O serviço de avaliação de IA gen oferece ferramentas de nível empresarial para uma avaliação objetiva e orientada por dados de modelos de IA generativa. Suporta e informa várias tarefas de desenvolvimento, como migrações de modelos, edição de comandos e ajuste fino.
Funcionalidades do serviço de avaliação de IA gen
A funcionalidade de definição do serviço de avaliação de IA gen é a capacidade de usar rubricas adaptativas, um conjunto de testes personalizados de aprovação ou reprovação para cada comando individual. As rubricas de avaliação são semelhantes aos testes unitários no desenvolvimento de software e visam melhorar o desempenho do modelo numa variedade de tarefas.
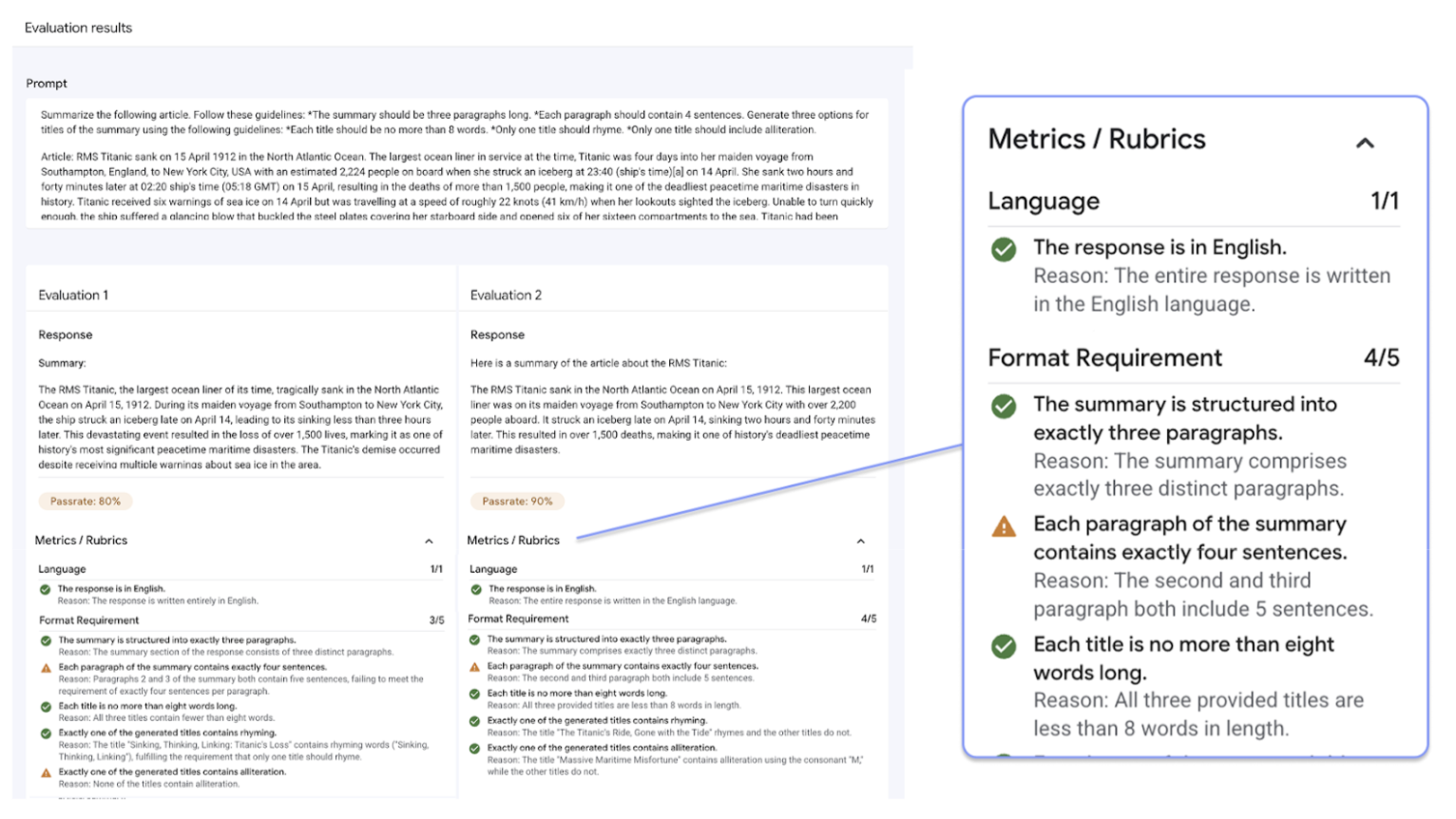
O serviço de avaliação de IA gen suporta os seguintes métodos de avaliação comuns:
Rubricas adaptativas (recomendado): gera um conjunto único de rubricas de aprovação ou reprovação para cada comando individual no seu conjunto de dados.
