
Gemini Enterprise Agent Platform
Innovationen entwickeln, erstellen und bereitstellen – mit Agenten für Unternehmen
Die Gemini Enterprise Agent Platform ist die umfassende Plattform von Google Cloud, mit der Entwickler KI-Agenten erstellen, skalieren, verwalten und optimieren können. Es ist eine zentrale Plattform für technische Teams, um KI-Agenten zu entwickeln, mit denen sich Unternehmensanwendungen und Workflows in leistungsstarke agentische Systeme umwandeln lassen.
Neukunden erhalten ein Guthaben von bis zu 300 $, um die Agent Platform und andere Google Cloud-Produkte auszuprobieren.
Features
KI-Agenten auf Unternehmensniveau entwickeln, skalieren, verwalten und optimieren
Die Agent Platform ist unsere offene und umfassende Plattform, mit der Unternehmen schnell KI-Agenten in Unternehmensqualität erstellen, skalieren, verwalten und optimieren können, die auf ihren Unternehmensdaten basieren. Die Plattform bietet die Full-Stack-Grundlage und die umfangreichen Entwickleroptionen, die Sie benötigen, um Ihre Anwendungen und Workflows in leistungsstarke agentische Systeme mit globaler Reichweite zu verwandeln.
Agentenbasierte Entwicklung und Workflows
Google Antigravity ist jetzt über die Agent Platform verfügbar und bietet eine zentrale App zum Steuern, Anpassen und Orchestrieren von Agenten. Sie können mehrere Agents gleichzeitig einsetzen, um ganze Workflows wie Produkteinführungen auszuführen. So lassen sich beispielsweise die Codegenerierung für Ihre Website, die Erstellung von Assets im Corporate Design und das Verfassen von E‑Mails an Kunden automatisieren. Laden Sie Antigravity herunter und melden Sie sich mit Ihren Google Cloud-Anmeldedaten bei der Desktop-Anwendung oder der Antigravity CLI an.
Mehr als 200 KI-Modelle und ‑Tools von Google und Drittanbietern
In Model Garden haben Sie die Wahl zwischen den neuesten multimodalen Modellen von Google wie Gemini 3.5, Drittanbietermodellen wie der Claude Model Family von Anthropic und offenen Modellen wie Gemma. Mit einer Vielzahl von Feinabstimmungsoptionen können Sie Modelle an Ihren Anwendungsfall anpassen.
Unser Modellbewertungsdienst bietet Tools auf Unternehmensniveau für eine objektive, datengestützte Bewertung von Modellen, die auf generativer KI basieren.
Offene und integrierte AI Platform
Data Scientists können mit den Agent Platform-Tools zum Trainieren, Abstimmen und Bereitstellen von ML-Modellen schneller arbeiten.
Agent Platform-Notebooks, einschließlich Colab Enterprise oder Workbench (Ihre Wahl), sind nativ in BigQuery eingebunden und bieten eine zentrale Oberfläche für alle Daten- und KI-Arbeitslasten.
Mit dem Agent Platform-Training und Vorhersage können Sie die Trainingszeit reduzieren und Modelle mithilfe von Open-Source-Frameworks Ihrer Wahl und einer optimierten KI-Infrastruktur ganz einfach in der Produktion bereitstellen.
MLOps für prädiktive und generative KI
Die Agent Platform bietet maßgeschneiderte MLOps-Tools für Data Scientists und ML-Entwickler, um ML-Projekte zu automatisieren, zu standardisieren und zu verwalten.
Modulare Tools helfen Ihnen dabei, teamübergreifend zusammenzuarbeiten und Modelle während des gesamten Entwicklungszyklus zu verbessern. Mit Model Evaluation können Sie das beste Modell für einen Anwendungsfall ermitteln und Workflows mit Pipelines orchestrieren, beliebige Modelle mit Model Registry verwalten, ML-Funktionen im Feature Store bereitstellen, freigeben und wiederverwenden sowie Modelle auf Eingabeabweichungen und ‑Drift überwachen.
Funktionsweise
Die Agent Platform bietet mehrere Optionen für die Agentenerstellung, das Modelltraining und die Bereitstellung:
- Mit der Agent Platform können Sie KI-Agenten in Unternehmensqualität auf einer einheitlichen Plattform erstellen, skalieren, verwalten und optimieren.
- Agent Studio bietet Zugriff auf große generative KI-Modelle, einschließlich Gemini 3, damit Sie sie für die Verwendung in KI-Anwendungen bewerten, optimieren und bereitstellen können.
