Questo articolo è la terza parte di una serie di quattro articoli che illustrano come puoi prevedere il lifetime value cliente (CLV) utilizzando AI Platform (AI Platform) su Google Cloud.
Gli articoli di questa serie includono quanto segue:
- Parte 1: Introduzione. Illustra il CLV e due tecniche di modellazione per la sua previsione.
- Parte 2: addestramento del modello. Spiega come preparare i dati e addestrare i modelli.
- Parte 3: distribuzione in produzione (questo articolo). Descrive come eseguire il deployment dei modelli descritti nella Parte 2 in un sistema di produzione.
- Parte 4: utilizzare AutoML Tables. Mostra come utilizzare AutoML Tables per creare ed eseguire il deployment di un modello.
Installazione del codice
Se vuoi seguire la procedura descritta in questo articolo, devi installare il codice di esempio da GitHub.
Se hai installato gcloud CLI, apri una finestra del terminale sul computer per eseguire questi comandi. Se non hai installato gcloud CLI, apri un'istanza di Cloud Shell.
Clona il repository di codice di esempio:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Segui le istruzioni di installazione nelle sezioni Installazione e Automazione del file README per configurare l'ambiente e implementare i componenti della soluzione. Sono inclusi il set di dati di esempio e l'ambiente Cloud Composer.
Gli esempi di comandi nelle sezioni seguenti presuppongono che tu abbia completato entrambi questi passaggi.
Nell'ambito delle istruzioni di installazione, devi configurare le variabili per il tuo ambiente come descritto nella sezione di configurazione del file README.
Modifica la variabile REGION in modo che corrisponda alla Google Cloud regione
più vicina a te dal punto di vista geografico. Per un elenco delle regioni, consulta
Regioni e zone.
Architettura e implementazione
Il seguente diagramma mostra l'architettura utilizzata in questa discussione.

L'architettura è suddivisa nelle seguenti funzioni:
- Importazione dei dati:i dati vengono importati in BigQuery.
- Preparazione dei dati:i dati non elaborati vengono trasformati in modo da essere utilizzabili dai modelli.
- Addestramento del modello:i modelli vengono creati, addestrati e ottimizzati in modo da poter essere utilizzati per eseguire previsioni.
- Pubblicazione delle previsioni: le previsioni offline vengono memorizzate e rese disponibili con bassa latenza.
- Automazione: tutte queste attività vengono eseguite e gestite tramite Cloud Composer.
Importazione dei dati
Questa serie di articoli non illustra un modo specifico per eseguire l'importazione dei dati. Esistono molti modi per importare dati in BigQuery, tra cui da Pub/Sub, da Cloud Storage e da BigQuery Data Transfer Service. Per ulteriori informazioni, consulta BigQuery per professionisti di data warehousing. Nell'approccio descritto in questa serie utilizziamo un set di dati pubblico. Importa questo set di dati in BigQuery, come descritto nel codice di esempio nel file README.
Preparazione dei dati
Per preparare i dati, esegui query su BigQuery come quelle riportate nella Parte 2 di questa serie. In un'architettura di produzione, esegui le query nell'ambito di un grafo aciclico diretto (DAG) di Apache Airflow. La sezione sull'automazione di questo documento fornisce ulteriori dettagli sull'esecuzione di query per la preparazione dei dati.
Addestramento del modello su AI Platform
Questa sezione fornisce una panoramica della parte di addestramento dell'architettura.
Indipendentemente dal tipo di modello scelto, il codice mostrato in questa soluzione è impacchettato per l'esecuzione su AI Platform, sia per l'addestramento sia per la previsione. AI Platform offre i seguenti vantaggi:
- Puoi eseguirlo localmente o nel cloud in un ambiente distribuito.
- Offre connettività integrata ad altri prodotti Google, come Cloud Storage.
- Puoi eseguirlo utilizzando solo pochi comandi.
- Semplifica l'ottimizzazione degli iperparametri.
- Si adatta con modifiche minime all'infrastruttura, se presenti.
