本頁說明如何使用 Gen AI Evaluation Service 執行模型評估後,查看及解讀模型評估結果。
查看評估結果
透過 Gen AI 評估服務,您可以在開發環境 (例如 Colab 或 Jupyter 筆記本) 中直接查看評估結果。.show() 方法適用於 EvaluationDataset 和 EvaluationResult 物件,可轉譯用於分析的互動式 HTML 報表。
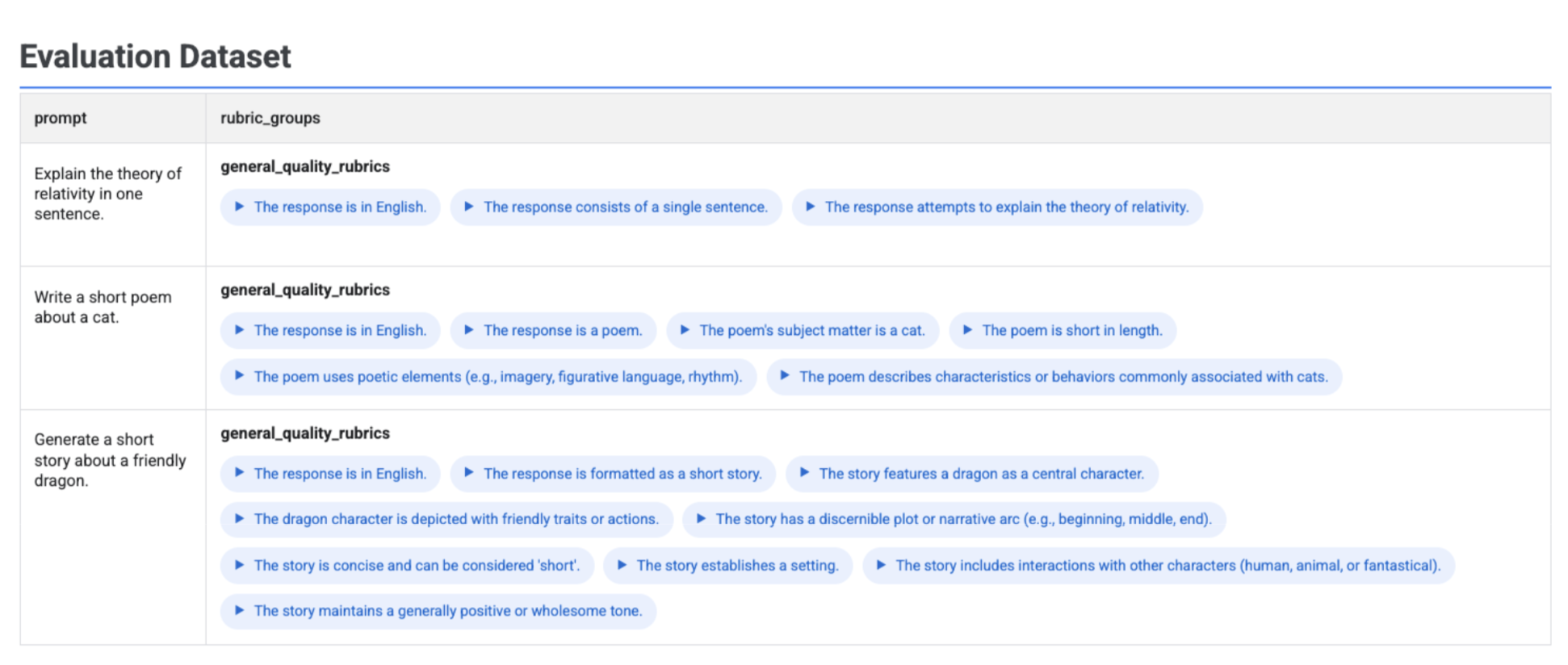
在資料集中以視覺化方式呈現產生的評量表
如果您執行 client.evals.generate_rubrics(),產生的 EvaluationDataset 物件會包含 rubric_groups 資料欄。