Este documento descreve a arquitetura geral de um sistema de aprendizagem automática (AA) que usa as bibliotecas do TensorFlow Extended (TFX). Também aborda como configurar uma integração contínua (CI), uma entrega contínua (CD) e uma preparação contínua (CT) para o sistema de ML usando o Cloud Build e o Vertex AI Pipelines.
Neste documento, os termos sistema de ML e pipeline de ML referem-se a pipelines de preparação de modelos de ML, em vez de pipelines de classificação ou previsão de modelos.
Este documento destina-se a cientistas de dados e engenheiros de ML que queiram adaptar as respetivas práticas de CI/CD para mover soluções de ML para produção no Google Cloude que queiram ajudar a garantir a qualidade, a capacidade de manutenção e a adaptabilidade dos respetivos pipelines de ML.
Este documento aborda os seguintes tópicos:
- Compreender a CI/CD e a automatização na AA.
- Conceber um pipeline de AA integrado com o TFX.
- Orquestrar e automatizar o pipeline de ML através do Vertex AI Pipelines.
- Configurar um sistema de CI/CD para o pipeline de ML através do Cloud Build.
MLOps
Para integrar um sistema de ML num ambiente de produção, tem de orquestrar os passos no seu pipeline de ML. Além disso, tem de automatizar a execução do pipeline para a preparação contínua dos seus modelos. Para experimentar novas ideias e funcionalidades, tem de adotar práticas de CI/CD nas novas implementações dos pipelines. As secções seguintes apresentam uma vista geral de nível superior da CI/CD e dos testes contínuos na aprendizagem automática.
Automatização de pipelines de ML
Em alguns exemplos de utilização, o processo manual de preparação, validação e implementação de modelos de ML pode ser suficiente. Esta abordagem manual funciona se a sua equipa gerir apenas alguns modelos de ML que não são reciclados ou não são alterados com frequência. Na prática, no entanto, os modelos falham frequentemente quando implementados no mundo real porque não se adaptam às alterações na dinâmica dos ambientes ou aos dados que descrevem essa dinâmica.
Para que o seu sistema de ML se adapte a essas alterações, tem de aplicar as seguintes técnicas de MLOps:
- Automatize a execução do pipeline de AA para voltar a formar novos modelos com novos dados para captar quaisquer padrões emergentes. O CT é abordado mais adiante neste documento na secção ML com pipelines do Vertex AI.
- Configure um sistema de fornecimento contínuo para implementar frequentemente novas implementações de toda a pipeline de ML. A CI/CD é abordada mais adiante neste documento na secção Configuração de CI/CD para ML no Google Cloud.
Pode automatizar os pipelines de produção de ML para voltar a formar os seus modelos com novos dados. Pode acionar o pipeline a pedido, de acordo com um horário, com a disponibilidade de novos dados, com a degradação do desempenho do modelo, com alterações significativas nas propriedades estatísticas dos dados ou com base noutras condições.
Pipeline de CI/CD em comparação com pipeline de CT
A disponibilidade de novos dados é um dos acionadores para voltar a formar o modelo de AA. A disponibilidade de uma nova implementação do pipeline de ML (incluindo uma nova arquitetura de modelo, engenharia de funcionalidades e hiperparâmetros) é outro acionador importante para voltar a executar o pipeline de ML. Esta nova implementação do pipeline de ML funciona como uma nova versão do serviço de previsão do modelo, por exemplo, um microsserviço com uma API REST para publicação online. A diferença entre os dois casos é a seguinte:
- Para preparar um novo modelo de ML com novos dados, a pipeline de CT implementada anteriormente é executada. Não são implementados novos pipelines nem componentes. Apenas é publicado um novo serviço de previsão ou um modelo recém-treinado no final do pipeline.
- Para preparar um novo modelo de AA com uma nova implementação, é implementada uma nova pipeline através de uma pipeline de CI/CD.
Para implementar rapidamente novos pipelines de ML, tem de configurar um pipeline de CI/CD. Este pipeline é responsável pela implementação automática de novos pipelines e componentes de ML quando novas implementações estão disponíveis e são aprovadas para vários ambientes (como desenvolvimento, teste, preparação, pré-produção e produção).
