Cet article présente différentes architectures offrant une haute disponibilité (HA) pour les déploiements PostgreSQL sur Google Cloud. La haute disponibilité est la mesure de la résilience du système en réponse à la défaillance d'une infrastructure sous-jacente. Dans ce document, la haute disponibilité fait référence à la disponibilité des clusters PostgreSQL au sein d'une même région cloud ou entre plusieurs régions, suivant le type d'architecture haute disponibilité choisi.
Ce document est destiné aux administrateurs de bases de données, aux architectes cloud et aux ingénieurs DevOps qui veulent apprendre comment renforcer la fiabilité au niveau des données PostgreSQL en améliorant le temps d'activité global du système. Ce document traite des concepts pertinents pour l'exécution de PostgreSQL sur Compute Engine. Il n'aborde pas l'utilisation de Cloud SQL pour PostgreSQL.
Pour les systèmes ou applications qui nécessitent un état persistant afin de gérer les requêtes ou les transactions, la couche de persistance des données doit être disponible pour un traitement correct des requêtes liées aux interrogations ou aux mutations de données. Les temps d'arrêt au niveau des données empêchent le système ou l'application d'effectuer les tâches nécessaires.
En fonction des objectifs de niveau de service (SLO) de votre système, vous pouvez avoir besoin d'une architecture capable de fournir un niveau de disponibilité plus élevé. Bien qu'il existe plusieurs façons d'obtenir la haute disponibilité, en règle générale, vous provisionnez une infrastructure redondante que vous pouvez rendre accessible rapidement à votre application.
Ce document traite des sujets suivants :
- Définition des termes liés aux concepts des bases de données à haute disponibilité.
- Options pour les topologies PostgreSQL à haute disponibilité.
- Informations contextuelles à prendre en compte pour chaque option d'architecture.
Terminologie
Les termes et concepts ci-dessous constituent des standards du secteur, et il est utile de les comprendre au-delà du cadre de ce document.
- réplication
-
Processus par lequel les transactions d'écriture (
INSERT,UPDATEouDELETE) et les modifications de schéma (instructions LDD (langage de définition de données)) sont capturées, journalisées, puis appliquées en série et en aval de manière fiable à tous les nœuds des instances dupliquées de base de données de l'architecture. - Nœud principal
- Nœud qui fournit un accès en lecture à l'état le plus récent des données persistantes. Toutes les écritures de base de données doivent être dirigées vers un nœud principal.
- Instance dupliquée (secondaire)
- Copie en ligne du nœud de base de données principal. Les modifications sont répliquées de manière synchrone ou asynchrone sur les nœuds d'instances dupliquées à partir du nœud principal. Il est possible de lire les données des nœuds d'instances dupliquées, sachant que les données peuvent être légèrement retardées en raison du délai avant réplication.
- Délai avant réplication
- Mesure, exprimée sous forme de numéro séquentiel dans le journal (LSN), d'ID de transaction ou d'heure. Le délai avant réplication exprime l'intervalle de temps entre le moment où des opérations de modification sont appliquées au nœud principal et celui où elles sont appliquées à l'instance dupliquée.
- Archivage continu
- Une sauvegarde incrémentielle dans laquelle la base de données enregistre en continu des transactions séquentielles dans un fichier.
- Journaux de transaction (journaux WAL ou "write ahead log")
- Un journal WAL (write-ahead log) est un fichier journal qui enregistre les modifications apportées aux fichiers de données avant qu'elles ne soient réellement apportées aux fichiers. En cas de plantage du serveur, le journal WAL est un moyen standard de garantir l'intégrité des données et la durabilité de vos écritures.
- Enregistrement WAL
- Enregistrement d'une transaction appliquée à la base de données. Un enregistrement WAL est mis en forme et stocké sous la forme d'une série d'enregistrements décrivant les modifications des fichiers de données au niveau des pages.
- Numéro séquentiel dans le journal (LSN)
- Les transactions créent des enregistrements WAL qui sont ajoutés au fichier WAL. La position de l'insertion s'appelle numéro de séquence de journal. Il s'agit d'un entier de 64 bits, représenté par deux nombres hexadécimaux séparés par une barre oblique (XXXXXXXX/YYZZZZZZ). "Z" représente la position de décalage dans le fichier WAL.
- Fichiers segments
- Fichiers contenant le plus d'enregistrements WAL possible, en fonction de la taille de fichier que vous configurez. Les noms des fichiers segments sont incrémentés de manière monotone et ont une taille de fichier par défaut de 16 Mo.
- Réplication synchrone
- Forme de réplication dans laquelle le serveur principal attend que l'instance dupliquée confirme l'écriture des données dans son journal de transactions avant d'envoyer la confirmation du commit au client. Lorsque vous exécutez la réplication par flux, vous pouvez utiliser l'option PostgreSQL
synchronous_commitpour configurer les garanties de cohérence. - Réplication asynchrone
- Forme de réplication dans laquelle le serveur principal n'attend pas que l'instance dupliquée confirme la réception de la transaction avant d'envoyer la confirmation du commit au client. La réplication asynchrone présente une latence inférieure à celle de la réplication synchrone. Toutefois, si le serveur principal subit un plantage et que ses transactions validées ne sont pas transférées vers l'instance dupliquée, il existe une possibilité de perte de données. La réplication asynchrone est le mode de réplication par défaut sur PostgreSQL, qui utilise soit l'envoi de journaux basé sur les fichiers, soit la réplication par flux.
- Envoi de journaux basé sur les fichiers
- Méthode de réplication dans PostgreSQL, qui transfère les fichiers segments WAL du serveur de base de données principal vers l'instance dupliquée. Le serveur principal fonctionne en mode d'archivage continu, tandis que chaque service de secours fonctionne en mode de récupération continue pour lire les fichiers WAL. Cette réplication est asynchrone.
- Réplication par flux
- Méthode de réplication dans laquelle l'instance dupliquée se connecte à l'instance principale et reçoit une séquence de modifications sous forme de flux continu. Comme les mises à jour arrivent via un flux, cette méthode permet de garder l'instance dupliquée plus à jour avec l'instance principale qu'avec la réplication par envoi de journaux. Bien que la réplication soit asynchrone par défaut, vous pouvez également configurer la réplication synchrone.
