En este documento se presentan los conceptos, los principios, la terminología y la arquitectura de la migración de bases de datos con un tiempo de inactividad casi nulo para los arquitectos de la nube que migran bases de datos a Google Cloud desde entornos on-premise u otras nubes.
Este documento es la primera parte de dos. En la parte 2 se explica cómo configurar y ejecutar el proceso de migración, incluidos los casos de error.
La migración de bases de datos es el proceso de migrar datos de una o varias bases de datos de origen a una o varias bases de datos de destino mediante un servicio de migración de bases de datos. Cuando finaliza una migración, el conjunto de datos de las bases de datos de origen se encuentra por completo (aunque posiblemente reestructurado) en las bases de datos de destino. Los clientes que accedieron a las bases de datos de origen se cambian a las bases de datos de destino y las bases de datos de origen se desactivan.
En el siguiente diagrama se ilustra este proceso de migración de bases de datos.
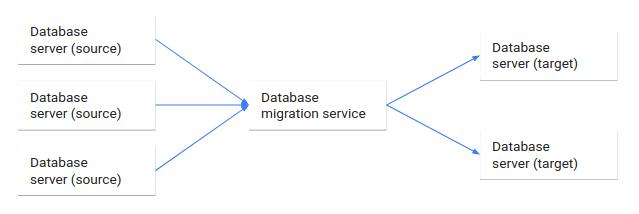
En este documento se describe la migración de bases de datos desde un punto de vista arquitectónico:
- Los servicios y las tecnologías implicados en la migración de bases de datos.
- Las diferencias entre la migración de bases de datos homogénea y heterogénea.
- Las ventajas y desventajas de elegir una tolerancia al tiempo de inactividad de la migración.
- Una arquitectura de configuración que admite una alternativa si se producen errores imprevistos durante una migración.
En este documento no se describe cómo configurar una tecnología de migración de bases de datos concreta. En su lugar, se presenta la migración de bases de datos en términos fundamentales, conceptuales y de principios.
Arquitectura
En el siguiente diagrama se muestra una arquitectura de migración de bases de datos genérica.
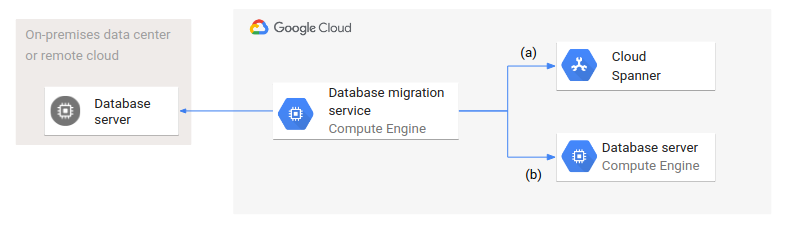
Un servicio de migración de bases de datos se ejecuta en Google Cloud y accede a las bases de datos de origen y de destino. Se representan dos variantes: (a) muestra la migración de una base de datos de origen en un centro de datos local o en una nube remota a una base de datos gestionada, como Spanner; (b) muestra una migración a una base de datos en Compute Engine.
Aunque las bases de datos de destino sean de tipos diferentes (gestionadas y no gestionadas) y tengan configuraciones distintas, la arquitectura y la configuración de la migración de bases de datos son las mismas en ambos casos.
Terminología
A continuación, se definen los términos más importantes sobre migración de datos para estos documentos:
Base de datos de origen: base de datos que contiene los datos que se van a migrar a una o varias bases de datos de destino.
Base de datos de destino: base de datos que recibe los datos migrados de una o varias bases de datos de origen.
Migración de bases de datos: migración de datos de bases de datos de origen a bases de datos de destino con el objetivo de desactivar los sistemas de bases de datos de origen una vez completada la migración. Se migra todo el conjunto de datos o un subconjunto.
Migración homogénea: migración de bases de datos de origen a bases de datos de destino en las que las bases de datos de origen y de destino son del mismo sistema de gestión de bases de datos del mismo proveedor.
Migración heterogénea: migración de bases de datos de origen a bases de datos de destino en la que las bases de datos de origen y de destino son de sistemas de gestión de bases de datos diferentes de distintos proveedores.
Sistema de migración de bases de datos: sistema o servicio de software que se conecta a bases de datos de origen y de destino, y que realiza migraciones de datos de las bases de datos de origen a las de destino.
Proceso de migración de datos: proceso configurado o implementado que ejecuta el sistema de migración de datos para transferir datos de las bases de datos de origen a las de destino, posiblemente transformando los datos durante la transferencia.
Replicación de bases de datos: transferencia continua de datos de bases de datos de origen a bases de datos de destino sin el objetivo de desactivar las bases de datos de origen. La replicación de bases de datos (a veces denominada streaming de bases de datos) es un proceso continuo.
Clasificación de las migraciones de bases de datos
Hay diferentes tipos de migraciones de bases de datos que pertenecen a diferentes clases. En esta sección se describen los criterios que definen esas clases.
Replicación y migración
En una migración de bases de datos, se transfieren datos de bases de datos de origen a bases de datos de destino. Una vez que se hayan migrado todos los datos, elimina las bases de datos de origen y redirige el acceso de los clientes a las bases de datos de destino. A veces, se conservan las bases de datos de origen como medida alternativa si se producen problemas imprevistos con las bases de datos de destino. Sin embargo, una vez que las bases de datos de destino funcionan de forma fiable, puedes eliminar las bases de datos de origen.
Con la réplica de bases de datos, en cambio, transfieres continuamente datos de las bases de datos de origen a las de destino sin eliminar las bases de datos de origen. A veces, la replicación de bases de datos se denomina "streaming de bases de datos". Aunque hay una hora de inicio definida, normalmente no hay una hora de finalización definida. La replicación puede detenerse o convertirse en una migración.
