本文档介绍如何测试和监控部署到 AI Platform Prediction 的机器学习 (ML) 模型的在线服务性能。本文档使用 Locust,这是一种用于负载测试的开源工具。
本文档适用于想要监控其生产环境中机器学习模型的服务工作负载、延迟时间和资源利用率的数据科学家和 MLOps 工程师。
本文档假定您具有一定的 Google Cloud、TensorFlow、AI Platform Prediction、Cloud Monitoring 和 Jupyter 笔记本的经验。
本文档附带一个 GitHub 代码库,其中包含用于实现本文档中所述系统的代码和部署指南。这些任务已整合到 Jupyter 笔记本中。
费用
您在本文档中使用的笔记本采用 Google Cloud的以下收费组件:
- Vertex AI Workbench 用户管理的笔记本
- AI Platform Prediction
- Cloud Storage
- Cloud Monitoring
- Google Kubernetes Engine (GKE)
如需根据您的预计使用量来估算费用,请使用价格计算器。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
架构概览
下图展示了用于部署机器学习模型以进行在线预测、运行负载测试以及收集和分析机器学习模型服务性能指标的系统架构。
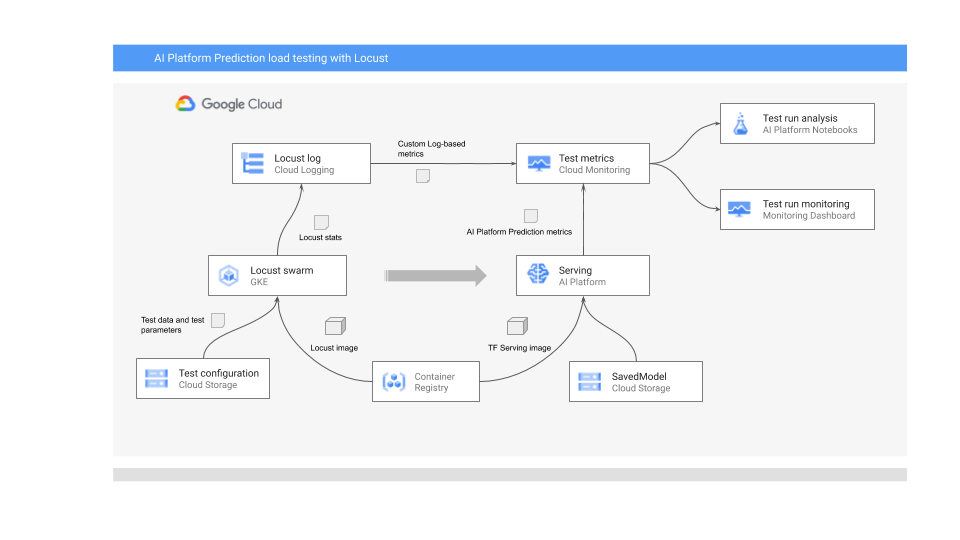
下图展示了以下流程:
- 经过训练的模型可能位于 Cloud Storage 中,例如 TensorFlow SavedModel 或 scikit-learn joblib。或者,它也可能合并到 Container Registry 的自定义服务容器中,例如,用于提供 PyTorch 模型的 TorchServe。
- 该模型作为 REST API 部署到 AI Platform Prediction。AI Platform Prediction 是一项全代管式模型服务,支持不同的机器类型、基于资源利用率的自动扩缩,还支持各种 GPU 加速器。
- Locust 用于实现测试任务(即用户行为)。为此,它会调用已部署到 AI Platform Prediction 的机器学习模型,并在 Google Kubernetes Engine (GKE) 上大规模运行该模型。这会模拟用户同时进行多个调用来负载测试模型预测服务的情况。您可以使用 Locust 网页界面监控测试的进度。
- Locust 将测试统计信息记录到 Cloud Logging。Locust 测试创建的日志条目用于定义 Cloud Monitoring 中的一组基于日志的指标。这些指标是标准 AI Platform Prediction 指标的补充。
- AI Platform 指标和自定义 Locust 指标均可实时直观呈现在 Cloud Monitoring 信息中心中。测试完成后,系统还会以编程方式收集指标,以便您分析和直观呈现 Vertex AI Workbench 用户管理的笔记本中的指标。
此场景中的 Jupyter 笔记本
准备和部署模型、运行 Locust 测试以及收集和分析测试结果等所有任务都在以下 Jupyter 笔记本中进行编码。如需执行任务,您需要运行每个笔记本中的单元序列。
01-prepare-and-deploy.ipynb。运行此笔记本以准备用于提供服务的 TensorFlow SavedModel,并将模型部署到 AI Platform Prediction。02-perf-testing.ipynb。运行此笔记本以在 Cloud Monitoring 中为 Locust 测试创建基于日志的指标,以及将 Locust 测试部署到 GKE 并运行它。03-analyze-results.ipynb。运行此笔记本以从 Cloud Monitoring 创建的标准 AI Platform 指标以及自定义 Locust 指标收集和分析 Locust 负载测试结果。
初始化环境
如关联的 GitHub 代码库的 README.md 文件中所述,您需要执行以下步骤准备环境来运行笔记本:
- 在您的 Google Cloud 项目中,创建一个 Cloud Storage 存储桶,用于存储经过训练的模型和 Locust 测试配置。请记下用于存储桶的名称,因为稍后需要用到。
- 在您的项目中创建 Cloud Monitoring 工作区。
- 创建具有所需 CPU 的 Google Kubernetes Engine 集群。节点池必须有权访问 Cloud API。
- 创建使用 TensorFlow 2 的 Vertex AI Workbench 用户管理笔记本实例。在本教程中,您不需要 GPU,因为您不需要训练模型。(GPU 在其他场景中可能很有用,特别是用于加快模型训练。)
