Questo articolo è la quarta parte di una serie di quattro articoli che illustra come puoi prevedere il lifetime value cliente (CLV) utilizzando AI Platform (AI Platform) su Google Cloud. Questo articolo spiega come utilizzare AutoML Tables per eseguire le previsioni.
Gli articoli di questa serie includono quanto segue:
- Parte 1: Introduzione. Illustra il CLV e due tecniche di modellazione per la sua previsione.
- Parte 2: addestramento del modello Spiega come preparare i dati e addestrare i modelli.
- Parte 3: esegui il deployment in produzione. Descrive come eseguire il deployment dei modelli descritti nella Parte 2 in un sistema di produzione.
- Parte 4: Utilizzo di AutoML Tables (questo articolo). Mostra come utilizzare AutoML Tables per creare ed eseguire il deployment di un modello.
La procedura descritta in questo articolo si basa sugli stessi passaggi di elaborazione dei dati in BigQuery descritti nella Parte 2 della serie. Questo articolo mostra come caricare il set di dati BigQuery in AutoML Tables e creare un modello. Questo articolo illustra inoltre come integrare il modello AutoML nel sistema di produzione descritto nella Parte 3.
Il codice per l'implementazione di questo sistema si trova nello stesso repository GitHub della serie originale. Questo articolo spiega come utilizzare il codice di AutoML Tables in quel repository.
Vantaggi di AutoML Tables
Nelle parti precedenti della serie, hai visto come prevedere il CLV utilizzando sia un modello statistico sia un modello DNN implementato in TensorFlow. AutoML Tables presenta diversi vantaggi rispetto agli altri due metodi:
- Non è necessario scrivere codice per creare il modello. È disponibile una UI della console che ti consente di creare, addestrare, gestire ed eseguire il deployment di set di dati e modelli.
- Aggiungere o modificare le funzionalità è facile e può essere eseguito direttamente nell'interfaccia della console.
- Il processo di addestramento è automatizzato, inclusa l'ottimizzazione degli iperparametri.
- AutoML Tables cerca l'architettura migliore per il tuo set di dati, eliminando la necessità di scegliere tra le numerose opzioni disponibili.
- AutoML Tables fornisce un'analisi dettagliata del rendimento di un modello addestrato, inclusa l'importanza delle funzionalità.
Di conseguenza, lo sviluppo e l'addestramento di un modello completamente ottimizzato utilizzando AutoML Tables possono richiedere meno tempo e costi.
Un deployment in produzione di una soluzione AutoML Tables richiede l'utilizzo dell'API client Python per creare e implementare i modelli ed eseguire le previsioni. Questo articolo mostra come creare e addestrare i modelli AutoML Tables utilizzando l'API client. Per indicazioni su come eseguire questi passaggi utilizzando la console di AutoML Tables, consulta la documentazione di AutoML Tables.
Installazione del codice
Se non hai installato il codice per la serie originale, segui gli stessi passaggi descritti nella Parte 2 della serie originale per installare il codice. Il file README nel repository GitHub descrive tutti i passaggi necessari per preparare l'ambiente, installare il codice e configurare AutoML Tables nel progetto.
Se hai installato il codice in precedenza, devi eseguire questi passaggi aggiuntivi per completare l'installazione per questo articolo:
- Abilita l'API AutoML Tables nel tuo progetto.
- Attiva l'ambiente miniconda che hai installato in precedenza.
- Installa la libreria client Python come descritto nella documentazione di AutoML Tables.
- Crea e scarica un file della chiave API e salvalo in una posizione nota per utilizzarlo in un secondo momento con la libreria client.
Eseguire il codice
Per molti dei passaggi descritti in questo articolo, devi eseguire comandi Python. Dopo aver preparato l'ambiente e installato il codice, hai a disposizione le seguenti opzioni per eseguirlo:
Esegui il codice in un notebook Jupyter. Dalla finestra del terminale nell'ambiente miniconda attivato, esegui il seguente comando:
$ (clv) jupyter notebook
Il codice per ogni passaggio di questo articolo si trova in un notebook nel repository di codice denominato
notebooks/clv_automl.ipynb. Apri questo notebook nell'interfaccia Jupyter. Puoi quindi eseguire ciascun passaggio man mano che segui il tutorial.Esegui il codice come script Python. I passaggi di codice per questo tutorial sono nel repository del codice nel file
clv_automl/clv_automl.py. Lo script accetta argomenti sulla riga di comando per i parametri configurabili come l'ID progetto, la posizione del file della chiave API, la regione e il nome del set di dati BigQuery. Google Cloud Esegui lo script dalla finestra del terminale nell'ambiente miniconda attivato, sostituendo il Google Cloud nome del progetto con[YOUR_PROJECT]:$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
Per l'elenco completo dei parametri e dei valori predefiniti, consulta il metodo
create_parsernello script o esegui lo script senza argomenti per visualizzare la documentazione sull'utilizzo.Dopo aver installato l'ambiente Cloud Composer come descritto nel file README, esegui il codice eseguendo i DAG, come descritto in seguito nella sezione Eseguire i DAG.
Preparazione dei dati
Questo articolo utilizza gli stessi set di dati e passaggi di preparazione dei dati in BigQuery descritti nella Parte 2 della serie originale. Dopo aver completato l'aggregazione dei dati come descritto nell'articolo, puoi creare un set di dati da utilizzare con AutoML Tables.
Creazione del set di dati AutoML Tables
Per iniziare, carica i dati preparati in BigQuery in AutoML Tables.
