Resumo
Este tutorial explica o processo de implementação e apresentação dos modelos Llama 3.1 e 3.2 através do vLLM no Vertex AI. Foi concebido para ser usado em conjunto com dois blocos de notas separados: Publicar Llama 3.1 com o vLLM para implementar modelos Llama 3.1 apenas de texto e Publicar Llama 3.2 multimodal com o vLLM para implementar modelos Llama 3.2 multimodelos que processam entradas de texto e imagem. Os passos descritos nesta página mostram como processar eficientemente a inferência de modelos em GPUs e personalizar modelos para diversas aplicações, equipando-o com as ferramentas para integrar modelos de linguagem avançados nos seus projetos.
No final deste guia, vai saber como:
- Transfira modelos Llama pré-criados do Hugging Face com o contentor vLLM.
- Use o vLLM para implementar estes modelos em instâncias de GPU no Google Cloud Vertex AI Model Garden.
- Publicar modelos de forma eficiente para processar pedidos de inferência à escala.
- Executar inferência em pedidos apenas de texto e pedidos de texto + imagem.
- Limpeza.
- Depure a implementação.
Principais funcionalidades dos vLLMs
| Funcionalidade | Descrição |
|---|---|
| PagedAttention | Um mecanismo de atenção otimizado que gere a memória de forma eficiente durante a inferência. Suporta a geração de texto de elevado débito através da atribuição dinâmica de recursos de memória, o que permite a escalabilidade para vários pedidos simultâneos. |
| Criação de lotes contínua | Consolida vários pedidos de entrada num único lote para processamento paralelo, maximizando a utilização e o débito da GPU. |
| Streaming de tokens | Ativa a saída token a token em tempo real durante a geração de texto. Ideal para aplicações que requerem baixa latência, como chatbots ou sistemas de IA interativos. |
| Compatibilidade de modelos | Suporta uma vasta gama de modelos pré-preparados em frameworks populares, como o Hugging Face Transformers. Facilita a integração e a experimentação com diferentes MDIs. |
| Várias GPUs e vários anfitriões | Permite a publicação eficiente de modelos distribuindo a carga de trabalho por várias GPUs numa única máquina e por várias máquinas num cluster, o que aumenta significativamente o débito e a escalabilidade. |
| Implementação eficiente | Oferece uma integração perfeita com APIs, como as conclusões de chat da OpenAI, o que facilita a implementação para exemplos de utilização de produção. |
| Integração perfeita com os modelos do Hugging Face | O vLLM é compatível com o formato de artefactos do modelo Hugging Face e suporta o carregamento a partir do HF, o que facilita a implementação de modelos Llama juntamente com outros modelos populares, como o Gemma, o Phi e o Qwen, numa definição otimizada. |
| Projeto de código aberto orientado pela comunidade | O vLLM é de código aberto e incentiva as contribuições da comunidade, promovendo a melhoria contínua na eficiência da publicação de LLMs. |
Personalizações de vLLM do Google Vertex AI: melhore o desempenho e a integração
A implementação do vLLM no Google Vertex AI Model Garden não é uma integração direta da biblioteca de código aberto. O Vertex AI mantém uma versão personalizada e otimizada do vLLM especificamente adaptada para melhorar o desempenho, a fiabilidade e a integração perfeita no Google Cloud.
- Otimizações de desempenho:
- Transferência paralela do Cloud Storage: acelera significativamente os tempos de carregamento e implementação de modelos, permitindo a obtenção de dados paralelos do Cloud Storage, reduzindo a latência e melhorando a velocidade de arranque.
- Melhoramentos de funcionalidades:
- LoRA dinâmico com melhorias na colocação em cache e suporte do Cloud Storage: expande as capacidades do LoRA dinâmico com mecanismos de colocação em cache no disco local e processamento de erros robusto, juntamente com suporte para carregar ponderações do LoRA diretamente a partir de caminhos do Cloud Storage e URLs assinados. Isto simplifica a gestão e a implementação de modelos personalizados.
- Análise da chamada de função do Llama 3.1/3.2: implementa a análise especializada para a chamada de função do Llama 3.1/3.2, melhorando a robustez na análise.
- Cache de prefixos de memória do anfitrião: o vLLM externo só suporta a cache de prefixos de memória da GPU.
- Descodificação especulativa: esta é uma funcionalidade existente do vLLM, mas o Vertex AI executou experiências para encontrar configurações de modelos de elevado desempenho.
Estas personalizações específicas da Vertex AI, embora sejam frequentemente transparentes para o utilizador final, permitem-lhe maximizar o desempenho e a eficiência das suas implementações do Llama 3.1 no Vertex AI Model Garden.
- Integração do ecossistema do Vertex AI:
- Suporte do formato de entrada/saída de previsão do Vertex AI: garante a compatibilidade perfeita com os formatos de entrada e saída de previsão do Vertex AI, simplificando o processamento de dados e a integração com outros serviços do Vertex AI.
- Consciência das variáveis de ambiente do Vertex: respeita e tira partido das variáveis de ambiente do Vertex AI (
AIP_*) para configuração e gestão de recursos, simplificando a implementação e garantindo um comportamento consistente no ambiente do Vertex AI. - Processamento de erros e robustez melhorados: implementa mecanismos abrangentes de processamento de erros, validação de entradas/saídas e encerramento do servidor para garantir a estabilidade, a fiabilidade e o funcionamento perfeito no ambiente gerido do Vertex AI.
- Servidor Nginx para capacidade: integra um servidor Nginx sobre o servidor vLLM, facilitando a implementação de várias réplicas e melhorando a escalabilidade e a elevada disponibilidade da infraestrutura de publicação.
Vantagens adicionais dos MMLGs
- Comparar o desempenho: o vLLM oferece um desempenho competitivo quando comparado com outros sistemas de publicação, como o text-generation-inference da Hugging Face e o FasterTransformer da NVIDIA, em termos de taxa de transferência e latência.
- Facilidade de utilização: a biblioteca oferece uma API simples para integração com fluxos de trabalho existentes, o que lhe permite implementar os modelos Llama 3.1 e 3.2 com uma configuração mínima.
- Funcionalidades avançadas: o vLLM suporta saídas de streaming (gerando respostas token a token) e processa de forma eficiente comandos de comprimento variável, melhorando a interatividade e a capacidade de resposta nas aplicações.
Para uma vista geral do sistema vLLM, consulte o ensaio.