O diagrama seguinte mostra a relação entre o pipeline de CI/CD e o pipeline de CT de ML.

Figura 1. Pipelines de CI/CD e ML CT.
O resultado destas condutas é o seguinte:
- Se receber uma nova implementação, um pipeline de CI/CD bem-sucedido implementa um novo pipeline de CT de ML.
- Se receber novos dados, um pipeline de CT bem-sucedido treina um novo modelo e implementa-o como um serviço de previsão.
Conceber um sistema de ML baseado no TFX
As secções seguintes abordam como criar um sistema de ML integrado usando o TensorFlow Extended (TFX) para configurar um pipeline de CI/CD para o sistema de ML. Embora existam várias frameworks para criar modelos de ML, o TFX é uma plataforma de ML integrada para desenvolver e implementar sistemas de ML de produção. Um pipeline do TFX é uma sequência de componentes que implementam um sistema de ML. Este pipeline do TFX foi concebido para tarefas de ML escaláveis de alto desempenho. Estas tarefas incluem a modelagem, a preparação, a validação, a publicação de inferências e a gestão de implementações. As principais bibliotecas do TFX são as seguintes:
- TensorFlow Data Validation (TFDV): Usado para detetar anomalias nos dados.
- TensorFlow Transform (TFT): Usado para o pré-processamento de dados e a engenharia de funcionalidades.
- Estimadores do TensorFlow e Keras: usados para criar e preparar modelos de ML.
- TensorFlow Model Analysis (TFMA): Usado para a avaliação e a análise de modelos de AA.
- TensorFlow Serving (TFServing): Usado para apresentar modelos de ML como APIs REST e gRPC.
Vista geral do sistema de ML do TFX
O diagrama seguinte mostra como as várias bibliotecas do TFX estão integradas para compor um sistema de ML.

Figura 2. Um sistema de ML típico baseado no TFX.
A Figura 2 mostra um sistema de ML típico baseado no TFX. Os passos seguintes podem ser concluídos manualmente ou através de um pipeline automatizado:
- Extração de dados: o primeiro passo é extrair os novos dados de preparação das respetivas origens de dados. Os resultados deste passo são ficheiros de dados que são usados para preparar e avaliar o modelo.
- Validação de dados: o TFDV valida os dados em comparação com o esquema de dados (não processados) esperado. O esquema de dados é criado e corrigido durante a fase de desenvolvimento, antes da implementação do sistema. Os passos de validação de dados detetam anomalias relacionadas com a distribuição de dados e as distorções de esquemas. Os resultados deste passo são as anomalias (se existirem) e uma decisão sobre se deve executar ou não os passos seguintes.
- Transformação de dados: após a validação, os dados são divididos e preparados para a tarefa de ML através da realização de transformações de dados e operações de engenharia de funcionalidades com o TFT. Os resultados deste passo são ficheiros de dados para preparar e avaliar o modelo, normalmente transformados no formato
TFRecords. Além disso, os artefactos de transformação produzidos ajudam a construir as entradas do modelo e incorporam o processo de transformação no modelo guardado exportado após a preparação. - Preparação e otimização do modelo: para implementar e preparar o modelo de AA, use a API
tf.Kerascom os dados transformados produzidos no passo anterior. Para selecionar as definições de parâmetros que originam o melhor modelo, pode usar o Keras Tuner, uma biblioteca de aperfeiçoamento de hiperparâmetros para o Keras. Em alternativa, pode usar outros serviços, como o Katib, o Vertex AI Vizier ou o otimizador de hiperparâmetros do Vertex AI. O resultado deste passo é um modelo guardado que é usado para avaliação e outro modelo guardado que é usado para a publicação online do modelo para previsão. - Avaliação e validação do modelo: quando o modelo é exportado após o passo de preparação, é avaliado num conjunto de dados de teste para avaliar a qualidade do modelo através do TFMA. A TFMA avalia a qualidade do modelo como um todo e identifica a parte do modelo de dados que não está a ter um bom desempenho. Esta avaliação ajuda a garantir que o modelo só é promovido para publicação se satisfizer os critérios de qualidade. Os critérios podem incluir um desempenho justo em vários subconjuntos de dados (por exemplo, dados demográficos e localizações) e um desempenho melhorado em comparação com modelos anteriores ou um modelo de referência. O resultado deste passo é um conjunto de métricas de desempenho e uma decisão sobre se deve promover o modelo para produção.
