Le modèle de détection d'objets peut identifier et localiser plus de 500 types d'objets dans une vidéo. Le modèle accepte un flux vidéo en entrée et renvoie un tampon de protocole avec les résultats de détection dans BigQuery. Le modèle s'exécute à un FPS. Lorsque vous créez une application qui utilise le modèle de détecteur d'objets, vous devez diriger la sortie du modèle vers un connecteur BigQuery pour afficher la sortie de la prédiction.
Spécifications de l'application du modèle de détection d'objets
Suivez les instructions ci-dessous pour créer un modèle de détecteur d'objets dans la consoleGoogle Cloud .
Console
Créer une application dans la Google Cloud console
Pour créer une application de détection d'objets, suivez les instructions de la section Créer une application.
Ajouter un modèle de détection d'objets
- Lorsque vous ajoutez des nœuds de modèle, sélectionnez Détecteur d'objets dans la liste des modèles pré-entraînés.
Ajouter un connecteur BigQuery
Pour utiliser la sortie, connectez l'application à un connecteur BigQuery.
Pour en savoir plus sur l'utilisation du connecteur BigQuery, consultez Connecter et stocker des données dans BigQuery. Pour en savoir plus sur les tarifs de BigQuery, consultez la page Tarifs de BigQuery.
Afficher les résultats de sortie dans BigQuery
Une fois que le modèle a généré des données dans BigQuery, affichez les annotations de sortie dans le tableau de bord BigQuery.
Si vous n'avez pas spécifié de chemin BigQuery, vous pouvez afficher le chemin créé par le système sur la page Studio de Vertex AI Vision.
Dans la console Google Cloud , ouvrez la page BigQuery.
Sélectionnez Développer à côté du projet cible, du nom de l'ensemble de données et du nom de l'application.
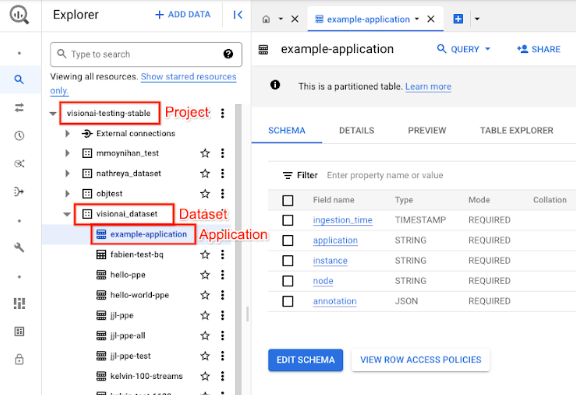
Dans la vue d'informations de la table, cliquez sur Aperçu. Consultez les résultats dans la colonne annotation. Pour obtenir une description du format de sortie, consultez la section Sortie du modèle.
L'application stocke les résultats dans l'ordre chronologique. Les résultats les plus anciens se trouvent au début du tableau, tandis que les résultats les plus récents sont ajoutés à la fin. Pour consulter les derniers résultats, cliquez sur le numéro de page pour accéder à la dernière page de la table.
Sortie du modèle
Le modèle génère des cadres de délimitation, leurs libellés d'objets et des scores de confiance pour chaque frame vidéo. La sortie contient également un code temporel. La fréquence du flux de sortie est d'une image par seconde.
Dans l'exemple de sortie du tampon de protocole qui suit, notez les points suivants:
- Code temporel : le code temporel correspond à l'heure de ce résultat d'inférence.
- Cadres identifiés : résultat de détection principal qui inclut l'identité du cadre, des informations sur le cadre de délimitation, le score de confiance et la prédiction d'objet.
Exemple d'objet JSON de sortie d'annotation
{
"currentTime": "2022-11-09T02:18:54.777154048Z",
"identifiedBoxes": [
{
"boxId":"0",
"normalizedBoundingBox": {
"xmin": 0.6963465,
"ymin": 0.23144785,
"width": 0.23944569,
"height": 0.3544306
},
"confidenceScore": 0.49874997,
"entity": {
"labelId": "0",
"labelString": "Houseplant"
}
}
]
}
Définition du tampon de protocole
// The prediction result protocol buffer for object detection
message ObjectDetectionPredictionResult {
// Current timestamp
protobuf.Timestamp timestamp = 1;
// The entity information for annotations from object detection prediction
// results
message Entity {
// Label id
int64 label_id = 1;
// The human-readable label string
string label_string = 2;
}
// The identified box contains the location and the entity of the object
message IdentifiedBox {
// An unique id for this box
int64 box_id = 1;
// Bounding Box in normalized coordinates [0,1]
message NormalizedBoundingBox {
// Min in x coordinate
float xmin = 1;
// Min in y coordinate
float ymin = 2;
// Width of the bounding box
float width = 3;
// Height of the bounding box
float height = 4;
}
// Bounding Box in the normalized coordinates
NormalizedBoundingBox normalized_bounding_box = 2;
// Confidence score associated with this bounding box
float confidence_score = 3;
// Entity of this box
Entity entity = 4;
}
// A list of identified boxes
repeated IdentifiedBox identified_boxes = 2;
}
Bonnes pratiques et limites
Pour obtenir les meilleurs résultats lorsque vous utilisez le détecteur d'objets, tenez compte des points suivants lorsque vous collectez des données et utilisez le modèle.
Recommandations concernant les données sources
Recommandation:Assurez-vous que les objets de l'image sont clairs et qu'ils ne sont pas recouverts ou masqués en grande partie par d'autres objets.
Exemples de données d'image que le détecteur d'objets peut traiter correctement:

|
Envoyer ces données d'image au modèle renvoie les informations de détection d'objets suivantes*:
* Les annotations de l'image suivante sont fournies à titre d'illustration uniquement. Les rectangles de délimitation, les libellés et les scores de confiance sont dessinés manuellement et non ajoutés par le modèle ni par un outil de console. Google Cloud

Non recommandé:évitez les données d'image dans lesquelles les éléments d'objets clés sont trop petits dans le cadre.
Exemple de données d'image que le détecteur d'objets ne peut pas traiter correctement:

|
Non recommandé:évitez les données d'image qui montrent les éléments d'objets clés partiellement ou entièrement recouverts par d'autres objets.
Exemple de données d'image que le détecteur d'objets ne peut pas traiter correctement:

|
Limites
- Résolution vidéo: la résolution vidéo d'entrée maximale recommandée est de 1 920 x 1 080, et la résolution minimale recommandée est de 160 x 120.
- Éclairage: les performances du modèle sont sensibles aux conditions d'éclairage. Une luminosité ou une obscurité extrême peut entraîner une qualité de détection moindre.
- Taille de l'objet: le détecteur d'objets a une taille d'objet minimale détectable. Assurez-vous que les objets cibles sont suffisamment grands et visibles dans vos données vidéo.