Modelos suportados
O vLLM oferece suporte para uma ampla seleção de modelos de última geração, o que lhe permite escolher um modelo que melhor se adapte às suas necessidades. A tabela seguinte oferece uma seleção destes modelos. No entanto, para aceder a uma lista abrangente de modelos suportados, incluindo os de inferência apenas de texto e multimodal, pode consultar o Website oficial do vLLM.
| Categoria | Modelos |
|---|---|
| Meta AI | Llama 3.3, Llama 3.2, Llama 3.1, Llama 3, Llama 2, Code Llama |
| Mistral AI | Mistral 7B, Mixtral 8x7B, Mixtral 8x22B e as respetivas variantes (Instruct e Chat), Mistral-tiny, Mistral-small e Mistral-medium |
| DeepSeek AI | DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama-8B, DeepSeek-R1-Distill-Qwen-14B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B, Deepseek-vl2-tiny, Deepseek-vl2-small e Deepseek-vl2 |
| MosaicML | MPT (7B e 30B) e variantes (Instruct e Chat), MPT-7B-StoryWriter-65k |
| OpenAI | GPT-2, GPT-3, GPT-4 e GPT-NeoX |
| Together AI | RedPajama, Pythia |
| Stability AI | StableLM (3B, 7B), StableLM-Alpha-3B, StableLM-Base-Alpha-7B, StableLM-Instruct-Alpha-7B |
| TII (Technology Innovation Institute) | Falcon 7B, Falcon 40B e variantes (Instruct, Chat), Falcon-RW-1B, Falcon-RW-7B |
| BigScience | BLOOM, BLOOMZ |
| FLAN-T5, UL2, Gemma (2B e 7B) e PaLM 2 | |
| Salesforce | CodeT5 e CodeT5+ |
| LightOn | Persimmon-8B-base e Persimmon-8B-chat |
| EleutherAI | GPT-Neo e Pythia |
| AI21 Labs | Jamba |
| Cerebras | Cerebras-GPT |
| Intel | Intel-NeuralChat-7B |
| Outros modelos proeminentes | StarCoder, OPT, Baichuan, Aquila, Qwen, InternLM, XGen, OpenLLaMA, Phi-2, Yi, OpenCodeInterpreter, Nous-Hermes, Gemma-it, Mistral-Instruct-v0.2-7B-Zeus, |
Comece a usar o Model Garden
O contentor de serviço de GPUs do vLLM Cloud está integrado no Model Garden, no playground, na implementação com um clique e nos exemplos de blocos de notas do Colab Enterprise. Este tutorial centra-se na família de modelos Llama da Meta AI como exemplo.
Use o bloco de notas do Colab Enterprise
As implementações de Playground e de um clique também estão disponíveis, mas não são descritas neste tutorial.
- Navegue para a página do cartão do modelo e clique em Abrir bloco de notas.
- Selecione o notebook Vertex Serving. O bloco de notas é aberto no Colab Enterprise.
- Execute o bloco de notas para implementar um modelo através do vLLM e envie pedidos de previsão para o ponto final.
Configuração e requisitos
Esta secção descreve os passos necessários para configurar o seu projeto Google Cloud e garantir que tem os recursos necessários para implementar e publicar modelos vLLM.
1. Faturação
- Ative a faturação: certifique-se de que a faturação está ativada para o seu projeto. Pode consultar o artigo Ative, desative ou altere a faturação de um projeto.
2. Disponibilidade e quotas de GPUs
- Para executar previsões com GPUs de alto desempenho (NVIDIA A100 de 80 GB ou H100 de 80 GB), certifique-se de que verifica as suas quotas para estas GPUs na região selecionada:
| Tipo de máquina | Tipo de acelerador | Regiões recomendadas |
|---|---|---|
| a2-ultragpu-1g | 1 NVIDIA_A100_80GB | us-central1, us-east4, europe-west4 e asia-southeast1 |
| a3-highgpu-8g | 8 NVIDIA_H100_80GB | us-central1, us-west1, europe-west4 e asia-southeast1 |
3. Configure um Google Cloud projeto
Execute o seguinte exemplo de código para se certificar de que o seu Google Cloud ambiente está configurado corretamente. Este passo instala as bibliotecas Python necessárias e configura o acesso aos Google Cloud recursos. As ações incluem:
- Instalação: atualize a biblioteca
google-cloud-aiplatforme clone o repositório que contém funções de utilidade. - Configuração do ambiente: definir variáveis para o Google Cloud ID do projeto, a região e um contentor do Cloud Storage exclusivo para armazenar artefactos do modelo.
- Ativação da API: ative as APIs Vertex AI e Compute Engine, que são essenciais para implementar e gerir modelos de IA.
- Configuração do contentor: crie um novo contentor do Cloud Storage ou verifique um contentor existente para garantir que está na região correta.
- Inicialização do Vertex AI: inicialize a biblioteca do cliente do Vertex AI com as definições do projeto, da localização e do contentor de preparação.
- Configuração da conta de serviço: identifique a conta de serviço predefinida para executar tarefas do Vertex AI e conceda-lhe as autorizações necessárias.
BUCKET_URI = "gs://"
REGION = ""
! pip3 install --upgrade --quiet 'google-cloud-aiplatform>=1.64.0'
! git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git
import datetime
import importlib
import os
import uuid
from typing import Tuple
import requests
from google.cloud import aiplatform
common_util = importlib.import_module(
"vertex-ai-samples.community-content.vertex_model_garden.model_oss.notebook_util.common_util"
)
models, endpoints = {}, {}
PROJECT_ID = os.environ["GOOGLE_CLOUD_PROJECT"]
if not REGION:
REGION = os.environ["GOOGLE_CLOUD_REGION"]
print("Enabling Vertex AI API and Compute Engine API.")
! gcloud services enable aiplatform.googleapis.com compute.googleapis.com
now = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
if BUCKET_URI is None or BUCKET_URI.strip() == "" or BUCKET_URI == "gs://":
BUCKET_URI = f"gs://{PROJECT_ID}-tmp-{now}-{str(uuid.uuid4())[:4]}"
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
! gsutil mb -l {REGION} {BUCKET_URI}
else:
assert BUCKET_URI.startswith("gs://"), "BUCKET_URI must start with `gs://`."
shell_output = ! gsutil ls -Lb {BUCKET_NAME} | grep "Location constraint:" | sed "s/Location constraint://"
bucket_region = shell_output[0].strip().lower()
if bucket_region != REGION:
raise ValueError(
"Bucket region %s is different from notebook region %s"
% (bucket_region, REGION)
)
print(f"Using this Bucket: {BUCKET_URI}")
STAGING_BUCKET = os.path.join(BUCKET_URI, "temporal")
MODEL_BUCKET = os.path.join(BUCKET_URI, "llama3_1")
print("Initializing Vertex AI API.")
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET)
shell_output = ! gcloud projects describe $PROJECT_ID
project_number = shell_output[-1].split(":")[1].strip().replace("'", "")
SERVICE_ACCOUNT = "your service account email"
print("Using this default Service Account:", SERVICE_ACCOUNT)
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.admin $BUCKET_NAME
! gcloud config set project $PROJECT_ID
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/storage.admin"
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/aiplatform.user"
Usar o Hugging Face com o Meta Llama 3.1, 3.2 e vLLM
As coleções Llama 3.1 e 3.2 da Meta oferecem uma variedade de grandes modelos de linguagem (GMLs) multilingues concebidos para a geração de texto de alta qualidade em vários exemplos de utilização. Estes modelos são pré-treinados e ajustados por instruções, destacando-se em tarefas como diálogo multilingue, resumo e obtenção de informações com base em agentes. Antes de usar os modelos Llama 3.1 e 3.2, tem de aceitar os respetivos termos de utilização, conforme mostrado na captura de ecrã. A biblioteca vLLM oferece um ambiente de publicação simplificado de código aberto com otimizações para latência, eficiência de memória e escalabilidade.