Affinché AI Platform possa addestrare e valutare un modello, devi fornire set di dati di addestramento, valutazione e test. Per creare i set di dati, esegui query SQL come quelle mostrate nella Parte 2 di questa serie. Poi esporta questi set di dati dalle tabelle BigQuery in Cloud Storage. Nell'architettura di produzione descritta in questo articolo, le query vengono eseguite da un DAG Airflow, descritto più dettagliatamente nella sezione Automazione di seguito. Puoi eseguire il DAG manualmente come descritto nella sezione Esegui DAG del file README.
Pubblicazione delle previsioni
Le previsioni possono essere create online o offline. Tuttavia, creare le previsioni è diverso dal pubblicarle. In questo contesto del CLV, eventi come un cliente che accede a un sito web o visita un negozio di vendita al dettaglio non incideranno drasticamente sul lifetime value del cliente. Pertanto, le previsioni possono essere eseguite offline, anche se i risultati potrebbero dover essere presentati in tempo reale. La previsione offline ha le seguenti funzionalità operative:
- Puoi eseguire gli stessi passaggi di pre-elaborazione sia per l'addestramento che per la previsione. Se l'addestramento e la previsione vengono pre-elaborate in modo diverso, le previsioni potrebbero essere meno accurate. Questo fenomeno è chiamato disallineamento addestramento/erogazione.
- Puoi utilizzare gli stessi strumenti per preparare i dati per l'addestramento e la previsione. L'approccio discusso in questa serie utilizza principalmente BigQuery per preparare i dati.
Puoi utilizzare AI Platform per eseguire il deployment del modello ed effettuare previsioni offline utilizzando un job batch. Per le previsioni, AI Platform semplifica attività come:
- Gestione delle versioni.
- Scalabilità con modifiche minime all'infrastruttura.
- Deployment su larga scala.
- Interazione con altri Google Cloud prodotti.
- Fornire un SLA.
L'attività di previsione batch utilizza i file archiviati su Cloud Storage sia per l'input che per l'output. Per il modello DNN, la seguente funzione di pubblicazione,
definita in task.py, definisce il formato degli input:
Il formato di output della previsione è definito in un EstimatorSpec restituito dalla funzione del modello Estimator in questo codice di model.py:
Utilizzare le previsioni
Dopo aver completato la creazione e il deployment dei modelli, puoi utilizzarli per eseguire previsioni sul CLV. Di seguito sono riportati alcuni casi d'uso comuni del CLV:
- Un esperto di dati può sfruttare le previsioni offline per creare segmenti di utenti.
- La tua organizzazione può fare offerte specifiche in tempo reale, quando un cliente interagisce con il tuo brand online o in un negozio.
Dati e analisi con BigQuery
Comprendere il CLV è fondamentale per le attivazioni. Questo articolo si concentra principalmente sul calcolo del lifetime value in base alle vendite precedenti. I dati sulle vendite provengono solitamente da strumenti di gestione dei rapporti con i clienti (CRM), ma le informazioni sul comportamento degli utenti possono avere altre origini, ad esempio Google Analytics 360.
Ti consigliamo di utilizzare BigQuery se ti interessa svolgere una delle seguenti attività:
- Memorizzazione di dati strutturati provenienti da molte origini.
- Trasferimento automatico dei dati da strumenti SaaS comuni come Google Analytics 360, YouTube o AdWords.
- Eseguire query ad hoc, inclusi join su terabyte di dati dei clienti.
- Visualizzazione dei dati mediante gli strumenti di business intelligence più avanzati.
Oltre al suo ruolo di motore di query e archiviazione gestito, BigQuery può eseguire algoritmi di machine learning direttamente utilizzando BigQuery ML. Caricando il valore CLV di ogni cliente in BigQuery, consente agli analisti, ai data scientist e ai data engineer di sfruttare metriche aggiuntive nelle loro attività. Il DAG Airflow discusso nella sezione successiva include un'attività per caricare le previsioni del CLV in BigQuery.