- Mit Model Garden können Sie die Agent Platform erkunden, testen, anpassen und bereitstellen sowie Open-Source-Modelle und Assets auswählen.
- Benutzerdefiniertes Training gibt Ihnen vollständige Kontrolle über den Trainingsprozess. Dazu gehört die Verwendung Ihres bevorzugten ML-Frameworks, das Schreiben eines eigenen Trainingscodes und das Auswählen von Optionen für die Hyperparameter-Abstimmung.
Die Agent Platform bietet mehrere Optionen für die Agentenerstellung, das Modelltraining und die Bereitstellung:
- Mit der Agent Platform können Sie KI-Agenten in Unternehmensqualität auf einer einheitlichen Plattform erstellen, skalieren, verwalten und optimieren.
- Agent Studio bietet Zugriff auf große generative KI-Modelle, einschließlich Gemini 3, damit Sie sie für die Verwendung in KI-Anwendungen bewerten, optimieren und bereitstellen können.
- Mit Model Garden können Sie die Agent Platform erkunden, testen, anpassen und bereitstellen sowie Open-Source-Modelle und Assets auswählen.
- Benutzerdefiniertes Training gibt Ihnen vollständige Kontrolle über den Trainingsprozess. Dazu gehört die Verwendung Ihres bevorzugten ML-Frameworks, das Schreiben eines eigenen Trainingscodes und das Auswählen von Optionen für die Hyperparameter-Abstimmung.
KI-Agenten erstellen und bereitstellen
Mit der Agent Platform erweiterte KI-Funktionen nutzen
Mit der Agent Platform erweiterte KI-Funktionen nutzen
Erstellen Sie produktionsreife Agenten und Anwendungen auf der Basis von generativer KI auf einer Plattform, die mit Ihnen skaliert. Unsere Agent Platform bietet eine sichere Umgebung für die Entwicklung und Bereitstellung von KI-Modellen und ‑Anwendungen.
Für Entwickler bleibt die Agent Platform unsere fortschrittliche Plattform, auf der sie mit Frameworks wie dem Agent Development Kit (ADK) komplexe KI-Agenten erstellen, anpassen und optimieren können.
Mit Codelab durchstarten und noch heute die erste KI-Anwendung erstellen
Tutorials, Kurzanleitungen und Labs
Mit der Agent Platform erweiterte KI-Funktionen nutzen
Mit der Agent Platform erweiterte KI-Funktionen nutzen
Erstellen Sie produktionsreife Agenten und Anwendungen auf der Basis von generativer KI auf einer Plattform, die mit Ihnen skaliert. Unsere Agent Platform bietet eine sichere Umgebung für die Entwicklung und Bereitstellung von KI-Modellen und ‑Anwendungen.
Für Entwickler bleibt die Agent Platform unsere fortschrittliche Plattform, auf der sie mit Frameworks wie dem Agent Development Kit (ADK) komplexe KI-Agenten erstellen, anpassen und optimieren können.
Mit Codelab durchstarten und noch heute die erste KI-Anwendung erstellen
Mit Gemini-Modellen entwickeln