打开 JupyterLab
如需完成此场景的任务,您需要打开 JupyterLab 环境并获取笔记本。
在 Google Cloud Console 中,前往 Notebooks 页面。
在用户管理的笔记本标签页上,点击您创建的笔记本环境旁边的打开 Jupyterlab。
这将在浏览器中打开 JupyterLab 环境。
如需启动终端标签,请点击启动器标签页中的终端图标。
在终端中,克隆
mlops-on-gcpGitHub 代码库:git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.git命令完成后,您会在文件浏览器中看到
mlops-on-gcp文件夹。 在该文件夹中,您会看到在本文档中使用的笔记本。
配置笔记本设置
在本部分中,您将使用特定于您的上下文的值设置笔记本中的变量,并准备环境以运行适用于该场景的代码。
- 导航到
model_serving/caip-load-testing目录。 - 对于这三个笔记本中的每个笔记本,请执行以下操作:
- 打开笔记本。
- 运行配置 Google Cloud 环境设置下的单元。
以下各部分重点介绍了过程的主要部分,并解释了设计和代码的各个方面。
提供模型以进行在线预测
本文档中使用的机器学习模型使用 TensorFlow Hub 中预先经过训练的 ResNet V2 101 图片分类模型。但是,您可调整本文档中的系统设计模式和技术,使其适应其他领域和其他类型的模型。
用于准备和提供 ResNet 101 模型的代码位于 01-prepare-and-deploy.ipynb 笔记本中。在笔记本中运行这些单元以执行以下任务:
- 从 TensorFlow Hub 下载并运行 ResNet 模型。
- 为模型创建服务签名。
- 将该模型导出为 SavedModel。
- 将 SavedModel 部署到 AI Platform Prediction。
- 验证已部署的模型。
本文档中的后续部分详细介绍了如何准备 ResNet 模型以及如何进行部署。
准备 ResNet 模型以进行部署
TensorFlow Hub 中的 ResNet 模型没有服务签名,因为它针对重组和微调进行了优化。因此,您需要为模型创建服务签名,以便可以提供模型用于在线预测。
此外,为了提供模型,我们建议您将特征工程逻辑嵌入服务接口中。这样做可以保证预处理与模型服务之间的关联,而不是依赖于客户端应用以所需的格式预处理数据。您还必须在服务接口中添加后处理,例如将类 ID 转换为类标签。
为使 ResNet 模型可用,您需要实现描述模型推理方法的服务签名。因此,笔记本代码会添加两个签名:
- 默认签名。此签名公开了 ResNet V2 101 模型的默认
predict方法。默认方法没有预处理逻辑或后处理逻辑。 - 预处理和后处理签名。此接口的预期输入需要相对复杂的预处理,包括编码、扩缩和归一化图片。因此,该模型还公开了一个替代签名,它用于嵌入预处理和后处理逻辑。此签名接受未处理的原始图片,并返回一个包含已排序的类标签和关联的标签概率的列表。
签名是在自定义模块类中创建的。该类派生自封装 ResNet 模型的 tf.Module 基类。自定义类通过实现图片预处理和输出后处理逻辑的方法扩展基类。自定义模块的默认方法会映射到基础 ResNet 模型的默认方法,来维持类似的接口。自定义模块导出为 SavedModel,其中包含原始模型、预处理逻辑和两个服务签名。
以下代码段展示了自定义模块类的实现:
LABELS_KEY = 'labels'
PROBABILITIES_KEY = 'probabilities'
NUM_LABELS = 5
class ServingModule(tf.Module):
"""
A custom tf.Module that adds image preprocessing and output post processing to
a base TF 2 image classification model from TensorFlow Hub.
"""
def __init__(self, base_model, input_size, output_labels):
super(ServingModule, self).__init__()
self._model = base_model
self._input_size = input_size
self._output_labels = tf.constant(output_labels, dtype=tf.string)
def _decode_and_scale(self, raw_image):
"""
Decodes, crops, and resizes a single raw image.
