Einführung
Stellen Sie sich vor, Sie sind der Trainer einer Fußballmannschaft. Sie haben eine umfangreiche Videobibliothek mit Spielen, die Sie dazu verwenden möchten, die Stärken und Schwächen Ihres Teams zu untersuchen. Es wäre unglaublich nützlich, Aktionen wie Tore, Fouls und Strafstöße aus vielen Spielen in einem Video zusammenzustellen. Doch für Sie bedeutet dies, dass Sie Hunderte Stunden Videomaterial prüfen und zahlreiche Aktionen verfolgen müssen. Jedes Video anzuschauen und die Segmente manuell zu kennzeichnen, um die jeweilige Aktion zu markieren, ist langwierig und zeitaufwendig. Und dieser Arbeitsaufwand fällt für jede Saison an. Wäre es nicht einfacher, einem Computer beizubringen, diese Aktionen automatisch zu erkennen und zu kennzeichnen, wenn sie in einem Video auftreten?
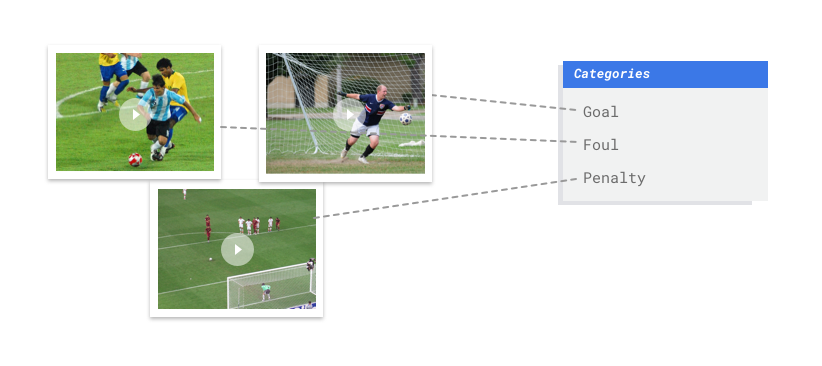
Warum ist maschinelles Lernen (ML) das richtige Werkzeug für dieses Problem?
 Bei der klassischen Programmierung muss ein Programmierer dem Computer alles Schritt für Schritt beibringen. Doch betrachten Sie einmal den Anwendungsfall der Identifizierung bestimmter Aktionen in Fußballspielen. Hier gibt es so viele Variationen bei der Farbe, dem Winkel, der Auflösung und Beleuchtung, dass zu viele Regeln codiert werden müssten, um einer Maschine zu erklären, wie sie die richtige Entscheidung trifft. Schwer vorstellbar, wo Sie überhaupt anfangen würden. Glücklicherweise ist maschinelles Lernen hervorragend geeignet, um dieses Problem zu lösen.
Bei der klassischen Programmierung muss ein Programmierer dem Computer alles Schritt für Schritt beibringen. Doch betrachten Sie einmal den Anwendungsfall der Identifizierung bestimmter Aktionen in Fußballspielen. Hier gibt es so viele Variationen bei der Farbe, dem Winkel, der Auflösung und Beleuchtung, dass zu viele Regeln codiert werden müssten, um einer Maschine zu erklären, wie sie die richtige Entscheidung trifft. Schwer vorstellbar, wo Sie überhaupt anfangen würden. Glücklicherweise ist maschinelles Lernen hervorragend geeignet, um dieses Problem zu lösen.
In diesem Leitfaden erfahren Sie, wie AutoML Video Intelligence Classification dieses Problem, den zugehörigen Arbeitsablauf und die anderen Arten von Problemen lösen kann, für die es entwickelt wurde.
Wie funktioniert AutoML Video Intelligence Classification?