- Réplication par flux physique
- Méthode de réplication qui achemine les modifications vers l'instance dupliquée. Cette méthode utilise les enregistrements WAL contenant les modifications de données physiques sous la forme d'adresses de blocs de disque et de modifications octet par octet.
- Réplication par flux logique
- Méthode de réplication qui capture les modifications en fonction de leur identité de réplication (clé primaire), ce qui offre davantage de contrôle sur la réplication des données par rapport à la réplication physique. En raison de restrictions sur la réplication logique de PostgreSQL, cette dernière nécessite une configuration spéciale pour un environnement à haute disponibilité. Ce guide traite de la réplication physique standard et n'aborde pas la réplication logique.
- uptime
- Durée (en pourcentage) pendant laquelle une ressource est opérationnelle et capable de diffuser une réponse à une requête.
- Détection des défaillances
- Processus permettant d'identifier qu'une défaillance d'infrastructure s'est produite.
- failover
- Processus de promotion de l'infrastructure de sauvegarde ou de secours (dans ce cas, le nœud d'instance dupliquée) au rang d'infrastructure principale. Lors du basculement, le nœud d'instance dupliquée devient le nœud principal.
- Commutation (switchover)
- Processus d'exécution manuelle d'un basculement sur un système de production. Une commutation vérifie que le système fonctionne correctement ou retire le nœud principal actuel du cluster pour en effectuer la maintenance.
- Objectif de temps de récupération (RTO)
- Durée écoulée, en temps réel, du processus de basculement au niveau des données. Le RTO dépend du délai acceptable d'un point de vue métier.
- Objectif de point de récupération (RPO)
- Quantité de données perdues (en temps réel écoulé) subie au niveau des données à la suite d'un basculement. Le RPO dépend de la perte de données acceptable d'un point de vue métier.
- remplacement
- Processus de rétablissement de l'ancien nœud principal après résolution de la condition ayant déclenché le basculement.
- Autoréparation
- Capacité d'un système à résoudre les problèmes sans intervention externe d'un opérateur humain.
- Partition réseau
- Condition dans laquelle deux nœuds d'une architecture, par exemple le nœud principal et les instances dupliquées, ne peuvent pas communiquer entre eux sur le réseau.
- Split-brain
- Condition qui se produit lorsque deux nœuds croient simultanément qu'ils sont le nœud principal.
- Groupe de nœuds
- Ensemble de ressources de calcul qui fournissent un service. Dans ce document, ce service est le niveau de persistance des données.
- Nœud témoin ou de quorum
- Ressource de calcul distincte permettant à un groupe de nœuds de déterminer ce qu'il doit faire lorsqu'une condition de split-brain se produit.
- Élection du responsable ou nœud principal
- Processus selon lequel un groupe de nœuds en relation avec des nœuds similaires, y compris des nœuds témoins, détermine le nœud à utiliser comme nœud principal.
Quand choisir une architecture haute disponibilité ?
Les architectures haute disponibilité offrent une protection renforcée contre les temps d'arrêt au niveau des données par rapport aux configurations de base de données à nœud unique. Pour choisir l'option la plus adaptée à votre cas d'utilisation métier, vous devez connaître la tolérance aux temps d'arrêt et les compromis respectifs des différentes architectures.
Utilisez une architecture haute disponibilité lorsque vous souhaitez fournir une disponibilité accrue au niveau des données afin de répondre aux exigences de fiabilité de vos charges de travail et services. Si votre environnement tolère un certain nombre de temps d'arrêt, une architecture haute disponibilité peut engendrer un coût et une complexité inutiles. Par exemple, les environnements de développement ou de test ont rarement besoin de la haute disponibilité au niveau de la base de données.
Évaluer les exigences liées à la haute disponibilité
Voici quelques questions pour vous aider à choisir l'option PostgreSQL haute disponibilité la plus adaptée à vos besoins métier :
- Quel niveau de disponibilité espérez-vous atteindre ? Avez-vous besoin d'une option permettant à votre service de continuer à fonctionner en cas de défaillance d'une zone unique ou de défaillance régionale complète ? Certaines options de haute disponibilité sont limitées à une région, tandis que d'autres peuvent être multirégionales.
- Quels services ou clients dépendent de votre niveau de données, et quel est le coût pour votre entreprise en cas de temps d'arrêt au niveau de persistance des données ? Si un service s'adresse uniquement à des clients internes qui n'utilisent le système que de manière occasionnelle, il présente probablement des exigences de disponibilité inférieures à celles d'un service devant assurer une diffusion continue à destination de client finaux.
- Quel est votre budget opérationnel ? Le coût est un critère important : pour offrir une haute disponibilité, vos coûts d'infrastructure et de stockage sont susceptibles d'augmenter.
- À quel point le processus doit-il être automatisé et avec quelle rapidité le basculement doit-il s'effectuer ? (Quel est votre objectif de temps de récupération (RTO) ?) Les options de haute disponibilité se différencient suivant la rapidité avec laquelle le système peut basculer et être disponible pour les clients.
- Est-il acceptable de perdre des données à la suite du basculement ? (Quel est votre RPO ?) En raison de la nature distribuée des topologies à haute disponibilité, il existe un compromis entre la latence de commit et le risque de perte de données due à une défaillance.
Fonctionnement de la haute disponibilité
Cette section décrit la réplication par flux et la réplication par flux synchrone qui sous-tendent les architectures PostgreSQL haute disponibilité.
Réplication par flux
La réplication par flux constitue une approche de réplication dans laquelle l'instance dupliquée se connecte à l'instance principale et reçoit en continu un flux d'enregistrements WAL. Par rapport à la réplication par envoi de journaux, la réplication par flux permet de garder l'instance dupliquée plus à jour avec l'instance principale. PostgreSQL offre une réplication par flux intégrée à partir de la version 9. De nombreuses solutions PostgreSQL à haute disponibilité utilisent la réplication par flux intégrée pour fournir le mécanisme de synchronisation de plusieurs nœuds d'instances dupliquées PostgreSQL avec l'instance principale. Plusieurs de ces options sont décrites dans la section Architectures PostgreSQL haute disponibilité plus loin dans ce document.
