifiche in un sistema di gestione del database. La tecnologia CDC è integrata nel database stesso e ha l'impatto sul carico più ridotto sul sistema.
Query differenziali
Se non esiste una funzionalità del sistema di gestione del database che supporti l'osservazione di tutte le modifiche nell'ordine corretto, puoi utilizzare le query differenziali come alternativa. In questo approccio, ogni elemento di dati in un database riceve un attributo aggiuntivo contenente un timestamp o un numero di sequenza. Ogni volta che l'elemento di dato viene modificato, viene aggiunto il timestamp della modifica o viene incrementato il numero di sequenza. Un algoritmo di polling legge tutti gli elementi di dati dall'ultima volta che è stato eseguito o dall'ultimo numero di sequenza utilizzato. Una volta che l'algoritmo di polling determina le modifiche, registra l'ora o il numero di sequenza corrente nel suo stato interno e poi le trasmette al database di destinazione.
Sebbene questo approccio funzioni senza problemi per le inserzioni e gli aggiornamenti, devi progettare attentamente le eliminazioni perché un'eliminazione rimuove un elemento di dati dal database. Dopo l'eliminazione dei dati, è impossibile per il poller rilevare che si è verificata un'eliminazione. Implementi un'eliminazione utilizzando un campo di stato aggiuntivo (un flag di eliminazione logica) che indica che i dati sono stati eliminati. In alternativa, gli elementi di dati eliminati possono essere raccolti in una o più tabelle e il poller accede a queste tabelle per determinare se è avvenuta l'eliminazione.
Per le varianti delle query differenziali, consulta Change Data Capture.
Le query differenziali sono l'approccio meno preferito perché comportano modifiche allo schema e alle funzionalità. L'esecuzione di query sul database aggiunge anche un carico di query che non riguarda l'esecuzione della logica del client.
Adattatore e agente
Il sistema di migrazione del database richiede l'accesso all'origine e ai sistemi di database. Gli adattatori sono l'astrazione che incapsula le funzionalità di accesso. Nella forma più semplice, un'opzione può essere un driver JDBC per inserire dati in un database di destinazione che supporta JDBC. In un caso più complesso, un adattatore è in esecuzione nell'ambiente del target (a volte chiamato agente) e accede a un'interfaccia di database integrata come i file di log. In un caso ancora più complesso, un adattatore o un agente si interfaccia con un altro sistema software, che a sua volta accede al database. Ad esempio, un agente accede a Oracle GoldenGate, che a sua volta accede a un database Oracle.
L'adattatore o l'agente che accede a un database di origine implementa l'interfaccia CDC o l'interfaccia di query differenziale, a seconda del design del sistema di database. In entrambi i casi, l'adattatore o l'agente fornisce modifiche al sistema di migrazione del database, che non è a conoscenza se le modifiche sono state acquisite tramite CDC o query differenziali.
Modifica dei dati
In alcuni casi d'uso, i dati vengono migrati dai database di origine ai database di destinazione senza modifiche. Queste migrazioni dirette sono in genere omogenee.
Tuttavia, molti casi d'uso richiedono la modifica dei dati durante il processo di migrazione. In genere, la modifica è necessaria quando esistono differenze nello schema, nei valori dei dati o opportunità di ripulire i dati durante la transizione.
Le sezioni seguenti descrivono diversi tipi di modifiche che possono essere richieste in una migrazione dei dati: trasformazione dei dati, arricchimento o correlazione dei dati e riduzione o filtraggio dei dati.
Trasformazione dei dati
La trasformazione dei dati trasforma alcuni o tutti i valori dei dati del database di origine. Ecco alcuni esempi:
- Trasformazione del tipo di dati. A volte i tipi di dati tra i database di origine e di destinazione non sono equivalenti. In questi casi, la trasformazione del tipo di dato esegue il passaggio del valore di origine al valore target in base alle regole di trasformazione del tipo. Ad esempio, un tipo di timestamp dell'origine potrebbe essere trasformato in una stringa nel target.
- Trasformazione della struttura dei dati. La trasformazione della struttura dei dati modifica la struttura nello stesso modello di database o tra diversi modelli di database. Ad esempio, in un sistema relazionale, una tabella di origine potrebbe essere suddivisa in due tabelle di destinazione oppure più tabelle di origine potrebbero essere denormalizzate in un'unica tabella di destinazione utilizzando un join. Una relazione 1:n nel database di origine potrebbe essere trasformata in una relazione padre-figlio in Spanner. I documenti di un sistema di database di documenti di origine potrebbero essere decomposti in un insieme di righe relazionali in un sistema di destinazione.