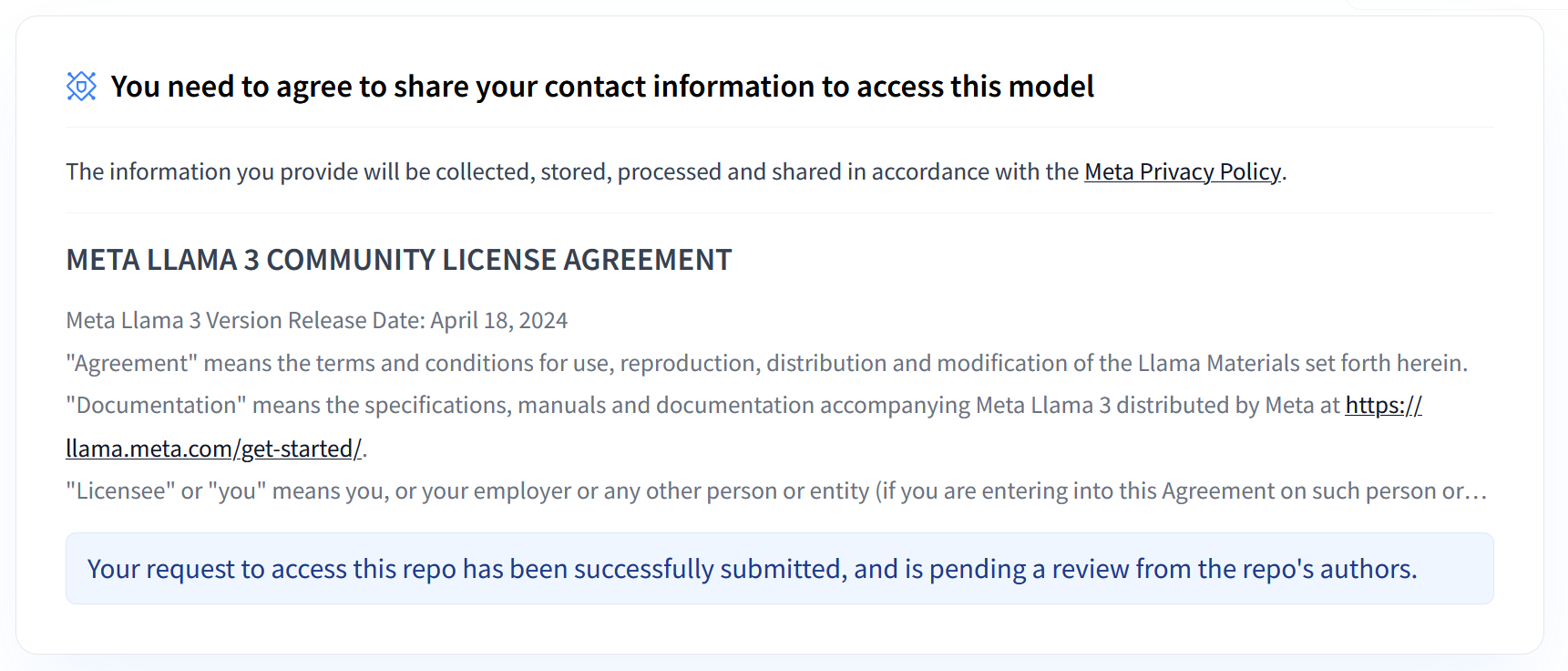 Figura 1: Contrato de licença da comunidade Meta LLama 3
Figura 1: Contrato de licença da comunidade Meta LLama 3
Vista geral das coleções Meta Llama 3.1 e 3.2
As coleções Llama 3.1 e 3.2 destinam-se a diferentes escalas de implementação e tamanhos de modelos, oferecendo-lhe opções flexíveis para tarefas de diálogo multilingues e muito mais. Consulte a página de vista geral do Llama para mais informações.
- Apenas texto: a coleção Llama 3.2 de grandes modelos de linguagem (GMLs) multilingues é uma coleção de modelos generativos pré-preparados e otimizados para instruções nos tamanhos de 1 mil milhões e 3 mil milhões (texto de entrada, texto de saída).
- Vision e Vision Instruct: a coleção Llama 3.2-Vision de modelos de linguagem (conteúdo extenso) (MDIs/CEs) multimodais é uma coleção de modelos generativos de raciocínio de imagens pré-treinados e ajustados por instruções nos tamanhos de 11 mil milhões e 90 mil milhões (texto + imagens de entrada, texto de saída). Otimização: tal como o Llama 3.1, os modelos 3.2 são personalizados para o diálogo multilingue e têm um bom desempenho em tarefas de obtenção e resumo, alcançando os melhores resultados em testes de referência padrão.
- Arquitetura do modelo: o Llama 3.2 também inclui uma estrutura de transformador autorregressiva, com SFT e RLHF aplicados para alinhar os modelos em termos de utilidade e segurança.
Tokens de acesso de utilizadores do Hugging Face
Este tutorial requer um token de acesso de leitura do Hugging Face Hub para aceder aos recursos necessários. Siga estes passos para configurar a autenticação:
 Figura 2: definições do token de acesso do Hugging Face
Figura 2: definições do token de acesso do Hugging Face
Gere um token de acesso de leitura:
- Navegue para as definições da sua conta do Hugging Face.
- Crie um novo token, atribua-lhe a função de leitura e guarde o token em segurança.
Use o token:
- Use o token gerado para autenticar e aceder a repositórios públicos ou privados, conforme necessário para o tutorial.
 Figura 3: faça a gestão do token de acesso do Hugging Face
Figura 3: faça a gestão do token de acesso do Hugging Face
Esta configuração garante que tem o nível de acesso adequado sem autorizações desnecessárias. Estas práticas melhoram a segurança e evitam a exposição acidental de tokens. Para mais informações sobre como configurar tokens de acesso, visite a página de tokens de acesso da Hugging Face.
Evite partilhar ou expor o seu token publicamente ou online. Quando define o seu token como uma variável de ambiente durante a implementação, este permanece privado para o seu projeto. O Vertex AI garante a sua segurança impedindo que outros utilizadores acedam aos seus modelos e pontos finais.
Para mais informações sobre a proteção do seu token de acesso, consulte o artigo Tokens de acesso da Hugging Face – Práticas recomendadas.
Implementação de modelos Llama 3.1 apenas de texto com o vLLM
Para a implementação ao nível da produção de grandes modelos de linguagem, o vLLM oferece uma solução de serviço eficiente que otimiza a utilização da memória, reduz a latência e aumenta o débito. Isto torna-o particularmente adequado para processar os modelos Llama 3.1 maiores, bem como os modelos Llama 3.2 multimodais.
Passo 1: escolha um modelo para implementar
Escolha a variante do modelo Llama 3.1 a implementar. As opções disponíveis incluem vários tamanhos e versões ajustadas por instruções:
base_model_name = "Meta-Llama-3.1-8B" # @param ["Meta-Llama-3.1-8B", "Meta-Llama-3.1-8B-Instruct", "Meta-Llama-3.1-70B", "Meta-Llama-3.1-70B-Instruct", "Meta-Llama-3.1-405B-FP8", "Meta-Llama-3.1-405B-Instruct-FP8"]
hf_model_id = "meta-Llama/" + base_model_name
Passo 2: verifique o hardware de implementação e a quota
A função deploy define o tipo de GPU e de máquina adequados com base no tamanho do modelo e verifica a quota nessa região para um projeto específico:
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
Verifique a disponibilidade da quota de GPUs na região especificada:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Passo 3: inspecione o modelo com o vLLM
A função seguinte carrega o modelo para o Vertex AI, configura as definições de implementação e implementa-o num ponto final através do vLLM.