- Publicação de modelos para previsão: após a validação do modelo recém-preparado, este é implementado como um microsserviço para publicar previsões online através do TensorFlow Serving. O resultado deste passo é um serviço de previsão implementado do modelo de ML preparado. Pode substituir este passo armazenando o modelo preparado num registo de modelos. Posteriormente, é iniciado um processo de CI/CD de publicação de modelos separado.
Para ver um exemplo de como usar as bibliotecas do TFX, consulte o tutorial oficial do componente Keras do TFX.
Sistema de AA do TFX em Google Cloud
Num ambiente de produção, os componentes do sistema têm de ser executados em grande escala numa plataforma fiável. O diagrama seguinte mostra como cada passo do pipeline de ML do TFX é executado através de um serviço gerido no Google Cloud, o que garante agilidade, fiabilidade e desempenho em grande escala.

Figura 3. Sistema de ML baseado no TFX em Google Cloud.
A tabela seguinte descreve os principais Google Cloud serviços apresentados na figura 3:
| Passo | Biblioteca TFX | Google Cloud serviço |
|---|---|---|
| Extração e validação de dados | TensorFlow Data Validation | Dataflow |
| Transformação de dados | TensorFlow Transform | Dataflow |
| Preparação e otimização de modelos | TensorFlow | Vertex AI Training |
| Avaliação e validação de modelos | TensorFlow Model Analysis | Dataflow |
| Publicação de modelos para previsões | TensorFlow Serving | Vertex AI Inference |
| Armazenamento de modelos | N/A | Registo de modelos Vertex AI |
- O Dataflow
é um serviço totalmente gerido, sem servidor e fiável para executar pipelines do
Apache Beam
em grande escala no Google Cloud. O Dataflow é usado para dimensionar os seguintes processos:
- Calcular as estatísticas para validar os dados recebidos.
- Realizar a preparação e a transformação de dados.
- Avaliar o modelo num conjunto de dados grande.
- Calcular métricas em diferentes aspetos do conjunto de dados de avaliação.
- O Cloud Storage
é um armazenamento altamente disponível e duradouro para objetos binários grandes.
O Cloud Storage aloja artefactos produzidos
durante a execução do pipeline de ML, incluindo o seguinte:
- Anomalias nos dados (se existirem)
- Dados e artefactos transformados
- Modelo exportado (preparado)
- Métricas de avaliação de modelos
- O Vertex AI Training é um serviço gerido para preparar modelos de ML em grande escala. Pode executar tarefas de preparação de modelos com contentores pré-criados para TensorFlow, Scikit-learn, XGBoost e PyTorch. Também pode executar qualquer framework usando os seus próprios contentores personalizados. Para a sua infraestrutura de preparação, pode usar aceleradores e vários nós para a preparação distribuída. Além disso, está disponível um serviço escalável baseado na otimização bayesiana para a ajuste de hiperparâmetros
- A Vertex AI Inference é um serviço gerido para executar previsões em lote usando os seus modelos preparados e previsões online implementando os seus modelos como um microsserviço com uma API REST. O serviço também se integra com o Vertex Explainable AI e o Vertex AI Model Monitoring para compreender os seus modelos e receber alertas quando existe uma funcionalidade ou uma variação e uma derivação da atribuição de funcionalidades.
- O Registo de modelos Vertex AI permite-lhe gerir o ciclo de vida dos seus modelos de ML. Pode criar versões dos modelos importados e ver as respetivas métricas de desempenho. Em seguida, pode usar um modelo para previsões em lote ou implementá-lo para publicação online através da inferência do Vertex AI
Orquestrar o sistema de ML através do Vertex AI Pipelines
Este documento abordou a forma de conceber um sistema de ML baseado no TFX e como executar cada componente do sistema em grande escala no Google Cloud. No entanto, precisa de um orquestrador para associar estes diferentes componentes do sistema. O orquestrador executa o pipeline numa sequência e move-se automaticamente de um passo para outro com base nas condições definidas. Por exemplo, uma condição definida pode estar a executar o passo de publicação do modelo após o passo de avaliação do modelo se as métricas de avaliação atingirem os limites predefinidos. Os passos também podem ser executados em paralelo para poupar tempo. Por exemplo, validar a infraestrutura de implementação e avaliar o modelo. A orquestração do pipeline de ML é útil nas fases de desenvolvimento e produção:
- Durante a fase de desenvolvimento, a orquestração ajuda os cientistas de dados a executar a experiência de ML, em vez de executar manualmente cada passo.