Chaque nœud d'instance dupliquée nécessite des ressources de calcul et de stockage dédiées. L'infrastructure des nœuds d'instances dupliquées est indépendante de l'infrastructure principale. Vous pouvez utiliser des nœuds d'instances dupliquées en tant qu'instances de secours à chaud ("hot standby") pour diffuser des requêtes client en lecture seule. Cette approche permet l'équilibrage de charge pour les requêtes en lecture seule entre l'instance principale et une ou plusieurs instances dupliquées.
La réplication par flux est par défaut asynchrone. L'instance principale n'attend pas de confirmation de la part d'une instance dupliquée avant de confirmer le commit d'une transaction au client. Si une instance principale subit une défaillance après avoir confirmé la transaction, mais avant qu'une instance dupliquée ne reçoive effectivement la transaction, la réplication asynchrone peut entraîner une perte de données. Si l'instance dupliquée est promue en tant que nouvelle instance principale, cette transaction n'y figure pas.
Réplication par flux synchrone
Vous pouvez configurer la réplication par flux en mode synchrone en définissant une ou plusieurs instances dupliquées en tant qu'instances de secours synchrones. Si vous configurez votre architecture pour la réplication synchrone, l'instance principale ne confirme pas le commit d'une transaction tant que l'instance dupliquée n'a pas elle même confirmé la persistance de la transaction. La réplication par flux synchrone offre une durabilité accrue en contrepartie d'une latence de transaction plus élevée.
L'option de configuration synchronous_commit vous permet également de configurer les garanties de durabilité progressive suivantes pour la transaction :
on[par défaut] : les instances dupliquées de secours synchrones écrivent les transactions validées dans leurs journaux WAL avant d'envoyer une confirmation à l'instance principale. L'utilisation de la configurationongarantit que la transaction ne peut être perdue que si l'instance principale et toutes les instances dupliquées de secours synchrones ont subi des défaillances de stockage simultanées. Étant donné que les instances dupliquées n'envoient leur confirmation qu'après avoir écrit leurs enregistrements WAL, les clients qui interrogent une instance dupliquée ne verront pas les modifications avant l'application effective des enregistrements WAL respectifs à la base de données dupliquée.remote_write: les instances dupliquées de secours synchrones confirment la réception de l'enregistrement WAL au niveau du système d'exploitation, mais ne garantissent pas que l'enregistrement WAL a bien été écrit sur le disque. Commeremote_writene garantit pas que l'enregistrement WAL a bien été écrit, la transaction peut être perdue en cas de défaillance à la fois sur le serveur principal et sur le serveur secondaire survenant avant l'écriture des enregistrements. La durabilité deremote_writeest inférieure à celle de l'optionon.remote_apply: les instances dupliquées de secours synchrones confirment la réception de la transaction et le succès de son application à la base de données avant de confirmer le commit de la transaction au client. L'utilisation de la configurationremote_applygarantit que la transaction est conservée dans l'instance dupliquée et que les résultats d'une requête client incluent immédiatement les effets de la transaction.remote_applyoffre une durabilité et une cohérence supérieures à celles des optionsonetremote_write.
Architectures PostgreSQL haute disponibilité
Au niveau le plus élémentaire, la haute disponibilité du niveau de données comprend les éléments suivants :
- Un mécanisme permettant de déterminer qu'une défaillance du nœud principal s'est produite
- Un processus permettant d'effectuer un basculement où le nœud d'instance dupliquée est promu au rang de nœud principal
- Un processus permettant de modifier le routage des requêtes afin que les requêtes d'application atteignent le nouveau nœud principal
- Éventuellement, une méthode permettant de revenir à l'architecture d'origine à l'aide des nœuds principal et d'instances dupliquées dans leur capacité d'origine et leur état avant le basculement.
Les sections ci-dessous présentent les architectures haute disponibilité suivantes :
- Le modèle Patroni
- L'extension et le service pg_auto_failover
- MIG avec état et disque persistant régional
Ces solutions à haute disponibilité minimisent les temps d'arrêt en cas de panne d'infrastructure ou d'interruption zonale. Lorsque vous faites votre choix entre ces options, recherchez un équilibre entre la latence des commits et la durabilité en fonction de vos besoins métier.
Un aspect essentiel d'une architecture de haute disponibilité est le temps et les efforts manuels nécessaires à la préparation d'un nouvel environnement de secours pour le basculement ou le remplacement ultérieur. Sinon, le système ne peut faire face qu'à une seule défaillance, et le service n'est pas protégé contre une violation du contrat de niveau de service. Nous vous recommandons de sélectionner une architecture haute disponibilité permettant d'effectuer des basculements manuels (commutations) avec l'infrastructure de production.
Haute disponibilité à l'aide du modèle Patroni
Patroni est un modèle logiciel Open Source (sous licence MIT), éprouvé et activement géré, qui fournit des outils permettant de configurer, déployer et exploiter une architecture PostgreSQL haute disponibilité. Patroni fournit un état de cluster partagé et une configuration d'architecture conservée dans un magasin de configurations distribué (DCS). Les options de mise en œuvre d'un magasin DCS incluent : etcd, Consul, Apache ZooKeeper ou Kubernetes. Le diagramme suivant illustre les principaux composants d'un cluster Patroni.
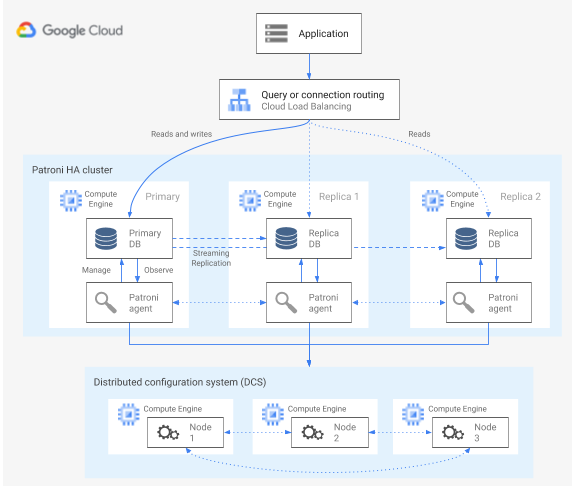
Figure 1 : Diagramme des principaux composants d'un cluster Patroni.