"""
image = tf.image.decode_image(raw_image, dtype=tf.dtypes.uint8, expand_animations=False)
image_shape = tf.shape(image)
image_height = image_shape[0]
image_width = image_shape[1]
crop_size = tf.minimum(image_height, image_width)
offset_height = ((image_height - crop_size) + 1) // 2
offset_width = ((image_width - crop_size) + 1) // 2
image = tf.image.crop_to_bounding_box(image, offset_height, offset_width, crop_size, crop_size)
image = tf.image.resize(image, [self._input_size, self._input_size])
image = tf.cast(image, tf.uint8)
return image
def _preprocess(self, raw_inputs):
"""
Preprocesses raw inputs as sent by the client.
"""
# A mitigation for https://github.com/tensorflow/tensorflow/issues/28007
with tf.device('/cpu:0'):
images = tf.map_fn(self._decode_and_scale, raw_inputs, dtype=tf.uint8)
images = tf.image.convert_image_dtype(images, tf.float32)
return images
def _postprocess(self, model_outputs):
"""
Postprocess outputs returned by the base model.
"""
probabilities = tf.nn.softmax(model_outputs)
indices = tf.argsort(probabilities, axis=1, direction='DESCENDING')
return {
LABELS_KEY: tf.gather(self._output_labels, indices, axis=-1)[:,:NUM_LABELS],
PROBABILITIES_KEY: tf.sort(probabilities, direction='DESCENDING')[:,:NUM_LABELS]
}
@tf.function(input_signature=[tf.TensorSpec([None, 224, 224, 3], tf.float32)])
def __call__(self, x):
"""
A pass-through to the base model.
"""
return self._model(x)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def predict_labels(self, raw_images):
"""
Preprocesses inputs, calls the base model
and postprocess outputs from the base model.
"""
# Call the preprocessing handler
images = self._preprocess(raw_images)
# Call the base model
logits = self._model(images)
# Call the postprocessing handler
outputs = self._postprocess(logits)
return outputs
serving_module = ServingModule(model, 224, imagenet_labels)
以下代码段展示了模型如何导出为 SavedModel,其中包含之前定义的服务签名:
...
default_signature = serving_module.__call__.get_concrete_function()
preprocess_signature = serving_module.predict_labels.get_concrete_function()
signatures = {