- Durante a fase de produção, a orquestração ajuda a automatizar a execução do pipeline de ML com base num horário ou em determinadas condições de acionamento.
ML com Vertex AI Pipelines
O Vertex AI Pipelines é um Google Cloud serviço gerido que lhe permite orquestrar e automatizar pipelines de ML em que cada componente do pipeline pode ser executado em contentores no Google Cloud ou noutras plataformas na nuvem. Os parâmetros e os artefactos do pipeline gerados são armazenados automaticamente no Vertex ML Metadata, o que permite o acompanhamento da linhagem e da execução. O serviço Vertex AI Pipelines consiste no seguinte:
- Uma interface do utilizador para gerir e acompanhar experiências, tarefas e execuções.
- Um motor para agendar fluxos de trabalho de ML com vários passos.
- Um SDK Python para definir e manipular pipelines e componentes.
- Integração com o Vertex ML Metadata para guardar informações sobre execuções, modelos, conjuntos de dados e outros artefactos.
O seguinte constitui um pipeline executado no Vertex AI Pipelines:
- Um conjunto de tarefas de ML em contentores ou componentes. Um componente do pipeline é um código autónomo que é incluído num imagem do Docker. Um componente executa um passo no pipeline. Recebe argumentos de entrada e produz artefactos.
- Uma especificação da sequência das tarefas de ML, definida através de uma linguagem específica do domínio (DSL) do Python. A topologia do fluxo de trabalho é definida implicitamente através da associação das saídas de um passo a montante às entradas de um passo a jusante. Um passo na definição do pipeline invoca um componente no pipeline. Num pipeline complexo, os componentes podem ser executados várias vezes em ciclos ou podem ser executados condicionalmente.
- Um conjunto de parâmetros de entrada do pipeline, cujos valores são transmitidos aos componentes do pipeline, incluindo os critérios de filtragem de dados e onde armazenar os artefactos que o pipeline produz.
O diagrama seguinte mostra um exemplo de gráfico de pipelines do Vertex AI.
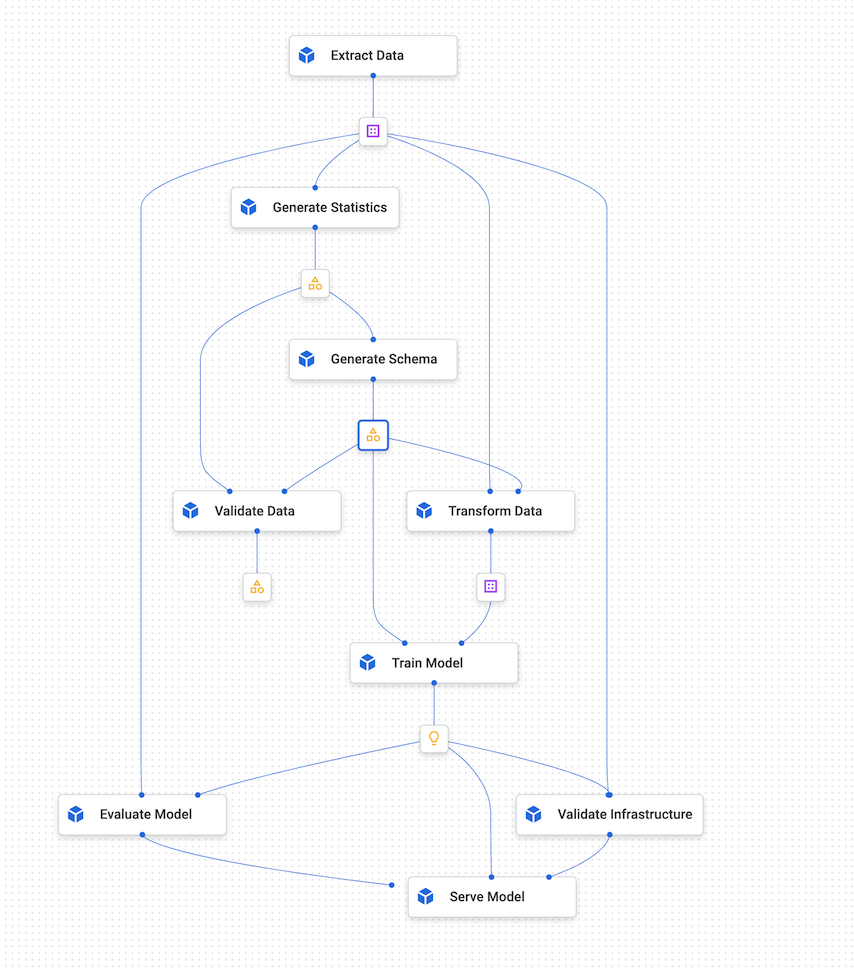
Figura 4. Um gráfico de exemplo dos Vertex AI Pipelines.
