Nesta página, descrevemos as opções de alta disponibilidade no Google Distributed Cloud.
Principal recurso
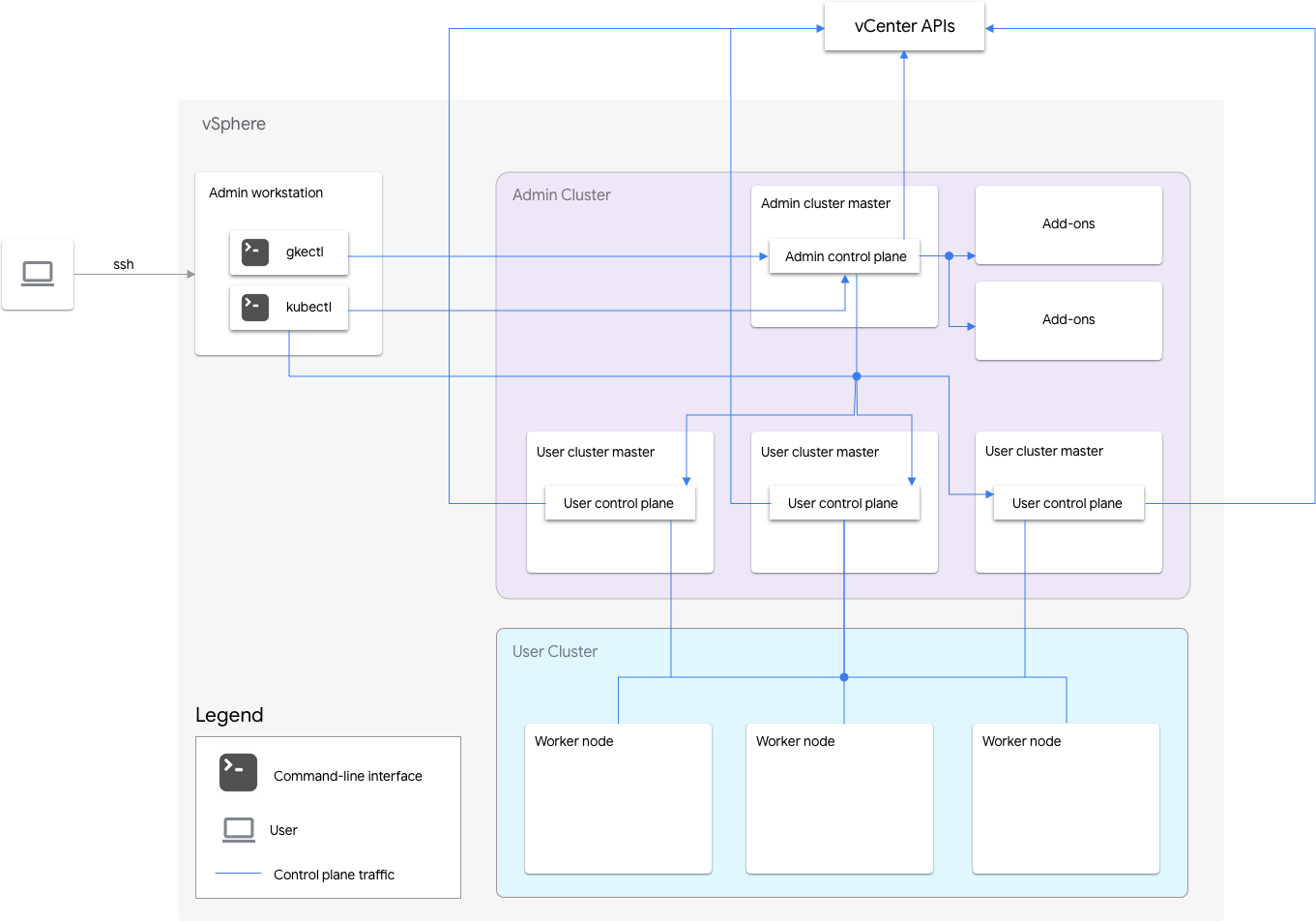
O GKE no VMware inclui um cluster de administrador e um ou mais clusters de usuário.
O cluster de administrador gerencia o ciclo de vida dos clusters de usuários, incluindo a criação, atualizações, upgrades e exclusão de clusters. No cluster de administração, o mestre do administrador gerencia os nós de worker de administrador, que incluem mestres do usuário (nós que executam o plano de controle dos clusters de usuários gerenciados) e nós de complemento (nós que executam os componentes do complemento compatíveis com o funcionalidade do cluster de administração).
