このページでは、Gen AI Evaluation Service を使用してモデル評価を実行した後に、モデルの評価結果を表示して解釈する方法について説明します。
評価の結果を表示する
Gen AI Evaluation Service を使用すると、Colab や Jupyter ノートブックなどの開発環境内で評価結果を直接可視化できます。EvaluationDataset オブジェクトと EvaluationResult オブジェクトの両方で使用できる .show() メソッドは、分析用のインタラクティブな HTML レポートをレンダリングします。
生成されたルーブリックをデータセットで可視化する
client.evals.generate_rubrics() を実行すると、結果の EvaluationDataset オブジェクトに rubric_groups 列が含まれます。このデータセットを可視化して、評価を実行する前に各プロンプト用に生成されたルーブリックを検査できます。
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
インタラクティブな表が表示され、各プロンプトとそれに関連付けられたルーブリックが rubric_groups 列内にネストされます。

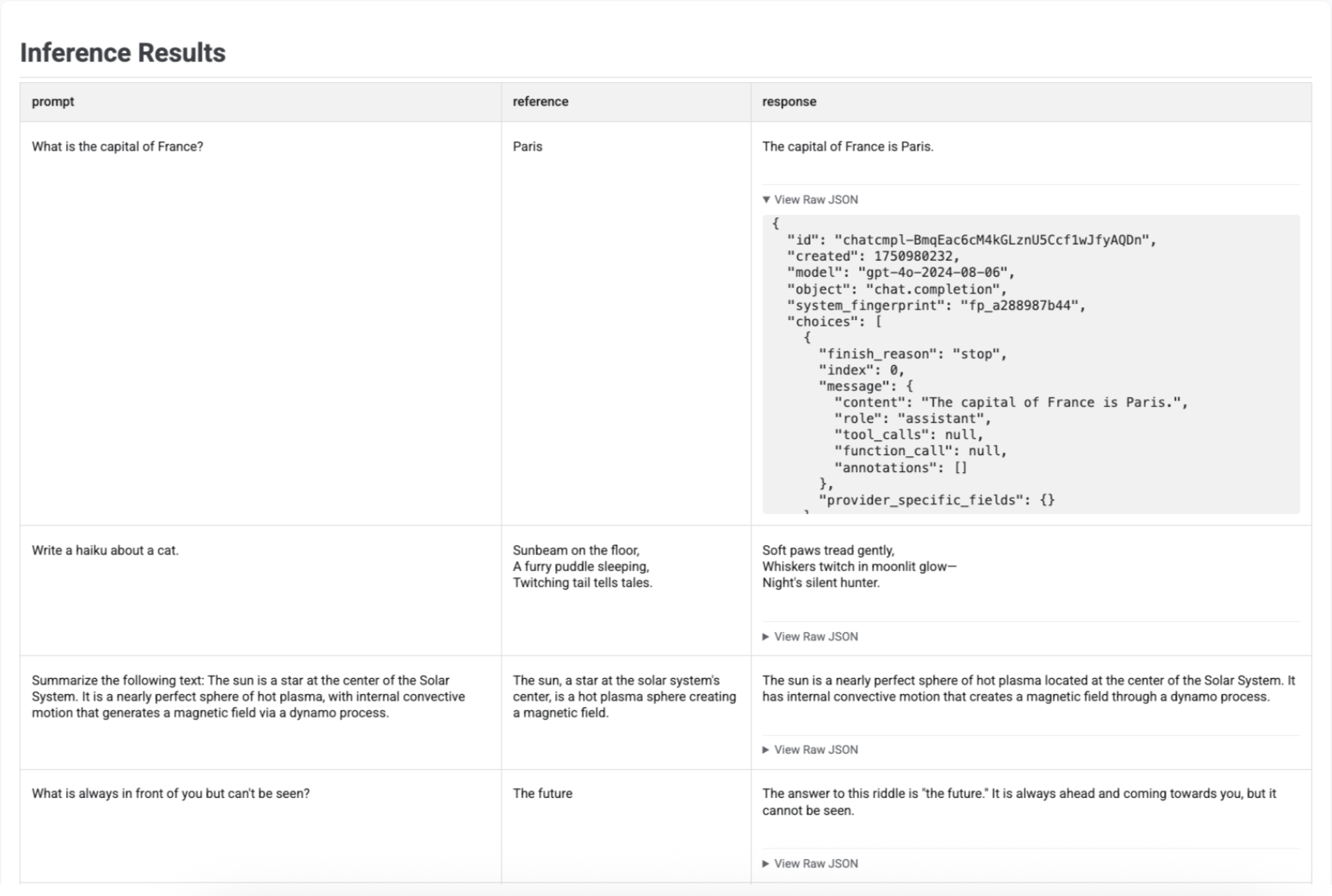
推論結果を可視化する
run_inference() でレスポンスを生成したら、結果の EvaluationDataset オブジェクトで .show() を呼び出して、元のプロンプトとリファレンスとともにモデルの出力を検査できます。これは、完全な評価を実行する前に品質を簡単にチェックする場合に便利です。
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
テーブルには、各プロンプト、対応するリファレンス(指定されている場合)、新しく生成されたレスポンスが表示されます。
評価レポートを可視化する
