O recurso de execução de código da API Gemini permite que o modelo gere e execute código em Python e aprenda de forma iterativa com os resultados até chegar a uma saída final. Use esse recurso para criar aplicativos que usam o raciocínio baseado em código e que produzem saídas de texto. Por exemplo, é possível usar a execução de código em um aplicativo que resolve equações ou processa textos.
A API Gemini inclui a execução de código como uma ferramenta, semelhante à chamada de função. Depois de adicionar a execução de código como uma ferramenta, o modelo decide quando usá-la.
O ambiente de execução de código inclui as seguintes bibliotecas. Não é possível instalar suas próprias bibliotecas.
- Altair
- Xadrez
- Cv2
- Matplotlib
- Mpmath (link em inglês)
- NumPy
- Pandas
- Pdfminer
- Reportlab
- Seaborn (em inglês)
- Sklearn
- Statsmodels (em inglês)
- Striprtf
- SymPy
- Tabulate (em inglês)
Modelos compatíveis
Os modelos a seguir oferecem suporte à execução de código:
- Gemini 2.5 Flash (pré-lançamento)
- Gemini 2.5 Flash-Lite (Pré-lançamento)
- Gemini 2.5 Flash-Lite
- Gemini 2.0 Flash com API Live (pré-lançamento)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
Começar a execução de código
Esta seção pressupõe que você concluiu as etapas de configuração mostradas no Guia de início rápido da API Gemini.
Ativar a execução de código no modelo
Você pode ativar a execução básica de código, conforme mostrado aqui:
Python
Instalar
pip install --upgrade google-genai
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA generativa com a Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Saiba como instalar ou atualizar o Go.
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA generativa com a Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
Instalar
npm install @google/genai
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA generativa com a Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Saiba como instalar ou atualizar o Java.
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA generativa com a Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
GENERATE_RESPONSE_METHOD: o tipo de resposta que você quer que o modelo gere. Escolha um método que gere como você quer que a resposta do modelo seja retornada:streamGenerateContent: a resposta é transmitida conforme é gerada para reduzir a percepção de latência para o público humano.generateContent: a resposta será retornada depois de ser totalmente gerada.
LOCATION: a região para processar a solicitação. As opções disponíveis incluem:Clicar para abrir uma lista parcial das regiões disponíveis
us-central1us-west4northamerica-northeast1us-east4us-west1asia-northeast3asia-southeast1asia-northeast1
PROJECT_ID: o ID do projeto.MODEL_ID: o ID do modelo que você quer usar.ROLE: o papel em uma conversa associada ao conteúdo. É necessário especificar um papel mesmo em casos de uso de turno único. Os valores aceitáveis são os seguintes:USER: especifica o conteúdo que é enviado por você.MODEL: especifica a resposta do modelo.
TEXT
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo chamado request.json.
Execute o comando a seguir no terminal para criar ou substituir
esse arquivo no diretório atual:
cat > request.json << 'EOF'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
EOFDepois execute o comando a seguir para enviar a solicitação REST:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD"
PowerShell
Salve o corpo da solicitação em um arquivo chamado request.json.
Execute o comando a seguir no terminal para criar ou substituir
esse arquivo no diretório atual:
@'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
'@ | Out-File -FilePath request.json -Encoding utf8Depois execute o comando a seguir para enviar a solicitação REST:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD" | Select-Object -Expand Content
Você receberá uma resposta JSON semelhante a seguinte.
Usar a execução de código na conversa
Você também pode usar a execução de código como parte de uma conversa.
REST
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://aiplatform.googleapis.com/v1/projects/test-project/locations/global/publishers/google/models/gemini-2.0-flash-001:generateContent -d \
$'{
"tools": [{'code_execution': {}}],
"contents": [
{
"role": "user",
"parts": {
"text": "Can you print \"Hello world!\"?"
}
},
{
"role": "model",
"parts": [
{
"text": ""
},
{
"executable_code": {
"language": "PYTHON",
"code": "\nprint(\"hello world!\")\n"
}
},
{
"code_execution_result": {
"outcome": "OUTCOME_OK",
"output": "hello world!\n"
}
},
{
"text": "I have printed \"hello world!\" using the provided python code block. \n"
}
],
},
{
"role": "user",
"parts": {
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}
}
]
}'
Execução de código x chamada de função
A execução de código e a chamada de função são recursos semelhantes:
- A execução de código permite que o modelo execute código no back-end da API em um ambiente fixo e isolado.
- Com a chamada de função, é possível executar as funções solicitadas pelo modelo em qualquer ambiente.
Em geral, prefira usar a execução de código se ela puder lidar com seu caso de uso. A execução de código é mais simples de usar (basta ativar) e é resolvida em uma
única solicitação GenerateContent. A chamada de função faz uma solicitação GenerateContent adicional para enviar de volta a saída de cada chamada de função.
Na maioria dos casos, use a chamada de função se você tiver funções próprias que quer executar localmente e a execução de código se quiser que a API escreva e execute o código Python para você e retorne o resultado.
Faturamento
Não há cobrança extra para ativar a execução de código na API Gemini. Você vai receber cobranças na taxa atual de tokens de entrada e saída com base no modelo do Gemini que estiver usando.
Confira outras informações importantes sobre o faturamento da execução de código:
- Você só recebe uma cobrança pelos tokens de entrada transmitidos ao modelo e pelos tokens de entrada intermediários gerados pelo uso da ferramenta de execução de código.