En este documento solo se habla de la migración de bases de datos.
Migración parcial frente a completa
Se entiende que la migración de bases de datos es una transferencia completa y coherente de datos. Usted define el conjunto de datos inicial que se va a transferir como una base de datos completa o parcial (un subconjunto de los datos de una base de datos), además de todos los cambios que se hayan confirmado en el sistema de la base de datos de origen a partir de ese momento.
Migración heterogénea frente a migración homogénea
Una migración de base de datos homogénea es una migración entre las bases de datos de origen y de destino de la misma tecnología de base de datos. Por ejemplo, migrar de una base de datos MySQL a otra base de datos MySQL, o de una base de datos Oracle® a otra base de datos Oracle. Las migraciones homogéneas también incluyen migraciones entre un sistema de bases de datos autogestionado, como PostgreSQL, y una versión gestionada del mismo, como Cloud SQL para PostgreSQL o AlloyDB para PostgreSQL.
En una migración de base de datos homogénea, es probable que los esquemas de las bases de datos de origen y de destino sean idénticos. Si los esquemas son diferentes, los datos de las bases de datos de origen deben transformarse durante la migración.
La migración de bases de datos heterogénea es una migración entre bases de datos de origen y de destino con tecnologías de bases de datos diferentes, por ejemplo, de una base de datos de Oracle a Spanner. La migración de bases de datos heterogéneas puede realizarse entre modelos de datos iguales (por ejemplo, de relacional a relacional) o entre modelos de datos diferentes (por ejemplo, de relacional a clave-valor).
Migrar de una tecnología de base de datos a otra no implica necesariamente cambiar de modelo de datos. Por ejemplo, Oracle, MySQL, PostgreSQL y Spanner admiten el modelo de datos relacional. Sin embargo, las bases de datos multimodo, como Oracle, MySQL o PostgreSQL, admiten diferentes modelos de datos. Los datos almacenados como documentos JSON en una base de datos multimodo se pueden migrar a MongoDB con poca o ninguna transformación, ya que el modelo de datos es el mismo en la base de datos de origen y en la de destino.
Aunque la distinción entre migración homogénea y heterogénea se basa en las tecnologías de bases de datos, también se puede clasificar según los modelos de bases de datos implicados. Por ejemplo, una migración de una base de datos de Oracle a Spanner es homogénea cuando ambas usan el modelo de datos relacional. Una migración es heterogénea si, por ejemplo, los datos almacenados como objetos JSON en Oracle se migran a un modelo relacional en Spanner.
Clasificar las migraciones por modelo de datos expresa con mayor precisión la complejidad y el esfuerzo necesarios para migrar los datos que basar la clasificación en el sistema de base de datos implicado. Sin embargo, como la categorización que se usa habitualmente en el sector se basa en los sistemas de bases de datos implicados, las secciones restantes se basan en esa distinción.
Tiempo de inactividad de la migración: nulo, mínimo o significativo
Una vez que hayas migrado correctamente un conjunto de datos de la base de datos de origen a la de destino, cambia el acceso de cliente a la base de datos de destino y elimina la base de datos de origen.
Para cambiar los clientes de las bases de datos de origen a las de destino, se deben llevar a cabo varios procesos:
- Para seguir procesando datos, los clientes deben cerrar las conexiones a las bases de datos de origen y crear nuevas conexiones a las bases de datos de destino. Lo ideal es que las conexiones se cierren correctamente, lo que significa que no se deshagan innecesariamente las transacciones en curso.
- Después de cerrar las conexiones en las bases de datos de origen, debe migrar los cambios restantes de las bases de datos de origen a las de destino (lo que se denomina vaciado) para asegurarse de que se registran todos los cambios.
- Es posible que tengas que probar las bases de datos de destino para asegurarte de que funcionan correctamente y de que los clientes también funcionan y operan dentro de los objetivos de nivel de servicio (SLOs) definidos.
En una migración, es imposible conseguir un tiempo de inactividad realmente nulo para los clientes, ya que hay momentos en los que los clientes no pueden procesar solicitudes. Sin embargo, puedes minimizar el tiempo durante el que los clientes no pueden procesar solicitudes de varias formas (tiempo de inactividad casi nulo):
- Puedes iniciar tus clientes de prueba en modo de solo lectura en las bases de datos de destino mucho antes de cambiar los clientes. Con este enfoque, las pruebas se realizan al mismo tiempo que la migración.
- Puede configurar la cantidad de datos que se migran (es decir, los datos en tránsito entre las bases de datos de origen y de destino) para que sea lo más pequeña posible cuando se acerque el periodo de cambio. Este paso reduce el tiempo de drenaje, ya que hay menos diferencias entre las bases de datos de origen y las de destino.
- Si se pueden iniciar nuevos clientes que operen en las bases de datos de destino simultáneamente con los clientes que operen en las bases de datos de origen, puedes acortar el tiempo de cambio porque los nuevos clientes estarán listos para ejecutarse en cuanto se hayan transferido todos los datos.
Aunque es poco realista conseguir un tiempo de inactividad cero durante un cambio, puedes minimizarlo iniciando las actividades simultáneamente con la migración de datos en curso cuando sea posible.
En algunos casos de migración de bases de datos, se puede aceptar un tiempo de inactividad considerable. Normalmente, esta asignación se debe a requisitos empresariales. En estos casos, puedes simplificar tu estrategia. Por ejemplo, en una migración de base de datos homogénea, puede que no necesites modificar los datos. En ese caso, la exportación e importación o la copia de seguridad y restauración son las opciones más adecuadas. En las migraciones heterogéneas, el sistema de migración de bases de datos no tiene que gestionar las actualizaciones de los sistemas de bases de datos de origen durante la migración.