您可以將這個資料集視覺化,在執行評估前檢查每個提示產生的評量表。
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
互動式表格會顯示每個提示和相關評量表,並巢狀內嵌於 rubric_groups 欄中:
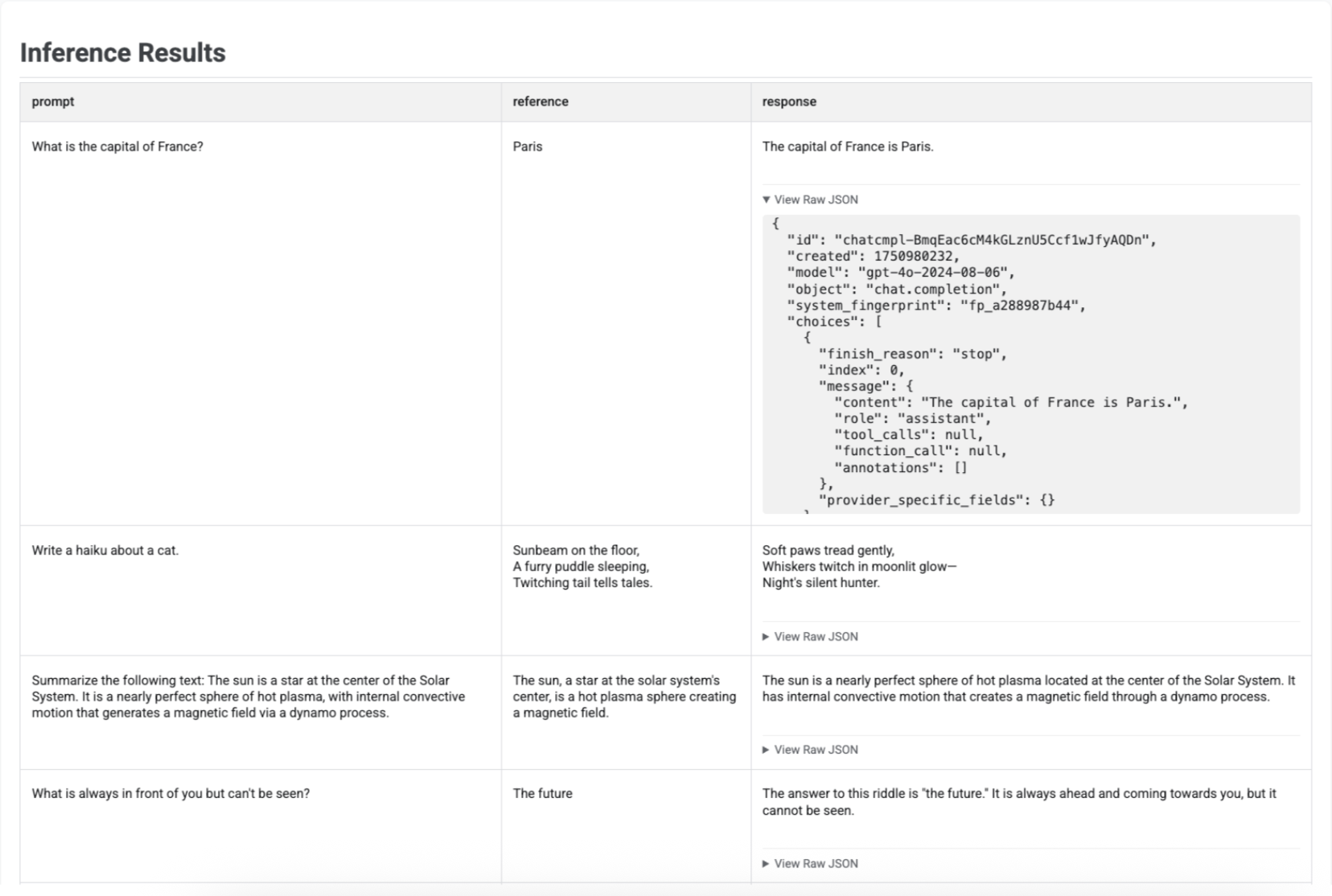
以圖表呈現推論結果
使用 run_inference() 生成回覆後,您可以對產生的 EvaluationDataset 物件呼叫 .show(),檢查模型輸出內容以及原始提示和參照。這項功能有助於在執行完整評估前,快速檢查品質:
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
表格會顯示每個提示、對應的參照 (如有) 和新生成的回覆:
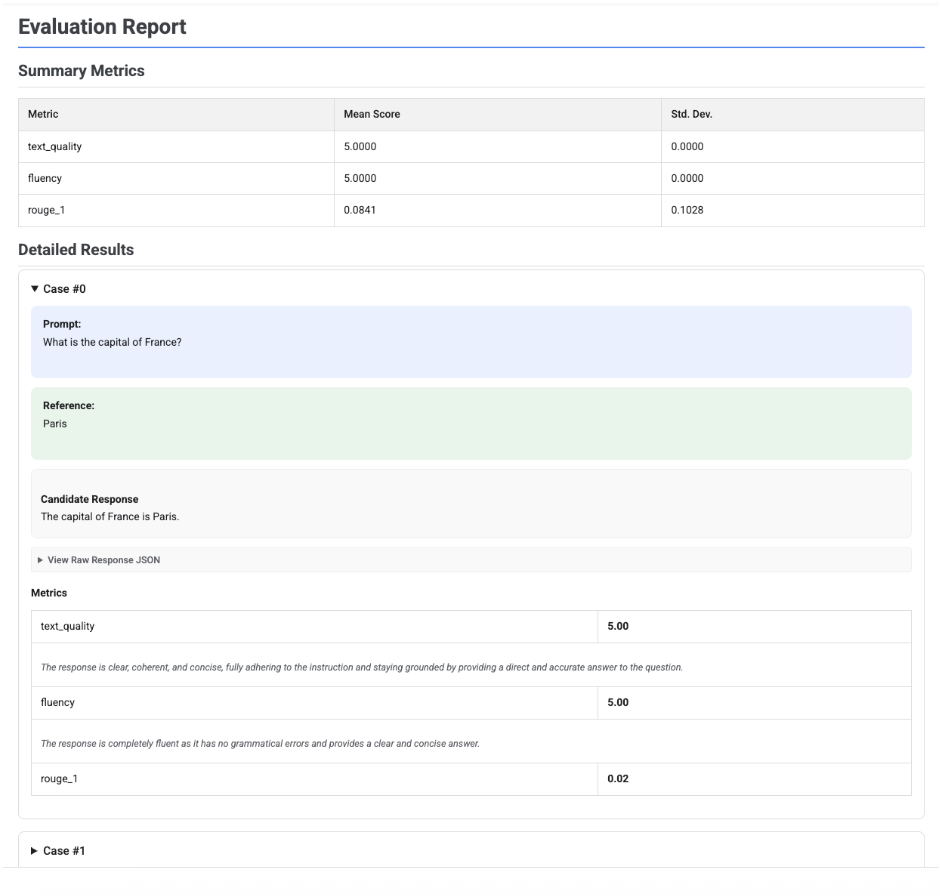
評估報告的視覺化呈現
在 EvaluationResult 物件上呼叫 .show() 時,系統會顯示報表,其中包含兩個主要部分:
摘要指標:所有指標的匯總檢視畫面,顯示整個資料集的平均分數和標準差。
詳細結果:逐一列出結果,方便您檢查提示、參考資料、候選回應,以及各項指標的具體分數和說明。
單一應徵者評估報告
如果是單一模型評估,報告會詳細列出各項指標的分數:
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()
在所有報表中,您都可以展開「查看原始 JSON」部分,檢查任何結構化格式的資料,例如 Gemini 或 OpenAI Chat Completion API 格式。
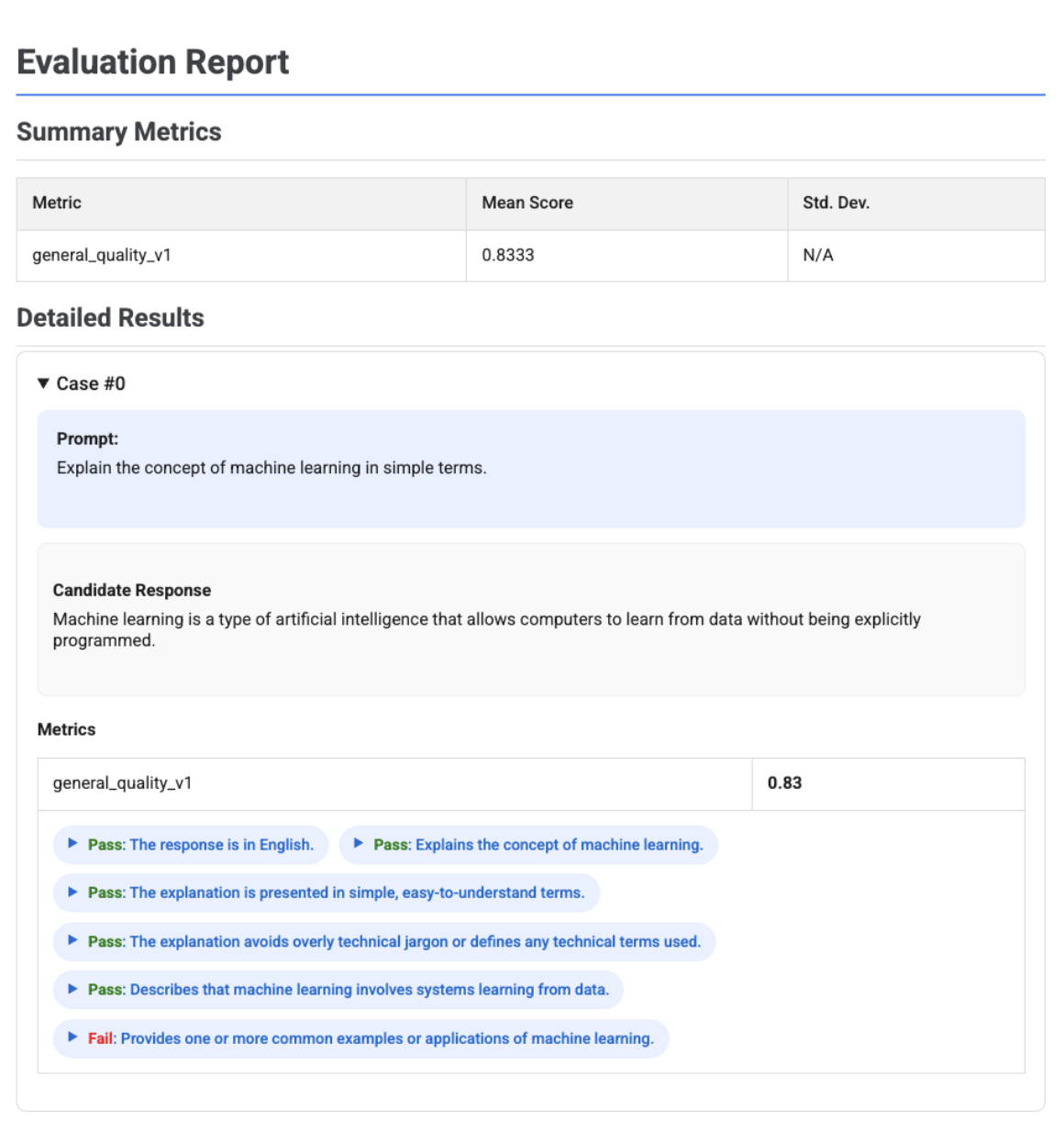
根據評量表自動調整的評估報告,內含評估結果
使用以適應性評量表為準的指標時,結果會包含每個套用至回應的評量表,以及通過或未通過的判定結果和原因。
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