- Trasformazione del valore dei dati. La trasformazione del valore dei dati è distinta dalla trasformazione del tipo di dati. La trasformazione del valore dei dati modifica il valore senza modificare il tipo di dati. Ad esempio, un fuso orario locale viene convertito in tempo universale coordinato (UTC). In alternativa, un codice postale breve (cinque cifre) rappresentato come stringa viene convertito in un codice postale lungo (cinque cifre seguite da un trattino seguito da 4 cifre, noto anche come ZIP+4).
Arricchimento e correlazione dei dati
La trasformazione dei dati viene applicata ai dati esistenti senza fare riferimento a dati di riferimento aggiuntivi correlati. Con l'arricchimento dei dati, vengono eseguite query su dati aggiuntivi per arricchire i dati di origine prima che vengano archiviati nel database di destinazione.
- Correlazione dei dati. È possibile correlare i dati di origine. Ad esempio, puoi combinare i dati di due tabelle in due database di origine. In un database di destinazione, ad esempio, puoi associare un cliente a tutti gli ordini aperti, completati e annullati, in cui i dati del cliente e dell'ordine provengono da due diversi database di origine.
- Arricchimento dei dati. L'arricchimento dei dati aggiunge dati di riferimento. Ad esempio, puoi arricchire i record che contengono solo un codice postale aggiungendo il nome della città corrispondente al codice postale. Una tabella di riferimento contenente i codici postali e i nomi delle città corrispondenti è un set di dati statico a cui si accede per questo caso d'uso. Anche i dati di riferimento possono essere dinamici. Ad esempio, potresti utilizzare un elenco di tutti i clienti noti come dati di riferimento.
Riduzione e filtraggio dei dati
Un altro tipo di trasformazione dei dati è la riduzione o il filtraggio dei dati di origine prima della migrazione a un database di destinazione.
- Riduzione dei dati. La riduzione dei dati rimuove gli attributi da un elemento di dato. Ad esempio, se in un elemento dati è presente un codice postale, il nome della città corrispondente potrebbe non essere obbligatorio e viene eliminato perché può essere ricalcolato o perché non è più necessario. A volte queste informazioni vengono conservate per motivi storici per registrare il nome della città inserito dall'utente, anche se il nome della città cambia nel tempo.
- Filtro dei dati. Il filtro dei dati rimuove completamente un elemento di dati. Ad esempio, tutti gli ordini annullati potrebbero essere rimossi e non trasferiti al database di destinazione.
Combinazione o ricostituzione dei dati
Se i dati vengono migrati da diversi database di origine a diversi database di destinazione, può essere necessario combinarli in modo diverso tra i database di origine e di destinazione.
Supponiamo che i clienti e gli ordini siano archiviati in due diversi database di origine. Un database di origine contiene tutti gli ordini e un secondo database di origine contiene tutti i clienti. Dopo la migrazione, i clienti e i relativi ordini vengono archiviati in una relazione 1:n all'interno di un singolo schema di database di destinazione, non in un singolo database di destinazione, ma in diversi database di destinazione, ciascuno contenente una partizione degli stessi. Ogni database di destinazione rappresenta una regione e contiene tutti i clienti e i relativi ordini situati in quella regione.
Indirizzi del database di destinazione
A meno che non sia presente un solo database di destinazione, ogni elemento di dati di cui viene eseguita la migrazione deve essere inviato al database di destinazione corretto. Ecco alcuni approcci per indirizzare il database di destinazione:
- Indirizzi basati su schema. L'indirizzamento basato sullo schema determina il database di destinazione in base allo schema. Ad esempio, tutti gli elementi dati di una raccolta di clienti o tutte le righe di una tabella dei clienti vengono migrati nello stesso database di destinazione che memorizza le informazioni sui clienti, anche se queste informazioni sono state distribuite in più database di origine.
- Routing basato sui contenuti. Il routing basato sui contenuti (ad esempio, tramite un router basato sui contenuti) determina il database di destinazione in base ai valori dei dati. Ad esempio, la migrazione di tutti i clienti che si trovano nella regione dell'America Latina viene eseguita in un database di destinazione specifico che rappresenta questa regione.