 AutoML Video Intelligence Classification ist eine Aufgabe des überwachten Lernens. Das heißt, Sie trainieren, testen und validieren das Modell für das maschinelle Lernen mit Beispielvideos, die bereits mit Labels versehen wurden. Mit einem trainierten Modell können Sie neue Videos einlesen, die dann als Videosegmente mit Labels ausgegeben werden. Ein Label ist eine vorhergesagte "Antwort" des Modells. Mit einem trainierten Modell für den Fußball-Anwendungsfall können Sie beispielsweise neue Fußballvideos und Videosegmente mit Labels einlesen, die Aktionsaufnahmen wie "Tor", "persönliches Foul" usw. beschreiben.
AutoML Video Intelligence Classification ist eine Aufgabe des überwachten Lernens. Das heißt, Sie trainieren, testen und validieren das Modell für das maschinelle Lernen mit Beispielvideos, die bereits mit Labels versehen wurden. Mit einem trainierten Modell können Sie neue Videos einlesen, die dann als Videosegmente mit Labels ausgegeben werden. Ein Label ist eine vorhergesagte "Antwort" des Modells. Mit einem trainierten Modell für den Fußball-Anwendungsfall können Sie beispielsweise neue Fußballvideos und Videosegmente mit Labels einlesen, die Aktionsaufnahmen wie "Tor", "persönliches Foul" usw. beschreiben.
Der Workflow von AutoML Video Intelligence Classification
AutoML Video Intelligence Classification verwendet einen Standard-Workflow für maschinelles Lernen:
- Daten erfassen: Bestimmen Sie abhängig vom gewünschten Ergebnis die Daten, die Sie zum Trainieren und Testen Ihres Modells benötigen.
- Daten vorbereiten: Achten Sie darauf, dass Ihre Daten ordnungsgemäß formatiert und mit Labels versehen sind.
- Trainieren: Legen Sie Parameter fest und erstellen Sie Ihr Modell.
- Auswerten: Überprüfen Sie die Modellmesswerte.
- Bereitstellen und Vorhersagen: Machen Sie Ihr Modell für die Verwendung verfügbar.
Bevor Sie jedoch mit dem Erfassen von Daten beginnen, sollten Sie über das Problem nachdenken, das Sie lösen möchten, um dies in Ihre Datenanforderungen einfließen zu lassen.
Anwendungsfall betrachten

Beginnen Sie mit dem Problem: Was möchten Sie erreichen? Wie viele Klassen müssen Sie vorhersagen? Eine Klasse ist etwas, dessen Identifizierung Sie Ihrem Modell beibringen wollen. Sie wird in der Modellausgabe als Label dargestellt. (Ein Modell zur Ballerkennung hat beispielsweise zwei Klassen: "Ball" und "Kein Ball".)
Abhängig von Ihren Antworten erstellt AutoML Video Intelligence Classification das erforderliche Modell, um Ihren Anwendungsfall zu lösen:
Ein binäres Klassifikationsmodell sagt ein binäres Ergebnis vorher (eine von zwei Klassen). Verwenden Sie dieses Modell für Ja- oder Nein-Fragen, zum Beispiel, um nur Tore in einem Fußballspiel zu identifizieren ("Ist dies ein Tor oder kein Tor?"). Beim Trainieren eines binären Klassifizierungsproblems kommen Sie generell mit weniger Videodaten aus als bei anderen Problemen.
Ein Klassifizierungsmodell mit mehreren Klassen sagt eine Klasse aus zwei oder mehr gesonderten Klassen vorher. Mit dieser Option können Sie Videosegmente kategorisieren. Beispielsweise, wenn Sie die Segmente einer Olympia-Videobibliothek klassifizieren möchten, um herauszufinden, welcher Sport zu einer bestimmten Zeit gezeigt wird. Die Ausgabe enthält Videosegmente, die einem einzigen Label zugeordnet sind, z. B. Schwimmen oder Turnen.
Ein Klassifizierungsmodell mit mehreren Labels sagt eine oder mehrere Klassen aus vielen möglichen Klassen vorher. Mit diesem Modell können Sie mehrere Klassen in einem einzelnen Videosegment mit Labels versehen. Dieser Problemtyp erfordert häufig mehr Trainingsdaten, da eine Unterscheidung zwischen vielen Klassen komplexer ist.