- Imagem do Docker: a implementação usa uma imagem do Docker vLLM pré-criada para uma publicação eficiente.
- Configuração: configure a utilização da memória, o comprimento do modelo e outras definições do vLLM. Para mais informações sobre os argumentos suportados pelo servidor, visite a página de documentação oficial do vLLM.
- Variáveis de ambiente: defina variáveis de ambiente para a autenticação e a origem da implementação.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 256,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
vllm_args = [
"python", "-m", "vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}", f"--dtype={dtype}",
f"--max-loras={max_loras}", f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}", "--disable-log-stats"
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": model_id,
"DEPLOY_SOURCE": "notebook",
"HF_TOKEN": HF_TOKEN
}
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Passo 4: execute a implementação
Execute a função de implementação com o modelo e a configuração selecionados. Este passo implementa o modelo e devolve as instâncias do modelo e do ponto final:
HF_TOKEN = ""
VLLM_DOCKER_URI = "us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241001_0916_RC00"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
gpu_memory_utilization = 0.9
max_model_len = 4096
max_loras = 1
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve"),
model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=use_dedicated_endpoint,
)
Depois de executar este exemplo de código, o seu modelo Llama 3.1 é implementado no Vertex AI e fica acessível através do ponto final especificado. Pode interagir com ele para tarefas de inferência, como geração de texto, resumo e diálogo. Consoante o tamanho do modelo, a implementação do novo modelo pode demorar até uma hora. Pode verificar o progresso na previsão online.
 Figura 4: ponto final de implementação do Llama 3.1 no painel de controlo do Vertex
Figura 4: ponto final de implementação do Llama 3.1 no painel de controlo do Vertex
Fazer previsões com o Llama 3.1 no Vertex AI
Depois de implementar com êxito o modelo Llama 3.1 no Vertex AI, pode começar a fazer previsões enviando comandos de texto para o ponto final. Esta secção apresenta um exemplo de geração de respostas com vários parâmetros personalizáveis para controlar o resultado.
Passo 1: defina o comando e os parâmetros
Comece por configurar o comando de texto e os parâmetros de amostragem para orientar a resposta do modelo. Seguem-se os parâmetros principais:
prompt: o texto de entrada para o qual quer que o modelo gere uma resposta. Por exemplo, prompt = "O que é um carro?".max_tokens: o número máximo de tokens na saída gerada. A redução deste valor pode ajudar a evitar problemas de limite de tempo.temperature: controla a aleatoriedade das previsões. Os valores mais elevados (por exemplo, 1,0) aumentam a diversidade, enquanto os valores mais baixos (por exemplo, 0,5) tornam a saída mais focada.top_p: limita o conjunto de amostragem à probabilidade cumulativa superior. Por exemplo, definir top_p = 0,9 só considera os tokens na massa de probabilidade dos 90% superiores.top_k: limita a amostragem aos k principais tokens mais prováveis. Por exemplo, se definir top_k = 50, a amostragem só é feita a partir dos 50 principais tokens.raw_response: se for Verdadeiro, devolve o resultado do modelo não processado. Se for False, aplique formatação adicional com a estrutura "Prompt:\n{prompt}\nOutput:\n{output}".lora_id(opcional): caminho para os ficheiros de pesos LoRA para aplicar pesos de adaptação de baixo nível (LoRA). Pode ser um contentor do Cloud Storage ou um URL do repositório do Hugging Face. Tenha em atenção que isto só funciona se--enable-loraestiver definido nos argumentos de implementação. O Dynamic LoRA não é suportado para modelos multimodais.
prompt = "What is a car?"
max_tokens = 50
temperature = 1.0
top_p = 1.0
top_k = 1
raw_response = False
lora_id = ""
Passo 2: envie o pedido de previsão
Agora que a instância está configurada, pode enviar o pedido de previsão para o ponto final do Vertex AI implementado. Este exemplo mostra como fazer uma previsão e imprimir o resultado:
response = endpoints["vllm_gpu"].predict(
instances=instances, use_dedicated_endpoint=use_dedicated_endpoint
)
for prediction in response.predictions:
print(prediction)
Exemplo de resultado
Segue-se um exemplo de como o modelo pode responder ao comando "O que é um carro?":
Human: What is a car?
Assistant: A car, or a motor car, is a road-connected human-transportation system
used to move people or goods from one place to another.
Notas adicionais
- Moderação: para garantir conteúdo seguro, pode moderar o texto gerado com as capacidades de moderação de texto do Vertex AI.
- Processar limites de tempo: se tiver problemas como
ServiceUnavailable: 503, experimente reduzir o parâmetromax_tokens.
Esta abordagem oferece uma forma flexível de interagir com o modelo Llama 3.1 através de diferentes técnicas de amostragem e adaptadores LoRA, o que o torna adequado para uma variedade de exemplos de utilização, desde a geração de texto de uso geral a respostas específicas de tarefas.
Implementar modelos Llama 3.2 multimodais com o vLLM
Esta secção explica o processo de carregamento de modelos Llama 3.2 pré-criados para o Registo de modelos e a respetiva implementação num ponto final do Vertex AI. A implementação pode demorar até uma hora, consoante o tamanho do modelo. Os modelos Llama 3.2 estão disponíveis em versões multimodais que suportam entradas de texto e de imagem. O vLLM suporta:
- Formato apenas de texto
- Formato de imagem única + texto
Estes formatos tornam o Llama 3.2 adequado para aplicações que requerem processamento de texto e visual.
Passo 1: escolha um modelo para implementar
Especifique a variante do modelo Llama 3.2 que quer implementar. O exemplo seguinte usa o modelo Llama-3.2-11B-Vision selecionado, mas pode escolher entre outras opções disponíveis com base nos seus requisitos.
base_model_name = "Llama-3.2-11B-Vision" # @param ["Llama-3.2-1B", "Llama-3.2-1B-Instruct", "Llama-3.2-3B", "Llama-3.2-3B-Instruct", "Llama-3.2-11B-Vision", "Llama-3.2-11B-Vision-Instruct", "Llama-3.2-90B-Vision", "Llama-3.2-90B-Vision-Instruct"]
hf_model_id = "meta-Llama/" + base_model_name
Passo 2: configure o hardware e os recursos
Selecione o hardware adequado para o tamanho do modelo. O vLLM pode usar diferentes GPUs consoante as necessidades computacionais do modelo:
- Modelos de 1B e 3B: use GPUs NVIDIA L4.
- Modelos 11B: use GPUs NVIDIA A100.
- Modelos 90B: use GPUs NVIDIA H100.
Este exemplo configura a implementação com base na seleção do modelo:
if "3.2-1B" in base_model_name or "3.2-3B" in base_model_name:
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-8"
accelerator_count = 1
elif "3.2-11B" in base_model_name:
accelerator_type = "NVIDIA_TESLA_A100"
machine_type = "a2-highgpu-1g"
accelerator_count = 1
elif "3.2-90B" in base_model_name:
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {base_model_name}.")