Dans la figure 1, les équilibreurs de charge sont devant les nœuds PostgreSQL, tandis que le magasin DCS et les agents Patroni fonctionnent sur les nœuds PostgreSQL.
Patroni exécute un processus d'agent sur chaque nœud PostgreSQL. Le processus d'agent gère le processus PostgreSQL et la configuration du nœud de données. L'agent Patroni se coordonne avec les autres nœuds via le magasin DCS. Le processus de l'agent Patroni expose également une API REST que vous pouvez interroger pour déterminer l'état et la configuration du service PostgreSQL pour chaque nœud.
Pour valider son rôle de membre du cluster, le nœud principal met régulièrement à jour la clé de responsable dans le magasin DCS. La clé de responsable inclut une valeur TTL (Time To Live). Si la valeur TTL s'écoule sans qu'il y ait de mise à jour, la clé de responsable est évincée du magasin DCS et cela déclenche l'élection d'un responsable afin de sélectionner un nouveau nœud principal parmi le pool de candidats.
Le diagramme suivant illustre un cluster opérationnel dans lequel le nœud A met à jour avec succès le verrou de responsable.
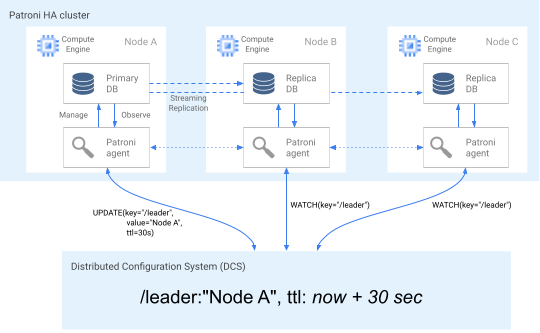
Figure 2. Diagramme d'un cluster opérationnel.
La figure 2 illustre un cluster opérationnel : le nœud B et le nœud C observent tandis que le nœud A a mis à jour avec succès la clé de responsable.
Détection des défaillances
L'agent Patroni transmet continuellement son état de fonctionnement en mettant à jour sa clé dans le magasin DCS. En parallèle, l'agent valide l'état de fonctionnement de PostgreSQL. Si l'agent détecte un problème, il cloisonne le nœud en s'arrêtant lui-même ou il rétrograde le nœud en le passant au statut d'instance dupliquée. Comme le montre le diagramme suivant, si le nœud perturbé est le nœud principal, sa clé de responsable stockée dans le magasin DCS expire et l'élection d'un nouveau responsable se produit.
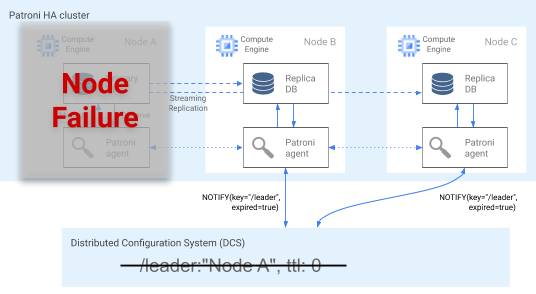
Figure 3. Diagramme d'un cluster perturbé.
La figure 3 illustre un cluster perturbé : un nœud principal en panne n'a pas récemment mis à jour sa clé de responsable dans le magasin DCS, et les instances dupliquées non principales sont informées que la clé de responsable est arrivée à expiration.
Sur les hôtes Linux, Patroni exécute également un watchdog au niveau du système d'exploitation sur les nœuds principaux. Ce watchdog écoute les messages keep-alive émanant du processus de l'agent Patroni. Si le processus ne répond pas et que le message keep-alive n'est pas envoyé, le watchdog redémarre l'hôte. Le watchdog permet d'éviter une condition de split-brain dans laquelle le nœud PostgreSQL continue de jouer le rôle de nœud principal, tandis que la clé de responsable figurant dans le magasin DCS a expiré en raison de la défaillance de l'agent et qu'un autre nœud principal (responsable) a été élu.
Processus de basculement
Si le verrou de responsable expire dans le magasin DCS, les nœuds des instances dupliquées candidates entament l'élection d'un responsable. Lorsqu'une instance dupliquée découvre l'absence d'un verrou de responsable, elle compare sa position de réplication à celles des autres instances dupliquées. Chaque instance dupliquée utilise l'API REST pour obtenir les positions des journaux WAL des autres nœuds d'instance dupliquée, comme indiqué dans le diagramme suivant.
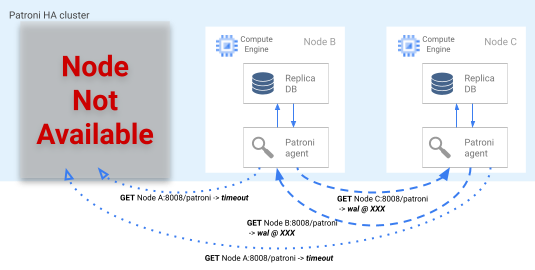
Figure 4. Diagramme du processus de basculement de Patroni.
La figure 4 illustre les requêtes de position des journaux WAL et les résultats respectifs provenant des nœuds d'instances dupliquées actifs. Le nœud A n'est pas disponible, et les nœuds opérationnels B et C se renvoient la même position WAL l'un à l'autre.
Le nœud le plus à jour (ou les nœuds, s'ils se trouvent à la même position) tente simultanément d'obtenir le verrou de responsable dans le magasin DCS. Cependant, un seul nœud peut créer la clé de responsable dans le magasin DCS. Le premier nœud à créer avec succès la clé de responsable est le gagnant de l'élection du responsable, comme illustré dans le diagramme suivant.
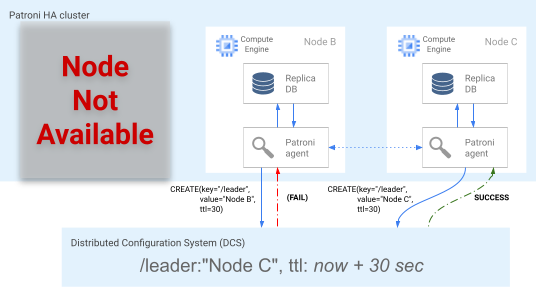
Figure 5. Diagramme de l'élection du responsable.