Puoi utilizzare entrambi i tipi di indirizzi contemporaneamente in una migrazione del database. Indipendentemente dal tipo di indirizzamento utilizzato, il database di destinazione deve avere lo schema corretto per consentire l'archiviazione degli elementi di dati.
Persistenza dei dati in transito
I sistemi di migrazione del database o gli ambienti su cui vengono eseguiti possono avere un errore durante una migrazione e i dati in transito possono andare persi. In caso di errori, devi riavviare il sistema di migrazione del database e assicurarti che i dati memorizzati nel database di origine vengano migrati in modo coerente e completo ai database di destinazione.
Nell'ambito del recupero, il sistema di migrazione del database deve identificare l'ultimo elemento di dati di cui è stata eseguita la migrazione per determinare da dove iniziare l'estrazione dai database di origine. Per riprendere dal punto di errore, il sistema deve mantenere uno stato interno relativo all'avanzamento della migrazione.
Puoi mantenere lo stato in diversi modi:
- Puoi archiviare tutti gli elementi di dati estratti all'interno del sistema di migrazione del database prima di qualsiasi modifica del database, quindi rimuovere l'elemento di dati una volta che la sua versione modificata è stata archiviata correttamente nel database di destinazione. Questo approccio garantisce che il sistema di migrazione del database possa determinare esattamente cosa viene estratto e archiviato.
- Puoi mantenere un elenco di riferimenti agli elementi di dati in transito. Una possibile soluzione è archiviare le chiavi principali o altri identificatori univoci di ogni elemento di dati insieme a un attributo di stato. Dopo un errore, questo stato costituisce la base per il recupero coerente del sistema.
- Puoi eseguire query sui database di origine e di destinazione dopo un errore per determinare la differenza tra i sistemi di database di origine e di destinazione. L'elemento di dati successivo da estrarre viene determinato in base alla differenza.
Altri approcci per mantenere lo stato possono dipendere dai database di origine specifici. Ad esempio, un sistema di migrazione del database può tenere traccia delle voci del log delle transazioni che vengono recuperate dal database di origine e di quelle inserite nel database di destinazione. In caso di errore, la migrazione può essere riavviata dall'ultima voce inserita correttamente.
La persistenza dei dati in transito è importante anche per altri motivi oltre a errori o guasti. Ad esempio, potrebbe non essere possibile eseguire query sui dati del database di origine per determinarne lo stato. Ad esempio, se il database di origine conteneva una coda, i messaggi al suo interno potrebbero essere stati rimossi a un certo punto.
Un altro caso d'uso per la persistenza dei dati in transito è l'elaborazione con finestre di grandi dimensioni. Durante la modifica dei dati, gli elementi di dati possono essere trasformati indipendentemente l'uno dall'altro. Tuttavia, a volte la modifica dei dati dipende da diversi elementi di dati (ad esempio, la numerazione degli elementi di dati elaborati al giorno, a partire da zero ogni giorno).
Un ultimo caso d'uso per la persistenza dei dati in transito è fornire la ripetibilità degli stessi durante la modifica quando il sistema di database non può accedere nuovamente ai database di origine. Ad esempio, potrebbe essere necessario eseguire nuovamente le modifiche ai dati con regole di modifica diverse, quindi verificare e confrontare i risultati con le modifiche iniziali dei dati. Questo approccio potrebbe essere necessario se devi monitorare eventuali incoerenze nel database di destinazione a causa di una modifica errata dei dati.
Verifica della completezza e della coerenza
Devi verificare che la migrazione del database sia completa e coerente. Questo controllo garantisce che la migrazione di ogni elemento dati venga eseguita una sola volta, che i set di dati nei database di origine e di destinazione siano identici e che la migrazione sia completata.
A seconda delle regole di modifica dei dati, è possibile che un elemento di dati venga estratto, ma non inserito in un database di destinazione. Per questo motivo, il confronto diretto dei database di origine e di destinazione non è un approccio solido per verificare la completezza e la coerenza. Tuttavia, se il sistema di migrazione del database tiene traccia degli elementi filtrati, puoi confrontare i database di origine e di destinazione insieme agli elementi filtrati.
