Auf dieser Seite wird beschrieben, wie Sie Ihre Daten für das Training eines AutoML Video Objekt-Tracking-Modells vorbereiten.
Videos vorbereiten
Auf dieser Seite wird beschrieben, wie Sie Ihre Trainings- und Testdaten vorbereiten, damit AutoML Video Intelligence Object Tracking ein Videoannotierungsmodell für Sie erstellen kann.
Das AutoML Video Intelligence-Objekttracking unterstützt folgende Videoformate, um Modelle zu trainieren oder Vorhersagen anzufordern.
- .MOV
- .MPEG4
- .MP4
- .AVI
Die maximale Dateigröße für Trainingsvideos beträgt 50 GB, die maximale Länge 3 Stunden. Einzelne Videodateien mit fehlerhaften oder leerem Zeitversatz im Container werden nicht unterstützt.
Trainingsdaten sollten den Daten, für die Vorhersagen zu treffen sind, möglichst ähnlich sein. Wenn Ihr Anwendungsfall beispielsweise verschwommene Videos mit niedriger Auflösung (zum Beispiel von einer Überwachungskamera) beinhaltet, sollten Ihre Trainingsdaten aus verschwommenen Videos mit niedriger Auflösung bestehen. Sie sollten außerdem mehrere Blickwinkel, Auflösungen und Hintergründe für Ihre Trainingsvideos bereitstellen.
AutoML Video Object Tracking-Modelle können in der Regel keine Labels vorhersagen, die von Menschen nicht zugewiesen werden können. Wenn beispielsweise ein Mensch nicht darin unterwiesen werden kann, während 1 bis 2 Sekunden beim Betrachten eines Videos ein Label zuzuweisen, kann Ihr Modell wahrscheinlich auch nicht dafür trainiert werden.
Die Größe des Begrenzungsrahmens ist 10px x 10px.
Bei einer Videoframeauflösung, die viel größer als 1024 x 1024 Pixel ist, kann die Bildqualität während der Framenormalisierung, die von AutoML Video Object Tracking verwendet wird, verloren gehen.
Die Modelle funktionieren am besten, wenn für das am häufigsten verwendete Label höchstens 100-mal mehr Frames vorhanden sind als für das am wenigsten verwendete Label. Sie sollten Labels mit sehr geringer Häufigkeit aus den Datasets entfernen.
Jedes eindeutige Label muss in mindestens drei verschiedenen Videoframes vorhanden sein. Außerdem muss jedes Label mindestens 10 Annotationen haben.
Die maximale Anzahl von Videoframes mit Labels in jedem Dataset ist derzeit auf 150.000 begrenzt.
Die maximale Gesamtzahl der annotierten Begrenzungsrahmen pro Dataset ist derzeit auf 1.000.000 begrenzt.
Die maximale Anzahl einmaliger Labels in jedem Dataset ist derzeit auf 1.000 begrenzt.
Ihre Trainingsdaten müssen mindestens ein Label enthalten.
Wir empfehlen mindestens 100 Trainingsvideoframes pro Label, wobei in jedem Frame alle relevanten Objekte gekennzeichnet sein sollten. Sie müssen nicht alle Frames, in denen Objekte auftauchen, mit einem Label kennzeichnen; aber je mehr Frames gekennzeichnet sind, desto besser ist das Modell. Sie sollten Frames auswählen, die nicht nebeneinander liegen, um verschiedene Größen, Winkel, Hintergründe, Lichtverhältnisse usw. abzudecken.
Trainings-, Validierungs- und Test-Datasets
Die Daten in einem Dataset werden beim Trainieren eines Modells in drei Datasets aufgeteilt: ein Trainings-Dataset, ein Validierungs-Dataset (optional) und ein Test-Dataset.
- Das Trainings-Dataset wird zum Erstellen eines Modells verwendet. Während der Suche nach Mustern in den Trainingsdaten werden mehrere Algorithmen und Parameter versucht.
- Wenn Muster erkannt werden, wird das Validierungs-Dataset zum Testen der Algorithmen und Muster verwendet. Von den Algorithmen und Mustern, die während des Trainings verwendet wurden, werden die mit der besten Leistung ausgewählt.
- Nachdem die besten Algorithmen und Muster ermittelt wurden, werden sie mit dem Test-Dataset auf Fehlerrate, Qualität und Genauigkeit getestet.
Es wird sowohl ein Validierungs- als auch ein Test-Dataset verwendet, um Verzerrungen im Modell zu vermeiden. Während der Validierungsphase werden optimale Modellparameter verwendet, was zu verzerrten Messwerten führen kann. Die Verwendung des Test-Datasets zur Bewertung der Qualität des Modells nach der Validierungsphase ermöglicht eine unvoreingenommene Qualitätsbeurteilung des Modells.
Verwenden Sie zum Identifizieren von Trainings- und Test-Datasets CSV-Dateien.