SDK Kubeflow Pipelines
O SDK Kubeflow Pipelines permite-lhe criar componentes, definir a respetiva orquestração e executá-los como um pipeline. Para ver detalhes sobre os componentes do Kubeflow Pipelines, consulte o artigo Crie componentes na documentação do Kubeflow.
Também pode usar o DSL de pipeline do TFX e usar componentes do TFX. Um componente do TFX encapsula capacidades de metadados. O controlador fornece metadados ao executor consultando o repositório de metadados. O publicador aceita os resultados do executor e armazena-os nos metadados. Também pode implementar o seu componente personalizado, que tem a mesma integração com os metadados. Pode compilar os seus pipelines do TFX para um YAML compatível com os Vertex AI Pipelines usando tfx.orchestration.experimental.KubeflowV2DagRunner. Em seguida, pode enviar o ficheiro para o Vertex AI Pipelines para execução.
O diagrama seguinte mostra como, nos Vertex AI Pipelines, uma tarefa em contentor pode invocar outros serviços, como tarefas do BigQuery, tarefas de preparação (distribuídas) do Vertex AI e tarefas do Dataflow.

Figura 5. Vertex AI Pipelines que invocam Google Cloud serviços geridos.
Os Vertex AI Pipelines permitem-lhe orquestrar e automatizar um pipeline de ML de produção executando os Google Cloud serviços necessários. Na figura 5, o Vertex ML Metadata funciona como o repositório de metadados de ML para os Vertex AI Pipelines.
Os componentes do pipeline não se limitam à execução de serviços relacionados com o TFX no Google Cloud. Estes componentes podem executar quaisquer serviços relacionados com dados e computação, incluindo o Dataproc para tarefas do SparkML, o AutoML e outras cargas de trabalho de computação.
A contentorização de tarefas no Vertex AI Pipelines tem as seguintes vantagens:
- Desvincula o ambiente de execução do tempo de execução do código.
- Garante a reprodutibilidade do código entre o ambiente de desenvolvimento e o ambiente de produção, porque os elementos que testa são os mesmos na produção.
- Isola cada componente no pipeline. Cada um pode ter a sua própria versão do tempo de execução, idiomas diferentes e bibliotecas diferentes.
- Ajuda na composição de pipelines complexos.
- Integra-se com o Vertex ML Metadata para a rastreabilidade e a reprodutibilidade das execuções de pipelines e dos artefactos.
Para uma introdução abrangente aos pipelines do Vertex AI, consulte a lista de exemplos de blocos de notas disponíveis.
Acionamento e agendamento de Vertex AI Pipelines
Quando implementa um pipeline para produção, tem de automatizar as respetivas execuções, consoante os cenários abordados na secção Automatização de pipelines de ML.
O SDK Vertex AI permite-lhe operar o pipeline programaticamente. A classe google.cloud.aiplatform.PipelineJob inclui APIs para criar experiências, bem como implementar e executar pipelines. Por conseguinte, ao usar o SDK, pode invocar o Vertex AI Pipelines a partir de outro serviço para alcançar acionadores baseados em eventos ou agendadores.

Figura 6. Diagrama de fluxo que demonstra vários acionadores para pipelines do Vertex AI que usam funções do Pub/Sub e do Cloud Run.