Funzionalità di replica del sistema di gestione del database
Un caso d'uso speciale in una migrazione omogenea si verifica quando il database di destinazione è una copia del database di origine. Nello specifico, gli schemi nei database di origine e di destinazione sono gli stessi, i valori dei dati sono gli stessi e ogni database di origine è una mappatura diretta (1:1) a un database di destinazione.
In questo caso, puoi utilizzare la funzionalità di replica integrata fornita con la maggior parte dei sistemi di gestione dei database per replicare un database in un altro.
Esistono due tipi di replica dei dati: logica e fisica.
Replica logica: nel caso della replica logica, le modifiche agli oggetti del database vengono trasferite in base ai relativi identificatori di replica (in genere chiavi primarie). I vantaggi della replica logica sono che è flessibile, granulare e puoi personalizzarla. In alcuni casi, la replica logica consente di replicare le modifiche tra diverse versioni del motore del database. Molti motori di database supportano i filtri di replica logica, che consentono di definire l'insieme di dati da replicare. I principali svantaggi sono che la replica logica potrebbe introdurvi un sovraccarico delle prestazioni e la latenza di questo metodo di replica è in genere superiore a quella della replica fisica.
Replicazione fisica: al contrario, la replicazione fisica funziona a livello di blocco del disco e offre prestazioni migliori con una latenza di replica inferiore. Per set di dati di grandi dimensioni, la replica fisica può essere più semplice ed efficiente, soprattutto nel caso di strutture di dati non relazionali. Tuttavia, non è personalizzabile e dipende molto dalla versione del motore del database.
Alcuni esempi sono la replica MySQL, la replica PostgreSQL (vedi anche pglogical) o la replica Microsoft SQL Server.
Tuttavia, se è necessaria la modifica dei dati o se hai una cardinalità diversa da una mappatura diretta, sono necessarie le funzionalità di un sistema di migrazione del database per gestire questo caso d'uso.
Funzionalità di migrazione del database personalizzata
Ecco alcuni motivi per cui è consigliabile creare funzionalità di migrazione del database anziché utilizzare un sistema di migrazione del database o un sistema di gestione del database:
- Hai bisogno del controllo totale su ogni dettaglio.
- Vuoi riutilizzare le funzionalità di migrazione del database.
- Vuoi ridurre i costi o semplificare la tua impronta tecnologica.
I componenti di base per creare funzionalità di migrazione sono i seguenti:
- Esportazione e importazione:se il tempo di riposo non è un fattore determinante, puoi utilizzare l'esportazione e l'importazione del database per eseguire la migrazione dei dati in migrazioni di database omogenee. Tuttavia, l'esportazione e l'importazione richiedono di mettere in stato di riposo il database di origine per impedire gli aggiornamenti prima di esportare i dati. In caso contrario, le modifiche potrebbero non essere acquisite nell'esportazione e il database di destinazione non sarà una copia esatta del database di origine.
- Backup e ripristino: come nel caso dell'esportazione e dell'importazione, il backup e il ripristino comportano tempi di riposo perché devi mettere in stato di riposo il database di origine in modo che il backup contenga tutti i dati e le modifiche più recenti. Il tempo di riposo prosegue fino al completamento del ripristino nel database di destinazione.
- Query differenziali:se è possibile modificare lo schema del database, puoi estenderlo in modo da poter eseguire query sulle modifiche del database nell'interfaccia di query. Viene aggiunto un attributo timestamp aggiuntivo che indica la data e l'ora dell'ultima modifica. È possibile aggiungere un altro flag di eliminazione che indica se l'elemento dati è stato eliminato o meno (eliminazione logica). Con queste due modifiche, un poller che viene eseguito a intervalli regolari può eseguire query su tutte le modifiche apportate dall'ultima esecuzione. Le modifiche vengono applicate al database di destinazione. Altri approcci sono descritti in Change Data Capture.
Queste sono solo alcune delle possibili opzioni per creare una migrazione del database personalizzata. Sebbene una soluzione personalizzata offra la massima flessibilità e il massimo controllo sull'implementazione, richiede anche una manutenzione costante per risolvere bug, limitazioni di scalabilità e altri problemi che potrebbero verificarsi durante una migrazione del database.
Considerazioni aggiuntive sulla migrazione del database
Le sezioni seguenti illustrano brevemente gli aspetti non funzionali importanti nel contesto della migrazione del database. Questi aspetti includono gestione degli errori, scalabilità, alta disponibilità e ripristino di emergenza.