Mit Agent Studio loslegen
Mit Agent Studio loslegen
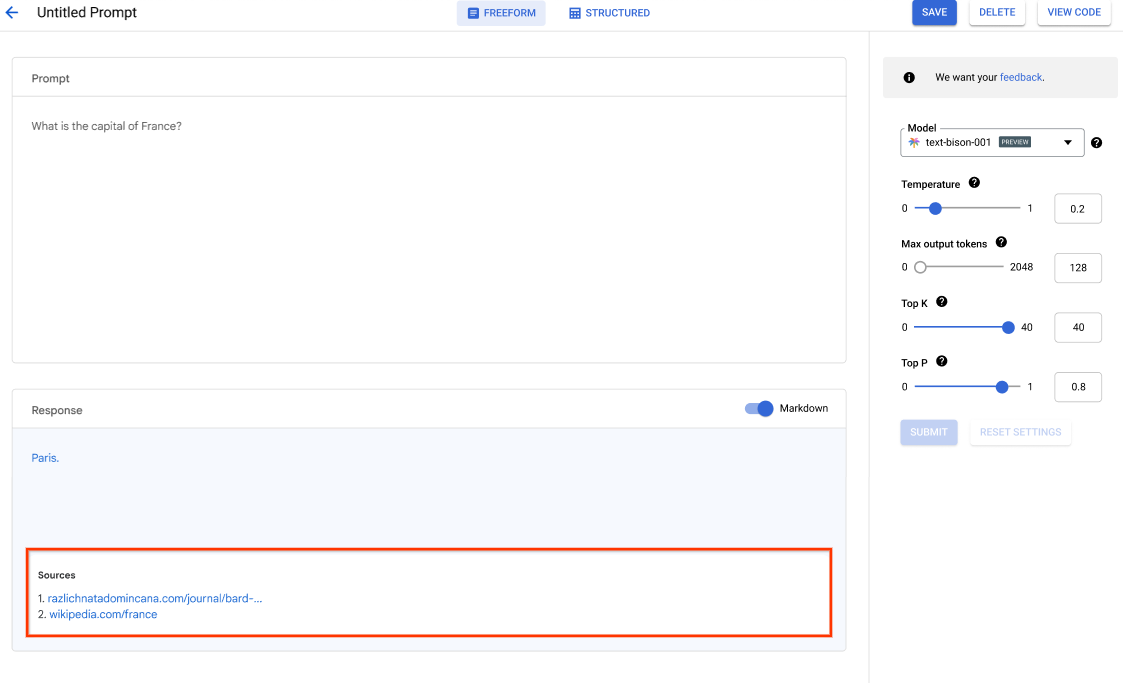
Mit Agent Studio können Sie Prompts für Gemini-Modelle in natürlicher Sprache, mit Code, Bildern oder Videos entwerfen, testen und verwalten. Probieren Sie Beispiel-Prompts aus, um Text aus Bildern zu extrahieren, Bild-Mock-ups in HTML zu konvertieren und sogar Antworten zu hochgeladenen Bildern oder Videos zu generieren.
Sie können Gemini auf der Agent Platform auch mit einem API-Schlüssel testen.
Zugriff auf Gemini-Modelle über die Gemini API in der Agent Platform
- Python
- JavaScript
- Java
- Go
- Curl
Tutorials, Kurzanleitungen und Labs
Mit Agent Studio loslegen
Mit Agent Studio loslegen
Mit Agent Studio können Sie Prompts für Gemini-Modelle in natürlicher Sprache, mit Code, Bildern oder Videos entwerfen, testen und verwalten. Probieren Sie Beispiel-Prompts aus, um Text aus Bildern zu extrahieren, Bild-Mock-ups in HTML zu konvertieren und sogar Antworten zu hochgeladenen Bildern oder Videos zu generieren.
Sie können Gemini auf der Agent Platform auch mit einem API-Schlüssel testen.
Codebeispiel
Zugriff auf Gemini-Modelle über die Gemini API in der Agent Platform
- Python
- JavaScript
- Java
- Go
- Curl
Daten extrahieren, zusammenfassen und klassifizieren
Generative KI zur Zusammenfassung, Klassifizierung und Extraktion verwenden
Generative KI zur Zusammenfassung, Klassifizierung und Extraktion verwenden
Hier erfahren Sie, wie Sie mit der generativen KI von Agent Platform Prompts für die Verarbeitung einer beliebigen Anzahl von Aufgaben erstellen. Zu den gängigsten Aufgaben zählen Klassifizierung, Zusammenfassung und Extraktion. Mit Gemini auf der Agent Platform können Sie Prompts in Bezug auf Struktur und Format flexibel entwerfen.
Tutorials, Kurzanleitungen und Labs
Generative KI zur Zusammenfassung, Klassifizierung und Extraktion verwenden
Generative KI zur Zusammenfassung, Klassifizierung und Extraktion verwenden
Hier erfahren Sie, wie Sie mit der generativen KI von Agent Platform Prompts für die Verarbeitung einer beliebigen Anzahl von Aufgaben erstellen. Zu den gängigsten Aufgaben zählen Klassifizierung, Zusammenfassung und Extraktion. Mit Gemini auf der Agent Platform können Sie Prompts in Bezug auf Struktur und Format flexibel entwerfen.
Modell für die Produktion bereitstellen
Für Batch- oder Onlinevorhersagen bereitstellen
Für Batch- oder Onlinevorhersagen bereitstellen
Wenn Sie mit Ihrem Modell ein Problem in der realen Welt lösen möchten, registrieren Sie es in Model Registry und verwenden dann den Vorhersagedienst der Agent Platform für Batch- und Onlinevorhersagen.