Na figura 6, pode ver um exemplo de como acionar o serviço Vertex AI Pipelines para executar um pipeline. O pipeline é acionado através do SDK Vertex AI a partir de uma função do Cloud Run. A função do Cloud Run em si é um subscritor do Pub/Sub e é acionada com base em novas mensagens. Qualquer serviço que queira acionar a execução do pipeline pode publicar no tópico Pub/Sub correspondente. O exemplo anterior tem três serviços de publicação:
- O Cloud Scheduler está a publicar mensagens de acordo com um agendamento e, por conseguinte, a acionar o pipeline.
- O Cloud Composer está a publicar mensagens como parte de um fluxo de trabalho maior, como um fluxo de trabalho de carregamento de dados que aciona o pipeline de preparação depois de o BigQuery carregar novos dados.
- O Cloud Logging publica uma mensagem com base em registos que cumprem alguns critérios de filtragem. Pode configurar os filtros para detetar a chegada de novos dados ou até mesmo alertas de desvio e deriva gerados pelo serviço Vertex AI Model Monitoring.
Configurar CI/CD para ML no Google Cloud
O Vertex AI Pipelines permite-lhe orquestrar sistemas de AA que envolvem vários passos, incluindo o pré-processamento de dados, a preparação e a avaliação de modelos, e a implementação de modelos. Na fase de exploração da ciência de dados, os Vertex AI Pipelines ajudam na experimentação rápida de todo o sistema. Na fase de produção, o Vertex AI Pipelines permite-lhe automatizar a execução do pipeline com base em novos dados para preparar ou voltar a preparar o modelo de ML.
Arquitetura de CI/CD
O diagrama seguinte mostra uma vista geral de alto nível da CI/CD para ML com os pipelines do Vertex AI.
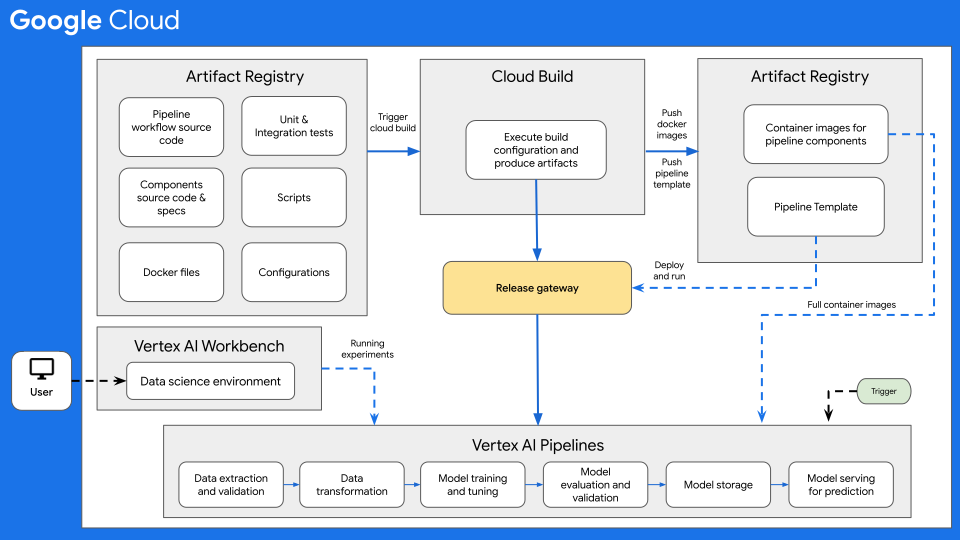
Figura 7: vista geral de alto nível da CI/CD com o Vertex AI Pipelines.
No centro desta arquitetura encontra-se o Cloud Build. O Cloud Build pode importar a origem do Artifact Registry, GitHub> ou Bitbucket, e, em seguida, executar uma compilação de acordo com as suas especificações e produzir artefactos, como contentores Docker ou ficheiros tar Python.
O Cloud Build executa a sua compilação como uma série de passos de compilação,
definidos num
ficheiro de configuração de compilação
(cloudbuild.yaml). Cada passo de compilação é executado num contentor Docker. Pode usar os passos de compilação suportados fornecidos pelo Cloud Build ou escrever os seus próprios passos de compilação.