Sin embargo, debes asegurarte de que el tiempo de inactividad aceptable sea lo suficientemente largo para que se produzca la migración de la base de datos y las pruebas posteriores. Si no se puede determinar claramente el tiempo de inactividad o es demasiado largo, debes planificar una migración que implique un tiempo de inactividad mínimo.
Cardinalidad de la migración de bases de datos
En muchos casos, la migración de bases de datos se lleva a cabo entre una única base de datos de origen y una única base de datos de destino. En estos casos, la cardinalidad es 1:1 (asignación directa). Es decir, una base de datos de origen se migra a una base de datos de destino sin cambios.
Sin embargo, la asignación directa no es la única posibilidad. Otras cardinalidades son las siguientes:
- Consolidación (n:1). En una consolidación, migras datos de varias bases de datos de origen a un número menor de bases de datos de destino (o incluso a una sola). Puedes usar este enfoque para simplificar la gestión de bases de datos o emplear una base de datos de destino que se pueda escalar.
- Distribución (1:n). En una distribución, migras datos de una base de datos de origen a varias bases de datos de destino. Por ejemplo, puede usar este método cuando necesite migrar una base de datos centralizada de gran tamaño que contenga datos regionales a varias bases de datos de destino regionales.
- Redistribución (n:m). En una redistribución, migras datos de varias bases de datos de origen a varias bases de datos de destino. Puedes usar este método cuando tengas bases de datos de origen fragmentadas con fragmentos de tamaños muy diferentes. La redistribución distribuye de forma uniforme los datos fragmentados en varias bases de datos de destino que representan los fragmentos.
La migración de bases de datos te ofrece la oportunidad de rediseñar e implementar la arquitectura de tu base de datos, además de migrar los datos.
Coherencia de la migración
Lo habitual es que la migración de una base de datos sea coherente. En el contexto de la migración, coherente significa lo siguiente:
- Completado. Todos los datos que se especifiquen para migrarse se migrarán. Los datos especificados pueden ser todos los datos de una base de datos de origen o un subconjunto de los datos.
- Duplicar gratis. Cada dato se migra una vez, y solo una vez. No se introducen datos duplicados en la base de datos de destino.
- Pedido. Los cambios en los datos de la base de datos de origen se aplican a la base de datos de destino en el mismo orden en que se produjeron en la base de datos de origen. Este aspecto es esencial para asegurar la coherencia de los datos.
Otra forma de describir la coherencia de la migración es que, una vez completada, el estado de los datos de las bases de datos de origen y de destino es equivalente. Por ejemplo, en una migración homogénea que implique la asignación directa de una base de datos relacional, deben existir las mismas tablas y filas en las bases de datos de origen y de destino.
Esta forma alternativa de describir la coherencia de la migración es importante porque no todas las migraciones de datos se basan en la aplicación secuencial de transacciones en la base de datos de origen a la base de datos de destino. Por ejemplo, puedes crear una copia de seguridad de la base de datos de origen y usarla para restaurar el contenido de la base de datos de origen en la base de datos de destino (cuando sea posible un tiempo de inactividad significativo).
Migración activa-pasiva frente a activa-activa
Una distinción importante es si las bases de datos de origen y de destino están abiertas a la modificación del procesamiento de consultas. En una migración de base de datos activa-pasiva, las bases de datos de origen se pueden modificar durante la migración, mientras que las bases de datos de destino solo permiten el acceso de solo lectura.
Una migración activa-activa permite que los clientes escriban en las bases de datos de origen y de destino durante la migración. En este tipo de migración, pueden producirse conflictos. Por ejemplo, si se modifica el mismo elemento de datos en la base de datos de origen y en la de destino de forma que entren en conflicto semánticamente, es posible que tengas que ejecutar reglas de resolución de conflictos para resolverlo.
En una migración activo-activo, debes poder resolver todos los conflictos de datos mediante reglas de resolución de conflictos. Si no puede hacerlo, es posible que los datos no sean coherentes.
Arquitectura de migración de bases de datos
Una arquitectura de migración de bases de datos describe los distintos componentes necesarios para ejecutar una migración de bases de datos. En esta sección se presenta una arquitectura de implementación genérica y se trata el sistema de migración de bases de datos como un componente independiente. También se analizan las funciones de un sistema de gestión de bases de datos que admiten la migración de datos, así como las propiedades no funcionales que son importantes en muchos casos prácticos.
Arquitectura de despliegue
Una migración de base de datos puede producirse entre bases de datos de origen y de destino ubicadas en cualquier entorno, como on-premise o en diferentes nubes. Cada base de datos de origen y de destino puede estar en un entorno diferente. No es necesario que todas estén en el mismo entorno.
En el siguiente diagrama se muestra un ejemplo de una arquitectura de implementación que incluye varios entornos.
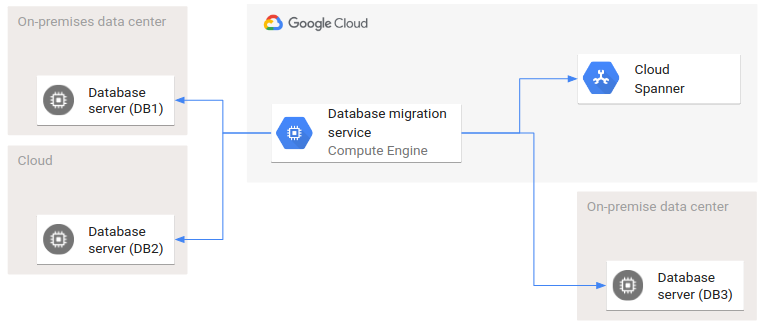
DB1 y DB2 son dos bases de datos de origen, y DB3 y Spanner son las bases de datos de destino. En esta migración de bases de datos, se utilizan dos nubes y dos centros de datos on-premise. Las flechas representan las relaciones de invocación: el servicio de migración de bases de datos invoca interfaces de todas las bases de datos de origen y destino.