Certifique-se de que tem a quota de GPU necessária:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Passo 3: implemente o modelo com o vLLM
A função seguinte processa a implementação do modelo Llama 3.2 no Vertex AI. Configura o ambiente, a utilização de memória e as definições do vLLM do modelo para uma publicação eficiente.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 12,
model_type: str = None,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if not base_model_id:
base_model_id = model_id
vllm_args = [
"python",
"-m",
"vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}",
f"--dtype={dtype}",
f"--max-loras={max_loras}",
f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}",
"--disable-log-stats",
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": base_model_id,
"DEPLOY_SOURCE": "notebook",
}
# HF_TOKEN is not a compulsory field and may not be defined.
try:
if HF_TOKEN:
env_vars["HF_TOKEN"] = HF_TOKEN
except NameError:
pass
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Passo 4: execute a implementação
Execute a função de implementação com o modelo e as definições configurados. A função devolve as instâncias do modelo e do ponto final, que pode usar para a inferência.
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
enforce_eager=True,
use_dedicated_endpoint=use_dedicated_endpoint,
max_num_seqs=max_num_seqs,
)
 Figura 5: ponto final de implementação do Llama 3.2 no painel de controlo do Vertex AI
Figura 5: ponto final de implementação do Llama 3.2 no painel de controlo do Vertex AI
Consoante o tamanho do modelo, a implementação do novo modelo pode demorar até uma hora a ser concluída. Pode verificar o respetivo progresso na previsão online.
Inferência com o vLLM no Vertex AI através da rota de previsão predefinida
Esta secção explica como configurar a inferência para o modelo Llama 3.2 Vision no Vertex AI através da rota de previsão predefinida. Vai usar a biblioteca vLLM para uma publicação eficiente e interagir com o modelo enviando um comando visual em combinação com texto.
Para começar, certifique-se de que o ponto final do modelo está implementado e pronto para previsões.
Passo 1: defina o comando e os parâmetros
Este exemplo fornece um URL de imagem e um comando de texto, que o modelo vai processar para gerar uma resposta.
 Figura 6: exemplo de entrada de imagem para pedir ao Llama 3.2
Figura 6: exemplo de entrada de imagem para pedir ao Llama 3.2
image_url = "https://images.pexels.com/photos/1254140/pexels-photo-1254140.jpeg"
raw_prompt = "This is a picture of"
# Reference prompt formatting guidelines here: https://www.Llama.com/docs/model-cards-and-prompt-formats/Llama3_2/#-base-model-prompt
prompt = f"<|begin_of_text|><|image|>{raw_prompt}"
Passo 2: configure os parâmetros de previsão
Ajuste os seguintes parâmetros para controlar a resposta do modelo:
max_tokens = 64
temperature = 0.5
top_p = 0.95
Passo 3: prepare o pedido de previsão
Configure o pedido de previsão com o URL da imagem, o comando e outros parâmetros.
instances = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_url},
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p,
},
]
Passo 4: faça a previsão
Envie o pedido para o seu ponto final da Vertex AI e processe a resposta:
response = endpoints["vllm_gpu"].predict(instances=instances)
for raw_prediction in response.predictions:
prediction = raw_prediction.split("Output:")
print(prediction[1])
Se encontrar um problema de limite de tempo (por exemplo, ServiceUnavailable: 503 Took too
long to respond when processing), experimente reduzir o valor de max_tokens para um número inferior, como 20, para mitigar o tempo de resposta.
Inferência com vLLM no Vertex AI através da API Chat Completion da OpenAI
Esta secção aborda como realizar a inferência nos modelos Llama 3.2 Vision através da API OpenAI Chat Completions na Vertex AI. Esta abordagem permite-lhe usar capacidades multimodais enviando comandos de texto e imagens para o modelo para obter respostas mais interativas.
Passo 1: execute a implementação do modelo Llama 3.2 Vision Instruct
Execute a função de implementação com o modelo e as definições configurados. A função devolve as instâncias do modelo e do ponto final, que pode usar para a inferência.
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
model, endpoint = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type="a2-highgpu-1g",
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
gpu_memory_utilization=0.9,
max_model_len=4096,
enforce_eager=True,
max_num_seqs=12,
)
Passo 2: configure o recurso de ponto final
Comece por configurar o nome do recurso do ponto final para a implementação do Vertex AI.
ENDPOINT_RESOURCE_NAME = "projects/{}/locations/{}/endpoints/{}".format(
PROJECT_ID, REGION, endpoint.name
)
Passo 3: instale o SDK da OpenAI e as bibliotecas de autenticação
Para enviar pedidos através do SDK da OpenAI, certifique-se de que as bibliotecas necessárias estão instaladas:
!pip install -qU openai google-auth requests
Passo 4: defina os parâmetros de entrada para a conclusão de chat
Configure o URL da imagem e o comando de texto que vão ser enviados para o modelo. Ajuste max_tokens e temperature para controlar a duração e a aleatoriedade da resposta, respetivamente.
user_image = "https://images.freeimages.com/images/large-previews/ab3/puppy-2-1404644.jpg"
user_message = "Describe this image?"
max_tokens = 50
temperature = 1.0
Passo 5: configure a autenticação e o URL base
Recupere as suas credenciais e defina o URL base para pedidos API.
import google.auth
import openai
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
BASE_URL = (
f"https://{REGION}-aiplatform.googleapis.com/v1beta1/{ENDPOINT_RESOURCE_NAME}"
)
try:
if use_dedicated_endpoint:
BASE_URL = f"https://{DEDICATED_ENDPOINT_DNS}/v1beta1/{ENDPOINT_RESOURCE_NAME}"
except NameError:
pass
Passo 6: envie o pedido de conclusão de chat
Usando a API Chat Completions da OpenAI, envie a imagem e o comando de texto para o seu ponto final da Vertex AI:
client = openai.OpenAI(base_url=BASE_URL, api_key=creds.token)
model_response = client.chat.completions.create(
model="",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": user_image}},
{"type": "text", "text": user_message},
],
}
],
temperature=temperature,
max_tokens=max_tokens,
)
print(model_response)
(Opcional) Passo 7: volte a associar a um ponto final existente
Para voltar a ligar-se a um ponto final criado anteriormente, use o ID do ponto final. Este passo é útil se quiser reutilizar um ponto final em vez de criar um novo.
endpoint_name = ""
aip_endpoint_name = (
f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_name}"
)
endpoint = aiplatform.Endpoint(aip_endpoint_name)
Esta configuração oferece flexibilidade para alternar entre os pontos finais criados recentemente e os existentes, conforme necessário, o que permite testes e implementação simplificados.
Limpeza
Para evitar cobranças contínuas e libertar recursos, certifique-se de que elimina os modelos implementados, os pontos finais e, opcionalmente, o contentor de armazenamento usado para esta experiência.