O processo do Cloud Build, que executa a CI/CD necessária para o seu sistema de ML, pode ser executado manualmente ou através de acionadores de compilação automatizados. Os acionadores executam os passos de compilação configurados sempre que as alterações são enviadas para a origem de compilação. Pode definir um acionador de compilação para executar a rotina de compilação em alterações ao repositório de origem ou para executar a rotina de compilação apenas quando as alterações corresponderem a determinados critérios.
Além disso, pode ter rotinas de compilação (ficheiros de configuração do Cloud Build) que são executadas em resposta a diferentes acionadores. Por exemplo, pode ter rotinas de compilação acionadas quando são feitos commits no ramo de desenvolvimento ou no ramo principal.
Pode usar substituições de variáveis de configuração para definir as variáveis de ambiente no momento da compilação. Estas substituições são captadas a partir de compilações acionadas. Estas variáveis incluem $COMMIT_SHA,
$REPO_NAME, $BRANCH_NAME, $TAG_NAME e $REVISION_ID. Outras variáveis não baseadas em acionadores são $PROJECT_ID e $BUILD_ID. As substituições são úteis para variáveis cujo valor não é conhecido até ao momento da compilação ou para reutilizar um pedido de compilação existente com valores de variáveis diferentes.
Exemplo de utilização do fluxo de trabalho de CI/CD
Normalmente, um repositório de código-fonte inclui os seguintes itens:
- O código fonte do fluxo de trabalho de pipelines Python onde o fluxo de trabalho de pipelines está definido
- O código fonte dos componentes da pipeline Python e os ficheiros de especificação dos componentes correspondentes para os diferentes componentes da pipeline, como validação de dados, transformação de dados, preparação de modelos, avaliação de modelos e publicação de modelos.
- Ficheiros Dockerfile necessários para criar imagens de contentores Docker, um para cada componente do pipeline.
- Testes de integração e de unidades Python para testar os métodos implementados no componente e no pipeline geral.
- Outros scripts, incluindo o ficheiro
cloudbuild.yaml, acionadores de teste e implementações de pipelines. - Ficheiros de configuração (por exemplo, o ficheiro
settings.yaml), incluindo configurações para os parâmetros de entrada do pipeline. - Blocos de notas usados para análise exploratória de dados, análise de modelos e experiências interativas em modelos.
No exemplo seguinte, é acionada uma rotina de compilação quando um programador envia código fonte para o ramo de desenvolvimento a partir do respetivo ambiente de ciência de dados.
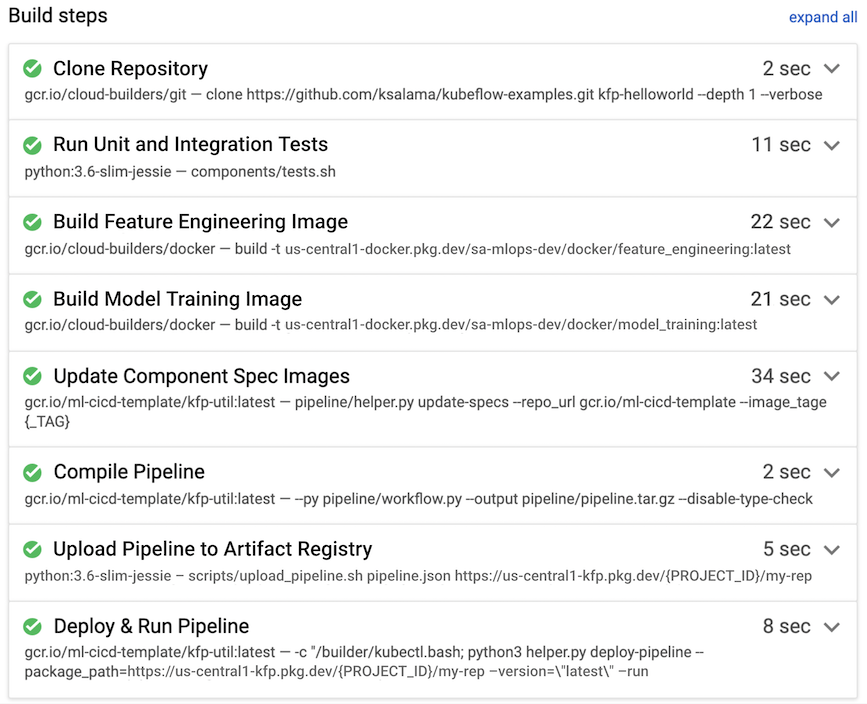
Figura 8. Exemplo de passos de compilação realizados pelo Cloud Build.