Un caso especial que no se trata en este artículo es la migración de datos de una base de datos a la misma base de datos. En este caso especial, se usa el sistema de migración de bases de datos solo para transformar datos, no para migrar datos entre diferentes sistemas en distintos entornos.
Básicamente, hay tres enfoques para migrar bases de datos, que se describen en esta sección:
- Usar un sistema de migración de bases de datos
- Usar la función de replicación del sistema de gestión de bases de datos
- Usar la función de migración de bases de datos personalizada
Sistema de migración de bases de datos
El sistema de migración de bases de datos es el elemento principal de la migración de bases de datos. El sistema ejecuta la extracción de datos real de las bases de datos de origen, transporta los datos a las bases de datos de destino y, opcionalmente, modifica los datos durante el tránsito. En esta sección se describen las funciones básicas del sistema de migración de bases de datos en general. Entre los sistemas de migración de bases de datos se incluyen los siguientes: Database Migration Service, Striim, Debezium, tcVision y Cloud Data Fusion.
Proceso de migración de datos
El componente técnico fundamental de un sistema de migración de bases de datos es el proceso de migración de datos. El proceso de migración de datos lo especifica un desarrollador y define las bases de datos de origen de las que se extraen los datos, las bases de datos de destino a las que se migran los datos y cualquier lógica de modificación de datos que se aplique a los datos durante la migración.
Puede especificar uno o varios procesos de migración de datos y ejecutarlos de forma secuencial o simultánea en función de las necesidades de la migración. Por ejemplo, si migras bases de datos independientes, los procesos de migración de datos correspondientes se pueden ejecutar en paralelo.
Extracción e inserción de datos
Puedes detectar cambios (inserciones, actualizaciones y eliminaciones) en un sistema de base de datos de dos formas: mediante la captura de datos de cambios (CDC) compatible con la base de datos, basada en un registro de transacciones, y mediante consultas diferenciales de los datos en sí con la interfaz de consulta de un sistema de gestión de bases de datos.
CDC basado en un registro de transacciones
La CDC compatible con bases de datos se basa en funciones de gestión de bases de datos que son independientes de la interfaz de consulta. Un enfoque se basa en los registros de transacciones (por ejemplo, el registro binario de MySQL). Un registro de transacciones contiene los cambios realizados en los datos en el orden correcto. El registro de transacciones se lee continuamente, por lo que se puede observar cada cambio. En el caso de la migración de bases de datos, este registro es extremadamente útil, ya que CDC asegura que cada cambio sea visible y se migre posteriormente a la base de datos de destino sin pérdida y en el orden correcto.
La CDC es el método preferido para capturar los cambios en un sistema de gestión de bases de datos. La CDC está integrada en la propia base de datos y es la que menos carga tiene en el sistema.
Consultas diferenciales
Si no existe ninguna función del sistema de gestión de bases de datos que admita la observación de todos los cambios en el orden correcto, puedes usar las consultas diferenciales como alternativa. En este enfoque, cada elemento de datos de una base de datos recibe un atributo adicional que contiene una marca de tiempo o un número de secuencia. Cada vez que se cambia el elemento de datos, se añade la marca de tiempo del cambio o se incrementa el número de secuencia. Un algoritmo de sondeo lee todos los elementos de datos desde la última vez que se ejecutó o desde el último número de secuencia que usó. Una vez que el algoritmo de sondeo determina los cambios, registra la hora actual o el número de secuencia en su estado interno y, a continuación, transfiere los cambios a la base de datos de destino.
Aunque este enfoque funciona sin problemas para las inserciones y las actualizaciones, debes diseñar las eliminaciones con cuidado, ya que eliminan un elemento de datos de la base de datos. Una vez que se eliminan los datos, el poller no puede detectar que se ha producido una eliminación. Para implementar una eliminación, se usa un campo de estado adicional (una marca de eliminación lógica) que indica que los datos se han eliminado. También se pueden recoger los elementos de datos eliminados en una o varias tablas, y el poller accede a esas tablas para determinar si se ha producido la eliminación.
Para ver las variantes de las consultas diferenciales, consulta Captura de datos de cambios.
Las consultas diferenciales son el método menos recomendable porque implican cambios en el esquema y en las funciones. Al consultar la base de datos, también se añade una carga de consulta que no está relacionada con la ejecución de la lógica del cliente.
Adaptador y agente
El sistema de migración de bases de datos requiere acceso a la fuente y a los sistemas de bases de datos. Los adaptadores son la abstracción que encapsula las capacidades de acceso. En su forma más sencilla, un adaptador puede ser un controlador JDBC para insertar datos en una base de datos de destino que admita JDBC. En un caso más complejo, un adaptador se ejecuta en el entorno de destino (a veces denominado agente) y accede a una interfaz de base de datos integrada, como los archivos de registro. En un caso aún más complejo, un adaptador o un agente interactúa con otro sistema de software, que a su vez accede a la base de datos. Por ejemplo, un agente accede a Oracle GoldenGate, que a su vez accede a una base de datos de Oracle.
El adaptador o el agente que accede a una base de datos de origen implementa la interfaz de CDC o la interfaz de consulta diferencial, en función del diseño del sistema de base de datos. En ambos casos, el adaptador o el agente proporciona cambios al sistema de migración de bases de datos, y el sistema de migración de bases de datos no sabe si los cambios se han capturado mediante CDC o consultas diferenciales.
