GenAI Evaluation Service는 생성형 AI 모델을 객관적이고 데이터 기반으로 평가할 수 있는 엔터프라이즈급 도구를 제공합니다. 이 서비스는 모델 마이그레이션, 프롬프트 수정, 미세 조정과 같은 다양한 개발 작업을 지원하고 안내합니다.
Gen AI Evaluation Service 기능
Gen AI Evaluation Service의 가장 큰 특징은 각 프롬프트에 맞게 조정된 통과 또는 실패 여부를 판별할 수 있는 적응형 기준표를 사용할 수 있다는 점입니다. 평가 기준표는 소프트웨어 개발에서의 단위 테스트와 유사하며 다양한 작업에서 모델 성능을 개선하는 것을 목표로 합니다.
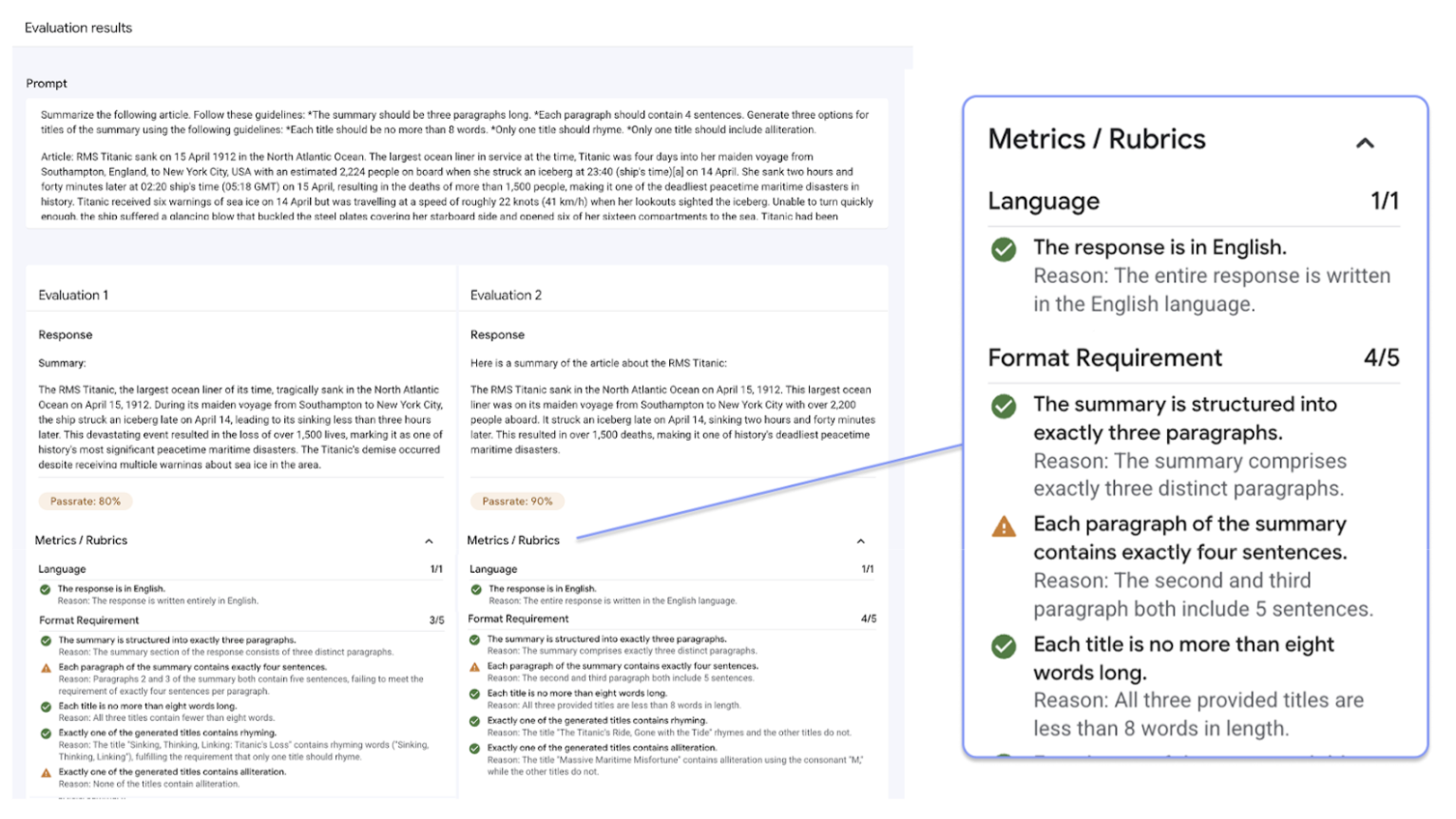
Gen AI Evaluation Service는 다음과 같은 일반적인 평가 방법을 지원합니다.