CSV-Dateien mit Video-URIs und -Labels erstellen
Sobald Ihre Dateien in Cloud Storage hochgeladen wurden, können Sie CSV-Dateien erstellen, die alle Trainingsdaten und die Kategorielabels für diese Daten aufführen. Die CSV-Dateien können beliebigen Dateinamen tragen, müssen UTF-8-codiert sein und die Endung .csv haben.
Es gibt drei Dateien, die Sie zum Trainieren und Prüfen Ihres Modells verwenden können:
| File | Beschreibung |
|---|---|
| Liste der Modelltrainingsdateien | Enthält Pfade zu den Trainings- und Test-CSV-Dateien. Mit dieser Datei werden die Speicherorte verschiedener CSV-Dateien angegeben, die Ihre Trainings- und Testdaten beschreiben. Der Inhalt der CSV-Datei mit den Pfaden kann beispielsweise so aussehen: Beispiel 1: TRAIN,gs://automl-video-demo-data/traffic_videos/traffic_videos_train.csv TEST,gs://automl-video-demo-data/traffic_videos/traffic_videos_test.csv Beispiel 2: UNASSIGNED,gs://automl-video-demo-data/traffic_videos/traffic_videos_labels.csv |
| Trainingsdaten | Wird verwendet, um das Modell zu trainieren. Enthält URIs zu Videodateien, das Label zur Identifizierung der Objektkategorie, die Instanz-ID zur Identifizierung der Objektinstanz über Videoframes in einem Video (optional), den Zeitversatz des gekennzeichneten Videoframes und die Koordinaten des Objektbegrenzungsrahmens. Wenn Sie eine CSV-Datei für Trainingsdaten angeben, müssen Sie auch eine CSV-Datei für den Test oder die nicht zugewiesene Datei bestimmen. |
| Testdaten | Wird verwendet, um das Modell während der Trainingsphase zu testen. Enthält die gleichen Felder wie in den Trainingsdaten. Wenn Sie eine CSV-Datei mit Testdaten angeben, müssen Sie auch eine CSV-Datei für das Training oder eine nicht zugewiesene Daten angeben. |
| Nicht zugewiesene Daten | Wird sowohl zum Trainieren als auch zum Testen des Modells verwendet. Enthält die gleichen Felder wie in den Trainingsdaten. Die Zeilen in der Datei mit nicht zugewiesenen Daten werden automatisch in Trainings- und Testdaten unterteilt, wobei in der Regel 80 % für Trainings- und 20 % für Testdaten verwendet werden. Sie können nur eine CSV-Datei für nicht zugewiesene Daten angeben, ohne CSV-Dateien für Trainings- und Testdaten angeben zu müssen. Sie können auch nur die CSV-Dateien für Trainings- und Testdaten angeben, ohne eine CSV-Datei für nicht zugewiesene Daten angeben zu müssen. |
Die Trainings-, Test- und nicht zugewiesenen Dateien enthalten eine Zeile mit einem Objektbegrenzungsrahmen in dem Dataset, das Sie hochladen, mit folgenden Spalten in jeder Zeile:
Der Inhalt, der kategorisiert und annotiert werden soll. Dieses Feld enthält den Cloud Storage-URI für das Video. Bei Cloud Storage-URIs wird zwischen Groß- und Kleinschreibung unterschieden.
Ein Label, das angibt, wie das Objekt kategorisiert wird. Labels müssen mit einem Buchstaben beginnen und dürfen nur Buchstaben, Zahlen und Unterstriche enthalten. Mit AutoML Video Object-Tracking können Sie auch Labels mit Leerzeichen verwenden.
Eine Instanz-ID, die die Objektinstanz in Videoframes eines Videos identifiziert (optional). Die Instanz-ID ist eine Ganzzahl. Wenn angegeben, verwendet AutoML Video Object Tracking die ID für Objekt-Tracking, das Training und die Bewertung. Die Begrenzungsrahmen derselben Objektinstanz, die in verschiedenen Videoframes vorhanden sind, werden mit derselben Instanz-ID gekennzeichnet. Die Instanz-ID ist nur in jedem Video einmalig, nicht jedoch im Dataset. Wenn beispielsweise zwei Objekte aus zwei verschiedenen Videos dieselbe Instanz-ID haben, heißt das nicht, dass sie dieselbe Objektinstanz haben.
Der Zeitversatz des Videoframes, der den Zeitversatz ab dem Beginn des Videos angibt. Der Zeitversatz ist eine Gleitkommazahl, die Einheiten werden in Sekunden angegeben.