Normalmente, o Cloud Build executa os seguintes passos de compilação, que também são apresentados na figura 7:
- O repositório de código fonte é copiado para o ambiente de tempo de execução do Cloud Build, no diretório
/workspace. - Executar testes de unidades e de integração.
- Opcional: execute a análise de código estático através de um analisador, como o Pylint.
- Se os testes forem aprovados, as imagens do contentor Docker são criadas, uma para cada componente do pipeline. As imagens estão etiquetadas com o parâmetro
$COMMIT_SHA. - As imagens de contentor Docker são carregadas para o Artifact Registry (conforme mostrado na figura 7).
- O URL da imagem é atualizado em cada um dos ficheiros
component.yamlcom as imagens de contentores Docker criadas e etiquetadas. - O fluxo de trabalho do pipeline é compilado para produzir o ficheiro
pipeline.json. - O ficheiro
pipeline.jsoné carregado para o Artifact Registry. - Opcional: execute o pipeline com os valores dos parâmetros como parte de um teste de integração ou de uma execução de produção. O pipeline executado gera um novo modelo e também pode implementar o modelo como uma API na Vertex AI Inference.
Para um exemplo de MLOps ponto a ponto pronto para produção que inclua CI/CD com o Cloud Build, consulte os exemplos ponto a ponto do Vertex Pipelines no GitHub.
Considerações adicionais
Quando configurar a arquitetura de CI/CD de ML no Google Cloud, tenha em atenção o seguinte:
- Para o ambiente de ciência de dados, pode usar um computador local ou um Vertex AI Workbench.
- Pode configurar o pipeline automatizado do Cloud Build para ignorar acionadores, por exemplo, se apenas os ficheiros de documentação forem editados ou se os blocos de notas de experimentação forem modificados.
- Pode executar o pipeline para testes de integração e regressão como um teste de compilação. Antes de implementar o pipeline no ambiente de destino, pode usar o método
wait()para aguardar a conclusão da execução do pipeline enviado. - Como alternativa à utilização do Cloud Build, pode usar outros sistemas de compilação, como o Jenkins. Está disponível uma implementação pronta a usar do Jenkins no Google Cloud Marketplace.
- Pode configurar o pipeline para implementação automática em diferentes ambientes, incluindo desenvolvimento, teste e preparação, com base em diferentes acionadores. Além disso, pode implementar manualmente em ambientes específicos, como pré-produção ou produção, normalmente após receber uma aprovação de lançamento. Pode ter várias rotinas de compilação para diferentes acionadores ou para diferentes ambientes de destino.
- Pode usar o Apache Airflow, um framework de agendamento e orquestração popular, para fluxos de trabalho de uso geral, que pode executar através do serviço Cloud Composer totalmente gerido.
- Quando implementa uma nova versão do modelo em produção, implemente-a como um lançamento canário para ter uma ideia do respetivo desempenho (CPU, memória e utilização do disco). Antes de configurar o novo modelo para publicar todo o tráfego em direto, também pode realizar testes A/B. Configure o novo modelo para publicar 10% a 20% do tráfego em direto. Se o novo modelo tiver um desempenho melhor do que o atual, pode configurá-lo para publicar todo o tráfego. Caso contrário, o sistema de publicação reverte para o modelo atual.
O que se segue?
- Saiba mais sobre a entrega contínua ao estilo GitOps com o Cloud Build.
- Para uma vista geral dos princípios e recomendações de arquitetura específicos das cargas de trabalho de IA e ML no Google Cloud, consulte aperspetiva de IA e ML no Well-Architected Framework.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.
Colaboradores
Autores:
- Ross Thomson | Arquiteto de soluções na nuvem
- Khalid Salama | Staff Software Engineer, Machine Learning
Outro colaborador: Wyatt Gorman | HPC Outbound Product Manager