Modificación de datos
En algunos casos prácticos, los datos se migran de las bases de datos de origen a las de destino sin modificar. Estas migraciones directas suelen ser homogéneas.
Sin embargo, en muchos casos prácticos es necesario modificar los datos durante el proceso de migración. Normalmente, es necesario hacer modificaciones cuando hay diferencias en el esquema o en los valores de los datos, o bien cuando se puede limpiar la información mientras está en transición.
En las siguientes secciones se describen varios tipos de modificaciones que pueden ser necesarias en una migración de datos: transformación, enriquecimiento o correlación de datos, y reducción o filtrado de datos.
Transformación de datos
La transformación de datos transforma algunos o todos los valores de datos de la base de datos de origen. Estos son algunos ejemplos:
- Transformación de tipos de datos. A veces, los tipos de datos de las bases de datos de origen y de destino no son equivalentes. En estos casos, la transformación del tipo de datos convierte el valor de origen en el valor de destino según las reglas de transformación de tipos. Por ejemplo, un tipo de marca de tiempo de la fuente se puede transformar en una cadena en el destino.
- Transformación de la estructura de datos. La transformación de la estructura de datos modifica la estructura en el mismo modelo de base de datos o entre diferentes modelos de base de datos. Por ejemplo, en un sistema relacional, una tabla de origen se puede dividir en dos tablas de destino, o bien se pueden desnormalizar varias tablas de origen en una tabla de destino mediante una combinación. Una relación de 1 a n en la base de datos de origen se puede transformar en una relación de padre a hijo en Spanner. Los documentos de un sistema de base de datos de documentos de origen se pueden descomponer en un conjunto de filas relacionales en un sistema de destino.
- Transformación del valor de los datos. La transformación de valores de datos es independiente de la transformación de tipos de datos. La transformación de valores de datos cambia el valor sin cambiar el tipo de datos. Por ejemplo, una zona horaria local se convierte a la hora universal coordinada (UTC). También se puede convertir un código postal corto (cinco dígitos) representado como una cadena en un código postal largo (cinco dígitos seguidos de un guion y cuatro dígitos, también conocido como ZIP+4).
Enriquecimiento y correlación de datos
La transformación de datos se aplica a los datos existentes sin hacer referencia a datos de referencia adicionales relacionados. Con el enriquecimiento de datos, se consultan datos adicionales para enriquecer los datos de origen antes de almacenarlos en la base de datos de destino.
- Correlación de datos. Es posible correlacionar datos de origen. Por ejemplo, puedes combinar datos de dos tablas de dos bases de datos de origen. Por ejemplo, en una base de datos de destino, puede relacionar un cliente con todos los pedidos abiertos, completados y cancelados, de forma que los datos del cliente y los datos del pedido procedan de dos bases de datos de origen diferentes.
- Enriquecimiento de datos. El enriquecimiento de datos añade datos de referencia. Por ejemplo, puede enriquecer registros que solo contengan un código postal añadiendo el nombre de la ciudad correspondiente. Una tabla de referencia que contiene códigos postales y los nombres de las ciudades correspondientes es un conjunto de datos estático al que se accede para este caso práctico. Los datos de referencia también pueden ser dinámicos. Por ejemplo, puedes usar una lista de todos los clientes conocidos como datos de referencia.
Reducción y filtrado de datos
Otro tipo de transformación de datos es reducir o filtrar los datos de origen antes de migrarlos a una base de datos de destino.
- Reducción de datos. La reducción de datos elimina atributos de un elemento de datos. Por ejemplo, si un elemento de datos incluye un código postal, es posible que no se necesite el nombre de la ciudad correspondiente y se elimine, ya que se puede volver a calcular o porque ya no es necesario. A veces, esta información se conserva por motivos históricos para registrar el nombre de la ciudad tal como lo ha introducido el usuario, aunque el nombre de la ciudad cambie con el tiempo.
- Filtrado de datos. Filtrar datos elimina un elemento de datos por completo. Por ejemplo, es posible que se eliminen todos los pedidos cancelados y no se transfieran a la base de datos de destino.
Combinación o recombinación de datos
Si los datos se migran de diferentes bases de datos de origen a diferentes bases de datos de destino, puede ser necesario combinar los datos de forma diferente entre las bases de datos de origen y de destino.
Supongamos que los clientes y los pedidos se almacenan en dos bases de datos de origen diferentes. Una base de datos de origen contiene todos los pedidos y otra base de datos de origen contiene todos los clientes. Después de la migración, los clientes y sus pedidos se almacenan en una relación de 1:n en un único esquema de base de datos de destino. Sin embargo, no se almacenan en una única base de datos de destino, sino en varias bases de datos de destino, cada una de las cuales contiene una partición de los datos. Cada base de datos de destino representa una región y contiene todos los clientes y sus pedidos ubicados en esa región.
Direccionamiento de la base de datos de destino
A menos que solo haya una base de datos de destino, cada elemento de datos que se migre debe enviarse a la base de datos de destino correcta. Estas son algunas de las formas de abordar la base de datos de destino:
- Direccionamiento basado en esquemas. La dirección basada en el esquema determina la base de datos de destino en función del esquema. Por ejemplo, todos los elementos de datos de una colección de clientes o todas las filas de una tabla de clientes se migran a la misma base de datos de destino que almacena información de clientes, aunque esta información se haya distribuido en varias bases de datos de origen.
- Enrutamiento basado en el contenido. El enrutamiento basado en el contenido (por ejemplo, mediante un enrutador basado en el contenido) determina la base de datos de destino en función de los valores de los datos. Por ejemplo, todos los clientes ubicados en la región de Latinoamérica se migran a una base de datos de destino específica que representa esa región.
