Questo articolo è la seconda parte di una serie di quattro articoli che illustra come puoi prevedere il lifetime value cliente (CLV) utilizzando AI Platform (AI Platform) su Google Cloud.
Gli articoli di questa serie includono quanto segue:
- Parte 1: Introduzione. Illustra il CLV e due tecniche di modellazione per la sua previsione.
- Parte 2: addestramento del modello (questo articolo). Spiega come preparare i dati e addestrare i modelli.
- Parte 3: esegui il deployment in produzione. Descrive come eseguire il deployment dei modelli descritti nella Parte 2 in un sistema di produzione.
- Parte 4: utilizzare AutoML Tables. Mostra come utilizzare AutoML Tables per creare ed eseguire il deployment di un modello.
Il codice per l'implementazione di questo sistema si trova in un repository GitHub. Questa serie illustra lo scopo del codice e come viene utilizzato.
Introduzione
Questo articolo fa seguito alla Parte 1, in cui hai appreso due diversi modelli per prevedere il lifetime value del cliente (CLV):
- Modelli probabilistici
- Modelli di reti neurali profonde (DNN), un tipo di modello di machine learning
Come indicato nella Parte 1, uno degli obiettivi di questa serie è confrontare questi modelli per la previsione del CLV. Questa parte della serie descrive come preparare i dati, creare e addestrare entrambi i tipi di modello per prevedere il CLV e fornisce alcune informazioni di confronto.
Installazione del codice
Se vuoi seguire la procedura descritta in questo articolo, devi installare il codice di esempio da GitHub.
Se hai installato gcloud CLI, apri una finestra del terminale sul computer per eseguire questi comandi. Se non hai installato gcloud CLI, apri un'istanza di Cloud Shell.
Clona il repository di codice di esempio:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Per configurare l'ambiente, segui le istruzioni di installazione riportate nella sezione Installazione del file README.
Preparazione dei dati
Questa sezione descrive come ottenere i dati e pulirli.
Ottenere e pulire il set di dati di origine
Prima di poter calcolare il CLV, devi assicurarti che i dati di origine contengano almeno quanto segue:
- Un ID cliente utilizzato per distinguere i singoli clienti.
- Un importo di acquisto per cliente che mostra quanto un cliente ha speso in un determinato momento.
- Una data per ogni acquisto.
In questo articolo, spiegheremo come addestrare i modelli utilizzando i dati storici sulle vendite del set di dati di vendita al dettaglio online disponibile pubblicamente del repository di machine learning UCI.[1]
Il primo passaggio consiste nel copiare il set di dati come file CSV in
Cloud Storage.
Utilizzando uno degli strumenti di caricamento per BigQuery, crea una tabella denominata data_source. Questo nome è arbitrario, ma il codice nel repository GitHub lo utilizza. Il set di dati è disponibile in un bucket pubblico associato a questa serie ed è già stato convertito in formato CSV.
- Sul computer o in Cloud Shell, esegui i comandi descritti nella sezione di configurazione del file README nel repository GitHub.
Il set di dati di esempio contiene i campi elencati nella tabella seguente. Per l'approccio descritto in questo articolo, utilizza solo i campi in cui la colonna Used (Utilizzato) è impostata su Yes (Sì). Alcuni campi non vengono utilizzati direttamente, ma aiutano a creare nuovi campi, ad esempio UnitPrice
e Quantity creano order_value.
| Usato | Campo | Tipo | Descrizione |
|---|---|---|---|
| No | InvoiceNo |
STRING |
Nominale. Un numero integrale di 6 cifre assegnato in modo univoco a ogni transazione.
Se questo codice inizia con la lettera c, indica una cancellazione. |
| No | StockCode |
STRING |
Codice prodotto (articolo). Nominale, un numero intero di 5 cifre assegnato in modo univoco a ogni prodotto distinto. |
| No | Description |
STRING |
Nome del prodotto (articolo). Nominale. |
| Sì | Quantity |
INTEGER |
Le quantità di ciascun prodotto (articolo) per transazione. Numerico. |
| Sì | InvoiceDate |
STRING |
Data e ora della fattura nel formato gg/mm/aa hh:mm. Il giorno e l'ora in cui è stata generata ogni transazione. |
| Sì | UnitPrice |
FLOAT |
Prezzo unitario. Numerico. Il prezzo del prodotto per unità in sterline. |
| Sì | CustomerID |
STRING |
Numero cliente. Nominale. Un numero intero di 5 cifre assegnato in modo univoco a ogni cliente. |
| No | Country |
STRING |
Nome del paese. Nominale. Il nome del paese in cui risiede ciascun cliente. |
pulisci i dati
Indipendentemente dal modello utilizzato, devi eseguire una serie di passaggi di preparazione e pulizia comuni a tutti i modelli. Le seguenti operazioni sono obbligatorie per ottenere un insieme di campi e record utilizzabili:
- Raggruppa gli ordini per giorno anziché utilizzare
InvoiceNo, perché l'unità di tempo minima utilizzata dai modelli probabilistici in questa soluzione è un giorno. - Mantieni solo i campi utili per i modelli probabilistici.
