本页面介绍了在使用 Gen AI Evaluation Service 运行模型评估后,如何查看和解读模型评估结果。
查看评估结果
借助 Gen AI Evaluation Service,您可以直接在开发环境中(例如 Colab 或 Jupyter 笔记本)直观呈现评估结果。.show() 方法适用于 EvaluationDataset 和 EvaluationResult 对象,可呈现交互式 HTML 报告以进行分析。
直观呈现数据集中生成的评分准则
如果您运行 client.evals.generate_rubrics(),生成的 EvaluationDataset 对象会包含 rubric_groups 列。您可以直观呈现此数据集,以便在运行评估之前检查为每个提示生成的评分准则。
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
系统会显示一个交互式表,其中包含每个提示以及为其生成的关联评分准则(嵌套在 rubric_groups 列中):

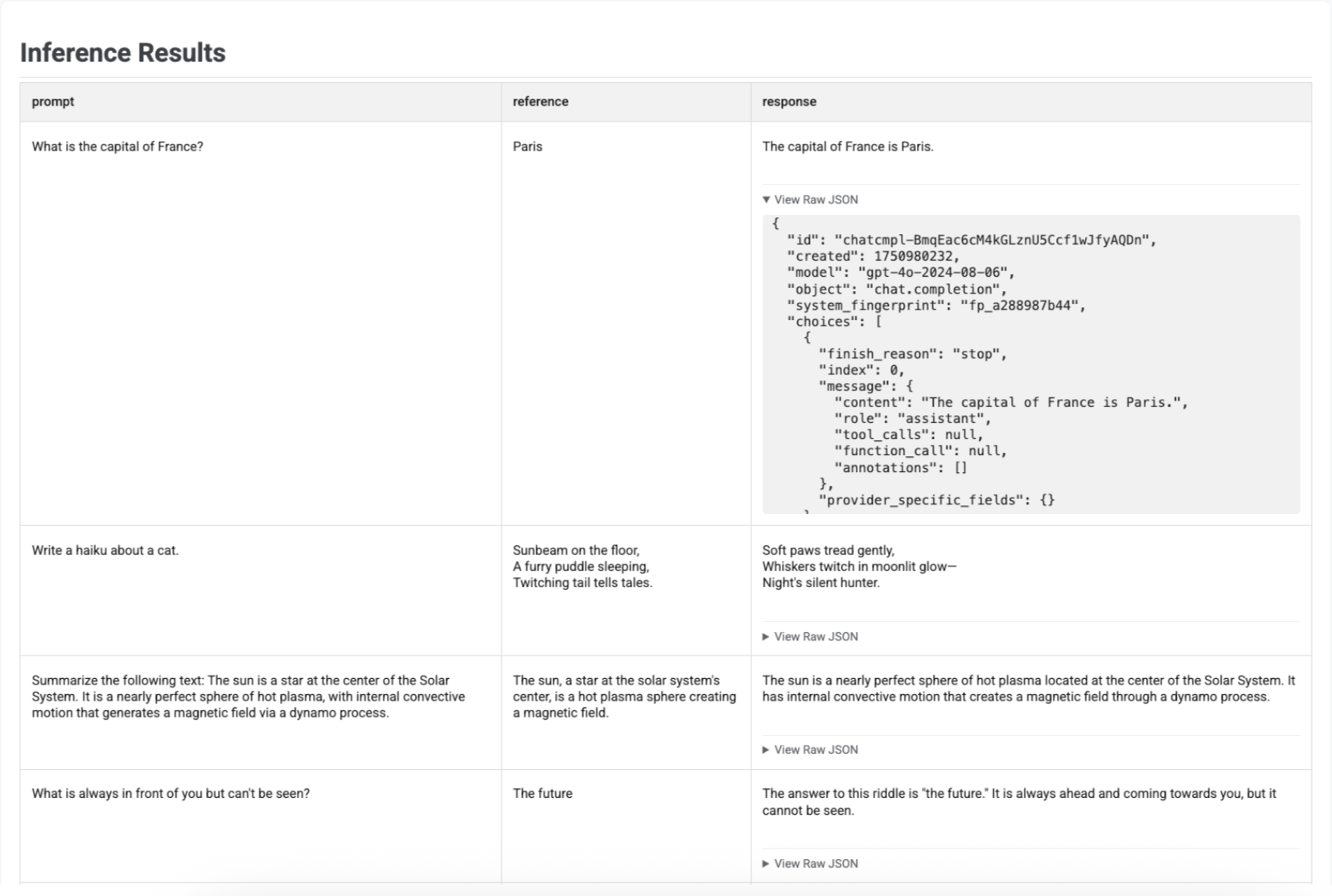
直观呈现推理结果