Das Fußballbeispiel von oben würde einen Klassifizierungsmodus mit mehreren Labels erfordern, da die Klassen (Aktionen wie Tore, persönliche Fouls usw.) gleichzeitig auftreten können, was bedeutet, dass ein einzelnes Videosegment mehrere Labels erfordern kann.
Hinweis zur Fairness
Fairness gehört zu den verantwortungsbewussten Vorgehensweisen bei der künstlichen Intelligenz von Google. Bei Fairness geht es darum, eine ungerechte oder von Vorurteilen beeinflusste Behandlung von Menschen aufgrund ihrer Herkunft, ihres Einkommens, ihrer sexuellen Orientierung, ihrer Religion, ihres Geschlechts und anderer Merkmale, die historisch mit Diskriminierung und Ausgrenzung verbunden waren, dort zu erkennen und zu verhindern, wo sie in Algorithmen oder bei der Entscheidungsfindung durch algorithmische Systeme sichtbar werden. Wenn Sie diesen Leitfaden lesen, sehen Sie "Fair-aware"-Hinweise, die aufzeigen, wie Sie ein faireres Modell für maschinelles Lernen erstellen. Weitere Informationen
Daten erfassen
 Nachdem Sie den Anwendungsfall festgelegt haben, müssen Sie die Videodaten erfassen, um das gewünschte Modell erstellen zu können. Die Daten, die Sie für das Training erfassen, haben einen Einfluss darauf, welche Art von Problemen Sie lösen können. Wie viele Videos können Sie verwenden? Enthalten die Videos genügend Beispiele für Klassen, die Ihr Modell vorhersagen soll? Bedenken Sie beim Erfassen Ihrer Videodaten Folgendes.
Nachdem Sie den Anwendungsfall festgelegt haben, müssen Sie die Videodaten erfassen, um das gewünschte Modell erstellen zu können. Die Daten, die Sie für das Training erfassen, haben einen Einfluss darauf, welche Art von Problemen Sie lösen können. Wie viele Videos können Sie verwenden? Enthalten die Videos genügend Beispiele für Klassen, die Ihr Modell vorhersagen soll? Bedenken Sie beim Erfassen Ihrer Videodaten Folgendes.
Genügend Videos einbeziehen
 Je mehr Trainingsvideos Ihr Dataset enthält, desto besser fällt das Ergebnis aus. Die Anzahl der empfohlenen Videos hängt auch von der Komplexität des Problems ab, das Sie lösen möchten. Beispielsweise benötigen Sie weniger Videodaten für ein binäres Klassifizierungsproblem (Vorhersage einer Klasse von zwei) als für ein Klassifizierungsproblem mit mehreren Labels (Vorhersage von einer oder mehreren Klassen von vielen).
Je mehr Trainingsvideos Ihr Dataset enthält, desto besser fällt das Ergebnis aus. Die Anzahl der empfohlenen Videos hängt auch von der Komplexität des Problems ab, das Sie lösen möchten. Beispielsweise benötigen Sie weniger Videodaten für ein binäres Klassifizierungsproblem (Vorhersage einer Klasse von zwei) als für ein Klassifizierungsproblem mit mehreren Labels (Vorhersage von einer oder mehreren Klassen von vielen).
Wie viele Videodaten Sie benötigen, kann sich auch aus der Komplexität dessen ergeben, was Sie zu klassifizieren versuchen. Betrachten Sie den Fußball-Anwendungsfall, bei dem ein Modell zur Unterscheidung von Aktionsaufnahmen erstellt wird. Vergleichen Sie das mit einem Modell, das zwischen Kolibriarten unterscheidet. Bedenken Sie die Nuancen und Ähnlichkeiten in Farbe, Größe und Form: Sie benötigen mehr Trainingsdaten, damit das Modell lernen kann, wie die einzelnen Arten genau identifiziert werden.