Puedes usar ambos tipos de direccionamiento al mismo tiempo en una migración de base de datos. Independientemente del tipo de direccionamiento que se utilice, la base de datos de destino debe tener el esquema correcto para que se almacenen los elementos de datos.
Persistencia de los datos en tránsito
Los sistemas de migración de bases de datos o los entornos en los que se ejecutan pueden fallar durante una migración y los datos en tránsito pueden perderse. Cuando se produzcan errores, debes reiniciar el sistema de migración de bases de datos y asegurarte de que los datos almacenados en la base de datos de origen se migren de forma coherente y completa a las bases de datos de destino.
Como parte de la recuperación, el sistema de migración de bases de datos debe identificar el último elemento de datos migrado correctamente para determinar desde dónde debe empezar a extraer datos de las bases de datos de origen. Para reanudar el proceso en el punto en el que se produjo el error, el sistema debe mantener un estado interno del progreso de la migración.
Puedes mantener el estado de varias formas:
- Puedes almacenar todos los elementos de datos extraídos en el sistema de migración de bases de datos antes de modificar cualquier base de datos y, a continuación, eliminar el elemento de datos una vez que su versión modificada se haya almacenado correctamente en la base de datos de destino. De esta forma, el sistema de migración de bases de datos puede determinar exactamente qué se extrae y se almacena.
- Puedes mantener una lista de referencias a los elementos de datos en tránsito. Una posibilidad es almacenar las claves principales u otros identificadores únicos de cada elemento de datos junto con un atributo de estado. Tras un fallo, este estado es la base para recuperar el sistema de forma coherente.
- Puede consultar las bases de datos de origen y de destino después de un fallo para determinar la diferencia entre los sistemas de bases de datos de origen y de destino. El siguiente elemento de datos que se va a extraer se determina en función de la diferencia.
Otros enfoques para mantener el estado pueden depender de las bases de datos de origen específicas. Por ejemplo, un sistema de migración de bases de datos puede registrar qué entradas del registro de transacciones se obtienen de la base de datos de origen y cuáles se insertan en la base de datos de destino. Si se produce un fallo, la migración se puede reiniciar desde la última entrada insertada correctamente.
La persistencia de los datos en tránsito también es importante por otros motivos además de los errores o fallos. Por ejemplo, es posible que no se puedan consultar los datos de la base de datos de origen para determinar su estado. Por ejemplo, si la base de datos de origen contenía una cola, es posible que los mensajes de esa cola se hayan eliminado en algún momento.
Otro caso práctico de la persistencia de los datos en tránsito es el procesamiento de datos con ventanas grandes. Durante la modificación de datos, los elementos de datos se pueden transformar de forma independiente entre sí. Sin embargo, a veces la modificación de los datos depende de varios elementos de datos (por ejemplo, numerar los elementos de datos procesados por día, empezando por cero cada día).
Un último caso práctico de persistencia de datos en tránsito es proporcionar repetibilidad de los datos durante la modificación de datos cuando el sistema de base de datos no puede acceder de nuevo a las bases de datos de origen. Por ejemplo, puede que tengas que volver a ejecutar las modificaciones de datos con reglas de modificación diferentes y, a continuación, verificar y comparar los resultados con las modificaciones de datos iniciales. Este enfoque puede ser necesario si tienes que monitorizar las incoherencias de la base de datos de destino debido a una modificación incorrecta de los datos.
Verificación de la integridad y la coherencia
Debes verificar que la migración de tu base de datos se ha completado y que es coherente. Esta comprobación asegura que cada elemento de datos se migre solo una vez, que los conjuntos de datos de las bases de datos de origen y de destino sean idénticos y que la migración se haya completado.
En función de las reglas de modificación de datos, es posible que se extraiga un elemento de datos, pero no se inserte en una base de datos de destino. Por este motivo, comparar directamente las bases de datos de origen y de destino no es un método fiable para verificar la integridad y la coherencia. Sin embargo, si el sistema de migración de bases de datos registra los elementos que se han filtrado, puede comparar las bases de datos de origen y de destino junto con los elementos filtrados.
Función de replicación del sistema de gestión de bases de datos
Un caso práctico especial en una migración homogénea es cuando la base de datos de destino es una copia de la base de datos de origen. En concreto, los esquemas de las bases de datos de origen y de destino son los mismos, los valores de los datos son los mismos y cada base de datos de origen se asigna directamente (1:1) a una base de datos de destino.
En este caso, puedes usar la función de replicación integrada que incluyen la mayoría de los sistemas de gestión de bases de datos para replicar una base de datos en otra.
Hay dos tipos de replicación de datos: lógica y física.
Réplica lógica: en el caso de la réplica lógica, los cambios en los objetos de la base de datos se transfieren en función de sus identificadores de réplica (normalmente, claves principales). Las ventajas de la replicación lógica son que es flexible, granular y se puede personalizar. En algunos casos, la replicación lógica permite replicar cambios entre diferentes versiones del motor de la base de datos. Muchos motores de bases de datos admiten filtros de replicación lógica, donde puede definir el conjunto de datos que se van a replicar. Las principales desventajas son que la replicación lógica puede introducir una sobrecarga de rendimiento y que la latencia de este método de replicación suele ser mayor que la de la replicación física.
Replicación física: por el contrario, la replicación física funciona a nivel de bloque de disco y ofrece un mejor rendimiento con una latencia de replicación más baja. En el caso de conjuntos de datos grandes, la replicación física puede ser más sencilla y eficiente, sobre todo en el caso de estructuras de datos no relacionales. Sin embargo, no se puede personalizar y depende en gran medida de la versión del motor de base de datos.