使用 run_inference() 生成回答后,您可以对生成的 EvaluationDataset 对象调用 .show(),以检查模型的输出以及原始提示和参考内容。这可用于在运行完整评估之前快速检查质量:
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
系统会显示一个表,其中包含每个提示、相应的参考内容(如果提供)以及新生成的回答:
直观呈现评估报告
当您对 EvaluationResult 对象调用 .show() 时,系统会显示一个报告,其中包含两个主要部分:
摘要指标:所有指标的汇总视图,其中显示整个数据集的平均得分和标准差。
详细结果:逐个用例的细分结果,可让您检查提示、参考内容、候选回答以及每个指标的具体得分和说明。
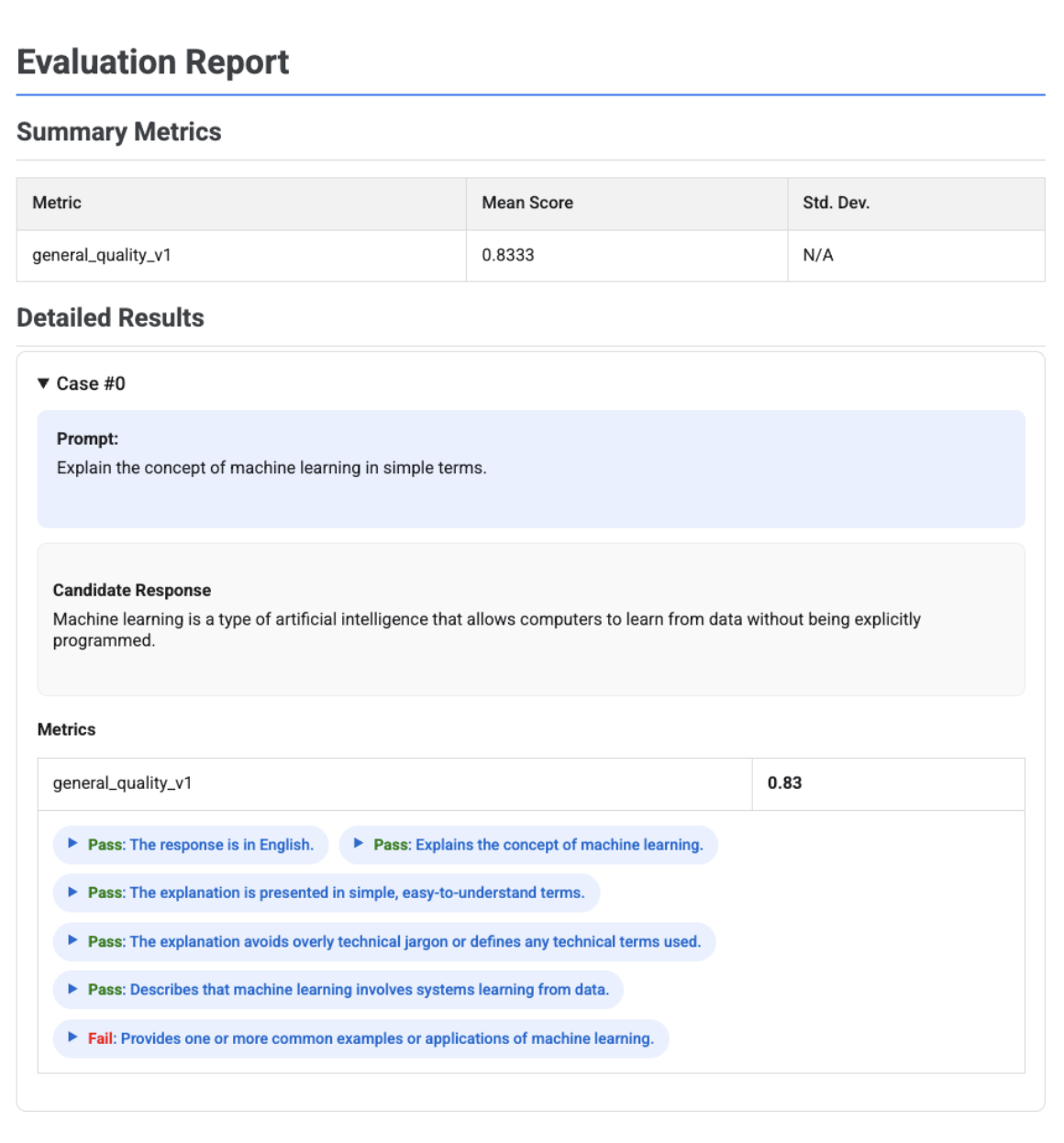
单候选项评估报告
对于单个模型评估,报告会详细说明每个指标的得分:
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()

