Dokumen ini menjelaskan arsitektur keseluruhan sistem machine learning (ML) menggunakan library TensorFlow Extended (TFX). Dokumen ini juga membahas cara menyiapkan continuous integration (CI), continuous delivery (CD), dan continuous training (CT) untuk sistem ML menggunakan Cloud Build dan Vertex AI Pipelines.
Dalam dokumen ini, istilah sistem ML dan pipeline ML merujuk pada pipeline pelatihan model ML, bukan pipeline penskoran atau prediksi model.
Dokumen ini ditujukan untuk data scientist dan engineer ML yang ingin menyesuaikan praktik CI/CD untuk memindahkan solusi ML ke produksi di Google Cloud, dan yang ingin membantu memastikan kualitas, kemampuan pemeliharaan, dan kemampuan adaptasi di pipeline ML mereka.
Dokumen ini membahas topik berikut:
- Memahami CI/CD dan otomatisasi di ML.
- Mendesain pipeline ML terintegrasi dengan TFX.
- Mengorkestrasi dan mengotomatiskan pipeline ML menggunakan Vertex AI Pipelines.
- Menyiapkan sistem CI/CD untuk pipeline ML menggunakan Cloud Build.
MLOps
Untuk mengintegrasikan sistem ML di lingkungan produksi, Anda perlu mengorkestrasi langkah-langkah di pipeline ML Anda. Selain itu, Anda perlu mengotomatiskan eksekusi pipeline untuk continuous training pada model Anda. Untuk bereksperimen dengan ide dan fitur baru, Anda perlu mengadopsi praktik CI/CD dalam implementasi pipeline yang baru. Bagian berikut memberikan ringkasan umum tentang CI/CD dan CT di ML.
Otomatisasi pipeline ML
Dalam beberapa kasus penggunaan, proses manual untuk melatih, memvalidasi, dan men-deploy model ML mungkin sudah cukup. Pendekatan manual ini berfungsi jika tim Anda hanya mengelola beberapa model ML yang tidak dilatih ulang atau tidak sering diubah. Namun dalam praktiknya, model sering kali rusak saat di-deploy di dunia nyata karena gagal beradaptasi dengan perubahan dinamika lingkungan, atau data yang menjelaskan dinamika tersebut.
Agar sistem ML dapat beradaptasi dengan perubahan tersebut, Anda perlu menerapkan teknik MLOps berikut:
- Otomatiskan eksekusi pipeline ML untuk melatih ulang model baru pada data baru agar dapat menangkap pola yang muncul. CT akan dibahas nanti dalam dokumen ini di bagian ML dengan Vertex AI Pipelines.
- Siapkan sistem continuous delivery untuk sering men-deploy implementasi baru dari seluruh pipeline ML. CI/CD akan dibahas nanti dalam dokumen ini di bagian Penyiapan CI/CD untuk ML di Google Cloud.
Anda dapat mengotomatiskan pipeline produksi ML untuk melatih ulang model Anda dengan data baru. Anda dapat memicu pipeline sesuai permintaan, sesuai jadwal, saat tersedianya data baru, saat penurunan performa model, saat perubahan signifikan pada properti statistik data, atau berdasarkan kondisi lainnya.
Pipeline CI/CD dibandingkan pipeline CT
Ketersediaan data baru adalah salah satu pemicu untuk melatih ulang model ML. Ketersediaan implementasi baru pipeline ML (termasuk arsitektur model baru, rekayasa fitur, dan hyperparameter) adalah pemicu penting lainnya dalam mengeksekusi ulang pipeline ML. Implementasi baru pipeline ML ini berfungsi sebagai versi baru layanan prediksi model, misalnya, microservice dengan REST API untuk penyajian online. Perbedaan antara kedua kasus tersebut adalah sebagai berikut:
- Untuk melatih model ML baru dengan data baru, pipeline CT yang di-deploy sebelumnya akan dieksekusi. Tidak ada pipeline atau komponen baru yang di-deploy; hanya layanan prediksi baru atau model yang baru dilatih yang disajikan di akhir pipeline.
- Untuk melatih model ML baru dengan implementasi baru, pipeline baru di-deploy melalui pipeline CI/CD.
Untuk men-deploy pipeline ML baru dengan cepat, Anda perlu menyiapkan pipeline CI/CD. Pipeline ini bertanggung jawab untuk men-deploy pipeline dan komponen ML baru secara otomatis saat implementasi baru tersedia dan disetujui untuk berbagai lingkungan (seperti pengembangan, pengujian, staging, praproduksi, dan produksi).