Ein Begrenzungsrahmen für ein Objekt im Videoframe. Der Begrenzungsrahmen für ein Objekt kann auf zwei Arten angegeben werden:
Verwenden von zwei Eckpunkten, die aus einer Reihe von x- und y-Koordinaten bestehen, wenn sie diagonale Punkte des Rechtecks sind, wie in diesem Beispiel gezeigt:
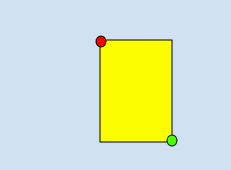
x_relative_min, y_relative_min,,,x_relative_max,y_relative_max,,
- Verwenden aller vier Eckpunkte:
x_relative_min,y_relative_min,x_relative_max,y_relative_min,x_relative_max,y_relative_max,x_relative_min,y_relative_max
Jeder
vertexwird durch x- und y-Koordinatenwerte angegeben. Diese Koordinaten müssen eine Gleitkommazahl im Bereich von 0 bis 1 sein, wobei 0 den minimalen x- oder y-Wert und 1 den größten x- oder y-Wert darstellt.Beispielsweise steht (0,0) für die obere linke Ecke und (1,1) für die rechte untere Ecke. Ein Begrenzungsrahmen für das gesamte Bild wird als (0,0,,,1,1,,) oder (0,0,1,0,1,1,0,1) ausgedrückt.
Die AutoML Video Object Tracking API erfordert keine bestimmte Eckpunktreihenfolge. Wenn außerdem vier angegebene Eckpunkte kein Rechteck parallel zu den Bildkanten bilden, gibt die AutoML Video Intelligence Object Tracking API Eckpunkte an, die ein solches Rechteck bilden.
Beispiele für CSV-Dataset-Dateien
Folgende Zeilen zeigen, wie Daten in einem Dataset angegeben werden. Das Beispiel umfasst einen Pfad zu einem Video in Cloud Storage, ein Label für das Objekt, einen Zeitversatz für den Start des Tracking und zwei diagonale Eckpunkte.
video_uri,label,instance_id,time_offset,x_relative_min,y_relative_min, x_relative_max,y_relative_min,x_relative_max,y_relative_max,x_relative_min,y_relative_max
gs://folder/video1.avi,car,,12.90,0.8,0.2,,,0.9,0.3,,
gs://folder/video1.avi,bike,,12.50,0.45,0.45,,,0.55,0.55,,
Wo in der ersten Zeile
- VIDEO_URI ist
gs://folder/video1.avi, - LABEL ist
car, - INSTANCE_ID nicht angegeben,
- TIME_OFFSET ist
12.90, - sind X_RELATIVE_MIN,Y_RELATIVE_MIN
0.8,0.2, - X_RELATIVE_MAX,Y_RELATIVE_MIN nicht angegeben,
- sind X_RELATIVE_MAX,Y_RELATIVE_MAX
0.9,0.3, - X_RELATIVE_MIN,Y_RELATIVE_MAX sind nicht angegeben
Wie bereits erwähnt, können Sie Ihre Begrenzungsrahmen auch angeben, indem Sie alle vier Eckpunkte angeben, wie in den folgenden Beispielen gezeigt.
gs://folder/video1.avi,car,,12.10,0.8,0.8,0.9,0.8,0.9,0.9,0.8,0.9
gs://folder/video1.avi,car,,12.90,0.4,0.8,0.5,0.8,0.5,0.9,0.4,0.9
gs://folder/video1.avi,car,,12.10,0.4,0.2,0.5,0.2,0.5,0.3,0.4,0.3
Sie müssen keine Validierungsdaten angeben, um die Ergebnisse Ihres trainierten Modells prüfen zu können. AutoML Video Object Tracking teilt die für das Training identifizierten Zeilen automatisch in Trainings- und Validierungsdaten auf, wobei 80 % für das Training und 20 % für die Validierung verwendet werden.
Fehlerbehebung bei Problemen mit CSV-Datasets
Wenn Sie Probleme bei der Angabe des Datasets mit einer CSV-Datei haben, prüfen Sie die CSV-Datei auf die in der folgenden Liste aufgeführten häufigen Fehler:
- Verwendung von Unicode-Zeichen für Labels. Japanische Schriftzeichen werden z. B. nicht unterstützt.
- Verwendung von Leerzeichen und nicht alphanumerischen Zeichen für Labels.
- Leere Zeilen
- Leere Spalten (Zeilen mit zwei aufeinanderfolgenden Kommas)
- Falsche Großschreibung von Cloud Storage-Videopfaden
- Falsch konfigurierte Zugriffssteuerung für Videodateien. Ihr Dienstkonto muss mindestens Leseberechtigungen haben oder die Dateien müssen öffentlich lesbar sein.
- Verweise auf Dateien, die keine Videodateien sind (zum Beispiel PDF- oder PSD-Dateien). Ebenso führen Dateien, die keine Videodateien sind, aber mit einer Dateiendung für Videos umbenannt wurden, zu einem Fehler.
- URI des Videos verweist auf einen anderen Bucket als das aktuelle Projekt. Der Zugriff ist nur auf Videos im Projekt-Bucket möglich.
- Nicht CSV-formatierte Dateien