- Mantieni solo i record con quantità di ordine e valori monetari positivi, come gli acquisti.
- Mantieni solo i record con quantità dell'ordine negative, ad esempio i resi.
- Conserva solo i record con un ID cliente.
- Mantieni solo i clienti che hanno acquistato qualcosa negli ultimi 90 giorni.
- Mantieni solo i clienti che hanno effettuato almeno due acquisti nel periodo di tempo utilizzato per creare le funzionalità.
Puoi eseguire tutte queste operazioni utilizzando la seguente query BigQuery. Come per i comandi precedenti, esegui questo codice ovunque tu abbia clonato il repository GitHub. Poiché i dati sono vecchi, ai fini di questo articolo la data del 12 dicembre 2011 è considerata la data odierna.
Questa query esegue due attività. Innanzitutto, se il set di dati di lavoro è di grandi dimensioni, la query lo riduce. Il set di dati di lavoro per questa soluzione è piuttosto piccolo, ma questa query può ridurre un set di dati estremamente grande di due ordini di grandezza in pochi secondi.
In secondo luogo, la query crea un set di dati di base su cui lavorare, simile al seguente:
customer_id
|
order_date
|
order_value
|
order_qty_articles
|
|---|---|---|---|
| 16915 | 2011-08-04 | 173,7 | 6 |
| 15349 | 2011-07-04 | 107,7 | 77 |
| 14794 | 2011-03-30 | -33,9 | -2 |
Il set di dati ripulito contiene anche il campo order_qty_articles. Questo campo è incluso solo per l'utilizzo da parte della rete neurale profonda (DNN) descritta nella sezione successiva.
Definizione degli intervalli di addestramento e target
Per prepararti all'addestramento dei modelli, devi scegliere una data di soglia. Questa data separa gli ordini in due partizioni:
- Gli ordini precedenti alla data di soglia vengono utilizzati per addestrare il modello.
- Gli ordini successivi alla data di soglia vengono utilizzati per calcolare il valore target.

La libreria Lifetimes include metodi per la preelaborazione dei dati. Tuttavia, i set di dati che utilizzi per il CLV possono essere piuttosto grandi, il che rende impraticabile eseguire la preelaborazione dei dati su un'unica macchina. L'approccio descritto in questo articolo utilizza query eseguite direttamente in BigQuery per suddividere gli ordini in due insiemi. I modelli ML e probabilistici utilizzano le stesse query, garantendo che entrambi i modelli operino sugli stessi dati.
La data della soglia ottimale potrebbe essere diversa per i modelli ML e per i modelli probabilistici. Puoi aggiornare questo valore della data direttamente all'interno dell'istruzione SQL. Considera la data di soglia ottimale come un iperparametro. Puoi trovare il valore più appropriato esplorando i dati ed eseguendo alcuni addestramenti di test.
La data di soglia viene utilizzata nella clausola WHERE della query SQL che seleziona
i dati di addestramento dalla tabella di dati puliti, come mostrato nell'esempio seguente:
Aggregare i dati
Dopo aver suddiviso i dati in intervalli di addestramento e target, li aggreghi per creare funzionalità e target effettivi per ogni cliente. Per i modelli probabilistici, l'aggregazione è limitata ai campi di recency, frequenza e valore monetario (RFM). Per i modelli DNN, vengono utilizzate anche le funzionalità RFM, ma è possibile utilizzare funzionalità aggiuntive per fare previsioni migliori.
La seguente query mostra come creare contemporaneamente funzionalità sia per i modelli DNN sia per quelli probabilistici:
La tabella seguente elenca gli elementi creati dalla query.