Diagram berikut menunjukkan hubungan antara pipeline CI/CD dan pipeline ML CT.

Gambar 1. Pipeline CI/CD dan ML CT.
Output untuk pipeline ini adalah sebagai berikut:
- Jika diberi implementasi baru, pipeline CI/CD yang berhasil akan men-deploy pipeline ML CT baru.
- Jika diberi data baru, pipeline CT yang berhasil akan melatih model baru dan men-deploy-nya sebagai layanan prediksi.
Merancang sistem ML berbasis TFX
Bagian berikut membahas cara mendesain sistem ML terintegrasi menggunakan TensorFlow Extended (TFX) untuk menyiapkan pipeline CI/CD untuk sistem ML. Meskipun ada beberapa framework untuk membangun model ML, TFX merupakan platform ML terintegrasi untuk mengembangkan dan men-deploy sistem ML produksi. Pipeline TFX adalah urutan komponen yang mengimplementasikan sistem ML. Pipeline TFX ini dirancang untuk tugas ML berperforma tinggi dan skalabel. Tugas-tugas ini termasuk pemodelan, pelatihan, validasi, inferensi penyajian, dan pengelolaan deployment. Library utama TFX adalah sebagai berikut:
- TensorFlow Data Validation (TFDV): Digunakan untuk mendeteksi anomali dalam data.
- TensorFlow Transform (TFT): Digunakan untuk pra-pemrosesan data dan rekayasa fitur.
- TensorFlow Estimator dan Keras: Digunakan untuk membuat dan melatih model ML.
- TensorFlow Model Analysis (TFMA): Digunakan untuk evaluasi dan analisis model ML.
- TensorFlow Serving (TFserving): Digunakan untuk menyajikan model ML sebagai REST dan gRPC API.
Ringkasan sistem TFX ML
Diagram berikut menunjukkan bagaimana berbagai library TFX diintegrasikan untuk membuat sistem ML.

Gambar 2. Sistem ML berbasis TFX umum.
Gambar 2 menunjukkan sistem ML berbasis TFX yang umum. Langkah-langkah berikut dapat diselesaikan secara manual atau dengan pipeline otomatis:
- Ekstraksi data: Langkah pertama adalah mengekstrak data pelatihan baru dari sumber datanya. Output langkah ini adalah file data yang digunakan untuk melatih dan mengevaluasi model.
- Validasi data: TFDV memvalidasi data terhadap skema data yang diharapkan (mentah). Skema data dibuat dan diperbaiki selama fase pengembangan, sebelum deployment sistem. Langkah-langkah validasi data mendeteksi anomali yang terkait dengan distribusi data dan kecondongan skema. Output langkah ini adalah anomali (jika ada) dan keputusan apakah akan mengeksekusi langkah downstream atau tidak.
- Transformasi data: Setelah data divalidasi, data dibagi dan
disiapkan untuk tugas ML dengan melakukan transformasi data dan operasi
rekayasa fitur menggunakan TFT. Output langkah ini adalah file data untuk
melatih dan mengevaluasi model, yang biasanya ditransformasi dalam
format
TFRecords. Selain itu, artefak transformasi yang dihasilkan membantu pembuatan input model dan menyematkan proses transformasi dalam model tersimpan yang diekspor setelah pelatihan. - Pelatihan dan penyesuaian model: Untuk mengimplementasikan dan melatih model ML, gunakan
tf.KerasAPI dengan data yang ditransformasi yang dihasilkan oleh langkah sebelumnya. Untuk memilih setelan parameter yang mengarah ke model terbaik, Anda dapat menggunakan Keras tuner, library penyesuaian hyperparameter untuk Keras. Atau, Anda dapat menggunakan layanan lain seperti Katib, Vertex AI Vizier, atau penyesuai hyperparameter dari Vertex AI. Output langkah ini adalah model tersimpan yang digunakan untuk evaluasi, dan model tersimpan lain yang digunakan untuk penyajian model secara online untuk prediksi. - Evaluasi dan validasi model: Ketika diekspor setelah langkah pelatihan, model akan dievaluasi pada set data pengujian untuk menilai kualitas model menggunakan TFMA. TFMA mengevaluasi kualitas model secara keseluruhan, dan mengidentifikasi bagian mana dari model data yang tidak berperforma baik. Evaluasi ini membantu menjamin bahwa model dipromosikan hanya untuk disajikan jika memenuhi kriteria kualitas. Kriteria tersebut dapat mencakup performa yang cukup baik pada berbagai subset data (misalnya, demografi dan lokasi), serta performa yang lebih baik dibandingkan dengan model sebelumnya atau model tolok ukur. Output dari langkah ini adalah sekumpulan metrik performa dan keputusan apakah akan mempromosikan model ke produksi atau tidak.