視覺化內容會顯示每個評量表、評量結果 (通過或未通過) 和理由,並在每個案例的指標結果中巢狀顯示。您可以展開每張資訊卡,查看各項評量結果的原始 JSON 酬載。這個 JSON 酬載包含其他詳細資料,例如完整評量表說明、評量表類型、重要性,以及判決背後的詳細原因。
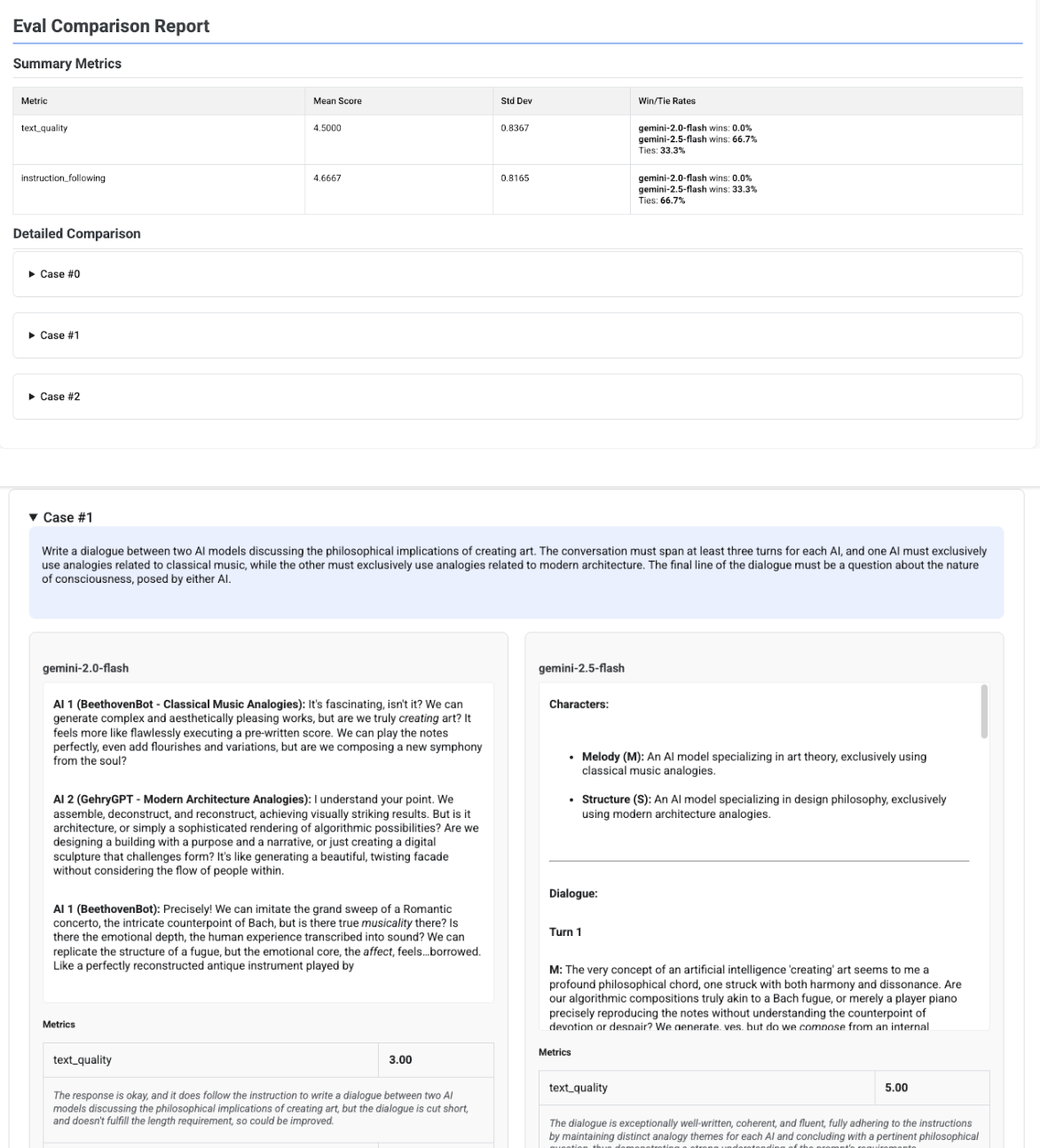
多位候選人比較報表
報表格式會根據您評估單一候選人或比較多位候選人而有所不同。如果是多位候選人的評估,報表會提供並列檢視畫面,並在摘要表格中列出勝率或平手率計算結果。
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()