- Você recebe uma cobrança pelos tokens de saída finais retornados na resposta da API.
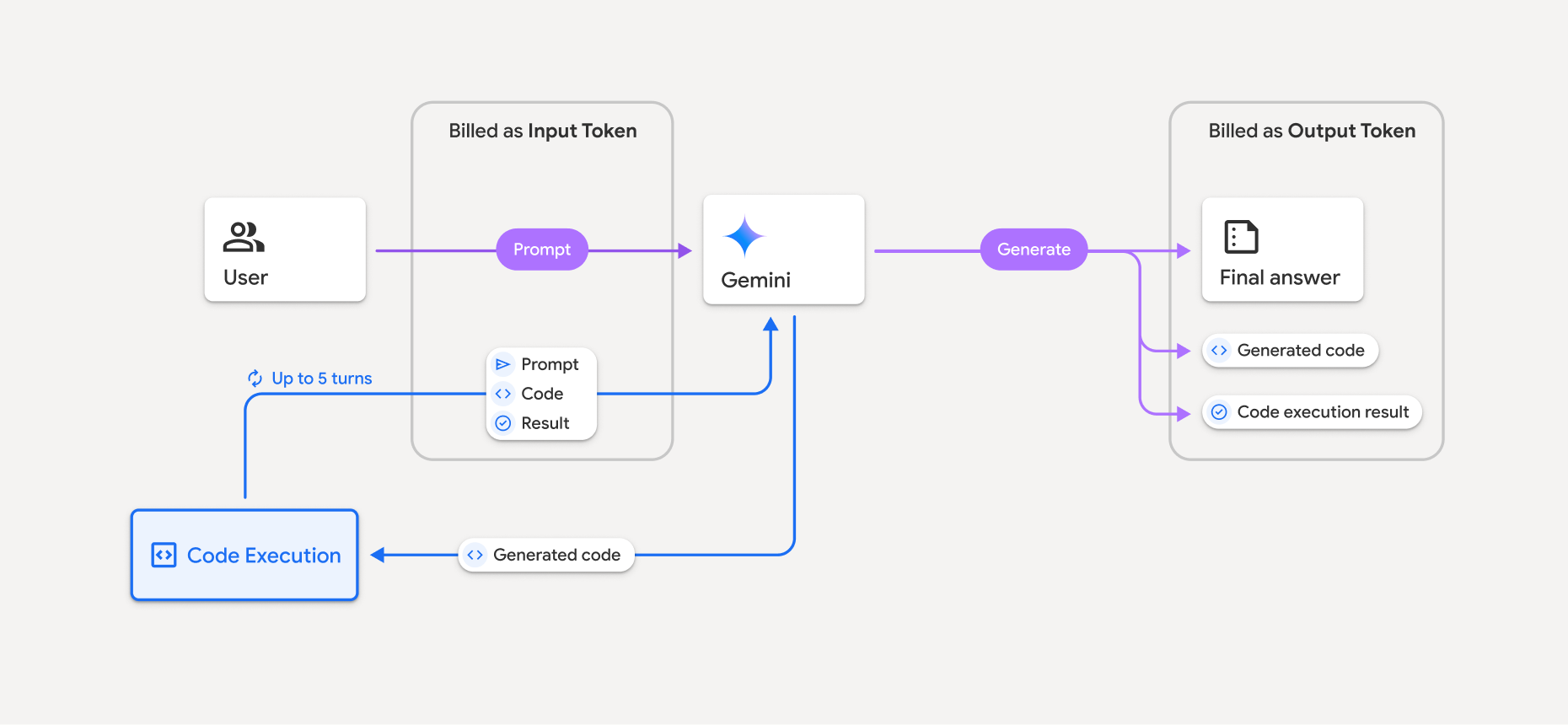
- Você recebe cobranças na taxa atual de tokens de entrada e saída com base no modelo do Gemini que está usando.
- Se o Gemini usar a execução de código ao gerar sua resposta, o comando original, o código gerado e o resultado do código executado serão rotulados como tokens intermediários e faturados como tokens de entrada.
- Em seguida, o Gemini gera um resumo e retorna o código gerado, o resultado do código executado e o resumo final. Eles são cobrados como tokens de saída.
- A API Gemini inclui uma contagem intermediária de tokens na resposta da API para que você possa acompanhar tokens de entrada extras além daqueles transmitidos no comando inicial.
O código gerado pode incluir texto e saídas multimodais, como imagens.
Limitações
- O modelo só pode gerar e executar código. Não é possível retornar outros artefatos, como arquivos de mídia.
- A ferramenta de execução de código não é compatível com URIs de arquivo como entrada/saída. No entanto, a ferramenta de execução de código aceita entrada de arquivo e saída de gráfico como bytes inline. Com esses recursos de entrada e saída, é possível fazer upload de arquivos CSV e de texto, fazer perguntas sobre eles e gerar gráficos do Matplotlib como parte do resultado da execução do código.
Os tipos MIME compatíveis com bytes em linha são
.cpp,.csv,.java,.jpeg,.js,.png,.py,.tse.xml. - A execução do código pode durar no máximo 30 segundos antes de atingir o tempo limite.
- Em alguns casos, ativar a execução de código pode levar a regressões em outras áreas da saída do modelo (por exemplo, escrever uma história).