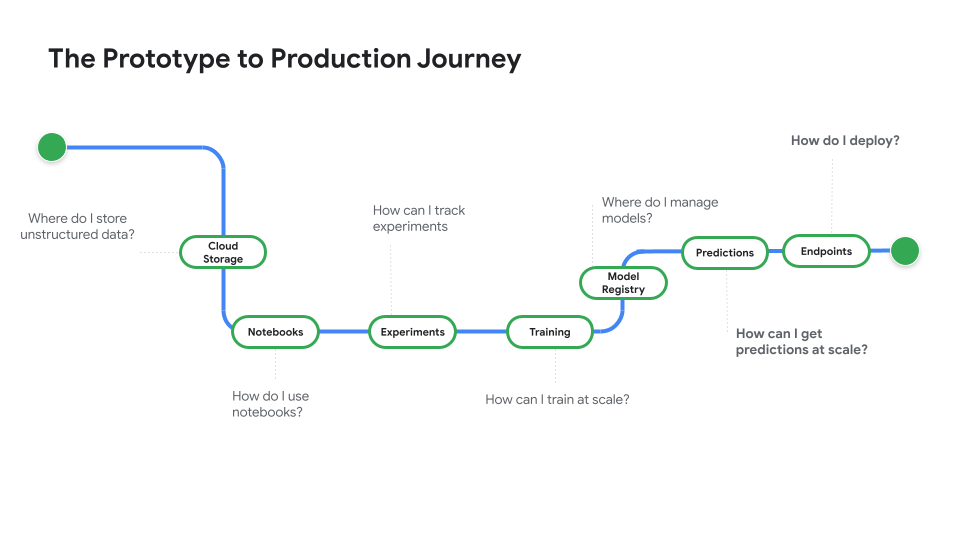
Sehen Sie sich die Videoreihe Von Prototyp zur Produktion an, die Sie vom Notebook-Code bis zu einem bereitgestellten Modell führt.
Tutorials, Kurzanleitungen und Labs
Für Batch- oder Onlinevorhersagen bereitstellen
Für Batch- oder Onlinevorhersagen bereitstellen
Wenn Sie mit Ihrem Modell ein Problem in der realen Welt lösen möchten, registrieren Sie es in Model Registry und verwenden dann den Vorhersagedienst der Agent Platform für Batch- und Onlinevorhersagen.
Sehen Sie sich die Videoreihe Von Prototyp zur Produktion an, die Sie vom Notebook-Code bis zu einem bereitgestellten Modell führt.
Benutzerdefinierte Modelle trainieren
Benutzerdefiniertes ML-Training – Übersicht und Dokumentation
Benutzerdefiniertes ML-Training – Übersicht und Dokumentation
Verschaffen Sie sich einen Überblick über den benutzerdefinierten Trainingsworkflow in Agent Platform, die Vorteile des benutzerdefinierten Trainings und die verschiedenen verfügbaren Trainingsoptionen. Außerdem werden auf dieser Seite alle Schritte im ML-Trainingsworkflow beschrieben, von der Vorbereitung der Daten bis hin zu Vorhersagen.
In dieser detaillierten Videoanleitung wird beschrieben, wie benutzerdefinierte Modelle auf der Agent Platform trainiert werden können.
Tutorials, Kurzanleitungen und Labs
Benutzerdefiniertes ML-Training – Übersicht und Dokumentation
Benutzerdefiniertes ML-Training – Übersicht und Dokumentation
Verschaffen Sie sich einen Überblick über den benutzerdefinierten Trainingsworkflow in Agent Platform, die Vorteile des benutzerdefinierten Trainings und die verschiedenen verfügbaren Trainingsoptionen. Außerdem werden auf dieser Seite alle Schritte im ML-Trainingsworkflow beschrieben, von der Vorbereitung der Daten bis hin zu Vorhersagen.
In dieser detaillierten Videoanleitung wird beschrieben, wie benutzerdefinierte Modelle auf der Agent Platform trainiert werden können.