| Nome funzionalità | Descrizione | Probabilistica | DNN |
|---|---|---|---|
monetary_dnn
|
La somma di tutti i valori monetari degli ordini per cliente durante il periodo di funzionalità. | x | |
monetary_btyd
|
La media di tutti i valori monetari degli ordini per ciascun cliente durante il periodo delle funzionalità. I modelli probabilistici presuppongono che il valore del primo ordine sia 0. Questo viene applicato dalla query. | x | |
recency
|
Il tempo che intercorre tra il primo e l'ultimo ordine effettuati da un cliente durante il periodo delle funzionalità. | x | |
frequency_dnn
|
Il numero di ordini effettuati da un cliente durante il periodo delle funzionalità. | x | |
frequency_btyd
|
Il numero di ordini effettuati da un cliente durante il periodo delle funzionalità meno il primo. | x | |
T
|
Il tempo che intercorre tra il primo ordine effettuato da un cliente e la fine del periodo di funzionalità. | x | x |
time_between
|
Il tempo medio tra un ordine e l'altro per un cliente durante il periodo di funzionalità. | x | |
avg_basket_value
|
Il valore monetario medio del carrello del cliente durante il periodo di funzionalità. | x | |
avg_basket_size
|
Il numero di articoli che il cliente ha in media nel carrello durante il periodo delle funzionalità. | x | |
cnt_returns
|
Il numero di ordini restituiti dal cliente durante il periodo di funzionalità. | x | |
has_returned
|
Indica se il cliente ha restituito almeno un ordine durante il periodo di funzionalità. | x | |
frequency_btyd_clipped
|
Uguale a frequency_btyd, ma con valori estremi tagliati dal limite. |
x | |
monetary_btyd_clipped
|
Uguale a monetary_btyd, ma con valori estremi tagliati dal limite. |
x | |
target_monetary_clipped
|
Uguale a target_monetary, ma con valori estremi tagliati dal limite. |
x | |
target_monetary
|
L'importo totale speso da un cliente, inclusi i periodi di addestramento e di destinazione. | x |
La selezione di queste colonne viene eseguita nel codice. Per i modelli probabilistici, la selezione viene eseguita utilizzando un DataFrame Pandas:
Per i modelli DNN, le funzionalità di TensorFlow sono definite nel
context.py file. Per questi modelli, i seguenti elementi vengono ignorati come funzionalità:
customer_id. Si tratta di un valore univoco che non è utile come caratteristica.target_monetary. Si tratta del target che il modello deve prevedere e quindi non viene utilizzato come input.
Creazione dei set di addestramento, valutazione e test per le reti neurali profonde
Questa sezione riguarda solo i modelli DNN. Per addestrare un modello ML, devi utilizzare tre set di dati non sovrapposti:
Il set di dati di addestramento (70-80%) viene utilizzato per apprendere i pesi per ridurre una funzione di perdita. L'addestramento continua finché la funzione di perdita non diminuisce più.
Il set di dati di valutazione (10-15%) viene utilizzato durante la fase di addestramento per evitare overfitting, ovvero quando un modello ha un buon rendimento sui dati di addestramento, ma non si generalizza bene.
Il set di dati di test (10-15%) deve essere utilizzato una sola volta, al termine dell'addestramento e della valutazione, per eseguire una misurazione finale del rendimento del modello. Questo set di dati non è mai stato visto dal modello durante il processo di addestramento, pertanto fornisce una misura statisticamente valida dell'accuratezza del modello.
La seguente query crea un set di addestramento con circa il 70% dei dati. La query segrega i dati utilizzando la seguente tecnica:
- Viene calcolato un hash dell'ID cliente, che produce un numero intero.
- Viene utilizzata un'operazione modulo per selezionare i valori hash inferiori a una determinata soglia.
Lo stesso concetto viene utilizzato per il set di valutazione e i set di test, in cui vengono conservati i dati superiori alla soglia.
Formazione
Come hai visto nella sezione precedente, puoi utilizzare diversi modelli per provare a predire il CLV. Il codice utilizzato in questo articolo è stato progettato per consentirti di decidere
quale modello utilizzare. Scegli il modello utilizzando il parametro model_type
che passi al seguente script shell di addestramento. Il codice si occupa del resto.
Il primo obiettivo dell'addestramento è che entrambi i modelli siano in grado di superare un benchmark ingenuo, che definiamo di seguito. Se entrambi i tipi di modelli possono superare questo valore (e dovrebbero), puoi confrontare il rendimento di ciascun tipo rispetto all'altro.
Benchmarking dei modelli
Ai fini di questa serie, un benchmark ingenuo viene definito utilizzando i seguenti parametri:
- Valore medio del carrello. Questo valore viene calcolato su tutti gli ordini effettuati prima della data di soglia.
- Conteggio degli ordini. Questo viene calcolato per l'intervallo di addestramento di tutti gli ordini effettuati prima della data di soglia.
- Moltiplicatore del conteggio. Questo valore viene calcolato in base al rapporto tra il numero di giorni prima della data di soglia e il numero di giorni tra la data di soglia e il giorno corrente.
Il benchmark presuppone ingenuamente che la percentuale di acquisti stabilita da un cliente durante l'intervallo di addestramento rimanga costante nell'intervallo di destinazione. Pertanto, se un cliente ha effettuato acquisti 6 volte in 40 giorni, si presume che ne effettui 9 in 60 giorni (60/40 * 6 = 9). La moltiplicazione del moltiplicatore del conteggio, del numero di ordini e del valore medio del carrello per ciascun cliente consente di ottenere un valore target previsto ingenuo per quel cliente.