Verwenden Sie diese Regeln als Grundlage, um Ihre Mindestanforderungen an Videodaten zu verstehen:
- 200 Videobeispiele pro Klasse, wenn Sie nur wenige Klassen haben und diese unverwechselbar sind
- Mehr als 1.000 Videobeispiele pro Klasse, wenn Sie mehr als 50 Klassen haben oder wenn die Klassen einander ähnlich sind
Die Menge der erforderlichen Videodaten ist möglicherweise größer als Ihr derzeitiger Bestand. Erwägen Sie, zusätzliche Videos über einen Drittanbieter zu beziehen. Wenn Sie nicht genügend Fußballvideos für Ihr Modell zum Identifizieren von Spielaktionen haben, könnten Sie beispielsweise zusätzliche Videos kaufen oder abrufen.
Videos gleichmäßig auf Klassen verteilen
Versuchen Sie, für jede Klasse eine ähnliche Anzahl von Trainingsbeispielen bereitzustellen. Hier ist der Grund: Stellen Sie sich vor, dass es sich bei 80 % Ihrer Trainings-Datasets um Fußballvideos handelt, die Torschüsse enthalten, aber nur 20 % der Videos persönliche Fouls oder Strafstöße zeigen. Bei einer solch ungleichen Verteilung der Klassen ist die Wahrscheinlichkeit größer, dass Ihr Modell vorhersagt, dass eine bestimmte Aktion ein Tor ist. Dies ist mit einem Multiple-Choice-Test vergleichbar, bei dem 80 % der richtigen Antworten "C" lauten: Ein versiertes Modell wird schnell herausfinden, dass "C" in den meisten Fällen eine ziemlich gute Vermutung ist.

Möglicherweise können Sie nicht für jede Klasse eine identische Anzahl von Videos beschaffen. Qualitativ hochwertige, verzerrungsfreie Beispiele zu finden, kann sich ferner für einige Klassen als schwierig erweisen. Versuchen Sie, ein Verhältnis von 1:10 einzuhalten: Wenn die größte Klasse 10.000 Videos enthält, sollte die kleinste mindestens 1.000 Videos enthalten.
Variation erfassen
Ihre Videodaten sollten die Vielfalt des Problembereichs erfassen. Je vielfältiger die Beispiele sind, die ein Modell während des Trainings sieht, desto schneller kann es neue oder weniger verbreitete Beispiele verallgemeinern. Denken Sie an das Klassifizierungsmodell für Fußballaktionen: Sie möchten Videos mit verschiedenen Kamerawinkeln, Tag- und Nachtzeiten und verschiedenen Spielerbewegungen einbeziehen. Wird das Modell einer Vielzahl von Daten ausgesetzt, kann es besser zwischen den einzelnen Aktionen unterscheiden.
Daten an die beabsichtigte Ausgabe anpassen

Suchen Sie nach Trainingsvideos, die den Videos ähneln, die Sie zur Vorhersage in das Modell einlesen möchten. Wenn beispielsweise alle Trainingsvideos im Winter oder am Abend aufgenommen wurden, wirken sich die Beleuchtungs- und Farbmuster in diesen Umgebungen auf das Modell aus. Wenn Sie dieses Modell dann zum Testen von Videos verwenden, die im Sommer oder bei Tageslicht aufgenommen wurden, erhalten Sie möglicherweise keine genauen Vorhersagen.
Zusätzlich zu berücksichtigende Faktoren: * Videoauflösung * Bilder pro Sekunde * Kamerawinkel * Hintergrund
Daten vorbereiten

Nachdem Sie die Videos erfasst haben, die Sie in Ihr Dataset aufnehmen möchten, müssen Sie prüfen, ob die Videos Begrenzungsrahmen mit Labels enthalten, damit das Modell weiß, wonach es suchen soll.