Passo 1: elimine pontos finais e modelos
O código seguinte anula a implementação de cada modelo e elimina os pontos finais associados:
# Undeploy model and delete endpoint
for endpoint in endpoints.values():
endpoint.delete(force=True)
# Delete models
for model in models.values():
model.delete()
Passo 2: (opcional) elimine o contentor do armazenamento na nuvem
Se criou um contentor do Cloud Storage especificamente para esta experiência, pode eliminá-lo definindo delete_bucket como True. Este passo é opcional, mas recomendado se já não precisar do contentor.
delete_bucket = False
if delete_bucket:
! gsutil -m rm -r $BUCKET_NAME
Seguindo estes passos, garante que todos os recursos usados neste tutorial são limpos, o que reduz os custos desnecessários associados à experiência.
Depuração de problemas comuns
Esta secção fornece orientações sobre a identificação e a resolução de problemas comuns encontrados durante a implementação e a inferência do modelo vLLM no Vertex AI.
Verifique os registos
Verifique os registos para identificar a causa principal das falhas de implementação ou do comportamento inesperado:
- Navegue para a consola do Vertex AI Prediction: aceda à consola do Vertex AI Prediction na Google Cloud consola.
- Selecione o ponto final: clique no ponto final que está a ter problemas. O estado deve indicar se a implementação falhou.
- Ver registos: clique no ponto final e, de seguida, navegue para o separador Registos ou clique em Ver registos. Isto direciona-o para o Cloud Logging, filtrado para mostrar registos específicos desse ponto final e implementação do modelo. Também pode aceder aos registos diretamente através do serviço Cloud Logging.
- Analise os registos: reveja as entradas de registo para ver mensagens de erro, avisos e outras informações relevantes. Veja as indicações de tempo para correlacionar as entradas do registo com ações específicas. Procure problemas relacionados com restrições de recursos (memória e CPU), problemas de autenticação ou erros de configuração.
Problema comum 1: CUDA Out of Memory (OOM) durante a implementação
Os erros de falta de memória (OOM) da CUDA ocorrem quando a utilização de memória do modelo excede a capacidade da GPU disponível.
No caso do modelo apenas de texto, usámos os seguintes argumentos do motor:
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 256
No caso do modelo multimodal, usámos os seguintes argumentos do motor:
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 12
A implementação do modelo multimodal com max_num_seqs = 256, como fizemos no caso do modelo apenas de texto, pode causar o seguinte erro:
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.91 GiB. GPU 0 has a total capacity of 39.38 GiB of which 3.76 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use. Of the allocated memory 34.94 GiB is allocated by PyTorch, and 175.15 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
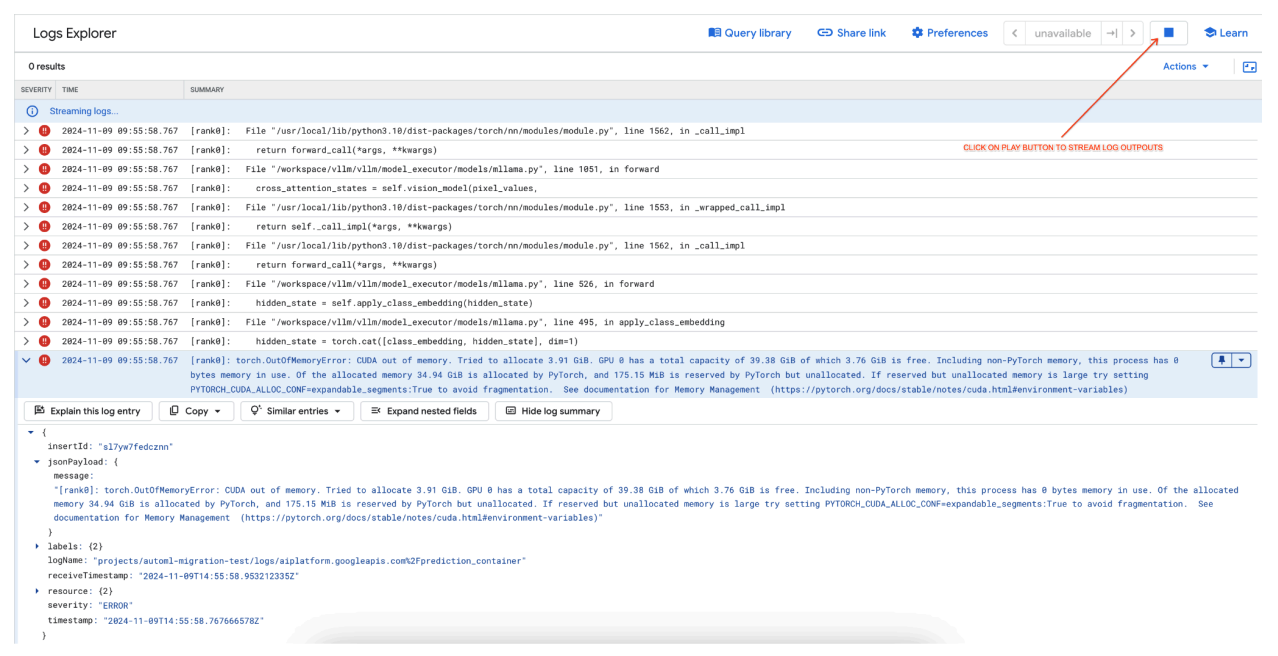 Figura 7: Registo de erros de GPU sem memória (OOM)
Figura 7: Registo de erros de GPU sem memória (OOM)
Compreenda a max_num_seqs e a memória da GPU:
- O parâmetro
max_num_seqsdefine o número máximo de pedidos simultâneos que o modelo pode processar. - Cada sequência processada pelo modelo consome memória da GPU. A utilização total de memória é proporcional a
max_num_seqsvezes a memória por sequência. - Geralmente, os modelos apenas de texto (como Meta-Llama-3.1-8B) consomem menos memória por sequência do que os modelos multimodais (como Llama-3.2-11B-Vision-Instruct), que processam texto e imagens.
Reveja o registo de erros (figura 8):
- O registo mostra um
torch.OutOfMemoryErrorao tentar atribuir memória na GPU. - O erro ocorre porque a utilização de memória do modelo excede a capacidade da GPU disponível. A GPU NVIDIA L4 tem 24 GB e a definição do parâmetro
max_num_seqsdemasiado elevada para o modelo multimodal provoca um excesso. - O registo sugere definir
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:Truepara melhorar a gestão de memória, embora o problema principal aqui seja a utilização elevada de memória.
