功能列表
借助 Vision API,您目前可以使用以下特征:
| 所有特征类型 |

|
- 图片的光学字符识别 (OCR);文本识别和机器编码文本转换。识别并提取图片中的 UTF-8 文本。
- 图片:已针对较大图片中的稀疏文本区域进行优化。
- 响应:返回通过文本、边界框和
textAnnotations 识别的字词列表,以及 OCR 检测到的文本的结构层次 (fullTextAnnotation) 列表。
- 提取的文本结构的层次结构:
- TextAnnotation -> 页面 -> 块 -> 段落 -> 字词 -> 符号。
- 页面中的每个结构组件都可以进一步包含各自的属性,例如检测到的语言、换行等等。
- 支持的语言:支持目前受支持的语言、映射的语言和实验性语言。
- 特征枚举值:
TEXT_DETECTION。
|

|
- 文件 (PDF/TIFF) 或密集文本图片的光学字符识别 (OCR);密集文本识别和机器编码文本转换。
- 文件:已针对文档文件 (PDF/TIFF) 进行优化。
- 图片:已针对图片(文档图片)中的密集文本区域以及包含手写内容的图片进行优化。
- 响应:返回用 OCR 检测到的文本 (
fullTextAnnotation) 的结构性层次结构。
- 提取的文本结构的层次结构:
- TextAnnotation -> 页面 -> 块 -> 段落 -> 字词 -> 符号。
- 页面中的每个结构组件都可以进一步包含各自的属性,例如检测到的语言、换行等等。
- 支持的语言:支持目前受支持的语言、映射的语言和实验性语言。
- 特征枚举值:
DOCUMENT_TEXT_DETECTION。
- 在请求
DOCUMENT_TEXT_DETECTION 和 TEXT_DETECTION 时优先考虑。
|

|
- 在地标图片中提供地标的名称、置信度分数和边界框。
- 提供检测到的实体的坐标。
|

|
- 提供识别到的实体的文本描述、置信度分数以及文件中徽标的边界多边形。
|
|
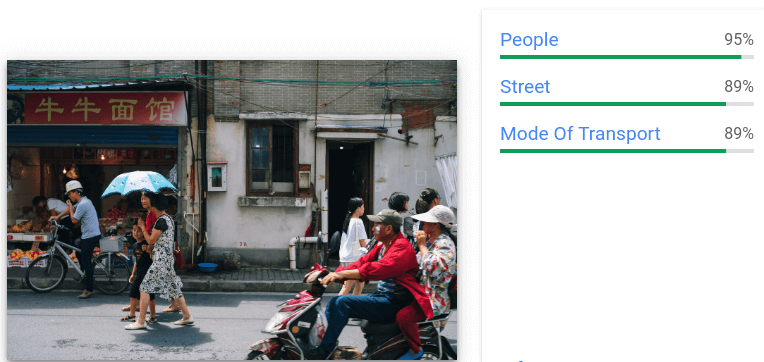
- 提供图片的通用化标签。
- 对于每个标签,系统会返回文本描述、置信度分数和话题性分数。
|