Pubblicazione a bassa latenza utilizzando Datastore
Le previsioni effettuate offline possono spesso essere riutilizzate per fornire previsioni in tempo reale. Per questo scenario, l'aggiornamento delle previsioni non è fondamentale, ma lo è l'accesso ai dati al momento giusto e in modo pratico.
Se memorizzi la previsione offline per la pubblicazione in tempo reale, le azioni intraprese da un cliente non cambieranno immediatamente il suo CLV. Tuttavia, è importante accedere rapidamente a questo CLV. Ad esempio, la tua azienda potrebbe voler reagire rapidamente quando un cliente utilizza il tuo sito web, fa una domanda all'help desk o effettua il pagamento tramite il tuo punto di vendita. In questi casi, una risposta rapida può migliorare il rapporto con i clienti. Pertanto, archiviare l'output della previsione in un database veloce e rendere disponibili query sicure per il frontend sono fattori chiave per il successo.
Supponiamo che tu abbia centinaia di migliaia di clienti unici. Datastore è una buona opzione per i seguenti motivi:
- Supporta i database di documenti NoSQL.
- Fornisce accesso rapido ai dati utilizzando una chiave (ID cliente), ma consente anche query SQL.
- È accessibile tramite un'API REST.
- È pronto per l'uso, il che significa che non è necessario alcun sovraccarico di configurazione.
- Si adatta automaticamente.
Poiché non è possibile caricare direttamente un set di dati CSV in Datastore, in questa soluzione utilizziamo Apache Beam su Dialogflow con un modello JavaScript per caricare le previsioni del CLV in Datastore. Il seguente snippet di codice del template JavaScript mostra come:
Quando i dati sono in Datastore, puoi scegliere come interagire con essi, ad esempio:
- Utilizza le librerie client Datastore dalla tua app.
- Creazione di un endpoint API utilizzando Cloud Endpoints o la piattaforma API Apigee.
- Utilizzo di funzioni Cloud Run per attività serverless.
Automatizzare la soluzione
I passaggi descritti finora vengono utilizzati quando inizi a utilizzare i dati per eseguire i primi passaggi di preelaborazione, addestramento e previsione. Tuttavia, la tua piattaforma non è ancora pronta per la produzione, perché hai ancora bisogno di automazione e gestione degli errori.
Alcuni script possono contribuire a unire i passaggi. Tuttavia, è buona prassi automatizzare i passaggi utilizzando un gestore dei flussi di lavoro. Apache Airflow è uno strumento di gestione del flusso di lavoro molto utilizzato e puoi utilizzare Cloud Composer per eseguire una pipeline Airflow gestita su Google Cloud.
Airflow funziona con i grafici diretti aciclici (DAG), che ti consentono di specificare ogni attività e la sua relazione con altre attività. Nell'approccio descritto in questa serie, esegui i seguenti passaggi:
- Creare set di dati BigQuery.
- Carica il set di dati pubblico da Cloud Storage in BigQuery.
- Pulisci i dati di una tabella BigQuery e scrivili in una nuova tabella BigQuery.
- Crea elementi in base ai dati di una tabella BigQuery e scrivili in un'altra tabella BigQuery.
- Se il modello è una rete neurale profonda (DNN), suddividi i dati in un set di addestramento e un set di valutazione in BigQuery.
- Esporta i set di dati in Cloud Storage e rendili disponibili per la piattaforma AI.
- Chiedi ad AI Platform di addestrare periodicamente il modello.
- Esegui il deployment del modello aggiornato in AI Platform.
- Esegui periodicamente una previsione batch sui nuovi dati.
- Salva le previsioni già salvate in Cloud Storage in Datastore e BigQuery.
Configurazione di Cloud Composer
Per informazioni su come configurare Cloud Composer, consulta le istruzioni nel file README del repository GitHub.