Para cada cluster de usuário, o cluster de administrador tem um nó não HA ou três nós de alta disponibilidade que executam o plano de controle. O plano de controle inclui o servidor da API Kubernetes, o programador do Kubernetes, o gerenciador do controlador do Kubernetes e vários controles críticos para o cluster do usuário.
A disponibilidade do plano de controle do cluster de usuários é essencial para operações de carga de trabalho, como criação, escalonamento, redução e encerramento. Em outras palavras, uma interrupção do plano de controle não interfere nas cargas de trabalho em execução. No entanto, as cargas de trabalho atuais perdem os recursos de gerenciamento do servidor da API Kubernetes se o plano de controle estiver ausente.
As cargas de trabalho e os serviços em contêineres são implantados nos nós de trabalho do cluster de usuários. Nenhum nó de trabalho único é essencial para a disponibilidade do aplicativo, desde que seja implantado com pods redundantes programados em vários nós de trabalho.
Como ativar a alta disponibilidade
O vSphere e o Google Distributed Cloud oferecem vários recursos que contribuem para a alta disponibilidade (HA, na sigla em inglês).
vSphere HA e vMotion
Recomendamos ativar os dois recursos a seguir no cluster do vCenter que hospeda seus clusters do Google Distributed Cloud:
Esses recursos melhoram a disponibilidade e a recuperação caso um host ESXi falhe.
O vCenter com alta disponibilidade usa vários hosts ESXi configurados como um cluster para fornecer recuperação
rápida de interrupções e alta disponibilidade econômica para aplicativos
executados em máquinas virtuais. Recomendamos que você provisione seu cluster
do vCenter com hosts extras e
ative o monitoramento de host de alta disponibilidade do vSphere
com Host Failure Response definido como Restart VMs. Assim, as VMs poderão ser
reiniciadas automaticamente em outros hosts disponíveis em caso de falha do host do ESXi.
O vMotion permite migração em tempo real e sem inatividade de VMs de um host ESXi para outro. Para a manutenção planejada do host, use a vMotion disponibilização em tempo real para evitar a inatividade do aplicativo e garantir a continuidade dos negócios.
Cluster de administrador
O Google Distributed Cloud oferece suporte à criação de clusters de administrador de alta disponibilidade (HA). Um cluster de administrador de alta disponibilidade tem três nós que executam componentes do plano de controle. Para informações sobre requisitos e limitações, consulte Cluster de administrador de alta disponibilidade.
A indisponibilidade do plano de controle do cluster de administrador não afeta a funcionalidade atual do cluster de usuário nem as cargas de trabalho em execução nos clusters de usuário.
Há dois nós complementares em um cluster de administrador. Se um deles estiver inativo, o outro
ainda poderá fornecer as operações de cluster de administrador. Para redundância,
o Google Distributed Cloud distribui serviços complementares essenciais, como kube-dns,
em ambos os nós complementares.
Se você definir antiAffinityGroups.enabled como true no arquivo de configuração do cluster
de administrador, o Google Distributed Cloud vai criar automaticamente
regras antiafinidade do vSphere DRS
para os nós de complementos, o que faz com que eles sejam distribuídos em
dois hosts físicos para alta disponibilidade.
Cluster de usuário
É possível ativar a alta disponibilidade para um cluster de usuário ao definir masterNode.replicas como 3 no
arquivo de configuração do cluster de usuário. Se o cluster de usuário tiver o
Plano de controle V2
ativado (recomendado), os três nós do plano de controle serão executados no cluster de usuário.
Os clusters de usuário do kubeception de alta disponibilidade legados executam os três nós do plano de controle no cluster de administrador. Cada nó do plano de controle
também executa uma réplica do etcd. O cluster do usuário continua funcionando,
desde que haja um plano de controle em execução e um quórum do etcd. Um quórum
do etcd exige que duas das três réplicas do etcd estejam funcionando.
Se você definir antiAffinityGroups.enabled como true no arquivo de configuração do cluster
de administrador, o Google Distributed Cloud vai criar automaticamente regras antiafinidade
do vSphere DRS para os três nós que executam o plano de controle do cluster de usuário.
Isso faz com que essas VMs sejam distribuídas em três hosts físicos.