Gestione degli errori
Gli errori durante la migrazione del database non devono causare la perdita di dati o l'elaborazione delle modifiche al database fuori sequenza. L'integrità dei dati deve essere preservata indipendentemente dalla causa dell'errore (ad esempio un bug nel sistema, un'interruzione della rete, un arresto anomalo della VM o un errore di zona).
La perdita di dati si verifica quando un sistema di migrazione recupera i dati dai database di origine e non li memorizza nei database di destinazione a causa di un errore. Quando i dati vengono persi, i database di destinazione non corrispondono a quelli di origine e quindi sono incoerenti e incompleti. La funzionalità di verifica della completezza e della coerenza segnala questo stato (Verifica della completezza e della coerenza).
Scalabilità
In una migrazione del database, il tempo di migrazione è una metrica importante. In una migrazione con zero downtime (nel senso di tempi di inattività minimi), la migrazione dei dati avviene mentre i database di origine continuano a cambiare. Per eseguire la migrazione in un periodo di tempo ragionevole, la velocità di trasferimento dei dati deve essere molto più rapida della frequenza degli aggiornamenti dei sistemi di database di origine, soprattutto se il sistema di database di origine è di grandi dimensioni. Maggiore è la velocità di trasferimento, più rapidamente può essere completata la migrazione del database.
Quando i sistemi di database di origine sono in stato di riposo e non vengono modificati, la migrazione potrebbe essere più rapida perché non sono necessarie modifiche. In un databaseomogeneo, il tempo di migrazione potrebbe essere abbastanza rapido perché puoi utilizzare le funzionalità di backup e ripristino o di esportazione e importazione e il trasferimento dei file è scalabile.
Alta disponibilità e ripristino di emergenza
In genere, i database di origine e di destinazione sono configurati per l'alta disponibilità. Un database primario ha una replica di lettura corrispondente che viene promossa a database primario in caso di errore.
Quando una zona non funziona, i database di origine o di destinazione eseguono il failover in un'altra zona per essere disponibili in modo continuo. Se si verifica un errore di zona durante la migrazione di un database, il sistema di migrazione stesso è interessato perché molti dei database di origine o di destinazione a cui accede diventano inaccessibili. Il sistema di migrazione deve ricollegarsi ai database principali appena promossi in esecuzione dopo un errore. Una volta ricollegato, il sistema di migrazione del database deve recuperare la migrazione stessa per garantire la completezza e la coerenza dei dati nei database di destinazione. Il sistema di migrazione deve determinare l'ultimo trasferimento coerente per stabilire da dove riprendere.
Se il sistema di migrazione del database stesso non funziona (ad esempio, la zona in cui viene eseguito diventa inaccessibile), deve essere recuperato. Un approccio di recupero è un riavvio a freddo. In questo approccio, il sistema di migrazione del database viene installato in una zona operativa e riavviato. Il problema più grande da risolvere è che il sistema di migrazione deve essere in grado di determinare l'ultimo trasferimento di dati coerente prima dell'errore e continuare da quel punto per garantire la completezza e la coerenza dei dati nei database di destinazione.
Se il sistema di migrazione del database è abilitato per l'alta disponibilità, può non riuscire e continuare l'elaborazione in un secondo momento. Se è importante che il sistema di migrazione del database abbia un tempo di inattività limitato, devi selezionare un database e implementare l'alta disponibilità.
In termini di recupero della migrazione del database, il ripristino di emergenza è molto simile all'alta disponibilità. Invece di ricollegarsi ai database principali appena promossi in una zona diversa, il sistema di migrazione dei database deve ricollegarsi ai database in una regione diversa (una regione di failover). Lo stesso vale per il sistema di migrazione del database stesso. Se la regione in cui viene eseguito il sistema di migrazione del database diventa inaccessibile, il sistema deve eseguire il failover in un'altra regione e continuare dall'ultimo trasferimento di dati coerente.