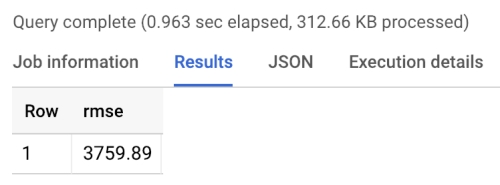
L'errore del benchmark è l'errore quadratico medio (RMSE): la media per tutti gli utenti della differenza assoluta tra il valore target previsto e il valore target effettivo. L'RMSE viene calcolato utilizzando la seguente query in BigQuery:
Il benchmark restituisce un RMSE di 3760, come mostrato nei seguenti risultati dell'esecuzione del benchmark. I modelli devono superare questo valore.
Modelli probabilistici
Come accennato nella Parte 1 di questa serie, questa utilizza una libreria Python chiamata Lifetimes che supporta vari modelli, tra cui la distribuzione Pareto/binomiale negativa (NBD) e i modelli BG/NBD beta-geometrici. Il seguente codice di esempio mostra come utilizzare la libreria Lifetimes per eseguire previsioni sul lifetime value con modelli probabilistici.
Per generare risultati CLV utilizzando il modello probabilistico nel tuo ambiente locale, puoi eseguire lo script mltrain.sh seguente. Fornisci parametri per le date di inizio e di fine della suddivisione dell'addestramento e per la fine del periodo di previsione.
./mltrain.sh local data --model_type paretonbd_model --threshold_date [YOUR_THRESHOLD_DATE] --predict_end [YOUR_END_DATE]
Modelli DNN
Il codice di esempio include implementazioni in TensorFlow di reti neurali profonde che utilizzano la classe Estimator DNNRegressor predefinita, nonché un modello Estimator personalizzato. DNNRegressor e l'estimatore personalizzato utilizzano lo stesso numero di livelli e neuroni in ogni livello. Questi valori sono iperparametri
che devono essere ottimizzati. Nel seguente file task.py, puoi trovare un elenco
di alcuni degli iperparametri impostati su valori testati manualmente
e che hanno dato buoni risultati.
Se utilizzi AI Platform, puoi utilizzare la funzionalità di ottimizzazione degli iperparametri, che eseguirà il test su una serie di parametri definiti in un file yaml. AI Platform utilizza l'ottimizzazione bayesiana per eseguire ricerche nello spazio degli iperparametri.
Risultati del confronto dei modelli
La tabella seguente mostra i valori RMSE per ciascun modello, addestrato sul set di dati di esempio. Tutti i modelli vengono addestrati sui dati RFM. I valori RMSE variano leggermente tra le esecuzioni a causa dell'inizializzazione casuale dei parametri. Il modello DNN utilizza funzionalità aggiuntive come il valore medio del carrello e il numero di resi.
| Modello | RMSE |
|---|---|
| DNN | 947,9 |
| BG/NBD | 1557 |
| Pareto/NBD | 1558 |
I risultati mostrano che su questo set di dati, il modello DNN supera i modelli probabilistici nella previsione del valore monetario. Tuttavia, le dimensioni relativamente ridotte del set di dati UCI limitano la validità statistica di questi risultati. Ti consigliamo di provare ciascuna delle tecniche sul tuo set di dati per scoprire quale offre i risultati migliori. Tutti i modelli sono stati addestrati utilizzando gli stessi dati originali (inclusi ID cliente, data dell'ordine e valore dell'ordine) sui valori RFM che sono stati estratto da questi dati. I dati di addestramento della rete neurale di tipo DNN includevano alcune funzionalità aggiuntive come la dimensione media del carrello e il numero di resi.
Il modello DNN restituisce solo il valore monetario complessivo del cliente. Se ti interessa predire la frequenza o il tasso di abbandono, devi eseguire alcune attività aggiuntive:
- Prepara i dati in modo diverso per modificare il target e possibilmente la data di soglia.
- Addestra nuovamente un modello di regressione per prevedere il target che ti interessa.
- Ottimizza gli iperparametri.
L'intento era eseguire un confronto sulle stesse caratteristiche di input tra i due tipi di modelli. Un vantaggio dell'utilizzo delle reti neurali profonde è che potresti migliorare i risultati aggiungendo più funzionalità rispetto a quelle utilizzate in questo esempio. Con le reti neurali di apprendimento profondo, puoi utilizzare i dati provenienti da origini quali eventi di flusso di clic, profili utente o funzionalità dei prodotti.
Ringraziamenti
Dua, D. e Karra Taniskidou, E. (2017). UCI Machine Learning Repository http://archive.ics.uci.edu/ml. Irvine, CA: University of California, School of Information and Computer Science.
Passaggi successivi
- Leggi la Parte 3: Deployment in produzione di questa serie per scoprire come eseguire il deployment di questi modelli.
- Scopri altre soluzioni di previsione predittiva.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.