La figure 5 illustre l'élection d'un responsable : deux candidats responsables tentent d'obtenir le verrou de responsable, mais seul l'un des deux nœuds, le nœud C, parvient à définir la clé de responsable et remporte l'élection.
Une fois l'élection remportée, l'instance dupliquée se promeut en tant que nouvelle instance principale. À partir du moment où l'instance dupliquée se promeut elle-même, la nouvelle instance principale met à jour la clé de responsable dans le magasin DCS afin de conserver le verrou de responsable, et les autres nœuds servent alors d'instances dupliquées.
Patroni fournit également l'outil de contrôle patronictl qui vous permet d'exécuter manuellement des commutations pour tester le processus de basculement de nœud. Cet outil permet aux opérateurs de tester leurs configurations de haute disponibilité en production.
Routage des requêtes
Le processus d'agent Patroni qui s'exécute sur chaque nœud expose des points de terminaison de l'API REST révélant le rôle actuel du nœud : instance principale ou instance dupliquée.
| Point de terminaison REST | Code de retour HTTP s'il s'agit de l'instance principale | Code de retour HTTP s'il s'agit d'une instance dupliquée |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
Étant donné que les vérifications d'état pertinentes modifient leur réponse si un nœud spécifique change de rôle, une vérification d'état effectuée par l'équilibreur de charge peut exploiter ces points de terminaison pour optimiser le routage du trafic du nœud principal et des instances répliquées. Le projet Patroni fournit des configurations de modèle pour l'équilibreur de charge proxy haute disponibilité. L'équilibreur de charge réseau interne passthrough peut utiliser ces mêmes vérifications d'état pour fournir des fonctionnalités similaires.
Processus de remplacement
En cas de défaillance d'un nœud, un cluster se trouve dans un état dégradé. Le processus de remplacement de Patroni permet de restaurer un cluster haute disponibilité dans un état sain après un basculement. Le processus de remplacement gère le retour du cluster à son état d'origine en initialisant automatiquement le nœud affecté en tant qu'instance dupliquée du cluster.
Par exemple, un nœud peut redémarrer en raison d'une défaillance du système d'exploitation ou de l'infrastructure sous-jacente. S'il s'agit du nœud principal et que son redémarrage prend plus de temps que défini par la valeur TTL de la clé de responsable, l'élection d'un responsable est déclenchée, et un nouveau nœud principal est sélectionné et promu. Lorsque le processus Patroni principal obsolète démarre, il détecte qu'il ne possède pas le verrou de responsable, se rétrograde automatiquement et rejoint le cluster au rang d'instance dupliquée.
En cas de défaillance irrécupérable d'un nœud, telles qu'une défaillance de zone peu probable, vous devez démarrer un nouveau nœud. Un opérateur de base de données peut démarrer manuellement un nouveau nœud, ou vous pouvez utiliser un groupe d'instances géré régional avec état (MIG) doté d'un nombre minimal de nœuds afin d'automatiser le processus. Une fois le nouveau nœud créé, Patroni détecte qu'il fait partie d'un cluster existant et l'initialise automatiquement en tant qu'instance dupliquée.
Haute disponibilité à l'aide de l'extension et du service pg_auto_failover
pg_auto_failover est une extension PostgreSQL Open Source (sous licence PostgreSQL) activement développée. pg_auto_failover configure une architecture haute disponibilité en développant les capacités PostgreSQL existantes. pg_auto_failover ne présente aucune dépendance autre que PostgreSQL.
Pour utiliser l'extension pg_auto_failover avec une architecture haute disponibilité, vous avez besoin d'au moins trois nœuds, chacun exécutant PostgreSQL avec l'extension activée. Tous les nœuds peuvent subir une défaillance sans que cela n'affecte le temps d'activité du groupe de bases de données. Un ensemble de nœuds gérés par pg_auto_failover est appelé formation. Le diagramme suivant illustre une architecture pg_auto_failover.
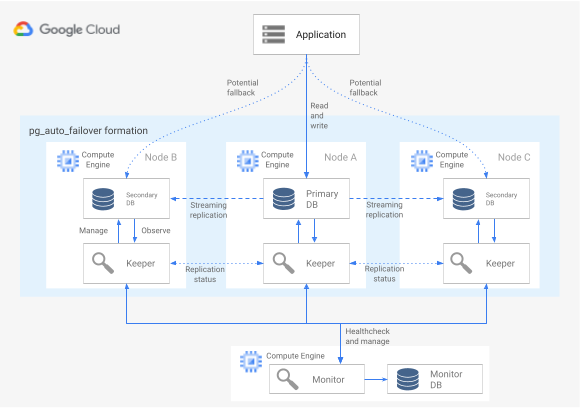
Figure 6. Diagramme d'une architecture pg_auto_failover.
La figure 6 présente une architecture pg_auto_failover constituée de deux composants principaux : le service Monitor et l'agent Keeper. Les outils "Keeper" et "Monitor" sont tous deux contenus dans l'extension pg_auto_failover.
Service Monitor
Le service pg_auto_failover Monitor est mis en œuvre en tant qu'extension PostgreSQL. Lorsque le service crée un nœud Monitor, il démarre une instance PostgreSQL avec l'extension pg_auto_failover activée. Monitor surveille l'état global de la formation, obtient le résultat des vérifications de l'état à partir des nœuds de données PostgreSQL membres, et orchestre le groupe à l'aide des règles établies par un automate fini (finite state machine, FSM). Conformément aux règles FSM concernant les transitions d'état, Monitor transmet des instructions aux nœuds du groupe pour les actions telles que la promotion, la rétrogradation et les modifications de configuration.
Agent Keeper
Sur chaque nœud de données pg_auto_failover, l'extension démarre un processus d'agent Keeper. Ce processus Keeper observe et gère le service PostgreSQL. Le processus Keeper envoie des mises à jour d'état au nœud Monitor, et reçoit et exécute les actions que Monitor envoie en réponse.
Par défaut, pg_auto_failover configure tous les nœuds de données secondaires du groupe en tant qu'instances dupliquées synchrones. Le nombre d'instances dupliquées synchrones requis pour un commit dépend de la configuration number_sync_standby que vous avez définie dans Monitor.