Per inizializzare il client, imposta il nome del file della chiave sul nome del file che hai scaricato nel passaggio di installazione:
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)Crea il set di dati:
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
Importazione dei dati da BigQuery
Dopo aver creato il set di dati, puoi importare i dati da BigQuery.
Importa i dati da BigQuery nel set di dati AutoML Tables:
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
Addestramento del modello
Dopo aver creato il set di dati AutoML per i dati CLV, puoi creare il modello AutoML Tables.
Recupera le specifiche delle colonne di AutoML Tables per ogni colonna del set di dati:
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}Le specifiche delle colonne sono necessarie nei passaggi successivi.
Assegna una delle colonne come etichetta per il modello AutoML Tables:
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)Questo codice utilizza la stessa colonna delle etichette (
target_monetary) del modello DNN di TensorFlow nella Parte 2.Definisci le funzionalità per addestrare il modello:
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')Le funzionalità utilizzate per addestrare il modello di AutoML Tables sono le stesse utilizzate per addestrare il modello DNN di TensorFlow nella Parte 2 della serie originale. Tuttavia, aggiungere o sottrarre funzionalità al modello è molto più semplice con AutoML Tables. Una volta creata in BigQuery, una funzionalità viene automaticamente inclusa nel modello, a meno che non la rimuovi esplicitamente come mostrato nello snippet di codice precedente.
Definisci le opzioni per la creazione del modello. Per questo set di dati è consigliato l'obiettivo di ottimizzazione di minimizzare l'errore assoluto medio, rappresentato dal parametro
MINIMIZE_MAE.model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }Per ulteriori informazioni, consulta la documentazione di AutoML Tables s sugli obiettivi di ottimizzazione.
Crea il modello e avvia l'addestramento:
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.nameIl valore restituito dalla chiamata al client (
create_model_response) viene fornito immediatamente. Il valorecreate_model_response.result()è una promessa che si blocca fino al completamento dell'addestramento. Il valoremodel_nameè un percorso della risorsa necessario per ulteriori chiamate al client che operano sul modello.
Valutazione del modello
Al termine dell'addestramento del modello, puoi recuperare le statistiche di valutazione del modello. Puoi utilizzare la Google Cloud console o l'API client.
Per utilizzare la console, vai alla scheda Valuta nella console AutoML Tables:

Per utilizzare l'API client, recupera le statistiche di valutazione del modello:
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]Viene visualizzato un output simile al seguente:
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
L'errore quadratico medio di 853.481 è migliore rispetto ai modelli probabilistici e TensorFlow utilizzati nella serie originale. Tuttavia, come discusso nella Parte 2, è consigliabile provare ciascuna delle tecniche fornite con i tuoi dati per vedere quale ha il rendimento migliore.
Eseguire il deployment del modello AutoML
I DAG di Cloud Composer della serie originale sono stati aggiornati per includere il modello AutoML Tables sia per l'addestramento che per la previsione. Per informazioni generali sul funzionamento dei DAG di Cloud Composer, consulta la sezione sull'automazione della soluzione nella Parte 3 degli articoli originali.
Puoi installare il sistema di orchestrazione Cloud Composer per questa soluzione seguendo le istruzioni riportate nel file README.
I metodi di chiamata dei DAG aggiornati nello script clv_automl/clv_automl.py che
riproducono le chiamate al codice client mostrate in precedenza per creare il modello e
eseguire le previsioni.
Il DAG di addestramento
Il DAG aggiornato per l'addestramento include attività per creare un modello AutoML Tables. Il seguente diagramma mostra il nuovo DAG per l'addestramento.

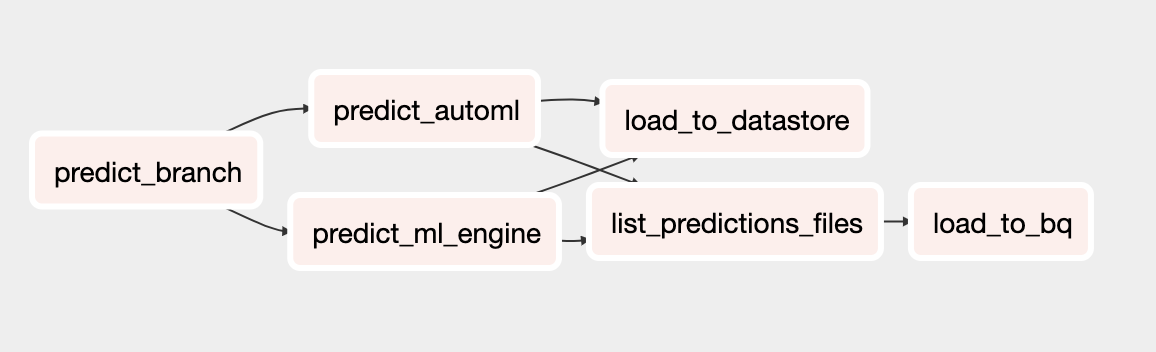
Il DAG di previsione
Il DAG aggiornato per la previsione include attività per eseguire previsioni batch con il modello AutoML Tables. Il seguente diagramma mostra il nuovo DAG per le previsioni.
Esecuzione dei DAG
Per attivare manualmente i DAG, puoi eseguire i comandi dalla sezione Esegui DAG del file README in Cloud Shell o utilizzando Google Cloud CLI.
Per eseguire il DAG
build_train_deploy:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'Esegui il DAG
predict_serve:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
Passaggi successivi
- Consulta il set completo di tutorial sul CLV.
- Esegui l'esempio completo nel repository GitHub.
- Scopri altre soluzioni di previsione predittiva.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.