'serving_default': default_signature,
'serving_preprocess': preprocess_signature
}
tf.saved_model.save(serving_module, model_path, signatures=signatures)
将模型部署到 AI Platform Prediction
将模型导出为 SavedModel 时,系统将执行以下任务:
- 系统将该模型上传到 Cloud Storage。
- 系统在 AI Platform Prediction 中创建模型对象。
- 系统为 SavedModel 创建模型版本。
笔记本中的以下代码段展示了执行这些任务的命令。
gcloud storage cp {model_path} {GCS_MODEL_LOCATION} --recursive
gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT_ID} \
--regions {REGION}
MACHINE_TYPE='n1-standard-8'
ACCELERATOR='count=1,type=nvidia-tesla-p4'
gcloud beta ai-platform versions create {MODEL_VERSION} \
--model={MODEL_NAME} \
--origin={GCS_MODEL_LOCATION} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--machine-type={MACHINE_TYPE} \
--accelerator={ACCELERATOR} \
--project={PROJECT_ID}
该命令会为模型预测服务以及 nvidia-tesla-p4 GPU 加速器创建 n1-standard-8 机器类型。
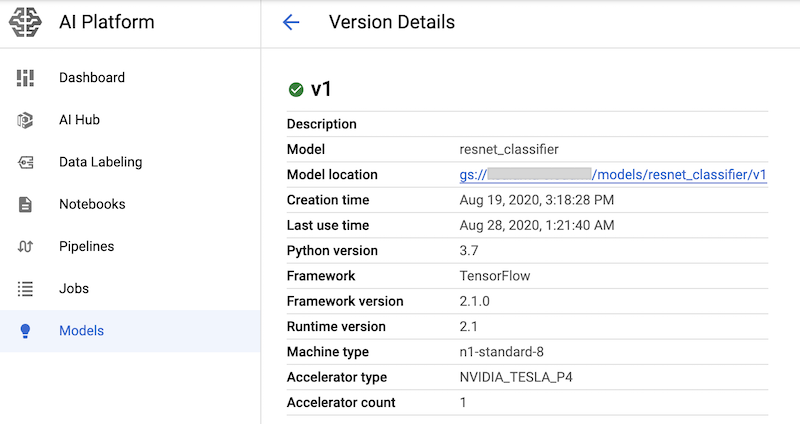
运行包含这些命令的笔记本单元后,您可以在 Google Cloud 控制台的 AI Platform 模型页面中查看模型版本,从而验证模型版本是否已部署。输出内容类似如下:
创建 Cloud Monitoring 指标
设置模型以提供服务后,您可以配置指标来监控服务性能。用于配置指标的代码位于 02-perf-testing.ipynb 笔记本中。
02-perf-testing.ipynb 笔记本的第一个部分使用 Python Cloud Logging SDK 在 Cloud Monitoring 中创建自定义的基于日志的指标。这些指标基于由 Locust 任务生成的日志条目。log_stats 方法会将日志条目写入名为 locust 的 Cloud Logging 日志。
每个日志条目都包含一组 JSON 格式的键值对,如下表所列。这些指标基于日志条目中的部分键。
| 键 | 值的说明 | 用量 |
|---|---|---|
test_id
|
测试 ID | 过滤 特性 |
model |
AI Platform Prediction 模型名称 | |
model_version |
AI Platform Prediction 模型版本 | |
latency
|
第 95 百分位的响应时间,该时间在 10 秒的滑动窗口中计算得出 | 指标 值 |
num_requests |
自测试开始以来的请求总数 | |
num_failures |
自测试开始以来的失败总数 | |
user_count |
模拟用户的数量 | |
rps |
每秒请求数 |
以下代码段显示了笔记本中创建基于日志的自定义指标的 create_locust_metric 函数。
def create_locust_metric(
metric_name:str,
log_path:str,
value_field:str,
bucket_bounds:List[int]):
metric_path = logging_client.metric_path(PROJECT_ID, metric_name)
log_entry_filter = 'resource.type=global AND logName={}'.format(log_path)
metric_descriptor = {
'metric_kind': 'DELTA',
'value_type': 'DISTRIBUTION',
'labels': [{'key': 'test_id', 'value_type': 'STRING'},
{'key': 'signature', 'value_type': 'STRING'}]}
bucket_options = {