Por ejemplo, la replicación de MySQL, la replicación de PostgreSQL (consulta también pglogical) o la replicación de Microsoft SQL Server.
Sin embargo, si es necesario modificar los datos o si la cardinalidad no es un mapeo directo, se necesitan las funciones de un sistema de migración de bases de datos para abordar este caso práctico.
Funciones de migración de bases de datos personalizadas
Algunas de las razones por las que se crean funciones de migración de bases de datos en lugar de usar un sistema de migración de bases de datos o un sistema de gestión de bases de datos son las siguientes:
- Necesitas tener un control total sobre cada detalle.
- Quieres reutilizar las funciones de migración de bases de datos.
- Quieres reducir los costes o simplificar tu huella tecnológica.
Estos son algunos de los elementos de creación para desarrollar funciones de migración:
- Exportación e importación: si el tiempo de inactividad no es un factor importante, puedes usar la exportación y la importación de bases de datos para migrar datos en migraciones de bases de datos homogéneas. Sin embargo, para exportar e importar, debe inmovilizar la base de datos de origen para evitar que se actualice antes de exportar los datos. De lo contrario, es posible que los cambios no se incluyan en la exportación y que la base de datos de destino no sea una copia exacta de la base de datos de origen.
- Copia de seguridad y restauración: al igual que en el caso de la exportación y la importación, la copia de seguridad y la restauración provocan un tiempo de inactividad porque debes inmovilizar la base de datos de origen para que la copia de seguridad contenga todos los datos y los cambios más recientes. El tiempo de inactividad continúa hasta que la restauración se completa correctamente en la base de datos de destino.
- Consultas diferenciales: si puedes cambiar el esquema de la base de datos, puedes ampliarlo para que los cambios en la base de datos se puedan consultar en la interfaz de consulta. Se añade un atributo de marca de tiempo adicional que indica la hora del último cambio. Se puede añadir una marca de eliminación adicional para indicar si el elemento de datos se ha eliminado o no (eliminación lógica). Con estos dos cambios, un poller que se ejecute a intervalos regulares puede consultar todos los cambios desde su última ejecución. Los cambios se aplican a la base de datos de destino. En el artículo Captura de datos de cambios se describen otros enfoques.
Estas son solo algunas de las opciones posibles para crear una migración de base de datos personalizada. Aunque una solución personalizada ofrece la mayor flexibilidad y control sobre la implementación, también requiere un mantenimiento constante para solucionar errores, limitaciones de escalabilidad y otros problemas que puedan surgir durante una migración de base de datos.
Consideraciones adicionales sobre la migración de bases de datos
En las siguientes secciones se describen brevemente los aspectos no funcionales que son importantes en el contexto de la migración de bases de datos. Estos aspectos incluyen la gestión de errores, la escalabilidad, la alta disponibilidad y la recuperación tras fallos.
Gestión de errores
Los errores que se produzcan durante la migración de la base de datos no deben provocar la pérdida de datos ni el procesamiento de los cambios de la base de datos fuera de orden. La integridad de los datos debe mantenerse independientemente de la causa del fallo (por ejemplo, un error en el sistema, una interrupción de la red, un fallo de la máquina virtual o un fallo de la zona).
Se produce una pérdida de datos cuando un sistema de migración obtiene los datos de las bases de datos de origen y no los almacena en las bases de datos de destino debido a algún error. Si se pierden datos, las bases de datos de destino no coinciden con las de origen y, por lo tanto, son incoherentes e incompletas. La función de verificación de la integridad y la coherencia marca este estado (Verificación de la integridad y la coherencia).
Escalabilidad
En una migración de bases de datos, el tiempo de migración es una métrica importante. En una migración con un periodo de inactividad mínimo, la migración de los datos se produce mientras las bases de datos de origen siguen cambiando. Para migrar en un plazo razonable, la velocidad de transferencia de datos debe ser significativamente mayor que la velocidad de actualización de los sistemas de bases de datos de origen, sobre todo si el sistema de bases de datos de origen es grande. Cuanto mayor sea la velocidad de transferencia, más rápido se podrá completar la migración de la base de datos.
Cuando los sistemas de bases de datos de origen están inactivos y no se modifican, la migración puede ser más rápida porque no hay cambios que incorporar. En una base de datos homogénea, el tiempo de migración puede ser bastante rápido porque puedes usar las funciones de copia de seguridad y restauración o de exportación e importación, y la transferencia de archivos se adapta.
Alta disponibilidad y recuperación tras fallos
Por lo general, las bases de datos de origen y de destino se configuran para que tengan una alta disponibilidad. Una base de datos principal tiene una réplica de lectura correspondiente que se convierte en la base de datos principal cuando se produce un fallo.
Si falla una zona, las bases de datos de origen o de destino se conmutan por error a otra zona para que estén disponibles de forma continua. Si se produce un fallo en una zona durante una migración de base de datos, el propio sistema de migración se verá afectado, ya que no se podrá acceder a varias de las bases de datos de origen o de destino a las que accede. El sistema de migración debe volver a conectarse a las bases de datos principales recién ascendidas que se ejecutan después de un fallo. Una vez que se haya vuelto a conectar el sistema de migración de bases de datos, este deberá recuperar la migración para asegurar la integridad y la coherencia de los datos de las bases de datos de destino. El sistema de migración debe determinar la última transferencia coherente para establecer dónde reanudar el proceso.
Si el propio sistema de migración de bases de datos falla (por ejemplo, si no se puede acceder a la zona en la que se ejecuta), debe recuperarse. Una de las formas de recuperación es el reinicio en frío. Con este método, el sistema de migración de bases de datos se instala en una zona operativa y se reinicia. El principal problema que hay que abordar es que el sistema de migración debe poder determinar la última transferencia de datos coherente antes del fallo y continuar desde ese punto para asegurar la integridad y la coherencia de los datos en las bases de datos de destino.