Warum müssen meine Videos Begrenzungsrahmen und Labels haben?
Wie lernt ein AutoML Video Intelligence Classification-Modell, Muster zu erkennen? Genau hierbei kommen beim Training Begrenzungsrahmen und Labels ins Spiel. In unserem Fußballbeispiel bedeutet dies: Jedes Beispielvideo muss Begrenzungsrahmen um Aktionsaufnahmen haben. Diesen Rahmen müssen außerdem Labels wie "Tor", "persönliches Foul" und "Elfmeter" zugewiesen sein. Andernfalls weiß das Modell nicht, wonach es suchen soll. Das Einzeichnen von Rahmen und das Zuweisen von Beschriftungen zu Ihren Beispielvideos kann einige Zeit dauern. Erwägen Sie ggf. die Verwendung eines Labeling-Dienstes, um die Arbeit an Dritte auszulagern.
Modell trainieren
Wenn die Videodaten für das Trainingsvideo vorbereitet sind, können Sie ein Modell für maschinelles Lernen erstellen. Sie können dasselbe Dataset zum Erstellen verschiedener ML-Modelle verwenden, auch wenn diese unterschiedliche Problemtypen haben.
Einer der Vorteile von AutoML Video Intelligence Classification besteht darin, dass die Standardparameter Sie zu einem zuverlässigen Modell für maschinelles Lernen führen. Möglicherweise müssen Sie jedoch die Parameter entsprechend der Datenqualität und dem gewünschten Ergebnis anpassen. Beispiel:
- Vorhersagetyp (die Detailtiefe, mit der die Videos verarbeitet werden)
- Frame-Rate
- Auflösung
Modell auswerten
 Im Anschluss an das Modelltraining erhalten Sie eine Zusammenfassung der Leistung. Modellbewertungsmesswerte basieren darauf, inwieweit das Modell bei einem Teil Ihres Datasets (dem Validierungs-Dataset) die Leistungserwartungen erfüllen konnte. Bei der Entscheidung, ob Ihr Modell bereit für den Einsatz bei realen Daten ist, müssen Sie einige wichtige Messwerte und Konzepte berücksichtigen.
Im Anschluss an das Modelltraining erhalten Sie eine Zusammenfassung der Leistung. Modellbewertungsmesswerte basieren darauf, inwieweit das Modell bei einem Teil Ihres Datasets (dem Validierungs-Dataset) die Leistungserwartungen erfüllen konnte. Bei der Entscheidung, ob Ihr Modell bereit für den Einsatz bei realen Daten ist, müssen Sie einige wichtige Messwerte und Konzepte berücksichtigen.
Punktzahl-Schwellenwert
Woher weiß ein Modell für maschinelles Lernen, wann ein Fußballtor wirklich ein Tor ist? Jeder Vorhersage wird ein Konfidenzwert zugewiesen – eine numerische Bewertung der Sicherheit des Modells, dass ein bestimmtes Videosegment eine Klasse enthält. Der Punktzahl-Schwellenwert ist die Zahl, die bestimmt, wann eine bestimmte Punktzahl in eine Ja- oder Nein-Entscheidung umgewandelt wird, also der Wert, bei dem Ihr Modell sagt "Ja, dieser Konfidenzwert ist hoch genug, um zu dem Schluss zu gelangen, dass dieses Videosegment ein Tor enthält."

Wenn der Punktzahl-Schwellenwert niedrig ist, besteht die Gefahr, dass Videosegmente mit den falschen Labels versehen werden. Aus diesem Grund sollte der Punktzahl-Schwellenwert auf einem bestimmten Anwendungsfall basieren. Stellen Sie sich einen medizinischen Anwendungsfall wie die Krebserkennung vor, bei dem die Folgen falsch vergebener Labels weitaus gravierender sind als bei Sportvideos. Bei der Krebserkennung ist ein höherer Punktzahl-Schwellenwert angebracht.