O Google Distributed Cloud também cria regras antiafinidade do vSphere DRS para os nós de trabalho no cluster de usuário, o que faz com que esses nós sejam distribuídos em pelo menos três hosts físicos. Várias regras antiafinidade do DRS são usadas por pool de nós de cluster de usuário com base no número de nós. Isso garante que os nós de trabalho encontrem hosts para execução, mesmo quando o número de hosts for menor que o número de VMs no pool de nós do cluster de usuário. Recomendamos que você inclua hosts físicos extras no cluster do vCenter. Configure também o DRS para ser totalmente automatizado para que, caso um host fique indisponível, o DRS possa reiniciar automaticamente as VMs em outros hosts disponíveis sem violar as regras antiafinidade delas.
O Google Distributed Cloud mantém um rótulo de nó especial,
onprem.gke.io/failure-domain-name, com valor definido como o nome do host ESXi
subjacente. Os aplicativos do usuário que querem alta disponibilidade podem configurar
regras podAntiAffinity com este rótulo como o topologyKey para garantir que
seus pods de aplicativo estejam distribuídos em diferentes VMs e hosts físicos.
Também é possível configurar vários pools de nós para um cluster de usuário com armazenamentos
de dados diferentes e rótulos de nós especiais. Da mesma forma, é possível configurar regras podAntiAffinity
com esse rótulo de nó especial como topologyKey para ter uma disponibilidade maior
após falhas do armazenamento de dados.
Para ter alta disponibilidade para cargas de trabalho do usuário, verifique se o cluster de usuário tem um número
suficiente de réplicas em nodePools.replicas. Isso garantirá o número pretendido de nós de trabalho do cluster de usuário
na condição de execução.
É possível usar armazenamentos de dados separados para clusters de administrador e clusters de usuários para isolar as falhas deles.
Balanceador de carga
Há dois tipos de balanceadores de carga que podem ser usados para alta disponibilidade.
Balanceador de carga MetalLB em pacote
Para o
balanceador de carga MetalLB em pacote,
você alcança a alta disponibilidade quando tem mais de um nó com enableLoadBalancer: true.
O MetalLB distribui serviços nos nós do balanceador de carga, mas para um único serviço, há apenas um nó líder processando todo o tráfego para esse serviço.
Durante o upgrade do cluster, há um tempo de inatividade quando os nós do balanceador de carga são atualizados. A duração da interrupção de failover do MetalLB aumenta à medida que o número de nós do balanceador de carga cresce. Com menos de cinco nós, a interrupção ocorre dentro de 10 segundos.
Balanceador de carga da Seesaw em pacote
Para o
balanceador de carga da Seesaw em pacote,
é possível ativar a alta disponibilidade ao definir
loadBalancer.seesaw.enableHA como true no arquivo de configuração do cluster.
Também é preciso ativar uma combinação de aprendizado MAC, transmissões forjadas
e modo variado no grupo de portas do balanceador de carga.
Com a alta disponibilidade, dois balanceadores de carga são configurados em modo ativo-passivo. Se o balanceador de carga ativo tiver um problema, o tráfego fará o failover para o balanceador de carga passivo.
Durante o upgrade de um balanceador de carga, há um tempo de inatividade. Se a alta disponibilidade estiver ativada no balanceador de carga, o tempo máximo de inatividade será de dois segundos.
Balanceador de carga com F5 BIG-IP integrado
A plataforma F5 BIG-IP oferece diversos Serviços para você melhorar a segurança, a disponibilidade e o desempenho dos seus aplicativos. Para o Google Distributed Cloud, o Big-IP fornece acesso externo e serviços de balanceamento de carga L3/4.
Para mais informações, consulte Alta disponibilidade do BIG-IP.
Como usar vários clusters para recuperação de desastres
A implantação de aplicativos em vários clusters em vários vCenters ou plataformas do GKE Enterprise pode fornecer maior disponibilidade global e limitar o raio de impacto durante interrupções.
Essa configuração usa o cluster do GKE Enterprise no data center secundário para recuperação de desastres em vez de configurar um novo cluster. Veja a seguir um resumo completo para conseguir isso:
Crie outro cluster de administrador e um cluster de usuário no data center secundário. Nesta arquitetura de vários clusters, é necessário que os usuários tenham dois clusters de administrador em cada data center, e cada cluster de administrador executa um cluster de usuário.
O cluster de usuário secundário tem um número mínimo de nós de trabalho (três) e está em espera ativa (sempre em execução).
As implantações de aplicativos podem ser replicadas nos dois vCenters usando o Config Sync, ou a abordagem recomendada é usar um conjunto de ferramentas de DevOps (CI/CD, Spinnaker) de aplicativo atual.
No caso de um desastre, o cluster de usuário pode ser redimensionado para o número de nós.
Além disso, é necessário fazer uma alternância de DNS para rotear o tráfego entre os clusters para o data center secundário.