 Figura 8: implementação do Llama 3.2 com falha
Figura 8: implementação do Llama 3.2 com falha
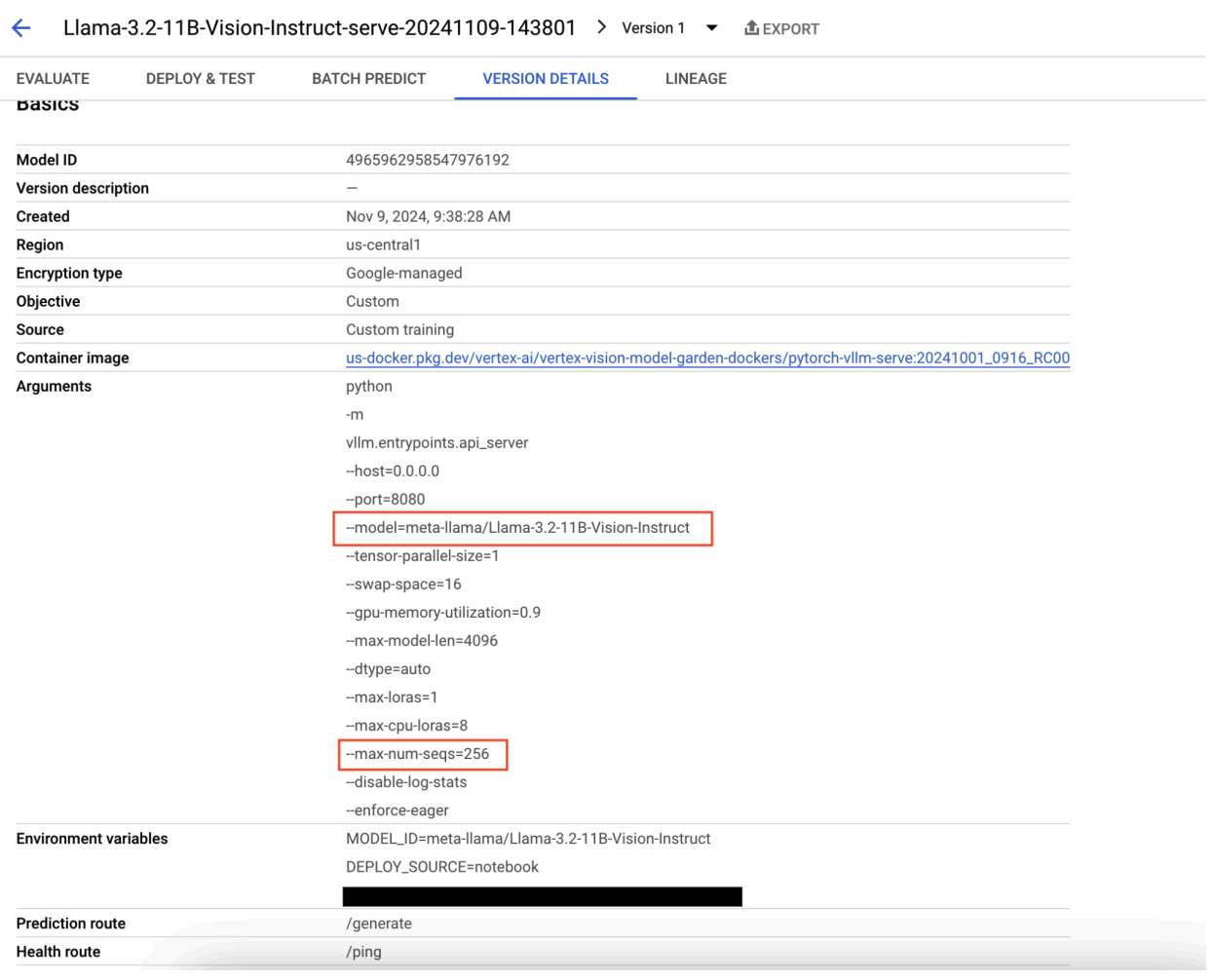 Figura 9: painel de detalhes da versão do modelo
Figura 9: painel de detalhes da versão do modelo
Para resolver este problema, navegue para a consola do Vertex AI Prediction e clique no ponto final. O estado deve indicar que a implementação falhou. Clique para ver os registos. Verifique se max-num-seqs = 256. Este valor é demasiado elevado para o Llama-3.2-11B-Vision-Instruct. Um valor mais adequado deve ser 12.
Problema comum 2: é necessário um token do Hugging Face
Os erros de token do Hugging Face ocorrem quando o modelo está restrito e requer credenciais de autenticação adequadas para aceder.
A captura de ecrã seguinte apresenta uma entrada de registo no Log Explorer do Google Cloud, que mostra uma mensagem de erro relacionada com o acesso ao modelo Meta LLaMA-3.2-11B-Vision alojado no Hugging Face. O erro indica que o acesso ao modelo está restrito, o que requer autenticação para continuar. A mensagem indica especificamente "Não é possível aceder ao repositório restrito para o URL", realçando que o modelo é restrito e requer credenciais de autenticação adequadas para aceder ao mesmo. Esta entrada de registo pode ajudar a resolver problemas de autenticação quando trabalha com recursos restritos em repositórios externos.
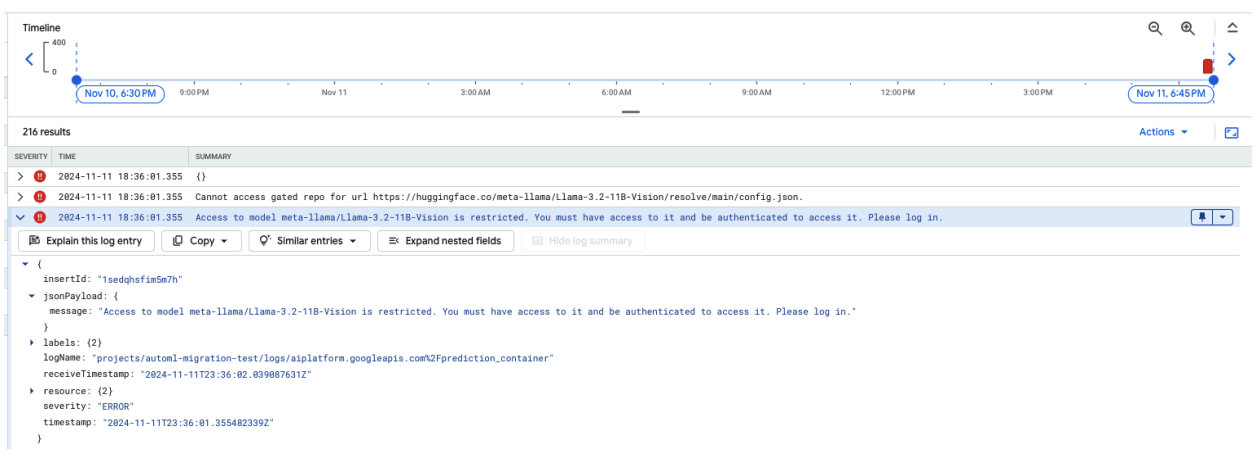 Figura 10: erro de token do Hugging Face
Figura 10: erro de token do Hugging Face
Para resolver este problema, valide as autorizações do seu token de acesso do Hugging Face. Copie o token mais recente e implemente um novo ponto final.
Problema comum 3: é necessário um modelo de chat
Os erros de modelo de chat ocorrem quando o modelo de chat predefinido já não é permitido e tem de ser fornecido um modelo de chat personalizado se o tokenizador não definir um.
Esta captura de ecrã mostra uma entrada de registo no Log Explorer do Google Cloud, onde ocorre um ValueError devido a um modelo de chat em falta na versão 4.44 da biblioteca de transformadores. A mensagem de erro indica que o modelo de chat predefinido já não é permitido e que tem de ser fornecido um modelo de chat personalizado se o tokenizador não definir um. Este erro realça uma alteração recente na biblioteca que requer a definição explícita de um modelo de chat, útil para resolver problemas ao implementar aplicações baseadas em chat.
