对象检测器模型可以识别和定位视频中 500 多种类型的对象。该模型接受视频流作为输入,并将包含检测结果的协议缓冲区输出到 BigQuery。模型以 1 FPS 的速度运行。创建使用对象检测器模型的应用时,您必须将模型输出定向到 BigQuery 连接器,才能查看预测输出。
对象检测器模型应用规范
按照以下说明在Google Cloud 控制台中创建对象检测器模型。
控制台
在 Google Cloud 控制台中创建应用
添加对象检测器模型
- 添加模型节点时,请从预训练模型列表中选择对象检测器。
添加 BigQuery 连接器
如需使用输出,请将应用连接到 BigQuery 连接器。
如需了解如何使用 BigQuery 连接器,请参阅将数据连接并存储到 BigQuery。如需了解 BigQuery 价格信息,请参阅 BigQuery 价格页面。
在 BigQuery 中查看输出结果
模型将数据输出到 BigQuery 后,您可以在 BigQuery 信息中心查看输出注释。
如果您未指定 BigQuery 路径,则可以在 Vertex AI Vision Studio 页面中查看系统创建的路径。
在 Google Cloud 控制台中,打开 BigQuery 页面。
选择目标项目、数据集名称和应用名称旁边的 Expand(展开)。
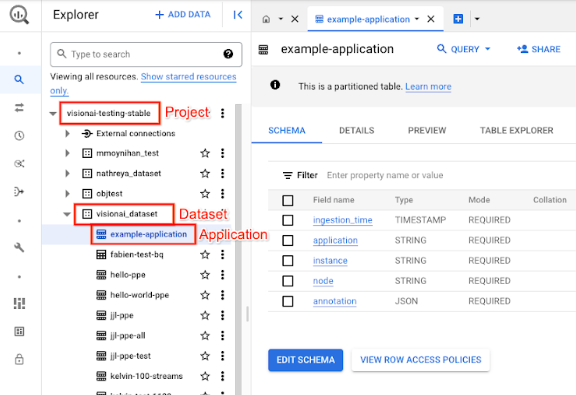
在表格详情视图中,点击预览。在注释列中查看结果。如需了解输出格式,请参阅模型输出。
应用会按时间顺序存储结果。最早的结果位于表格的开头,而最新的结果则添加到表格的末尾。如需查看最新结果,请点击页码以前往最后一个表格页。
模型输出
该模型会为每个视频帧输出边界框、其对象标签和置信度分数。输出还包含时间戳。输出流的速率为每秒一帧。
在以下协议缓冲区输出示例中,请注意以下事项:
- 时间戳 - 时间戳对应于此推理结果的时间。
- 已识别出的框 - 主要检测结果,包括框标识、边界框信息、置信度得分和对象预测。
注释输出 JSON 对象示例
{
"currentTime": "2022-11-09T02:18:54.777154048Z",
"identifiedBoxes": [
{
"boxId":"0",
"normalizedBoundingBox": {
"xmin": 0.6963465,
"ymin": 0.23144785,
"width": 0.23944569,
"height": 0.3544306
},
"confidenceScore": 0.49874997,
"entity": {
"labelId": "0",
"labelString": "Houseplant"
}
}
]
}
协议缓冲区定义
// The prediction result protocol buffer for object detection
message ObjectDetectionPredictionResult {
// Current timestamp
protobuf.Timestamp timestamp = 1;
// The entity information for annotations from object detection prediction
// results
message Entity {
// Label id
int64 label_id = 1;
// The human-readable label string
string label_string = 2;
}
// The identified box contains the location and the entity of the object
message IdentifiedBox {
// An unique id for this box
int64 box_id = 1;
// Bounding Box in normalized coordinates [0,1]
message NormalizedBoundingBox {
// Min in x coordinate
float xmin = 1;
// Min in y coordinate
float ymin = 2;
// Width of the bounding box
float width = 3;
// Height of the bounding box
float height = 4;
}
// Bounding Box in the normalized coordinates
NormalizedBoundingBox normalized_bounding_box = 2;
// Confidence score associated with this bounding box
float confidence_score = 3;
// Entity of this box
Entity entity = 4;
}
// A list of identified boxes
repeated IdentifiedBox identified_boxes = 2;
}
最佳做法和限制
为了在使用对象检测器时获得最佳结果,请在获取数据和使用模型时考虑以下事项。
源数据建议
建议:确保图片中的物体清晰可见,没有被其他物体遮挡或严重遮挡。
对象检测器能够正确处理的图片数据示例:

|
向模型发送此图片数据会返回以下对象检测信息*:
* 下图中的注释仅供说明之用。边界框、标签和置信度得分是手动绘制的,而不是由模型或任何控制台工具添加的。 Google Cloud

不建议:避免在图片数据中出现关键对象项在取景框中过小的情况。
以下是对象检测器无法正确处理的图片数据示例:

|
不推荐:避免提交的图片数据中显示的关键对象项被其他对象部分或完全遮挡。
以下是对象检测器无法正确处理的图片数据示例:

|
限制
- 视频分辨率:建议的输入视频分辨率上限为 1920 x 1080,建议的最低分辨率为 160 x 120。
- 光照:模型性能对光照条件非常敏感。极亮或极暗的环境可能会导致检测质量较差。
- 对象大小:对象检测器具有最小可检测对象大小。 确保目标对象足够大,并且在视频数据中清晰可见。