Vorhersageergebnisse
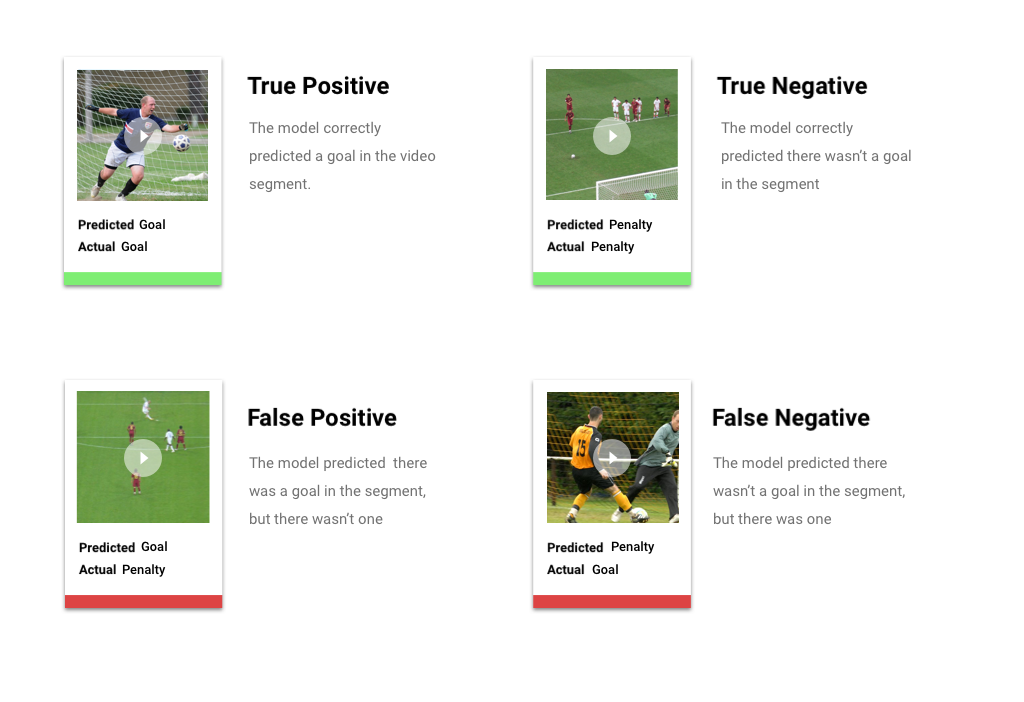
Nach Anwenden des Punktzahl-Schwellenwerts fallen die von Ihrem Modell gemachten Vorhersagen in eine von vier Kategorien. Zum besseren Verständnis dieser Kategorien stellen Sie sich vor, dass Sie ein Modell erstellt haben, um zu erkennen, ob ein bestimmtes Segment ein Fußballtor enthält (oder nicht). In diesem Beispiel ist ein Tor die positive Klasse (also das, was das Modell vorherzusagen versucht).
- Richtig positiv: Das Modell sagt die positive Klasse richtig vorher. Das Modell hat ein Tor im Videosegment korrekt vorhergesagt.
- Falsch positiv: Das Modell sagt die positive Klasse falsch vorher. Das Modell hat vorhergesagt, dass das Segment ein Tor enthält, aber es gab keines.
- Richtig negativ: Das Modell sagt die negative Klasse richtig vorher. Das Modell hat richtig vorhergesagt, dass es im Segment kein Tor gibt.
- Falsch negativ: Das Modell sagt fälschlicherweise eine negative Klasse vorher. Das Modell hat vorhergesagt, dass das Segment kein Tor enthält, aber es gab eines.
Precision und recall
Anhand Precision und Recall können Sie analysieren, wie gut das Modell Informationen erfasst und welche es auslässt. Weitere Informationen zu Genauigkeit und Trefferquote
- Precision ist der Anteil der positiven Vorhersagen, die richtig waren. Welcher Anteil aller Vorhersagen, die mit dem Label "Tor" ("Goal") versehen waren, enthielt tatsächlich ein Tor?
