物件偵測器模型可在影片中識別及定位超過 500 種物件。這個模型會接受影片串流做為輸入內容,並將偵測結果輸出至 BigQuery 的通訊協定緩衝區。模型的執行速度為 1 FPS。建立使用物件偵測器模型的應用程式時,您必須將模型輸出內容導向 BigQuery 連接器,才能查看預測輸出內容。
物件偵測模型應用程式規格
請按照下列操作說明,在Google Cloud 控制台中建立物件偵測器模型。
主控台
在 Google Cloud 控制台中建立應用程式
如要建立物件偵測工具應用程式,請按照「建構應用程式」中的操作說明進行。
新增物件偵測器模型
- 新增模型節點時,請從預先訓練模型清單中選取「Object detector」。
新增 BigQuery 連接器
如要使用輸出內容,請將應用程式連結至 BigQuery 連接器。
如要瞭解如何使用 BigQuery 連接器,請參閱「將資料連結並儲存至 BigQuery」一文。如要瞭解 BigQuery 的定價資訊,請參閱 BigQuery 定價頁面。
在 BigQuery 中查看輸出結果
模型將資料輸出至 BigQuery 後,請在 BigQuery 資訊主頁中查看輸出註解。
如果您未指定 BigQuery 路徑,可以在 Vertex AI Vision Studio 頁面中查看系統建立的路徑。
在 Google Cloud 控制台開啟「BigQuery」頁面。
選取目標專案、資料集名稱和應用程式名稱旁的 「展開」。
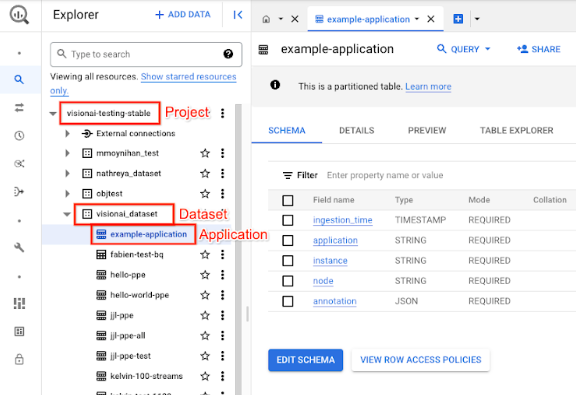
在資料表詳細資料檢視畫面中,按一下「預覽」。查看「註解」欄中的結果。如需輸出格式的說明,請參閱「模型輸出內容」。
應用程式會依時間順序儲存結果。最舊的結果會顯示在表格的開頭,而最新的結果則會新增至表格的結尾。如要查看最新結果,請按一下頁碼,前往最後一個表格頁面。
模型輸出
模型會為每個影片影格輸出定界框、物件標籤和可信度分數。輸出內容也包含時間戳記。輸出串流的速率為每秒一幀。
在下列通訊協定緩衝區輸出範例中,請注意以下事項:
- 時間戳記:時間戳記對應至推論結果的時間。
- 已識別的方塊:主要偵測結果,包含方塊 ID、邊界框資訊、信心分數和物件預測。
註解輸出 JSON 物件的範例
{
"currentTime": "2022-11-09T02:18:54.777154048Z",
"identifiedBoxes": [
{
"boxId":"0",
"normalizedBoundingBox": {
"xmin": 0.6963465,
"ymin": 0.23144785,
"width": 0.23944569,
"height": 0.3544306
},
"confidenceScore": 0.49874997,
"entity": {
"labelId": "0",
"labelString": "Houseplant"
}
}
]
}
通訊協定緩衝區定義
// The prediction result protocol buffer for object detection
message ObjectDetectionPredictionResult {
// Current timestamp
protobuf.Timestamp timestamp = 1;
// The entity information for annotations from object detection prediction
// results
message Entity {
// Label id
int64 label_id = 1;
// The human-readable label string
string label_string = 2;
}
// The identified box contains the location and the entity of the object
message IdentifiedBox {
// An unique id for this box
int64 box_id = 1;
// Bounding Box in normalized coordinates [0,1]
message NormalizedBoundingBox {
// Min in x coordinate
float xmin = 1;
// Min in y coordinate
float ymin = 2;
// Width of the bounding box
float width = 3;
// Height of the bounding box
float height = 4;
}
// Bounding Box in the normalized coordinates
NormalizedBoundingBox normalized_bounding_box = 2;
// Confidence score associated with this bounding box
float confidence_score = 3;
// Entity of this box
Entity entity = 4;
}
// A list of identified boxes
repeated IdentifiedBox identified_boxes = 2;
}
最佳做法和限制
為確保使用物件偵測器時能獲得最佳結果,請在取得資料和使用模型時考量下列事項。
來源資料建議
建議做法:請確認圖片中的物體清晰可見,且不會被其他物體遮蔽或大幅遮蔽。
物件偵測器可正確處理的圖片資料範例:

|
傳送模型這項圖片資料會傳回下列物件偵測資訊:*
*下方圖片中的註解僅供說明之用。定界框、標籤和可信度分數都是手動繪製,並非由模型或任何 Google Cloud 控制台工具新增。

不建議:請避免使用圖片資料,其中關鍵物件項目在畫面中過小。
物件偵測器無法正確處理的圖片資料範例:

|
不建議:請避免使用顯示主要物件項目遭其他物件部分或完全遮蓋的圖片資料。
物件偵測器無法正確處理的圖片資料範例:

|
限制
- 影片解析度:建議的最大輸入影片解析度為 1920 x 1080,建議的最小解析度為 160 x 120。
- 光線:模型成效會受到光線條件影響。光線過亮或過暗可能會導致偵測品質降低。
- 物件大小:物件偵測器有可偵測的物件大小下限。請確認目標物體在影片資料中足夠大且可見。