Détection des défaillances
Les agents Keeper exécutés sur les nœuds de données principal et secondaires se connectent de manière périodique au nœud Monitor afin de communiquer leur état actuel et de vérifier s'il y a des actions à exécuter. Le nœud Monitor se connecte également aux nœuds de données pour effectuer des vérifications d'état en exécutant des appels d'API du protocole PostgreSQL (libpq), qui imitent l'application cliente PostgreSQL pg_isready(). Si aucune de ces actions n'aboutit dans un certain délai (par défaut, 30 secondes), le nœud Monitor détermine qu'une défaillance du nœud de données a eu lieu. Vous pouvez modifier les paramètres de configuration PostgreSQL afin de personnaliser le délai de surveillance et le nombre de nouvelles tentatives. Pour plus d'informations, consultez la section Basculement et tolérance aux pannes.
En cas de défaillance d'un nœud unique, l'une des affirmations suivantes est vraie :
- Si le nœud de données non opérationnel est un nœud principal, Monitor déclenche un basculement.
- Si le nœud de données non opérationnel est un nœud secondaire, Monitor désactive la réplication synchrone pour ce nœud non opérationnel.
- Si le nœud défaillant est le nœud Monitor, le basculement automatique n'est pas possible. Pour éviter ce point de défaillance unique, vous devez vous assurer d'avoir mis en place un service de surveillance et une procédure de reprise après sinistre adéquats.
Le diagramme suivant illustre les scénarios de défaillance et les états de formation résultants décrits dans la liste précédente.
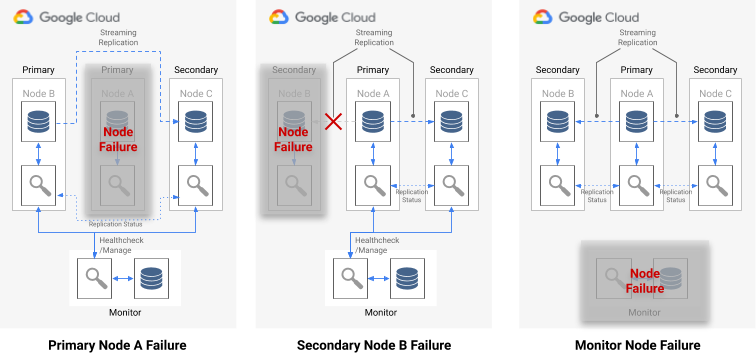
Figure 7. Diagramme des scénarios de défaillance pg_auto_failover.
Processus de basculement
Chaque nœud de base de données du groupe possède les options de configuration suivantes, qui déterminent le processus de basculement :
replication_quorum: option booléenne. Sireplication_quorumest défini surtrue, le nœud est considéré comme candidat potentiel pour le basculement.candidate_priority: valeur entière comprise entre 0 et 100.candidate_prioritya une valeur par défaut de 50 que vous pouvez modifier pour affecter la priorité de basculement. La priorité des nœuds en tant que candidats potentiels pour le basculement est basée sur la valeurcandidate_priority. Les nœuds dont la valeurcandidate_priorityest plus élevée ont également une priorité plus élevée. Le processus de basculement nécessite que, dans n'importe quelle formation pg_auto_failover, il existe au moins deux nœuds avec une priorité de candidat non nulle.
En cas de défaillance du nœud principal, les nœuds secondaires sont considérés pour être promus en tant qu'instance principale s'ils présentent une réplication synchrone active et s'ils sont membres de replication_quorum.
Les nœuds secondaires sont pris en compte pour la promotion en fonction des critères progressifs suivants :
- Nœuds ayant la priorité de candidat la plus élevée
- Nœuds de secours ayant la position de journal WAL la plus avancée publiée dans Monitor
- Sélection aléatoire pour départager les candidats en dernier recours
Un candidat au basculement est un candidat en retard lorsqu'il n'a pas publié la position LSN la plus avancée dans le journal WAL. Dans ce scénario, pg_auto_failover orchestre une étape intermédiaire dans le mécanisme de basculement : le candidat en retard récupère les octets WAL manquants à partir d'un nœud de secours ayant une position LSN plus avancée. Le nœud de secours est ensuite promu. Postgres autorise cette opération, car la réplication en cascade permet à toute instance de secours d'agir en tant que nœud en amont pour une autre instance de secours.
Routage des requêtes
pg_auto_failure ne fournit aucune fonctionnalité de routage des requêtes côté serveur.
Au lieu de cela, pg_auto_failure repose sur le routage des requêtes côté client qui utilise le pilote client PostgreSQL officiel libpq.
Lorsque vous définissez l'URI de connexion, le pilote peut accepter plusieurs hôtes dans son mot clé host.
La bibliothèque cliente utilisée par votre application doit soit encapsuler libpq, soit mettre en œuvre la possibilité de fournir plusieurs hôtes afin que l'architecture soit compatible avec un basculement entièrement automatisé.
Processus de remplacement et de basculement
Lorsque le processus Keeper redémarre un nœud défaillant ou démarre un nouveau nœud de remplacement, il vérifie le nœud Monitor pour déterminer la prochaine action à effectuer. Si un nœud ayant redémarré après avoir subi une défaillance était auparavant le nœud principal, et que l'outil Monitor a déjà choisi un nouveau nœud principal en suivant le processus de basculement, l'agent Keeper réinitialise alors cette instance principale obsolète en tant qu'instance dupliquée secondaire.
pg_auto_failure fournit l'outil pg_autoctl, qui vous permet d'exécuter manuellement des commutations pour tester le processus de basculement de nœud. En plus de permettre aux opérateurs de tester leurs configurations haute disponibilité en production, l'outil vous aide à restaurer un cluster haute disponibilité dans un état sain après un basculement.
Haute disponibilité à base de MIG avec état et de disques persistants régionaux
Cette section décrit une approche de la haute disponibilité qui utilise les composants Google Cloud suivants :
- Disque persistant régional Lorsque vous utilisez des disques persistants régionaux, les données sont répliquées de manière synchrone entre deux zones d'une région. Vous n'avez donc pas besoin d'utiliser la réplication par flux. Cependant, la haute disponibilité est limitée à exactement deux zones d'une même région.