- Penyajian model untuk prediksi: Setelah model yang baru dilatih divalidasi, model tersebut di-deploy sebagai microservice untuk menyajikan prediksi online menggunakan TensorFlow Serving. Output langkah ini adalah layanan prediksi yang di-deploy dari model ML yang dilatih. Anda dapat mengganti langkah ini dengan menyimpan model terlatih dalam model registry. Selanjutnya, model terpisah yang menyajikan proses CI/CD akan diluncurkan.
Untuk contoh cara menggunakan library TFX, lihat Tutorial TFX Keras Component resmi.
Sistem ML TFX di Google Cloud
Dalam lingkungan produksi, komponen sistem harus berjalan dalam skala besar di platform yang andal. Diagram berikut menunjukkan cara setiap langkah pipeline ML TFX dijalankan menggunakan layanan terkelola di Google Cloud, yang memastikan ketangkasan, keandalan, dan performa dalam skala besar.

Gambar 3. Sistem ML berbasis TFX di Google Cloud.
Tabel berikut menjelaskan layanan utamaGoogle Cloud yang ditunjukkan dalam gambar 3:
| Langkah | Library TFX | Google Cloud service |
|---|---|---|
| Ekstraksi dan validasi data | TensorFlow Data Validation | Dataflow |
| Transformasi data | TensorFlow Transform | Dataflow |
| Pelatihan dan penyesuaian model | TensorFlow | Vertex AI Training |
| Evaluasi dan validasi model | TensorFlow Model Analysis | Dataflow |
| Penyajian model untuk prediksi | TensorFlow Serving | Inferensi Vertex AI |
| Penyimpanan Model | T/A | Vertex AI Model Registry |
- Dataflow
adalah layanan terkelola sepenuhnya, serverless, dan andal untuk menjalankan
pipeline Apache Beam
dalam skala besar di Google Cloud. Dataflow
digunakan untuk menskalakan proses berikut:
- Menghitung statistik untuk memvalidasi data yang masuk.
- Melakukan persiapan dan transformasi data.
- Mengevaluasi model pada set data besar.
- Menghitung metrik pada berbagai aspek set data evaluasi.
- Cloud Storage
adalah penyimpanan yang sangat tersedia dan tahan lama untuk objek besar biner.
Cloud Storage menghosting artefak yang dihasilkan
selama eksekusi pipeline ML, termasuk hal berikut:
- Anomali data (jika ada)
- Data dan artefak yang ditransformasi
- Model yang diekspor (dilatih)
- Metrik evaluasi model
- Vertex AI Training adalah layanan terkelola untuk melatih model ML dalam skala besar. Anda dapat mengeksekusi tugas pelatihan model dengan container siap pakai untuk TensorFlow, Scikit learn, XGBoost, dan PyTorch. Anda juga dapat menjalankan framework apa pun menggunakan container kustom Anda sendiri. Untuk infrastruktur pelatihan, Anda dapat menggunakan akselerator dan beberapa node untuk pelatihan terdistribusi. Selain itu, layanan berbasis pengoptimalan Bayesian yang skalabel untuk penyesuaian hyperparameter juga tersedia
- Vertex AI Inference adalah layanan terkelola untuk menjalankan prediksi batch menggunakan model terlatih dan prediksi online dengan men-deploy model Anda sebagai microservice menggunakan REST API. Layanan ini juga terintegrasi dengan Vertex Explainable AI dan Vertex AI Model Monitoring untuk memahami model Anda dan menerima pemberitahuan saat ada kecondongan dan penyimpangan fitur atau atribusi fitur.
- Vertex AI Model Registry memungkinkan Anda mengelola siklus proses model ML Anda. Anda dapat membuat versi model yang diimpor dan melihat metrik performanya. Kemudian, sebuah model dapat digunakan untuk prediksi batch atau men-deploy model Anda untuk penyajian online menggunakan Vertex AI Inference
Mengorkestrasi sistem ML menggunakan Vertex AI Pipelines
Dokumen ini telah membahas cara mendesain sistem ML berbasis TFX, dan cara menjalankan setiap komponen sistem dalam skala besar di Google Cloud. Namun, Anda memerlukan orkestrator untuk menghubungkan berbagai komponen sistem ini secara bersamaan. Orkestrator menjalankan pipeline secara berurutan, dan otomatis berpindah dari satu langkah ke langkah lainnya berdasarkan kondisi yang ditentukan. Misalnya, kondisi yang ditentukan mungkin mengeksekusi langkah penyajian model setelah langkah evaluasi model jika metrik evaluasi memenuhi batas yang telah ditentukan. Langkah-langkah juga dapat dijalankan secara paralel untuk menghemat waktu, misalnya memvalidasi infrastruktur deployment dan mengevaluasi model. Mengorkestrasi pipeline ML berguna dalam fase pengembangan dan produksi:
- Selama fase pengembangan, orkestrasi membantu data scientist menjalankan eksperimen ML, bukan mengeksekusi setiap langkah secara manual.