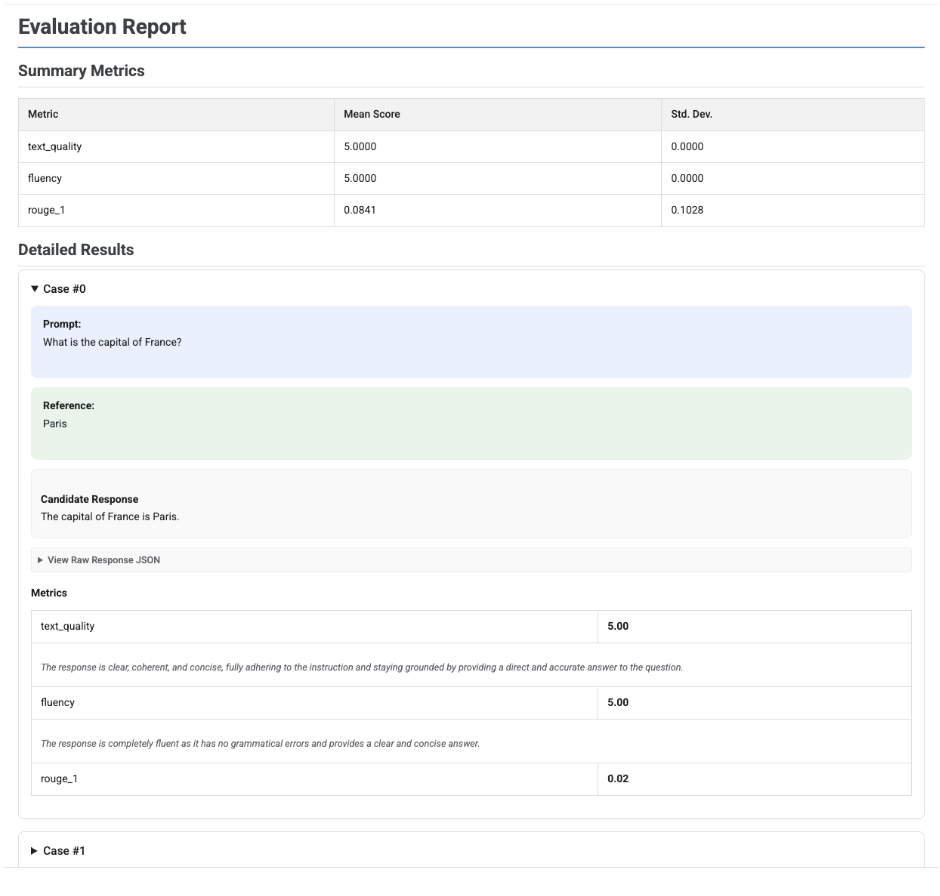
EvaluationResult オブジェクトで .show() を呼び出すと、次の 2 つの主要セクションを含むレポートが表示されます。
概要指標: すべての指標の集計ビュー。データセット全体の平均スコアと標準偏差が表示されます。
詳細な結果: ケースごとの内訳。プロンプト、参照、候補レスポンス、各指標の特定のスコアと説明を確認できます。
単一の候補者の評価レポート
単一のモデル評価の場合、レポートには各指標のスコアの詳細が表示されます。
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()
すべてのレポートで、[View Raw JSON] セクションを開いて、Gemini や OpenAI Chat Completion API 形式などの構造化された形式のデータを検査できます。
判定を含む適応型ルーブリック ベースの評価レポート
適応型ルーブリック ベースの指標を使用すると、結果には、レスポンスに適用された各ルーブリックの合格または不合格の判定と理由が含まれます。
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
可視化には、各ケースの指標結果内にネストされた各ルーブリック、その判定(合格または不合格)、理由が表示されます。特定のルーブリックの判定ごとに、カードを展開して未加工の JSON ペイロードを表示できます。この JSON ペイロードには、ルーブリックの完全な説明、ルーブリックのタイプ、重要度、判定の背後にある詳細な理由などの追加の詳細が含まれています。

複数候補の比較レポート
レポートの形式は、1 人の候補者を評価するか、複数の候補者を比較するかによって異なります。複数候補の評価の場合、レポートには並列ビューが表示され、概要表に勝率または引き分け率の計算が含まれます。
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()