- Trefferquote ist der Anteil aller positiven Vorhersagen, die tatsächlich identifiziert wurden. Welcher Anteil von allen Fußballtoren, die man hätte identifizieren können, wurde tatsächlich identifiziert?
Abhängig von Ihrem Anwendungsfall müssen Sie möglicherweise entweder Precision oder Recall optimieren. Betrachten Sie folgende Anwendungsfälle:
Anwendungsfall: Private Informationen in Videos
Stellen Sie sich vor, Sie entwickeln eine Software, die sensible Informationen in einem Video automatisch erkennt und unkenntlich macht. Falsche Ergebnisse können folgende Auswirkungen haben:
- Ein falsch positives Ergebnis weist auf etwas hin, das nicht zensiert werden muss, aber trotzdem zensiert wird. Das ist zwar ärgerlich, aber nicht von Nachteil.

- Bei einem falsch negativen Ergebnis werden keine Informationen erkannt, die zensiert werden müssen, beispielsweise eine Kreditkartennummer. Dies würde vertrauliche Informationen freigeben und stellt den schlimmsten Fall dar.
In diesem Anwendungsfall ist es wichtig, die Trefferquote zu optimieren, damit das Modell alle relevanten Fälle findet. Bei einem für die Trefferquote optimierten Modell werden eher marginal relevante Beispiele, aber auch eher falsche mit Labels versehen (es wird häufiger als nötig zensiert).
Anwendungsfall: Suche im Videobestand
Angenommen, Sie möchten eine Software erstellen, mit der Nutzer eine Videobibliothek anhand eines Suchbegriffs durchsuchen können. Betrachten wir die falschen Ergebnisse:
- Ein falsch positives Ergebnis liefert ein irrelevantes Video. Da Ihr System versucht, nur relevante Videos zu liefern, macht Ihre Software nicht wirklich das, wofür sie entwickelt wurde.

- Ein falsch negatives Ergebnis liefert kein relevantes Video. Da viele Suchbegriffe für Hunderte von Videos stehen, ist dieses Problem weniger schlimm, als wenn ein irrelevantes Video zurückgegeben würde.

In diesem Beispiel sollten Sie die Genauigkeit optimieren, um sicherzustellen, dass Ihr Modell in hohem Maße relevante, korrekte Ergebnisse liefert. Modelle mit hoher Genauigkeit werden wahrscheinlich nur die relevantesten Beispiele mit Labels versehen, möglicherweise aber das eine oder andere auslassen. Weitere Informationen zu Modellbewertungsmesswerten
Modell bereitstellen
 Wenn Sie mit der Leistung des Modells zufrieden sind, ist es an der Zeit, dass Sie das Modell einsetzen.
AutoML Video Intelligence Classification verwendet Batchvorhersagen, mit denen Sie eine CSV-Datei mit Dateipfaden zu Videos hochladen können, die in Cloud Storage gehostet werden. Ihr Modell verarbeitet dann jedes Video und gibt Vorhersagen in einer anderen CSV-Datei aus. Die Batchvorhersage ist asynchron, d. h. das Modell verarbeitet zuerst alle Vorhersageanfragen, bevor die Ergebnisse ausgegeben werden.
Wenn Sie mit der Leistung des Modells zufrieden sind, ist es an der Zeit, dass Sie das Modell einsetzen.
AutoML Video Intelligence Classification verwendet Batchvorhersagen, mit denen Sie eine CSV-Datei mit Dateipfaden zu Videos hochladen können, die in Cloud Storage gehostet werden. Ihr Modell verarbeitet dann jedes Video und gibt Vorhersagen in einer anderen CSV-Datei aus. Die Batchvorhersage ist asynchron, d. h. das Modell verarbeitet zuerst alle Vorhersageanfragen, bevor die Ergebnisse ausgegeben werden.