Si el sistema de migración de bases de datos está habilitado para la alta disponibilidad, puede conmutar por error y seguir procesando después. Si es importante que el sistema de migración de la base de datos tenga un tiempo de inactividad limitado, debes seleccionar una base de datos e implementar una alta disponibilidad.
En cuanto a la recuperación de la migración de la base de datos, la recuperación tras desastres es muy similar a la alta disponibilidad. En lugar de volver a conectarse a las bases de datos primarias recién ascendidas de otra zona, el sistema de migración de bases de datos debe volver a conectarse a las bases de datos de otra región (una región de failover). Lo mismo ocurre con el propio sistema de migración de bases de datos. Si la región en la que se ejecuta el sistema de migración de bases de datos deja de estar accesible, el sistema debe cambiar a otra región y continuar desde la última transferencia de datos coherente.
Inconvenientes
Hay varios errores que pueden provocar que los datos de las bases de datos de destino sean incoherentes. Estos son algunos de los más habituales que debes evitar:
- Infracción de pedidos. Si la escalabilidad del sistema de migración se consigue mediante el escalado horizontal, se ejecutan varios procesos de transferencia de datos simultáneamente (en paralelo). Los cambios en un sistema de base de datos de origen se ordenan según las transacciones confirmadas. Si los cambios se recogen del registro de transacciones, el orden debe mantenerse durante toda la migración. La transferencia de datos en paralelo puede cambiar el orden debido a la variación de la velocidad entre los procesos subyacentes. Es necesario asegurarse de que los datos se inserten en las bases de datos de destino en el mismo orden en que se reciben de las bases de datos de origen.
- Infracción de la coherencia. Con las consultas diferenciales, las bases de datos de origen tienen atributos de datos adicionales que contienen, por ejemplo, marcas de tiempo de confirmación. Las bases de datos de destino no tendrán marcas de tiempo de confirmación, ya que estas solo se implementan para establecer la gestión de cambios en las bases de datos de origen. Es importante asegurarse de que las inserciones en las bases de datos de destino tengan una marca de tiempo coherente, lo que significa que todos los cambios con la misma marca de tiempo deben estar en la misma transacción de inserción, actualización o upsert. De lo contrario, la base de datos de destino podría tener un estado incoherente (temporalmente) si se insertan algunos cambios y otros con la misma marca de tiempo no. Este estado temporal incoherente no importa si no se accede a las bases de datos de destino para procesarlas. Sin embargo, si se usan para pruebas, la coherencia es fundamental. Otro aspecto es la creación de los valores de marca de tiempo en la base de datos de origen y cómo se relacionan con la hora de confirmación de la transacción en la que se definen. Debido a las dependencias de confirmación de transacciones, una transacción con una marca de tiempo anterior puede hacerse visible después de una transacción con una marca de tiempo posterior. Si la consulta diferencial se ejecuta entre las dos transacciones, no verá la transacción con la marca de tiempo anterior, lo que provocará una incoherencia en la base de datos de destino.
- Faltan datos o están duplicados. Cuando se produce una conmutación por error, es necesario realizar una recuperación cuidadosa si algunos datos no se han replicado entre la réplica principal y la de conmutación por error. Por ejemplo, una base de datos de origen falla y no se replican todos los datos en la réplica de conmutación por error. Al mismo tiempo, los datos ya se han migrado a la base de datos de destino antes del error. Después de la conmutación por error, la base de datos principal recién ascendida está desfasada en cuanto a los cambios de datos de la base de datos de destino (llamada restauración). Un sistema de migración debe reconocer esta situación y recuperarse de ella de forma que la base de datos de destino y la de origen vuelvan a un estado coherente.
- Transacciones locales. Para que la base de datos de origen y la de destino reciban los mismos cambios, un enfoque habitual es que los clientes escriban en ambas bases de datos en lugar de usar un sistema de migración de datos. Este enfoque tiene varios inconvenientes. Un error habitual es que dos escrituras en la base de datos son dos transacciones independientes, por lo que puede producirse un fallo después de que finalice la primera y antes de que finalice la segunda. En este caso, los datos son incoherentes y debes recuperarlos. Además, hay varios clientes en general y no están coordinados. Los clientes no conocen el orden de confirmación de las transacciones de la base de datos de origen y, por lo tanto, no pueden escribir en las bases de datos de destino que implementan ese orden de transacciones. Los clientes pueden cambiar el orden, lo que puede provocar incoherencias en los datos. A menos que todo el acceso se realice a través de clientes coordinados y todos los clientes aseguren el orden de las transacciones de destino, este enfoque puede provocar un estado incoherente en la base de datos de destino.
En general, hay otros errores que debes evitar. La mejor forma de detectar problemas que puedan provocar incoherencias en los datos es realizar un análisis completo de los fallos que recorra todos los posibles escenarios de fallo. Si se implementa la simultaneidad en el sistema de migración de la base de datos, se deben examinar todos los órdenes de ejecución posibles del proceso de migración de datos para asegurarse de que se mantiene la coherencia de los datos. Si se implementa la alta disponibilidad o la recuperación tras fallos (o ambas), se deben examinar todas las combinaciones de fallos posibles.
Siguientes pasos
- Consulta Migraciones de bases de datos: conceptos y principios (parte 2).
- Consulta información sobre la migración de bases de datos en los siguientes documentos:
- Consulta Migración de bases de datos para ver más guías de migración de bases de datos.
- Consulta arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Centro de arquitectura de Cloud.