- Groupes d'instances gérés avec état. Dans le cadre d'un plan de contrôle, une paire de MIG avec état est utilisée pour assurer l'exécution d'un nœud principal PostgreSQL principal. Lorsque le MIG avec état démarre une nouvelle instance, il peut associer le disque persistant régional existant. À tout moment, seul un des MIG a une instance en cours d'exécution.
- Cloud Storage. Un objet présent dans un bucket Cloud Storage contient une configuration indiquant dans quel MIG s'exécute le nœud de base de données principal et dans quel MIG le nœud de basculement doit être créé.
- Vérifications d'état et autoréparation du MIG. La vérification d'état surveille l'état de l'instance. Si le nœud en cours d'exécution devient non opérationnel, la vérification d'état lance le processus d'autoréparation.
- Journalisation. Lorsque l'autoréparation arrête le nœud principal, une entrée est enregistrée dans le journal. Les entrées de journal pertinentes sont exportées vers un sujet de récepteur Pub/Sub à l'aide d'un filtre.
- Fonctions Cloud basées sur des événements. Le message Pub/Sub déclenche Cloud Functions. Cloud Functions utilise la configuration Cloud Storage pour déterminer les actions à effectuer pour chaque MIG avec état.
- Équilibreur de charge réseau interne à stratégie directe. L'équilibreur de charge assure le routage vers l'instance en cours d'exécution dans le groupe. Cela garantit qu'une modification de l'adresse IP d'instance causée par la recréation de l'instance est transparente pour le client.
Le diagramme suivant illustre un exemple de haute disponibilité à base de MIG avec état et de disques persistants régionaux :

Figure 8. Diagramme de système haute disponibilité à base de MIG avec état et de disques persistants régionaux
La figure 8 montre un nœud principal opérationnel diffusant le trafic client. Les clients se connectent à l'adresse IP statique de l'équilibreur de charge réseau interne à stratégie directe. L'équilibreur de charge achemine les requêtes des clients vers la VM qui est actuellement en cours d'exécution dans le cadre du MIG. Les volumes de données sont stockés sur des disques persistants régionaux installés.
Pour mettre en œuvre cette approche, créez une image de VM sur laquelle PostgreSQL démarre à l'initialisation, qui servira de modèle d'instance pour le groupe d'instances géré. Vous devez également configurer sur le nœud une vérification d'état basée sur HTTP, telle que pgDoctor. Une vérification d'état basée sur HTTP permet de s'assurer que l'équilibreur de charge et le groupe d'instances sont en mesure de déterminer l'état du nœud PostgreSQL.
Disque persistant régional
Pour provisionner un périphérique de stockage par blocs offrant une réplication de données synchrone entre deux zones d'une région, vous pouvez utiliser l'option de stockage de disque persistant régional de Compute Engine. Un disque persistant régional peut constituer un composant de base essentiel pour la mise en œuvre d'une option PostgreSQL haute disponibilité qui ne repose pas sur la réplication par flux intégrée à PostgreSQL.
Si l'instance de VM de votre nœud principal devient indisponible en raison d'une défaillance de l'infrastructure ou d'une panne de zone, vous pouvez forcer l'association du disque persistant régional à une instance de VM située dans votre zone de sauvegarde de la même région.
Pour associer le disque persistant régional à une instance de VM dans votre zone de sauvegarde, vous pouvez effectuer l'une des opérations suivantes :
- Gardez une instance de VM de secours à froid dans la zone de sauvegarde. Une instance de VM de secours à froid est une instance de VM arrêtée qui ne comporte aucun disque persistant régional installé, mais qui est identique à l'instance de VM du nœud principal. En cas de défaillance, la VM de secours à froid est démarrée et le disque persistant régional y est installé. L'instance de secours à froid et l'instance de nœud principal disposent des mêmes données.
- Créez une paire de MIG avec état en utilisant le même modèle d'instance. Les MIG fournissent des vérifications de l'état et sont diffusés dans le cadre du plan de contrôle. En cas de défaillance du nœud principal, une instance de basculement est créée dans le MIG cible de manière déclarative. Le MIG cible est défini dans l'objet Cloud Storage. Une configuration par instance est utilisée pour associer le disque persistant régional.
Si la panne du service de données est rapidement identifiée, l'opération d'association forcée prend généralement moins d'une minute, ce qui permet d'atteindre un RTO de l'ordre de quelques minutes.
Si votre entreprise peut tolérer le temps d'arrêt supplémentaire nécessaire pour détecter une panne, la communiquer et effectuer le basculement manuellement, il n'est pas nécessaire d'automatiser le processus d'association forcée. Si votre tolérance en termes de RTO est inférieure, vous pouvez automatiser le processus de détection et de basculement. Cloud SQL pour PostgreSQL offre également une mise en œuvre entièrement gérée de cette approche à haute disponibilité.
Processus de détection des pannes et de basculement
L'approche haute disponibilité utilise les capacités d'autoréparation des groupes d'instances pour surveiller l'état des nœuds à l'aide d'une vérification d'état. En cas d'échec de la vérification d'état, l'instance existante est considérée comme non opérationnelle et est arrêtée. Cet arrêt lance le processus de basculement à l'aide de Logging, Pub/Sub et de la fonction Cloud Functions déclenchée.
Pour qu'un disque régional soit systématiquement monté sur la VM, l'un des deux MIG sera configuré par Cloud Functions pour créer une instance dans l'une des deux zones où le disque persistant régional est disponible. En cas de défaillance d'un nœud, l'instance de remplacement est démarrée dans la zone secondaire en se basant sur l'état persistant dans Cloud Storage.

Figure 9 : Diagramme d'une défaillance de zone dans un groupe d'instances géré.
Dans la figure 9, l'ancien nœud principal de la zone A a subi une défaillance et Cloud Functions a configuré le MIG B pour lancer une nouvelle instance principale dans la zone B. Le mécanisme de détection des défaillances est automatiquement configuré pour surveiller l'état du nouveau nœud principal.
Routage des requêtes
L'équilibreur de charge réseau interne à stratégie directe achemine les clients vers l'instance qui exécute le service PostgreSQL. L'équilibreur de charge utilise la même vérification d'état que le groupe d'instances afin de déterminer si l'instance est disponible pour diffuser des requêtes. Si le nœud n'est pas disponible en raison de sa recréation, les connexions échouent. Une fois l'instance redémarrée, les vérifications d'état commencent à réussir et les nouvelles connexions sont acheminées vers le nœud disponible. Cette configuration ne comporte aucun nœud en lecture seule, car il n'y a qu'un seul nœud en cours d'exécution.