Preise
| Preise für die Agent Platform | Sie zahlen für die verwendeten Tools, Speichermengen, Rechenleistungen und Cloud-Ressourcen der Agent Platform. Neukundinnen und Neukunden erhalten ein Guthaben von 300 $, um die Agent Platform und andere Google Cloud-Produkte auszuprobieren. | |
|---|---|---|
| Tools und Nutzung | Beschreibung | Preis |
Generative KI | Imagen-Modell für die Bildgenerierung Basierend auf den Preisen für Bild- und Zeicheneingabe oder für das benutzerdefinierte Training. | Ab 0,0001 $ |
Text-, Chat- und Codegenerierung Basierend auf jeweils 1.000 Zeichen Eingabe (Prompt) und je 1.000 Zeichen Ausgabe (Antwort). | Ab 0,0001 $ pro 1.000 Zeichen | |
Benutzerdefinierte Modelle | Training von benutzerdefiniertem Modell Basierend auf dem pro Stunde verwendeten Maschinentyp, der Region und den verwendeten Beschleunigern. Erhalten Sie einen Kostenvoranschlag von unserem Verkaufsteam oder über unseren Preisrechner. | Vertrieb kontaktieren |
Agent Platform-Notebooks | Computing- und Speicherressourcen Basiert auf den Preisen, die auch für Compute Engine und Cloud Storage gelten. | Weitere Informationen im Abschnitt „Produkte“ |
Verwaltungsgebühren Zusätzlich zur oben genannten Ressourcennutzung fallen Verwaltungsgebühren je nach Instanzen, Notebooks und verwalteten Notebooks sowie der verwendeten Region an. Details ansehen. | Weitere Informationen | |
Agent Platform-Pipelines | Ausführungs- und zusätzliche Gebühren Basierend auf der Ausführungsgebühr, den verwendeten Ressourcen und möglichen zusätzlichen Servicegebühren. | Ab 0,03 $ Pro Pipelineausführung |
Vektorsuche in der Agent Platform | Kosten für Bereitstellung und Erstellung Abhängig von der Größe Ihrer Daten, der Anzahl der Abfragen pro Sekunde, die Sie ausführen möchten, und der Anzahl der verwendeten Knoten. Beispiel ansehen. | Weitere Informationen im Beispiel |
Preisinformationen für alle Funktionen und Dienste der Agent Platform ansehen.
Preise für die Agent Platform
Sie zahlen für die verwendeten Tools, Speichermengen, Rechenleistungen und Cloud-Ressourcen der Agent Platform. Neukundinnen und Neukunden erhalten ein Guthaben von 300 $, um die Agent Platform und andere Google Cloud-Produkte auszuprobieren.
Generative KI
Imagen-Modell für die Bildgenerierung
Basierend auf den Preisen für Bild- und Zeicheneingabe oder für das benutzerdefinierte Training.
Starting at
0,0001 $
Text-, Chat- und Codegenerierung
Basierend auf jeweils 1.000 Zeichen Eingabe (Prompt) und je 1.000 Zeichen Ausgabe (Antwort).
Starting at
0,0001 $
pro 1.000 Zeichen
Benutzerdefinierte Modelle
Training von benutzerdefiniertem Modell
Basierend auf dem pro Stunde verwendeten Maschinentyp, der Region und den verwendeten Beschleunigern. Erhalten Sie einen Kostenvoranschlag von unserem Verkaufsteam oder über unseren Preisrechner.
Vertrieb kontaktieren
Agent Platform-Notebooks
Computing- und Speicherressourcen
Basiert auf den Preisen, die auch für Compute Engine und Cloud Storage gelten.
Weitere Informationen im Abschnitt „Produkte“
Verwaltungsgebühren
Zusätzlich zur oben genannten Ressourcennutzung fallen Verwaltungsgebühren je nach Instanzen, Notebooks und verwalteten Notebooks sowie der verwendeten Region an. Details ansehen.
Weitere Informationen
Agent Platform-Pipelines
Ausführungs- und zusätzliche Gebühren
Basierend auf der Ausführungsgebühr, den verwendeten Ressourcen und möglichen zusätzlichen Servicegebühren.
Starting at
0,03 $
Pro Pipelineausführung
Vektorsuche in der Agent Platform
Kosten für Bereitstellung und Erstellung
Abhängig von der Größe Ihrer Daten, der Anzahl der Abfragen pro Sekunde, die Sie ausführen möchten, und der Anzahl der verwendeten Knoten. Beispiel ansehen.
Weitere Informationen im Beispiel
Preisinformationen für alle Funktionen und Dienste der Agent Platform ansehen.
Proof of Concept starten
Anwendungsszenario
Das volle Potenzial von generativer KI nutzen

„Die Präzision der Lösung für generative KI von Google Cloud und die praktische Funktion der Agent Platform gibt uns die Zuversicht, dass wir mit der Implementierung dieser hochmodernen Technologie in das Herzstück unseres Unternehmens unser langfristiges Ziel einer Reaktionszeit von null Minuten erreichen werden.“
Abdol Moabery, CEO von GA Telesis
Analystenberichte
Google wird im Bericht „IDC MarketScape: Worldwide GenAI Life-Cycle Foundation Model Software 2025“ als einer der führenden Anbieter genannt. Bericht herunterladen
Google wird im Gartner-Bericht „Magic Quadrant™ for AI Application Development Platforms, Q4 2025“ als einer der führenden Anbieter eingestuft. Bericht lesen
Google wird im Bericht „The Forrester Wave™: AI/ML Platforms, Q3 2024“ als ein führender Anbieter eingestuft. Bericht lesen