对于所有报告,您都可以展开查看原始 JSON 部分,以检查任何结构化格式(例如 Gemini 或 OpenAI Chat Completion API 格式)的数据。
基于自适应评分准则的评估报告(含判定结果)
使用基于自适应评分准则的指标时,结果会包含应用于回答的每个评分准则的通过或未通过判定结果以及相应推理。
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
可视化图表会显示每个评分准则、其判定结果(通过或未通过)以及推理,这些信息嵌套在每个用例的指标结果中。对于每个特定的评分准则判定结果,您可以展开相应卡片以显示原始 JSON 载荷。此 JSON 载荷包含其他详细信息,例如完整评分准则说明、评分准则类型、重要性以及判定结果背后的详细推理。
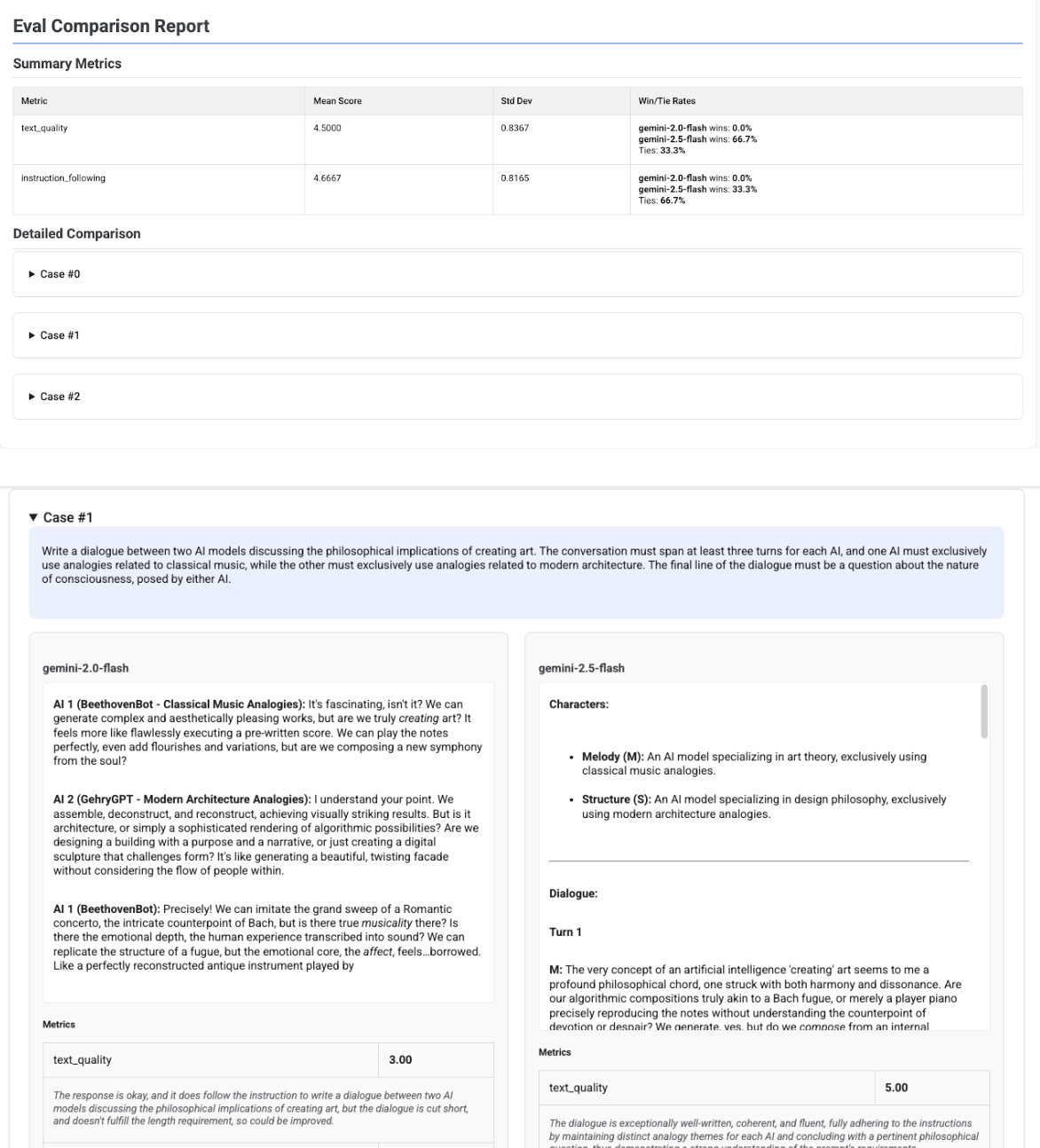
多候选项比较报告
报告的格式会根据您是评估单个候选项还是比较多个候选项而进行调整。对于多候选项评估,报告会提供并排视图,并在摘要表中包含胜率或平局率计算结果。
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()