'explicit_buckets': {'bounds': bucket_bounds}}
value_extractor = 'EXTRACT(jsonPayload.{})'.format(value_field)
label_extractors = {
'test_id': 'EXTRACT(jsonPayload.test_id)',
'signature': 'EXTRACT(jsonPayload.signature)'}
metric = logging_v2.types.LogMetric(
name=metric_name,
filter=log_entry_filter,
value_extractor=value_extractor,
bucket_options=bucket_options,
label_extractors=label_extractors,
metric_descriptor=metric_descriptor,
)
try:
logging_client.get_log_metric(metric_path)
print('Metric: {} already exists'.format(metric_path))
except:
logging_client.create_log_metric(parent, metric)
print('Created metric {}'.format(metric_path))
以下代码段展示了如何在笔记本中调用 create_locust_metric 方法来创建上表中显示的四个自定义 Locust 指标。
# user count metric
metric_name = 'locust_users'
value_field = 'user_count'
bucket_bounds = [1, 16, 32, 64, 128]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# latency metric
metric_name = 'locust_latency'
value_field = 'latency'
bucket_bounds = [1, 50, 100, 200, 500]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# failure count metric
metric_name = 'num_failures'
value_field = 'num_failures'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# request count metric
metric_name = 'num_requests'
value_field = 'num_requests'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
笔记本会创建一个名为 AI Platform Prediction 和 Locust 的自定义 Cloud Monitoring 信息中心。信息中心会组合标准 AI Platform Prediction 指标和根据 Locust 日志创建的自定义指标。
如需了解详情,请参阅 Cloud Logging API 文档。
您可以手动创建此信息中心及其图表。不过,该笔记本提供了一种使用 monitoring-template.json JSON 模板创建它的编程方式。该代码使用 DashboardsServiceClient 类加载 JSON 模板,并在 Cloud Monitoring 中创建信息中心,如以下代码段所示:
parent = 'projects/{}'.format(PROJECT_ID)
dashboard_template_file = 'monitoring-template.json'
with open(dashboard_template_file) as f:
dashboard_template = json.load(f)
dashboard_proto = Dashboard()
dashboard_proto = ParseDict(dashboard_template, dashboard_proto)
dashboard = dashboard_service_client.create_dashboard(parent, dashboard_proto)
创建信息中心后,您可以在 Google Cloud 控制台的 Cloud Monitoring 信息中心列表中看到它:
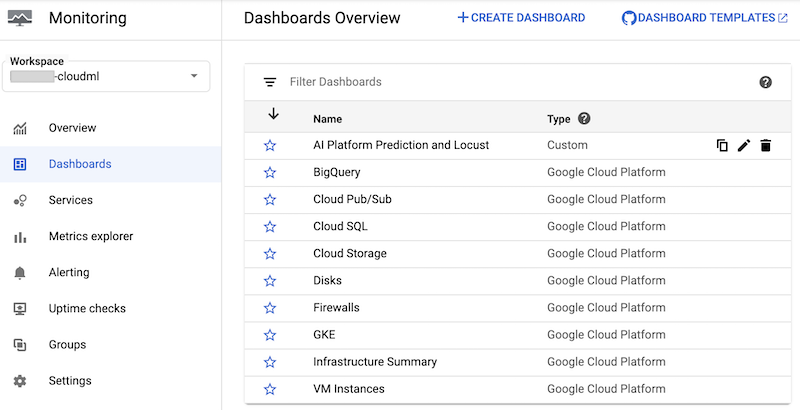