|
- 返回图片中的主色。
- 每种颜色以 RGBA 颜色空间表示,具有置信度分数,并且会显示该颜色占据的像素比例 [0, 1]。
|

|
|
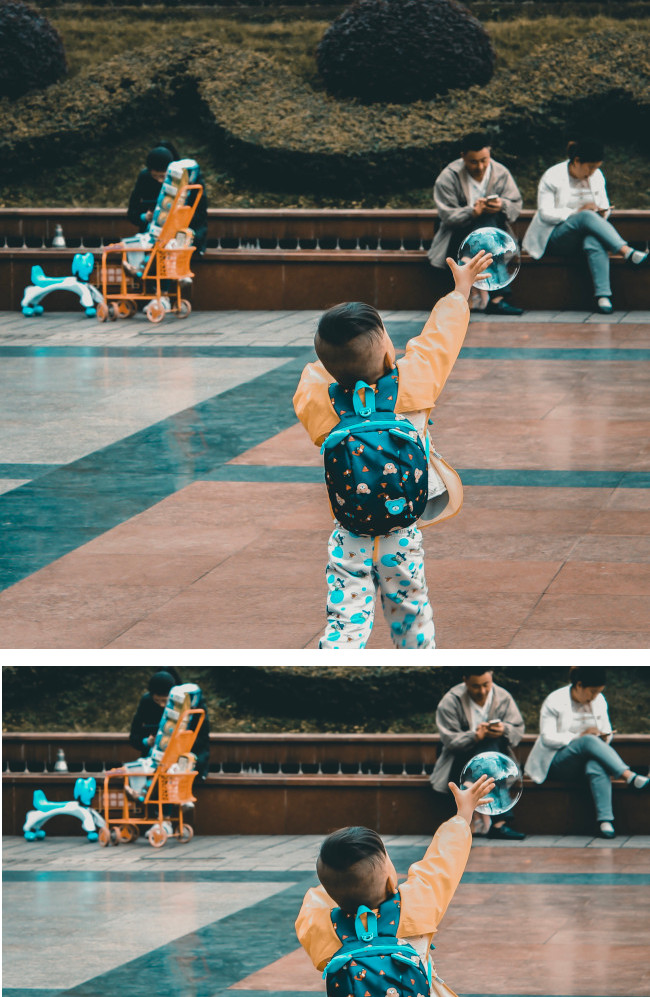
|
- 为每个请求提供剪裁后图片的边界多边形、置信度分数以及此重要区域相对于原始图片的重要性比例。
- 您可以为单个图片最多提供 16 个图片比例值(宽高比)。
|

|
- 提供一系列与图片相关的 Web 内容。
- 返回以下信息:
- 网络实体:根据网络上的类似图片推断出的实体(标签/说明)。
- 完全匹配的图片:互联网上任意尺寸的完全匹配图片的网址列表。
- 部分匹配的图片:具有共同关键特征(例如剪裁后的原始图片)的图片的网址列表。
- 具有匹配图片的页面:具有满足上述条件的图片的网页(由网页网址、网页标题、匹配的图片网址标识)列表。
- 外观类似的图片:与原始图片具有某些共同特征的图片的网址列表。
- 最佳猜测标签:对根据互联网上类似图片推断出的所请求图片主题的最佳猜测。
|
|
- 提供以下露骨内容类别的似然度评分:
adult、spoof、medical、violence 和 racy。
- 似然度评分表示为 6 个不同的值:
UNKNOWN、VERY_UNLIKELY、UNLIKELY、POSSIBLE、LIKELY 或 VERY_LIKELY。
|

|
- 使用边界多边形定位脸部,并识别具体的面部“特征”(例如眼睛、耳朵、鼻子、嘴巴等)以及相应的置信度值。
- 返回情绪(喜悦、悲伤、愤怒、惊喜)和常规图片属性(曝光不足、模糊处理、存在头饰)的似然度评分。
- 似然度评分表示为 6 个不同的值:
UNKNOWN、VERY_UNLIKELY、UNLIKELY、POSSIBLE、LIKELY 或 VERY_LIKELY。
- 不支持特定个人面部识别。
|
1.
图片来源:Unsplash 用户 Nikolay Vorobyev(添加了注释)。
↩
2.
图片来源:Robert Scoble(CC BY 2.0,已添加注释)。↩
3.
图片来源:Unsplash 用户 Alex Knight。
↩
4.
图片来源:Unsplash 用户 Jeremy Bishop。
↩
5.
图片来源:Unsplash 用户 Bogdan Dada(添加了注释)。
↩
6.
图片来源:Unsplash 用户 Yasmin Dangor(显示原始图片和剪裁后的图片)。
↩
7.
图片来源:
Unsplash 用户 Quinten de Graaf。
↩
如未另行说明,那么本页面中的内容已根据知识共享署名 4.0 许可获得了许可,并且代码示例已根据 Apache 2.0 许可获得了许可。有关详情,请参阅 Google 开发者网站政策。Java 是 Oracle 和/或其关联公司的注册商标。
最后更新时间 (UTC):2025-11-04。
[[["易于理解","easyToUnderstand","thumb-up"],["解决了我的问题","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["很难理解","hardToUnderstand","thumb-down"],["信息或示例代码不正确","incorrectInformationOrSampleCode","thumb-down"],["没有我需要的信息/示例","missingTheInformationSamplesINeed","thumb-down"],["翻译问题","translationIssue","thumb-down"],["其他","otherDown","thumb-down"]],["最后更新时间 (UTC):2025-11-04。"],[],[]]