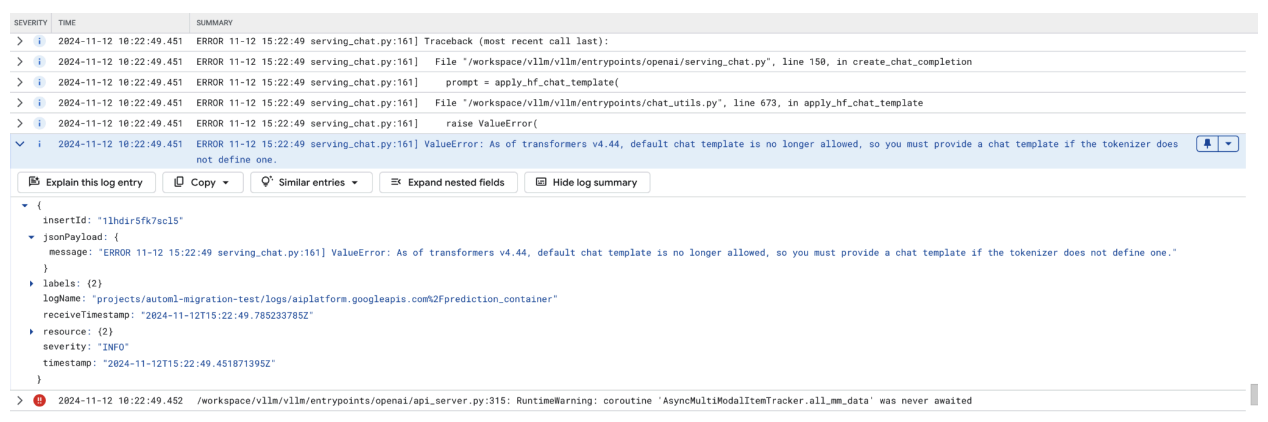 Figura 11: modelo de chat necessário
Figura 11: modelo de chat necessário
Para contornar esta situação, certifique-se de que fornece um modelo de chat durante a implementação através do argumento de entrada --chat-template. Pode encontrar modelos de exemplo no repositório de exemplos do vLLM.
Problema comum 4: Model Max Seq Len
Os erros de comprimento máximo da sequência do modelo ocorrem quando o comprimento máximo da sequência do modelo (4096) é superior ao número máximo de tokens que podem ser armazenados na cache KV (2256).
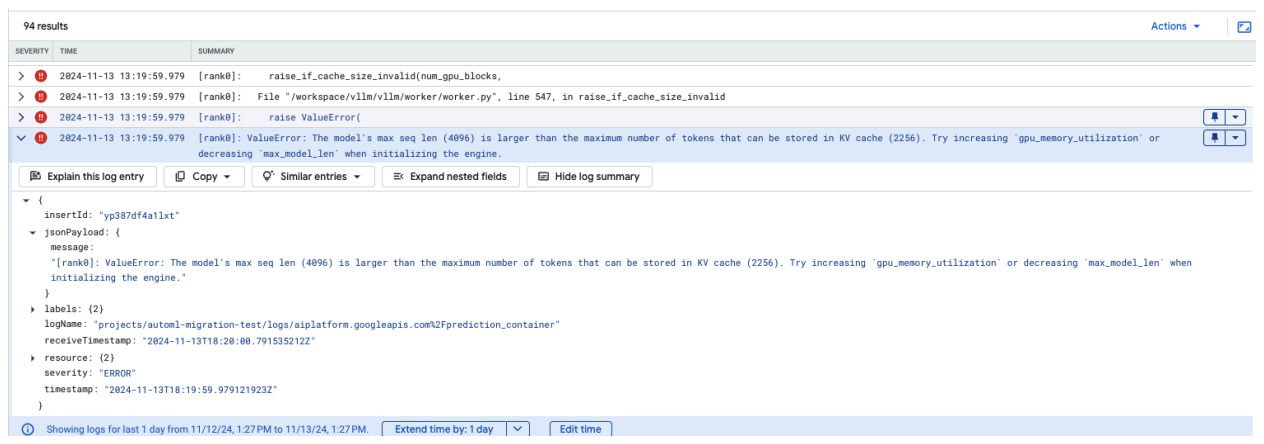 Figura 12: comprimento da sequência máximo demasiado grande
Figura 12: comprimento da sequência máximo demasiado grande
ValueError: O comprimento máximo da sequência do modelo (4096) é superior ao número máximo de tokens que podem ser armazenados na cache KV (2256). Experimente aumentar gpu_memory_utilization ou diminuir max_model_len ao inicializar o motor.
Para resolver este problema, defina max_model_len como 2048, que é inferior a 2256. Outra resolução para este problema é usar mais GPUs ou GPUs maiores. Se optar por usar mais GPUs, tem de definir o parâmetro tensor-parallel-size adequadamente.
Notas de lançamento do contentor vLLM do Model Garden
Lançamentos principais
vLLM padrão
Data de lançamento |
Arquitetura |
Versão do vLLM |
URI do contentor |
|---|---|---|---|
| 17 de julho de 2025 | ARM |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250717_0916_arm_RC01 |
| 10 de julho de 2025 | x86 |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250710_0916_RC01 |
| 20 de junho de 2025 | x86 |
Após a versão v0.9.1, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250620_0916_RC01 |
| 11 de junho de 2025 | x86 |
v0.9.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250611_0916_RC01 |
| 2 de junho de 2025 | x86 |
v0.9.0 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250601_0916_RC01 |
| 6 de maio de 2025 | x86 |
v0.8.5.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250506_0916_RC01 |
| Apr 29, 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250429_0916_RC01, 20250430_0916_RC00_maas |
| 17 de abril de 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250417_0916_RC01 |
| 10 de abril de 2025 | x86 |
A partir da v0.8.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250410_0917_RC01 |
| 7 de abril de 2025 | x86 |
v0.8.3 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250407_0917_RC01, 20250407_0917_RC0120250429_0916_RC00_maas |
| 7 de abril de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250404_0916_RC01 |
| 5 de abril de 2025 | x86 |
Após a v0.8.2, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250405_1205_RC01 |
| 31 de março de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250401_0916_RC01 |
| 26 de março de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250327_0916_RC01 |
| 23 de março de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250324_0916_RC01 |
| 21 de março de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250321_0916_RC01 |
| 11 de março de 2025 | x86 |
Após a v0.7.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250312_0916_RC01 |
| 3 de março de 2025 | x86 |
v0.7.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250304_0916_RC01 |
| 14 de janeiro de 2025 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250114_0916_RC00_maas |
| 2 de dez. 2024 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241202_0916_RC00_maas |
| 12 de novembro de 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241112_0916_RC00_maas |
| 16 de outubro de 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241016_0916_RC00_maas |
vLLM otimizado
Data de lançamento |
Arquitetura |
URI do contentor |
|---|---|---|
| 21 de janeiro de 2025 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20250121_0835_RC00 |
| 29 de out. de 2024 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20241029_0835_RC00 |
Lançamentos adicionais
Pode encontrar a lista completa de lançamentos de contentores vLLM padrão do VMG na página do Artifact Registry.
As versões da vLLM-TPU em estado experimental estão etiquetadas com <yyyymmdd_hhmm_tpu_experimental_RC00>.