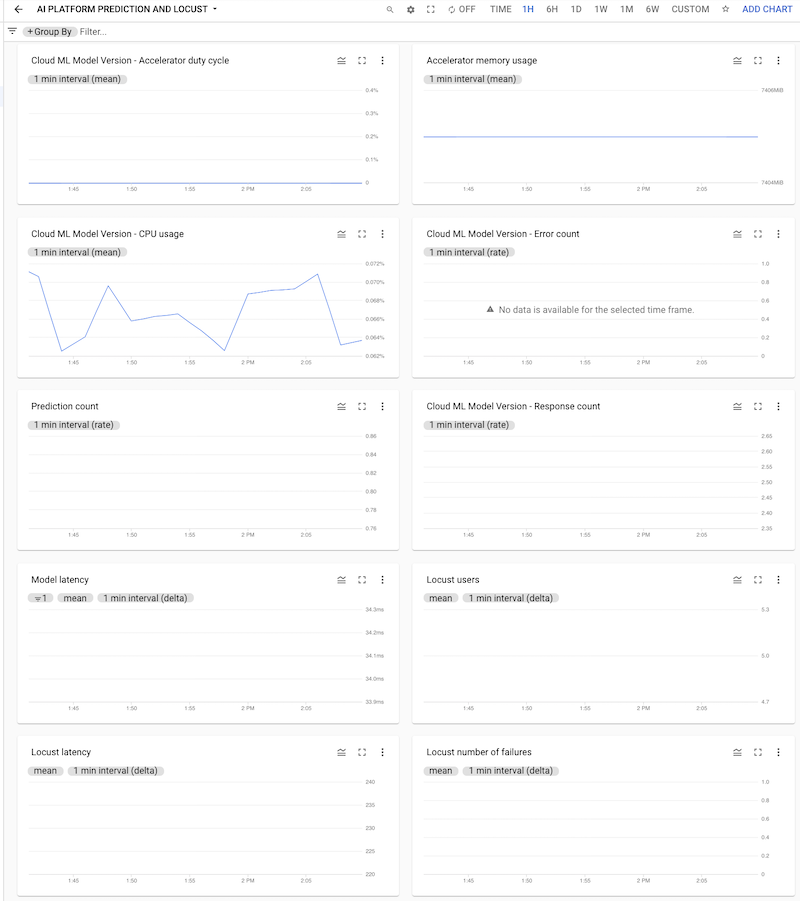
您可以点击信息中心将其打开,然后查看图表。每个图表都会显示来自 AI Platform Prediction 或 Locust 日志的指标,如以下屏幕截图所示。
将 Locust 测试部署到 GKE 集群
在将 Locust 系统部署到 GKE 之前,您需要构建 Docker 容器映像,其中包含 task.py 文件中内置的测试逻辑。该映像派生自 baseline locust.io 映像,并用于 Locust 主节点和工作器 pod。
用于构建和部署的逻辑位于笔记本的 3. 将 Locust 部署到 GKE 集群下。该映像使用以下代码构建:
image_uri = 'gcr.io/{}/locust'.format(PROJECT_ID)
!gcloud builds submit --tag {image_uri} locust/locust-image
笔记本中描述的部署过程是使用 Kustomize 定义的。Locust Kustomize 部署清单定义了以下文件,这些文件定义了组件:
locust-master。此文件定义了一个部署,用于托管一个网页界面,您可在其中开始测试并查看实时统计信息。locust-worker。此文件定义了一个部署,用于运行任务以对机器学习模型预测服务进行负载测试。通常,系统会创建多个工作器来模拟多个用户同时调用预测服务 API 的效果。locust-worker-service。此文件定义了一项服务,用于通过 HTTP 负载均衡器访问locust-master中的网页界面。
在部署集群之前,您需要更新默认清单。默认清单包含 kustomization.yaml 和 patch.yaml 文件。您必须在这两个文件中进行更改。
在 kustomization.yaml 文件中,执行以下操作:
- 设置自定义 Locust 映像的名称。将
images部分中的newName字段设置为您之前构建的自定义映像的名称。 - (可选)设置工作器 Pod 的数量。默认配置会部署 32 个工作器 Pod。要更改数量,请修改
replicas部分中的count字段。确保您的 GKE 集群具有足够数量的 Locust 工作器 CPU。 - 为测试配置和载荷文件设置 Cloud Storage 存储桶。在
configMapGenerator部分中,确保设置以下内容:LOCUST_TEST_BUCKET。将此项设置为您之前创建的 Cloud Storage 存储桶的名称。LOCUST_TEST_CONFIG。将此项设置为测试配置文件名。在 YAML 文件中,此项设置为test-config.json,但如果您要使用其他名称,可以更改此项。LOCUST_TEST_PAYLOAD。将此项设置为测试载荷文件名。在 YAML 文件中,此项设置为test-payload.json,但如果您要使用其他名称,可以更改此项。
在 patch.yaml 文件中,执行以下操作:
- (可选)修改托管 Locust 主实例和工作器的节点池。如果将 Locust 工作负载部署到
default-pool以外的节点池,请找到matchExpressions部分,然后在values下更新 Locust 工作负载将部署到的节点池的名称。
进行这些更改后,您可以将自定义设置构建到 Kustomize 清单中,并将 Locust 部署(locust-master、locust-worker 和 locust-master-service)应用到 GKE 集群。笔记本中的以下命令用于执行这些任务:
!kustomize build locust/manifests | kubectl apply -f -
您可以在 Google Cloud 控制台中检查已部署的工作负载。输出内容类似如下:
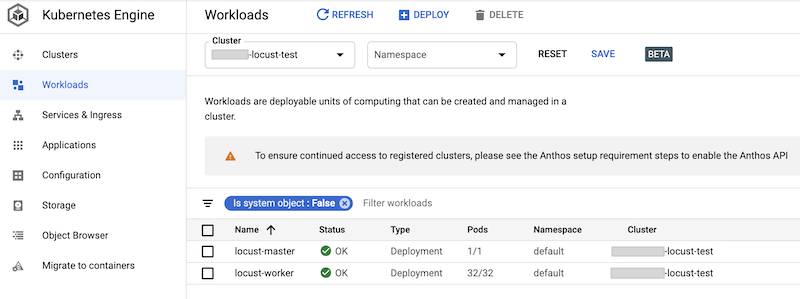
实现 Locust 负载测试
Locust 的测试任务是调用已部署到 AI Platform Prediction 的模型。
此任务在 AIPPClient 类中实现,该类位于 /locust/locust-image/ 文件夹中的 task.py 模块。以下代码段展示了类实现。
class AIPPClient(object):
"""
A convenience wrapper around AI Platform Prediction REST API.
"""
def __init__(self, service_endpoint):
logging.info(
"Setting the AI Platform Prediction service endpoint: {}".format(service_endpoint))