- Selama fase produksi, orkestrasi membantu mengotomatiskan eksekusi pipeline ML berdasarkan jadwal atau kondisi pemicu tertentu.
ML dengan Vertex AI Pipelines
Vertex AI Pipelines adalah Google Cloud layanan terkelola yang memungkinkan Anda mengorkestrasi dan mengotomatiskan pipeline ML tempat setiap komponen pipeline dapat dijalankan dalam container di Google Cloud atau platform cloud lainnya. Parameter pipeline dan artefak yang dihasilkan otomatis disimpan di Vertex ML Metadata yang memungkinkan pelacakan silsilah dan eksekusi. Layanan Vertex AI Pipelines terdiri dari:
- Antarmuka pengguna untuk mengelola dan melacak eksperimen, tugas, dan operasi.
- Mesin untuk menjadwalkan alur kerja ML multi-langkah.
- Python SDK untuk menentukan dan memanipulasi pipeline dan komponen.
- Integrasi dengan Vertex ML Metadata untuk menyimpan informasi tentang eksekusi, model, set data, dan artefak lainnya.
Berikut ini adalah pipeline yang dieksekusi di Vertex AI Pipelines:
- Kumpulan tugas ML dalam container, atau komponen. Komponen pipeline adalah kode mandiri yang dikemas sebagai image Docker. Komponen melakukan satu langkah di pipeline. Komponen mengambil argumen input dan menghasilkan artefak.
- Spesifikasi urutan tugas ML, yang ditentukan melalui bahasa khusus domain (DSL) Python. Topologi alur kerja ditentukan secara implisit dengan menghubungkan output langkah upstream ke input langkah downstream. Langkah dalam definisi pipeline memanggil komponen dalam pipeline. Dalam pipeline yang kompleks, komponen dapat dieksekusi beberapa kali dalam loop, atau dapat dieksekusi secara bersyarat.
- Kumpulan parameter input pipeline, yang nilainya diteruskan ke komponen pipeline, termasuk kriteria untuk memfilter data dan tempat untuk menyimpan artefak yang dihasilkan pipeline.
Diagram berikut menunjukkan grafik sampel Vertex AI Pipelines.
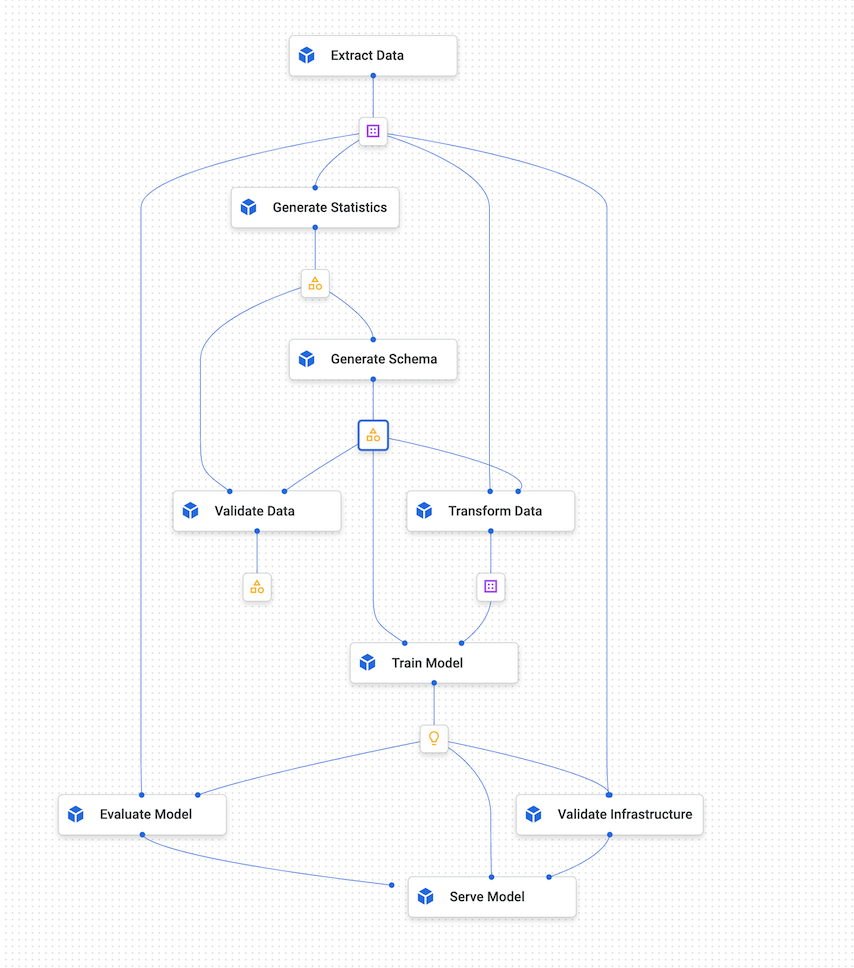
Gambar 4. Contoh grafik Vertex AI Pipelines.