적응형 기준표(권장): 데이터 세트의 각 개별 프롬프트마다 고유한 통과 또는 실패 기준표를 생성합니다.
정적 기준표: 모든 프롬프트에 고정된 평가 기준을 적용합니다.
계산 기반 측정항목: 정답이 있을 때
ROUGE또는BLEU와 같은 결정론적 알고리즘을 사용합니다.커스텀 함수: 특수한 요구사항을 위해 Python에서 자체 평가 로직을 정의할 수 있습니다.
평가 데이터 세트 생성
다음 방법을 통해 평가 데이터 세트를 만들 수 있습니다.
완전한 프롬프트 인스턴스를 포함한 파일을 업로드하거나, 프롬프트 템플릿과 함께 변수 값이 포함된 해당 파일을 제공하여 완료된 프롬프트를 채울 수 있습니다.
프로덕션 로그에서 직접 샘플링하여 모델의 실제 사용을 평가합니다.
합성 데이터 생성을 사용해 모든 프롬프트 템플릿에 대해 대량의 일관된 예시를 생성합니다.
지원되는 인터페이스
다음 인터페이스를 사용해 평가를 정의하고 실행할 수 있습니다.
Google Cloud 콘솔: 안내식 엔드 투 엔드 워크플로를 제공하는 웹 사용자 인터페이스입니다. 데이터 세트를 관리하고, 평가를 실행하며, 대화형 보고서와 시각화를 심층적으로 탐색할 수 있습니다. 콘솔을 사용한 평가 수행을 참조하세요.
Python SDK: Colab 또는 Jupyter 환경에서 프로그래매틱 방식으로 평가를 실행하고 모델 간 비교를 나란히 렌더링할 수 있습니다. Vertex AI SDK의 생성형 AI 클라이언트를 사용한 평가 수행을 참조하세요.
사용 사례
Gen AI Evaluation Service를 사용하면 모델이 특정 작업과 고유한 기준에 대해 어떻게 성능을 발휘하는지 확인할 수 있으며, 이는 공개 리더보드나 일반 벤치마크에서는 얻을 수 없는 귀중한 인사이트를 제공합니다. 이 서비스는 다음과 같은 핵심 개발 작업을 지원합니다.
모델 마이그레이션: 모델 버전을 비교하여 동작 차이를 파악하고, 그에 따라 프롬프트와 설정을 미세 조정합니다.
최적의 모델 찾기: Google 및 서드 파티 모델을 사용자의 데이터에서 직접 비교 실행하여 성능 기준선을 설정하고, 사용 사례에 가장 적합한 모델을 식별합니다.
프롬프트 개선: 평가 결과를 활용해 맞춤설정 작업을 안내합니다. 평가를 다시 실행하면 즉각적이고 정량화 가능한 피드백을 제공하는 긴밀한 피드백 루프가 형성됩니다.
모델 미세 조정: 일관된 평가 기준을 각 실행에 적용하여 미세 조정된 모델의 품질을 평가합니다.
적응형 기준표를 활용한 평가
적응형 기준표는 대부분의 평가 사용 사례에서 권장되는 방법이며 일반적으로 평가를 시작하는 가장 빠른 방법입니다.
일반적인 LLM-as-a-judge 시스템처럼 공통된 평가 기준표 세트를 사용하는 대신, 테스트 기반 평가 프레임워크는 데이터 세트의 각 개별 프롬프트에 대해 고유한 통과 또는 실패 기준표 세트를 적응형으로 생성합니다. 이 접근 방식은 모든 평가가 해당 작업에 적합하도록 보장합니다.
각 프롬프트에 대한 평가 프로세스는 다음의 2단계 시스템을 따릅니다.
기준표 생성: 서비스가 먼저 프롬프트를 분석하고, 올바른 응답이 충족해야 하는 구체적이고 검증 가능한 테스트(기준표) 목록을 생성합니다.
기준표 검증: 모델이 응답을 생성한 후, 서비스는 각 기준표에 따라 응답을 평가하고, 명확한
Pass또는Fail판정과 그 이유를 제공합니다.

최종 결과는 모델이 통과한 기준표와 전체 통과율을 집계한 것이며, 이를 통해 문제를 진단하고 개선사항을 측정할 수 있는 실행 가능한 인사이트를 얻을 수 있습니다.