credentials, _ = google.auth.default()
self._authed_session = AuthorizedSession(credentials)
self._service_endpoint = service_endpoint
def predict(self, project_id, model, version, signature, instances):
"""
Invokes the predict method on the specified signature.
"""
url = '{}/v1/projects/{}/models/{}/versions/{}:predict'.format(
self._service_endpoint, project_id, model, version)
request_body = {
'signature_name': signature,
'instances': instances
}
response = self._authed_session.post(url, data=json.dumps(request_body))
return response
task.py 文件中的 AIPPUser 类继承自 locust.User 类来模拟调用 AI Platform Prediction 模型的用户行为。此行为是在 predict_task 方法中实现的。AIPPUser 类的 on_start 方法会从 Cloud Storage 存储桶下载以下文件,该存储桶是在 task.py 文件中的 LOCUST_TEST_BUCKET 变量中指定的。
test-config.json。此 JSON 文件包括测试的以下配置:test_id、project_id、model、version。test-payload.json。此 JSON 文件包含 AI Platform Prediction 预期格式的数据实例以及目标签名。
用于准备测试数据和测试配置的代码包含在 02-perf-testing.ipynb 笔记本中的4. 配置 Locust 测试。
测试配置和数据实例用作 AIPPClient 类中 predict 方法的参数,以使用所需的测试数据测试目标模型。AIPPUser 会模拟单个用户的两次调用之间等待时间(1 到 2 秒)。
运行 Locust 测试
运行笔记本单元以将 Locust 工作负载部署到 GKE 集群后,并且在创建 test-config.json 和 test-payload.json 文件然后将这些文件上传到 Cloud Storage 后,您可以使用新 Locust 负载测试的网页界面来启动、停止和配置该测试。笔记本中的代码会使用以下命令检索公开该网页界面的外部负载均衡器的网址:
%%bash
IP_ADDRESS=$(kubectl get service locust-master | awk -v col=4 'FNR==2{print $col}')
echo http://$IP_ADDRESS:8089
如需执行测试,请执行以下操作:
- 在浏览器中,输入您检索的网址。
如需使用不同的配置模拟测试工作负载,请在 Locust 界面中输入值,如下所示:
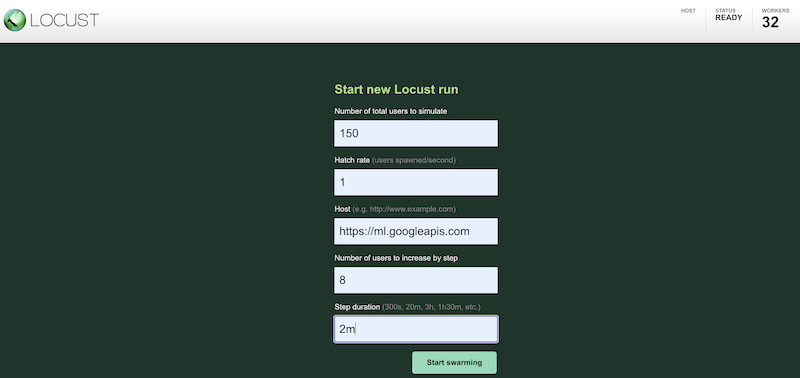
上面的屏幕截图展示了以下配置值:
- 要模拟的用户总数:
150 - 填充率:
1 - 主机:
http://ml.googleapis.com - 逐步增加的用户数:
10 - 单步时长:
2m
- 要模拟的用户总数:
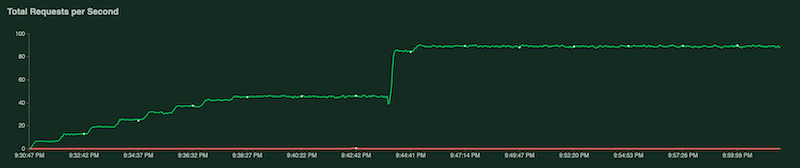
测试运行时,您可以通过检查 Locust 图表来监控测试。以下屏幕截图显示了值的显示方式。
其中一个图表展示了每秒请求总数:
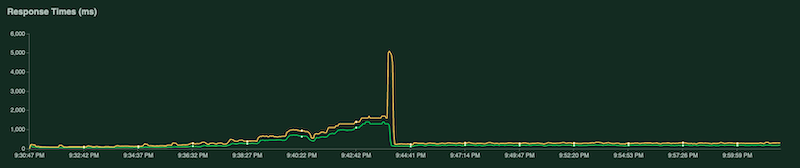
另一个图表展示了以毫秒为单位的响应时间:
如前所述,这些统计信息也会记录到 Cloud Logging 中,以便您创建基于日志的自定义 Cloud Monitoring 指标。
收集和分析测试结果
下一项任务是收集并分析结果日志中作为 Pandas DataFrame 对象计算得出的 Cloud Monitoring 指标,以便您可直观呈现和分析笔记本中的结果。用于执行此任务的代码位于 03-analyze-results.ipynb 笔记本中。
代码使用 Cloud Monitoring Query Python SDK 来过滤和检索指标值(在 project_id、test_id、start_time、end_time、model、model_version、log_name 参数中传递的值)。