Processus de remplacement
Si le nœud de base de données échoue à une vérification de l'état en raison d'un problème matériel sous-jacent, le nœud est recréé sur une autre instance sous-jacente. À ce stade, l'architecture revient à son état d'origine sans aucune étape supplémentaire. Toutefois, en cas de défaillance d'une zone, la configuration continue à s'exécuter dans un état dégradé jusqu'à récupération complète de la première zone. Bien que ce risque soit très faible, en cas de défaillance simultanée dans les deux zones configurées pour la réplication de disque persistant régional et le MIG avec état, l'instance PostgreSQL ne peut pas être récupérée et la base de données n'est pas disponible pour répondre aux requêtes pendant la durée de la panne.
Comparaison des options de haute disponibilité
Les tableaux suivants comparent les options de haute disponibilité proposées par Patroni, pg_auto_failover et les MIG avec état avec des disques persistants régionaux.
Configuration et architecture
| Patroni | pg_auto_failover | MIG avec état et disques persistants régionaux |
|---|---|---|
|
Nécessite une architecture à haute disponibilité, une configuration DCS, ainsi qu'une surveillance et des alertes. La configuration de l'agent sur des nœuds de données est relativement simple. |
Aucune dépendance externe autre que PostgreSQL n'est requise. Nécessite un nœud dédié au service de surveillance. Le nœud de surveillance requiert la haute disponibilité et une reprise après sinistre pour s'assurer qu'il ne représente pas un point de défaillance unique (SPOF). | Architecture comprenant exclusivement des services Google Cloud. Vous n'exécutez qu'un seul nœud de base de données actif à la fois. |
Configurabilité de la haute disponibilité
| Patroni | pg_auto_failover | MIG avec état et disques persistants régionaux |
|---|---|---|
| Extrêmement configurable : accepte la réplication synchrone et asynchrone, et vous permet de spécifier les nœuds qui doivent être synchrones et asynchrones. Inclut la gestion automatique des nœuds synchrones. Autorise les configurations haute disponibilité à zones multiples et multirégionales. Le magasin DCS doit être accessible. | Semblable à Patroni : très configurable. Toutefois, étant donné que l'outil Monitor n'est disponible que sous la forme d'une instance unique, tout type de configuration doit prendre en compte l'accès à ce nœud. | Limité à deux zones d'une même région avec réplication synchrone. |
Capacité à gérer une partition réseau
| Patroni | pg_auto_failover | MIG avec état et disques persistants régionaux |
|---|---|---|
| L'auto-cloisonnement accompagné d'une surveillance au niveau du système d'exploitation offre une protection contre les situations de split-brain. Tout échec de connexion au magasin DCS entraîne l'auto-rétrogradation de l'instance principale au rang d'instance dupliquée, puis le déclenchement d'un basculement visant à privilégier la durabilité plutôt que la disponibilité. | Utilise une combinaison de vérifications d'état allant de l'instance principale au service Monitor et à l'instance dupliquée, afin de détecter une partition réseau, et se rétrograde si nécessaire. | Non applicable : comme il n'existe qu'un seul nœud PostgreSQL actif à la fois, il n'y a donc pas de partition réseau. |
Configuration du client
| Patroni | pg_auto_failover | MIG avec état et disques persistants régionaux |
|---|---|---|
| Transparent pour le client, car celui-ci se connecte à un équilibreur de charge. | Nécessite une bibliothèque cliente pour prendre en charge plusieurs définitions d'hôtes dans la configuration, car le système ne peut pas s'interfacer facilement avec un équilibreur de charge. | Transparent pour le client, car celui-ci se connecte à un équilibreur de charge. |
Automatisation de l'initialisation des nœuds PostgreSQL, gestion de la configuration
| Patroni | pg_auto_failover | MIG avec état et disques persistants régionaux |
|---|---|---|
Fournit des outils permettant de gérer la configuration PostgreSQL (patronictl
edit-config) et initialise automatiquement les nouveaux nœuds ou les nœuds redémarrés dans le cluster. Vous pouvez initialiser les nœuds à l'aide de pg_basebackup ou d'autres outils tels que WALL-E et barman.
|
Initialisation automatique des nœuds, mais limitée à l'utilisation de pg_basebackup lors de l'initialisation d'un nouveau nœud d'instance dupliquée.
La gestion de la configuration est limitée aux configurations liées à pg_auto_failover.
|
Un groupe d'instances avec état et avec disque partagé élimine tout besoin d'initialisation de nœud PostgreSQL. Comme il n'y a qu'un seul nœud en cours d'exécution à la fois, la gestion de la configuration se fait sur un seul nœud. |
Personnalisation et éventail de fonctionnalités
| Patroni | pg_auto_failover | MIG avec état et disques persistants régionaux |
|---|---|---|
|
Fournit une interface de hook pour permettre l'appel d'actions définies par l'utilisateur lors des étapes clés, telles que la rétrogradation ou la promotion. Configurabilité avec un large éventail de fonctionnalités, par exemple la prise en charge de différents types de magasins DCS, différentes méthodes d'initialisation des instances dupliquées et différentes méthodes pour fournir une configuration PostgreSQL. Autorise la configuration de clusters de secours qui permettent d'utiliser des clusters d'instances dupliquées en cascade afin de faciliter la migration entre les clusters. |
Limitée, car il s'agit d'un projet relativement récent. | Non applicable. |
Maturité
| Patroni | pg_auto_failover | MIG avec état et disques persistants régionaux |
|---|---|---|
| Ce projet est disponible depuis 2015. Il est utilisé en production par de grandes entreprises telles que Zalando et GitLab. | Projet relativement récent, annoncé début 2019. | Composé entièrement de produits Google Cloud accessibles à tous. |
Étape suivante
- Documentez-vous sur la configuration de la haute disponibilité pour Cloud SQL.
- Découvrez les options de haute disponibilité avec des disques persistants régionaux.
- Documentez-vous sur Patroni.
- En savoir plus sur pg_auto_failover.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.