Kubeflow Pipelines SDK
Kubeflow Pipelines SDK memungkinkan Anda membuat komponen, menentukan orkestrasinya, dan menjalankannya sebagai pipeline. Untuk mengetahui detail tentang komponen Kubeflow Pipelines, lihat Membuat komponen dalam dokumentasi Kubeflow.
Anda juga dapat menggunakan TFX Pipeline DSL dan menggunakan komponen TFX. Komponen TFX mengenkapsulasi kemampuan metadata. Driver memberikan metadata kepada eksekutor dengan meng-kueri penyimpanan metadata. Penayang menerima hasil eksekutor dan menyimpannya dalam metadata. Anda juga dapat menerapkan komponen kustom yang memiliki integrasi yang sama dengan metadata. Anda dapat mengompilasi pipeline TFX ke YAML yang kompatibel dengan Vertex AI Pipelines menggunakan tfx.orchestration.experimental.KubeflowV2DagRunner. Kemudian, Anda dapat mengirimkan file tersebut ke Vertex AI Pipelines untuk dieksekusi.
Diagram berikut menunjukkan bagaimana tugas dalam container dapat memanggil layanan lain seperti tugas BigQuery, tugas pelatihan Vertex AI (terdistribusi), dan tugas Dataflow, di Vertex AI Pipelines.

Gambar 5. Vertex AI Pipelines yang memanggil layanan terkelolaGoogle Cloud .
Vertex AI Pipelines memungkinkan Anda untuk mengorkestrasi dan mengotomatiskan pipeline ML produksi dengan mengeksekusi layanan Google Cloud yang diperlukan. Pada Gambar 5, Vertex ML Metadata berfungsi sebagai penyimpanan metadata ML untuk Vertex AI Pipelines.
Komponen pipeline tidak dibatasi untuk mengeksekusi layanan terkait TFX di Google Cloud. Komponen ini dapat mengeksekusi semua layanan terkait data dan komputasi, termasuk Dataproc untuk tugas SparkML, AutoML, dan workload komputasi lainnya.
Memasukkan tugas ke dalam container di Vertex AI Pipelines memiliki keuntungan berikut:
- Memisahkan lingkungan eksekusi dari runtime kode Anda.
- Memberikan kemampuan reproduksi kode antara lingkungan pengembangan dan lingkungan produksi, karena hal yang Anda uji sama dalam produksi.
- Mengisolasi setiap komponen dalam pipeline; masing-masing dapat memiliki versi runtime-nya sendiri, bahasa yang berbeda, dan library yang berbeda.
- Membantu komposisi pipeline yang kompleks.
- Terintegrasi dengan Vertex ML Metadata untuk keterlacakan dan kemampuan reproduksi eksekusi dan artefak pipeline.
Untuk pengantar komprehensif tentang Vertex AI Pipelines, lihat daftar contoh notebook yang tersedia.
Memicu dan menjadwalkan Vertex AI Pipelines
Saat men-deploy pipeline ke produksi, Anda harus mengotomatiskan eksekusinya, bergantung pada skenario yang dibahas di bagian Otomatisasi pipeline ML.
Dengan Vertex AI SDK, Anda dapat mengoperasikan pipeline secara terprogram. Class google.cloud.aiplatform.PipelineJob mencakup API untuk membuat eksperimen, dan untuk men-deploy serta menjalankan pipeline. Dengan menggunakan SDK, Anda dapat memanggil Vertex AI Pipelines dari layanan lain untuk mencapai penjadwal atau pemicu berbasis peristiwa.

