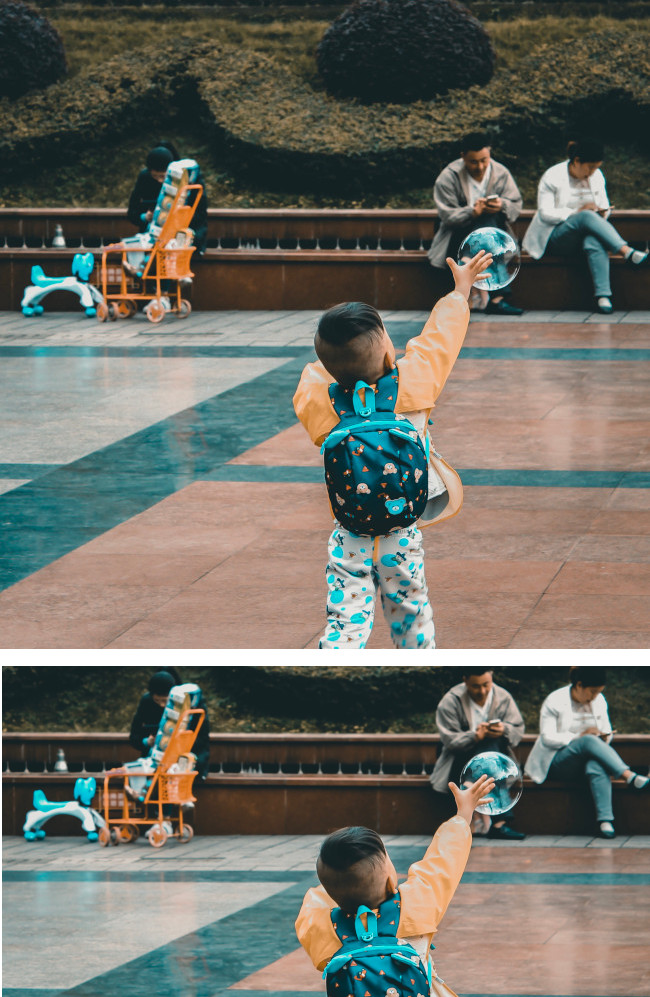Reconhecimento ótico de carateres (OCR) para uma imagem; reconhecimento de texto e
conversão em texto codificado por máquina. Identifica e extrai texto UTF-8 numa imagem.
Imagens: otimizadas para áreas esparsas de texto numa imagem maior.
Resposta: devolve uma lista de palavras identificadas com texto, caixas delimitadoras e textAnnotations, bem como a hierarquia estrutural do texto detetado pelo OCR (fullTextAnnotation).
Reconhecimento ótico de carateres (OCR) para um ficheiro (PDF/TIFF) ou uma imagem de texto
densa; reconhecimento de texto denso e
conversão em texto codificado por máquina.
Ficheiros: otimizado para ficheiros de documentos (PDF/TIFF).
Imagens: otimizadas para áreas densas de texto numa imagem (imagens que são documentos) e imagens que contêm escrita manual.
Resposta: devolve a hierarquia estrutural do texto detetado pelo OCR (fullTextAnnotation).
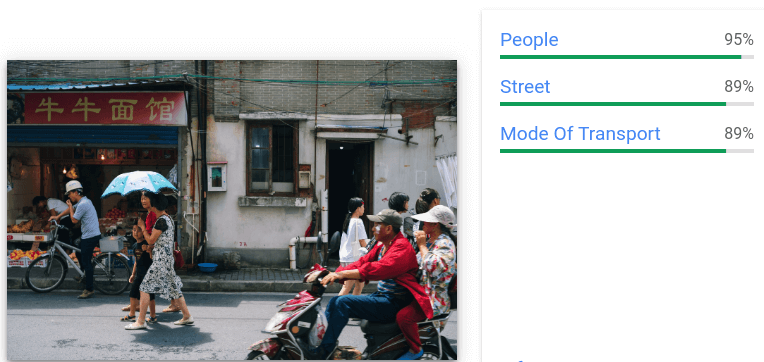
Fornece anotações gerais de etiquetas e caixas delimitadoras para vários objetos
reconhecidos numa única imagem.
Para cada objeto detetado, são devolvidos os seguintes elementos: uma descrição textual, uma pontuação de confiança e vértices normalizados [0,1] para o polígono delimitador à volta do objeto.
Fornece um polígono delimitador para a imagem recortada, uma pontuação de confiança e uma fração de importância desta região saliente relativamente à imagem original para cada pedido.
Pode fornecer até 16 valores de proporção de imagem (largura:altura)
para uma única imagem.
Fornece uma série de conteúdos Web relacionados com uma imagem.
Devolve as seguintes informações:
Entidades Web: entidades inferidas (etiquetas/descrições) de imagens semelhantes na Web.
Imagens de correspondência total: uma lista de URLs de imagens de correspondência total de qualquer tamanho na Internet.
Imagens de correspondência parcial: uma lista de URLs de imagens que
partilham caraterísticas de pontos-chave, como uma versão recortada da imagem
original.
Páginas com imagens correspondentes: uma lista de páginas Web (identificadas pelo URL da página, título da página e URL da imagem correspondente) com uma imagem que cumpre as condições descritas acima.
Imagens visualmente semelhantes: uma lista de URLs de imagens que partilham algumas funcionalidades com a imagem original.
Etiqueta de melhor palpite: um melhor palpite sobre o tópico da imagem pedida inferido a partir de imagens semelhantes na Internet.
Localiza caras com polígonos delimitadores,
e identifica "pontos de referência" faciais específicos, como olhos, orelhas, nariz, boca,
etc., juntamente com os respetivos valores de confiança.
Devolve classificações de probabilidade para a emoção
(alegria, tristeza, raiva, surpresa) e propriedades gerais da imagem
(subexposta, desfocada, presença de um acessório para a cabeça).
As classificações de probabilidade são expressas
como 6 valores diferentes: UNKNOWN, VERY_UNLIKELY,
UNLIKELY, POSSIBLE, LIKELY ou
VERY_LIKELY.
[[["Fácil de entender","easyToUnderstand","thumb-up"],["Meu problema foi resolvido","solvedMyProblem","thumb-up"],["Outro","otherUp","thumb-up"]],[["Difícil de entender","hardToUnderstand","thumb-down"],["Informações incorretas ou exemplo de código","incorrectInformationOrSampleCode","thumb-down"],["Não contém as informações/amostras de que eu preciso","missingTheInformationSamplesINeed","thumb-down"],["Problema na tradução","translationIssue","thumb-down"],["Outro","otherDown","thumb-down"]],["Última atualização 2025-10-19 UTC."],[],[]]