Problemi
Diversi problemi possono causare dati incoerenti nei database di destinazione. Ecco alcuni esempi comuni da evitare:
- Violazione dell'ordine. Se la scalabilità del sistema di migrazione viene ottenuta tramite lo scale out, vengono eseguiti contemporaneamente (in parallelo) diversi processi di trasferimento dei dati. Le modifiche in un sistema di database di origine sono ordinate in base alle transazioni committate. Se le modifiche vengono rilevate dal log delle transazioni, l'ordine deve essere mantenuto durante la migrazione. Il trasferimento parallelo dei dati può modificare l'ordine a causa della velocità variabile tra i processi sottostanti. È necessario assicurarsi che i dati vengano inseriti nei database di destinazione nello stesso ordine in cui vengono ricevuti dai database di origine.
- Violazione della coerenza. Con le query differenziali, i database di origine hanno attributi di dati aggiuntivi che contengono, ad esempio, i timestamp dei commit. I database di destinazione non avranno timestamp di commit perché i timestamp di commit vengono implementati solo per stabilire la gestione delle modifiche nei database di origine. È importante assicurarsi che gli inserimenti nei database di destinazione siano coerenti con il timestamp, il che significa che tutte le modifiche con lo stesso timestamp devono trovarsi nella stessa transazione di inserimento, aggiornamento o upsert. In caso contrario, il database di destinazione potrebbe avere uno stato incoerente (temporaneamente) se vengono inserite alcune modifiche e non altre con lo stesso timestamp. Questo stato temporaneo incoerente non è importante se non viene eseguito l'accesso ai database di destinazione per l'elaborazione. Tuttavia, se vengono utilizzati per i test, la coerenza è fondamentale. Un altro aspetto è la creazione dei valori timestamp nel database di origine e il loro rapporto con il momento del commit della transazione in cui sono impostati. A causa delle dipendenze dal commit delle transazioni, una transazione con un timestamp precedente potrebbe diventare visibile dopo una transazione con un timestamp successivo. Se la query differenziale viene eseguita tra le due transazioni, non viene visualizzata la transazione con il timestamp precedente, il che comporta un'incongruenza nel database di destinazione.
- Dati mancanti o duplicati. Quando si verifica un failover, è necessario un recupero attento se alcuni dati non vengono replicati tra l'istanza principale e la replica di failover. Ad esempio, un database di origine esegue il failover e non tutti i dati vengono replicati nella replica di failover. Allo stesso tempo, la migrazione dei dati al database di destinazione è già stata eseguita prima dell'errore. Dopo il failover, il database principale appena promosso è in ritardo in termini di modifiche ai dati nel database di destinazione (chiamato flashback). Un sistema di migrazione deve riconoscere questa situazione e recuperarla in modo che il database di destinazione e quello di origine tornino a uno stato coerente.
- Transazioni locali. Per fare in modo che i database di origine e di destinazione ricevano le stesse modifiche, un approccio comune è fare in modo che i client scrivano in entrambi i database anziché utilizzare un sistema di migrazione dei dati. Questo approccio presenta diversi problemi. Un problema è che due scritture nel database sono due transazioni distinte; potresti riscontrare un errore dopo il completamento della prima e prima del completamento della seconda. Questo scenario causa dati incoerenti da cui devi recuperare. Inoltre, in genere ci sono diversi clienti che non sono coordinati. I client non conoscono l'ordine di commit delle transazioni del database di origine e pertanto non possono scrivere nei database di destinazione che implementano quell'ordine di transazioni. I client potrebbero modificare l'ordine, il che può portare a incoerenze nei dati. A meno che tutto l'accesso non passi attraverso client coordinati e tutti i client garantiscano l'ordine delle transazioni di destinazione, questo approccio può portare a uno stato inconsistente con il database di destinazione.
In generale, ci sono altri pericoli da tenere in considerazione. Il modo migliore per trovare i problemi che potrebbero portare a incoerenze nei dati è eseguire un'analisi completa degli errori che itera in tutti i possibili scenari di errore. Se la concorrenza è implementata nel sistema di migrazione del database, è necessario esaminare tutti i possibili ordini di esecuzione del processo di migrazione dei dati per garantire la coerenza dei dati. Se sono implementati l'alta disponibilità o il ripristino di emergenza (o entrambi), devono essere esaminate tutte le possibili combinazioni di errori.
Passaggi successivi
- Leggi Migrazioni dei database: concetti e principi (Parte 2).
- Scopri di più sulla migrazione del database nei seguenti documenti:
- Consulta la sezione Migrazione del database per altre guide alla migrazione del database.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.