Grafi diretti aciclici per questa soluzione
Questa soluzione utilizza due DAG. Il primo DAG copre i passaggi da 1 a 8 della sequenza elencata in precedenza:
Il seguente diagramma mostra l'interfaccia utente di Cloud Composer/Airflow, che riassume i passaggi da 1 a 8 del DAG di Airflow.
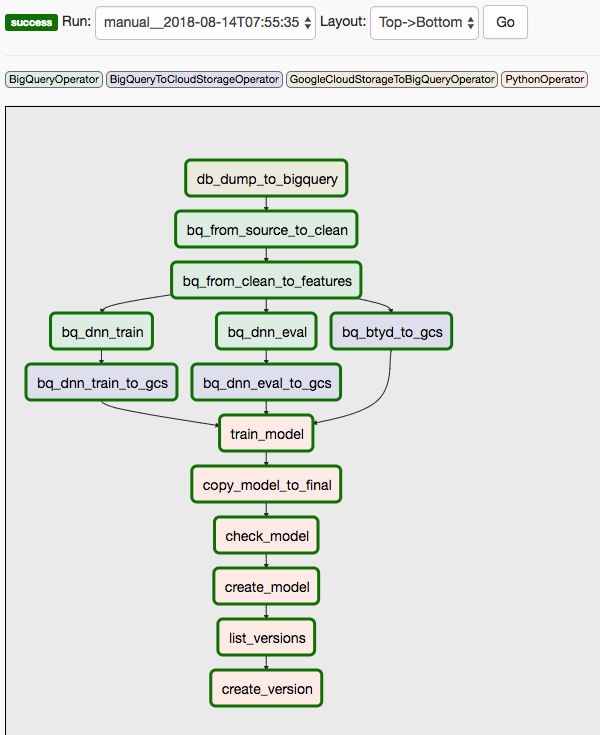
Il secondo DAG copre i passaggi 9 e 10.
Il seguente diagramma riassume i passaggi 9 e 10 del processo DAG di Airflow.
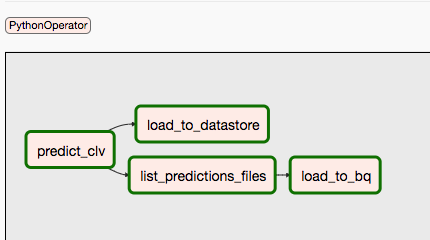
I DAG sono separati perché le previsioni e l'addestramento potrebbero avvenire in modo indipendente e con una pianificazione diversa. Ad esempio, potresti eseguire le seguenti operazioni:
- Prevedi quotidianamente i dati per i clienti nuovi o esistenti.
- Riaddestra il modello settimanalmente per incorporare nuovi dati o attivalo dopo la ricezione di un numero specifico di nuove transazioni.
Per attivare manualmente il primo DAG, puoi eseguire il comando dalla sezione Esegui DAG del file README in Cloud Shell o utilizzando l'interfaccia a riga di comando gcloud.
Il parametro conf passa le variabili a diverse parti dell'automazione. Ad esempio, nella seguente query SQL utilizzata per estrarre i componenti dai dati pulizia, le variabili vengono utilizzate per parametrizzare la clausola FROM:
Puoi attivare il secondo DAG utilizzando un comando simile. Per maggiori dettagli, consulta il file README nel repository GitHub.
Passaggi successivi
- Esegui l'esempio completo nel repository GitHub.
- Incorpora nuove funzionalità nel modello CLV utilizzando alcune delle seguenti opzioni:
- Dati sul clickstream, che possono aiutarti a prevedere il CLV per i clienti per i quali non hai dati storici.
- Reparti e categorie di prodotti che possono aggiungere un contesto aggiuntivo e che potrebbero essere utili alla rete neurale.
- Nuove funzionalità create utilizzando gli stessi input utilizzati in questa soluzione. Ad esempio, le tendenze di vendita per le ultime settimane o mesi prima della data di soglia.
- Leggi la Parte 4: Utilizza AutoML Tables per il modello.
- Scopri altre soluzioni di previsione predittiva.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.