Gambar 6. Diagram alur menunjukkan beberapa pemicu untuk Vertex AI Pipelines yang menggunakan fungsi Pub/Sub dan Cloud Run.
Pada Gambar 6, Anda dapat melihat contoh cara memicu layanan Vertex AI Pipelines untuk mengeksekusi pipeline. Pipeline dipicu menggunakan Vertex AI SDK dari fungsi Cloud Run. Fungsi Cloud Run itu sendiri adalah pelanggan Pub/Sub dan dipicu berdasarkan pesan baru. Layanan apa pun yang ingin memicu eksekusi pipeline dapat memublikasikan di topik Pub/Sub yang sesuai. Contoh sebelumnya memiliki tiga layanan publikasi:
- Cloud Scheduler memublikasikan pesan sesuai jadwal sehingga memicu pipeline.
- Cloud Composer memublikasikan pesan sebagai bagian dari alur kerja yang lebih besar, seperti alur kerja penyerapan data yang memicu pipeline pelatihan setelah BigQuery menyerap data baru.
- Cloud Logging memublikasikan pesan berdasarkan log yang memenuhi beberapa kriteria pemfilteran. Anda dapat menyiapkan filter untuk mendeteksi kedatangan data baru atau bahkan pemberitahuan kecondongan dan penyimpangan yang dihasilkan oleh layanan Vertex AI Model Monitoring.
Menyiapkan CI/CD untuk ML di Google Cloud
Dengan Vertex AI Pipelines, Anda dapat mengorkestrasi sistem ML yang melibatkan beberapa langkah, termasuk pra-pemrosesan data, pelatihan dan evaluasi model, serta deployment model. Dalam fase eksplorasi data science, Vertex AI Pipelines akan membantu eksperimen keseluruhan sistem dengan cepat. Pada fase produksi, Vertex AI Pipelines memungkinkan Anda mengotomatiskan eksekusi pipeline berdasarkan data baru untuk melatih atau melatih ulang model ML.
Arsitektur CI/CD
Diagram berikut menunjukkan ringkasan umum CI/CD untuk ML dengan Vertex AI Pipelines.
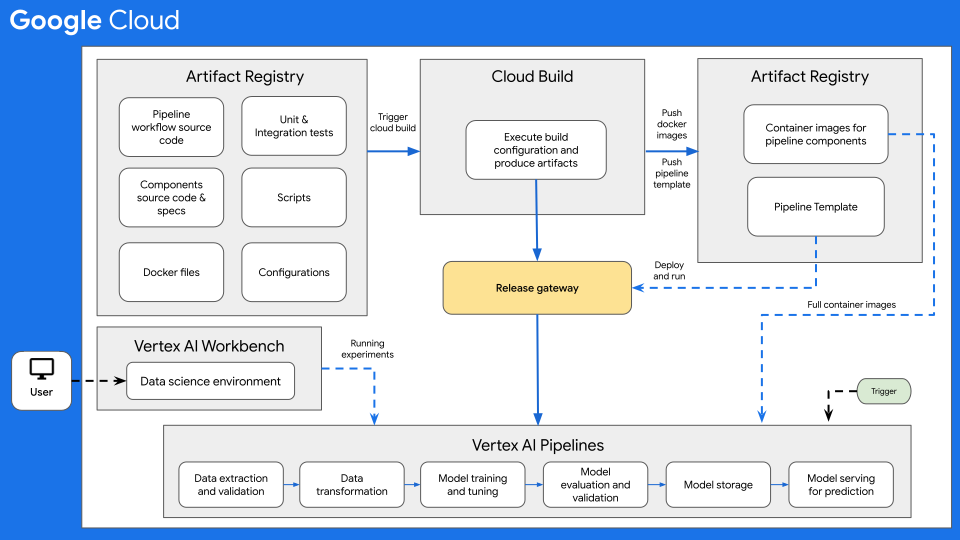
Gambar 7: Ringkasan umum CI/CD dengan Vertex AI Pipelines.
Inti dari arsitektur ini adalah Cloud Build. Cloud Build dapat mengimpor sumber dari Artifact Registry, GitHub, atau Bitbucket, lalu mengeksekusi build sesuai spesifikasi Anda, dan menghasilkan artefak seperti container Docker atau file tar Python.
Cloud Build mengeksekusi build Anda sebagai serangkaian langkah build,
yang ditentukan dalam
file konfigurasi build
(cloudbuild.yaml). Setiap langkah build berjalan dalam container Docker. Anda
dapat
menggunakan langkah build yang didukung
yang disediakan oleh Cloud Build, atau
menulis langkah build Anda sendiri.