以下代码段显示了检索 AI Platform Prediction 指标和基于日志的自定义 Locust 指标的方法。
import pandas as pd
from google.cloud.monitoring_v3.query import Query
def _get_aipp_metric(metric_type: str, labels: List[str]=[], metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified AIPP metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_resources(model_id=model)
query = query.select_resources(version_id=model_version)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.set_index(df.index.round('T'))
return df
def _get_locust_metric(metric_type: str, labels: List[str]=[],
metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified custom logs-based metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_metrics(log=log_name)
query = query.select_metrics(test_id=test_id)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.apply(lambda row: [metric.mean for metric in row])
df = df.set_index(df.index.round('T'))
return df
对于每个指标,会以 Pandas DataFrame 对象的形式检索指标数据,然后将各个数据帧合并为一个 DataFrame 对象。具有合并结果的最终 DataFrame 对象在笔记本中如下所示:
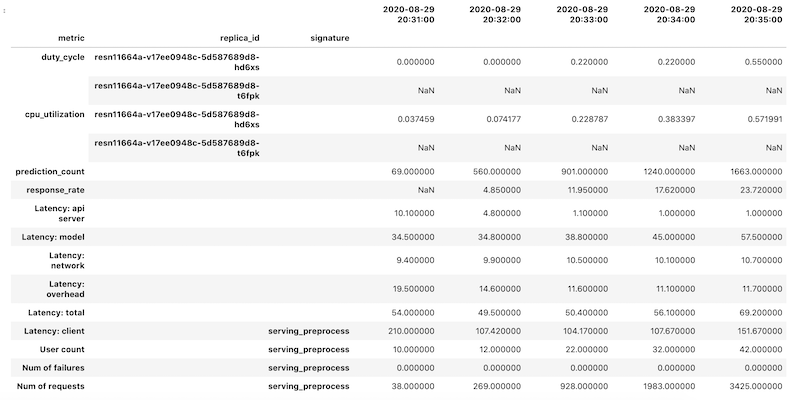
检索到的 DataFrame 对象对列名称使用分层索引。这是因为某些指标包含多个时间序列。例如,GPU duty_cycle 指标包括部署中使用的每个 GPU 的测量时间序列,表示为 replica_id。列索引的顶层显示单个指标的名称。第二个级别是副本 ID。第三级别显示模型的签名。所有指标都在同一时间轴上对齐。
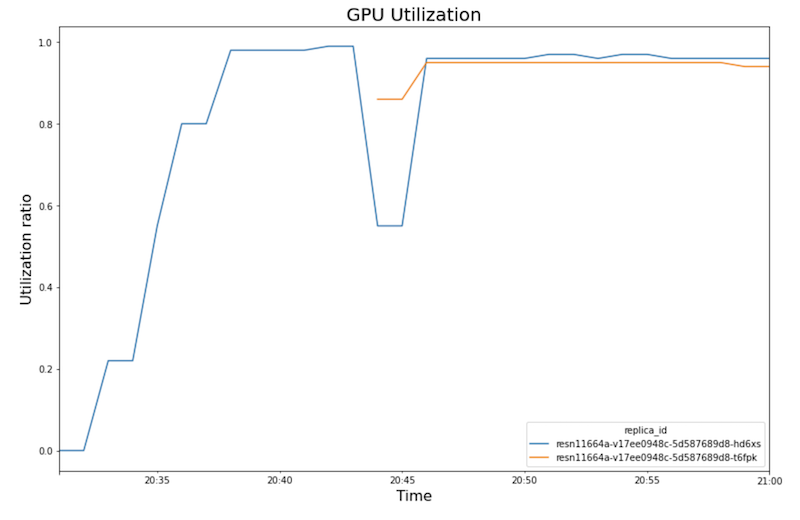
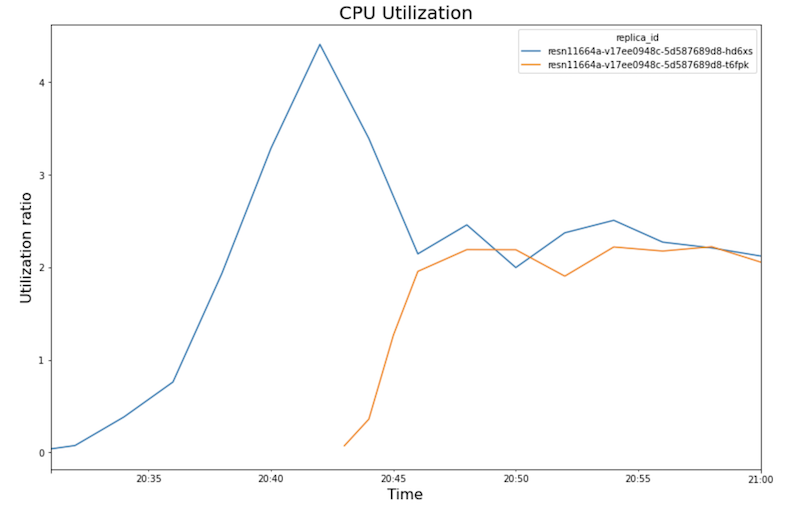
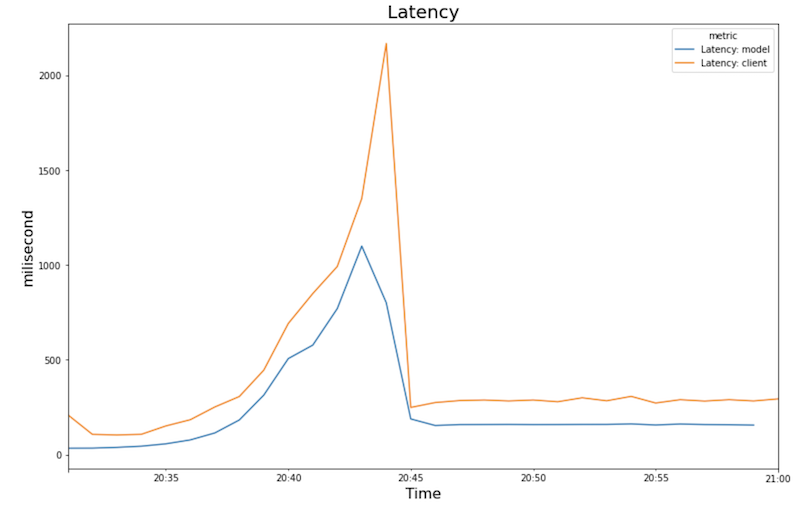
下图展示了您在笔记本中看到的 GPU 利用率、CPU 利用率和延迟时间。
GPU 利用率:
CPU 利用率:
延迟时间:
这些图表显示以下行为和序列:
- 随着工作负载(用户数量)的增加,CPU 和 GPU 利用率也会增加。因此,延迟时间会增加,模型延迟时间与总延迟时间之间的差异也会增加,直到在 20:40 左右达到峰值。
- 在 20:40,GPU 利用率达到 100%,而 CPU 图表显示利用率达到 4 个 CPU。示例在此测试使用具有 8 个 CPU 的
n1-standard-8机器。因此,CPU 利用率达到 50%。 - 此时,自动扩缩功能会添加容量:添加新的服务节点并附加一个 GPU 副本。第一个 GPU 副本利用率下降,第二个 GPU 副本利用率增加。
- 延迟时间会随着新副本开始处理预测而减少,在大约 200 毫秒时收敛。
- 每个副本的 CPU 利用率收敛在大约 250%,即利用 8 个 CPU 中的 2.5 个。此值表示您可以使用
n1-standard-4机器,而不是n1-standard-8机器。
清理
为避免因本文档中使用的资源导致您的 Google Cloud 产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
如果您想保留 Google Cloud 项目但删除您创建的资源,请删除 Google Kubernetes Engine 集群和已部署的 AI Platform 模型。
后续步骤
- 了解 MLOps 以及机器学习中的持续交付和自动化流水线。
- 了解使用 TFX、Kubeflow 流水线和 Cloud Build 的 MLOps 的架构。
- 如需查看更多参考架构、图表和最佳实践,请探索云架构中心。