주관적이고 대략적인 점수에서 객관적이고 세분화된 테스트 결과로 전환함으로써, 평가 기반 개발 주기를 채택하고 생성형 AI 애플리케이션을 빌드하는 과정에 소프트웨어 엔지니어링의 권장사항을 적용할 수 있습니다.
기준표 평가 예시
Gen AI Evaluation Service가 기준표를 생성하고 사용하는 방법을 이해하려면 다음 예시를 살펴보세요.
사용자 프롬프트: Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
이 프롬프트에 대해 기준표 생성 단계에서는 다음과 같은 기준표가 생성될 수 있습니다.
기준표 1: 응답은 제공된 기사의 요약이어야 합니다.
기준표 2: 응답은 정확히 네 문장으로 구성되어야 합니다.
기준표 3: 응답은 낙관적인 어조를 유지해야 합니다.
모델이 다음과 같은 응답을 생성할 수 있습니다. The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
기준표 검증 단계에서 Gen AI Evaluation Service는 응답을 각 기준표에 따라 평가합니다.
기준표 1: 응답은 제공된 기사의 요약이어야 합니다.
판정:
Pass이유: 응답이 주요 내용을 정확하게 요약하고 있습니다.
기준표 2: 응답은 정확히 네 문장으로 구성되어야 합니다.
판정:
Pass이유: 응답이 네 개의 구분된 문장으로 이루어져 있습니다.
기준표 3: 응답은 낙관적인 어조를 유지해야 합니다.
판정:
Fail이유: 마지막 문장이 부정적인 내용을 도입하여 낙관적인 어조를 훼손합니다.
최종적으로 이 응답의 통과율은 66.7%입니다. 두 모델을 비교하려면, 동일한 생성된 테스트 세트를 기준으로 두 모델의 응답을 평가하고 전체 통과율을 비교할 수 있습니다.
평가 워크플로
평가를 완료하려면 일반적으로 다음 단계를 거쳐야 합니다.
평가 데이터 세트 만들기: 특정 사용 사례를 반영하는 프롬프트 인스턴스로 데이터 세트를 조합합니다. 계산 기반 측정항목을 사용할 계획이라면 기준 답변(정답)을 포함할 수 있습니다.
평가 측정항목 정의: 모델 성능을 측정하는 데 사용할 측정항목을 선택합니다. SDK는 모든 측정항목 유형을 지원하며, 콘솔은 적응형 기준표를 지원합니다.
모델 응답 생성: 데이터 세트에 대한 응답을 생성할 모델을 하나 이상 선택합니다. SDK는
LiteLLM을 통해 호출할 수 있는 모든 모델을 지원하며, 콘솔은 Google Gemini 모델을 지원합니다.평가 실행: 선택한 측정항목에 따라 각 모델의 응답을 평가하는 작업을 실행합니다.
결과 해석: 집계된 점수와 개별 응답을 검토하여 모델 성능을 분석합니다.
평가 시작하기
콘솔을 사용하여 평가를 시작할 수 있습니다.
또는, 다음 코드는 Vertex AI SDK의 생성형 AI 클라이언트를 사용해 평가를 완료하는 방법을 보여줍니다.
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Vertex AI",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
Gen AI Evaluation Service는 두 가지 SDK 인터페이스를 제공합니다.
Vertex AI SDK의 생성형 AI 클라이언트(권장)(미리보기)
from vertexai import client생성형 AI 클라이언트는 평가를 위한 최신 권장 인터페이스로, 통합된 클라이언트 클래스를 통해 액세스합니다. 이 클라이언트는 모든 평가 방법을 지원하며, 모델 비교, 노트북 내 시각화, 모델 맞춤설정을 위한 인사이트를 포함한 워크플로에 적합하도록 설계되었습니다.
Vertex AI SDK의 평가 모듈(GA)
from vertexai.evaluation import EvalTask평가 모듈은 이전 인터페이스, 기존 워크플로와의 하위 호환성을 위해 유지되고 있으나, 더 이상 적극적으로 개발되지 않습니다. 이 인터페이스는
EvalTask클래스를 통해 액세스됩니다. 이 방법은 표준 LLM-as-a-judge 및 계산 기반 측정항목을 지원하지만 적응형 기준표와 같은 최신 평가 방법은 지원하지 않습니다.
지원되는 리전
Gen AI Evaluation Service에서 지원되는 리전은 다음과 같습니다.
아이오와(
us-central1)북버지니아(
us-east4)오리건(
us-west1)네바다 주 라스베이거스(
us-west4)벨기에(
europe-west1)네덜란드(
europe-west4)프랑스 파리(
europe-west9)