Proses Cloud Build, yang menjalankan CI/CD yang diperlukan untuk sistem ML Anda, dapat dieksekusi secara manual atau melalui pemicu build otomatis. Pemicu mengeksekusi langkah-langkah build yang dikonfigurasi setiap kali perubahan dikirim ke sumber build. Anda dapat menetapkan pemicu build untuk mengeksekusi rutinitas build saat ada perubahan pada repositori sumber, atau untuk mengeksekusi rutinitas build hanya jika perubahan sesuai dengan kriteria tertentu.
Selain itu, Anda dapat memiliki rutinitas build (file konfigurasi Cloud Build) yang dieksekusi sebagai respons terhadap pemicu yang berbeda. Misalnya, Anda dapat memiliki rutinitas build yang dipicu saat commit dibuat ke cabang pengembangan atau ke cabang utama.
Anda dapat menggunakan substitusi variabel
konfigurasi
untuk menentukan variabel lingkungan pada waktu build. Substitusi ini
diambil dari build yang dipicu. Variabel ini mencakup $COMMIT_SHA,
$REPO_NAME, $BRANCH_NAME, $TAG_NAME, dan $REVISION_ID. Variabel
lainnya yang tidak berbasis pemicu adalah $PROJECT_ID dan $BUILD_ID. Substitusi
berguna untuk variabel yang nilainya tidak diketahui hingga waktu build, atau untuk menggunakan kembali
permintaan build yang sudah ada dengan nilai variabel yang berbeda.
Kasus penggunaan alur kerja CI/CD
Repositori kode sumber biasanya mencakup item berikut:
- Kode sumber alur kerja pipeline Python tempat alur kerja pipeline ditentukan
- Kode sumber komponen pipeline Python dan file spesifikasi komponen yang sesuai untuk berbagai komponen pipeline seperti validasi data, transformasi data, pelatihan model, evaluasi model, dan penyajian model.
- Dockerfile yang diperlukan untuk membuat image container Docker, satu untuk setiap komponen pipeline.
- Pengujian unit dan integrasi Python untuk menguji metode yang diimplementasikan di komponen dan pipeline keseluruhan.
- Skrip lain, termasuk file
cloudbuild.yaml, pemicu pengujian, dan deployment pipeline. - File konfigurasi (misalnya, file
settings.yaml), termasuk konfigurasi untuk parameter input pipeline. - Notebook yang digunakan untuk analisis data eksploratif, analisis model, dan eksperimen interaktif pada model.
Pada contoh berikut, rutinitas build dipicu saat developer mengirim kode sumber ke cabang pengembangan dari lingkungan data science mereka.
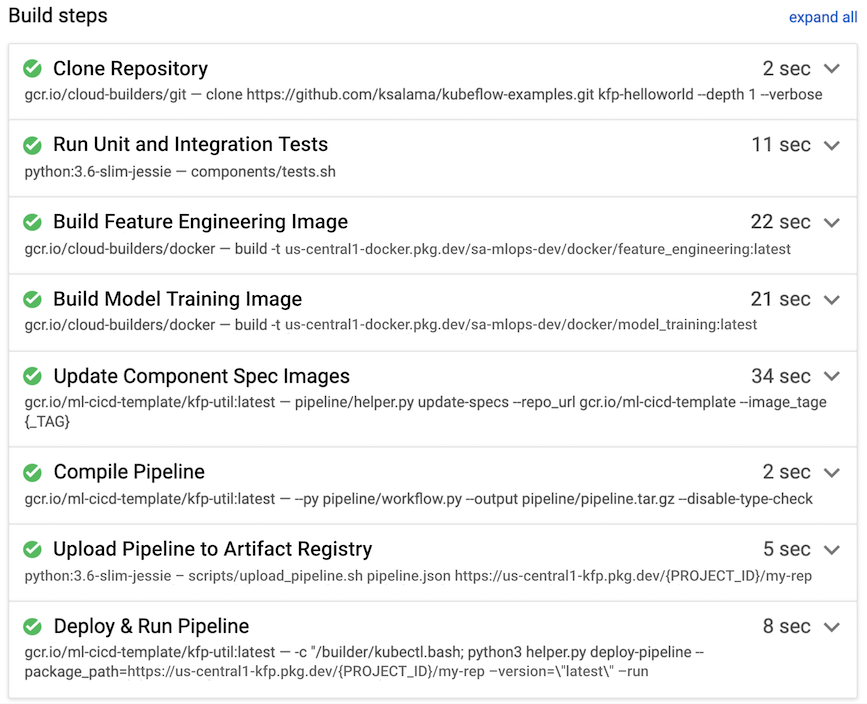
Gambar 8. Contoh langkah-langkah build yang dijalankan oleh Cloud Build.
Cloud Build biasanya melakukan langkah-langkah build berikut, yang juga ditunjukkan pada gambar 7:
- Repositori kode sumber disalin ke lingkungan runtime
Cloud Build, di bagian direktori
/workspace. - Jalankan pengujian unit dan integrasi.
- Opsional: Jalankan analisis kode statis menggunakan penganalisis seperti Pylint.
- Jika pengujian lulus, image container Docker akan di-build, satu untuk setiap
komponen pipeline. Gambar diberi tag dengan
parameter
$COMMIT_SHA. - Image container Docker diupload ke Artifact Registry (seperti yang ditunjukkan pada gambar 7).
- URL image diperbarui di setiap file
component.yamldengan image container Docker yang dibuat dan diberi tag. - Alur kerja pipeline dikompilasi untuk menghasilkan
file
pipeline.json. - File
pipeline.jsondiupload ke Artifact Registry. - Opsional: Jalankan pipeline dengan parameter value sebagai bagian dari pengujian integrasi atau eksekusi produksi. Pipeline yang dieksekusi menghasilkan model baru dan juga dapat men-deploy model sebagai API di Vertex AI Inference.
Untuk contoh MLOps menyeluruh siap produksi yang mencakup CI/CD menggunakan Cloud Build, lihat Contoh Menyeluruh Vertex Pipelines di GitHub.
Pertimbangan lainnya
Saat Anda menyiapkan arsitektur ML CI/CD di Google Cloud, pertimbangkan hal berikut:
- Untuk lingkungan data science, Anda dapat menggunakan komputer lokal, atau Vertex AI Workbench.
- Anda dapat mengonfigurasi pipeline Cloud Build otomatis untuk melewati pemicu, misalnya, jika hanya file dokumentasi yang diedit, atau jika notebook eksperimen diubah.
- Anda dapat mengeksekusi pipeline untuk pengujian integrasi dan regresi sebagai
pengujian build. Sebelum pipeline di-deploy ke lingkungan
target, Anda dapat menggunakan metode
wait()untuk menunggu pipeline yang dikirimkan dijalankan hingga selesai. - Selain menggunakan Cloud Build, Anda dapat menggunakan sistem build lain seperti Jenkins. Deployment Jenkins yang siap digunakan tersedia di Google Cloud Marketplace.
- Anda dapat mengonfigurasi pipeline agar otomatis di-deploy ke berbagai lingkungan, termasuk pengembangan, pengujian, dan staging, berdasarkan pemicu yang berbeda. Selain itu, Anda dapat men-deploy ke lingkungan tertentu secara manual, seperti praproduksi atau produksi, biasanya setelah mendapatkan persetujuan rilis. Anda dapat memiliki beberapa rutinitas build untuk pemicu yang berbeda atau untuk lingkungan target yang berbeda.
- Anda dapat menggunakan Apache Airflow, framework orkestrasi dan penjadwalan yang populer, untuk alur kerja tujuan umum, yang dapat dijalankan menggunakan layanan Cloud Composer yang terkelola sepenuhnya.
- Saat Anda men-deploy versi baru model ke produksi, deploy model tersebut sebagai rilis canary untuk mendapatkan gambaran performa model tersebut (penggunaan CPU, memori, dan disk). Sebelum mengonfigurasi model baru untuk menyajikan semua traffic live, Anda juga dapat melakukan pengujian A/B. Konfigurasi model baru untuk menyajikan 10% hingga 20% dari traffic langsung. Jika performa model baru lebih baik daripada model saat ini, Anda dapat mengonfigurasi model baru tersebut untuk menyajikan semua traffic. Jika tidak, sistem penyajian akan melakukan roll back ke model saat ini.
Langkah berikutnya
- Pelajari lebih lanjut Continuous delivery bergaya GitOps dengan Cloud Build.
- Untuk mengetahui ringkasan prinsip dan rekomendasi arsitektur khusus untuk workload AI dan ML di Google Cloud, lihat perspektif AI dan ML dalam Well-Architected Framework.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.
Kontributor
Penulis:
- Ross Thomson | Cloud Solutions Architect
- Khalid Salama | Staff Software Engineer, Machine Learning
Kontributor lainnya: Wyatt Gorman | HPC Outbound Product Manager