Rubricas estáticas: aplique um conjunto fixo de critérios de pontuação a todos os comandos.
Métricas baseadas em cálculos: use algoritmos determinísticos, como
ROUGEouBLEU, quando estiverem disponíveis factos.Funções personalizadas: defina a sua própria lógica de avaliação em Python para requisitos especializados.
Geração de conjuntos de dados de avaliação
Pode criar um conjunto de dados de avaliação através dos seguintes métodos:
Carregue um ficheiro com instâncias de comandos completas ou forneça um modelo de comando juntamente com um ficheiro correspondente de valores variáveis para preencher os comandos concluídos.
Extraia amostras diretamente dos registos de produção para avaliar a utilização real do seu modelo.
Use a geração de dados sintéticos para gerar um grande número de exemplos consistentes para qualquer modelo de comando.
Interfaces suportadas
Pode definir e executar as suas avaliações através das seguintes interfaces:
Google Cloud consola: uma interface do utilizador Web que oferece um fluxo de trabalho guiado e completo. Faça a gestão dos seus conjuntos de dados, execute avaliações e explore relatórios e visualizações interativos. Consulte o artigo Realize a avaliação através da consola.
SDK Python: execute avaliações programaticamente e renderize comparações de modelos lado a lado diretamente no seu ambiente do Colab ou Jupyter. Consulte o artigo Realize a avaliação com o cliente de IA gen. no SDK Vertex AI
Exemplos de utilização
O serviço de avaliação de IA gen permite-lhe ver o desempenho de um modelo nas suas tarefas específicas e em comparação com os seus critérios únicos, fornecendo estatísticas valiosas que não podem ser obtidas a partir de tabelas de classificação públicas e referências gerais. Isto suporta tarefas de desenvolvimento críticas, incluindo:
Migrações de modelos: compare versões de modelos para compreender as diferenças comportamentais e otimizar os seus comandos e definições em conformidade.
Encontrar o melhor modelo: execute comparações diretas de modelos da Google e de terceiros nos seus dados para estabelecer uma base de referência de desempenho e identificar o mais adequado para o seu exemplo de utilização.
Melhoria dos comandos: use os resultados da avaliação para orientar os seus esforços de personalização. A nova execução de uma avaliação cria um ciclo de feedback rigoroso, fornecendo feedback imediato e quantificável sobre as suas alterações.
Ajuste preciso do modelo: avalie a qualidade de um modelo ajustado com precisão aplicando critérios de avaliação consistentes a todas as execuções.
Avaliações com rubricas adaptáveis
As rubricas adaptativas são o método recomendado para a maioria dos exemplos de utilização de avaliação e são normalmente a forma mais rápida de começar a usar as avaliações.
Em vez de usar um conjunto geral de rubricas de classificação, como a maioria dos sistemas de LLM como juiz, a framework de avaliação orientada por testes gera adaptativamente um conjunto único de rubricas de aprovação ou reprovação para cada comando individual no seu conjunto de dados. Esta abordagem garante que cada avaliação é relevante para a tarefa específica que está a ser avaliada.
O processo de avaliação de cada comando usa um sistema de dois passos:
Geração de rubricas: o serviço analisa primeiro o seu comando e gera uma lista de testes específicos e verificáveis, as rubricas, que uma boa resposta deve cumprir.
Validação da rubrica: depois de o modelo gerar uma resposta, o serviço avalia a resposta em função de cada rubrica, fornecendo um veredito
PassouFailclaro e uma justificação.

O resultado final é uma taxa de aprovação agregada e uma discriminação detalhada das rubricas que o modelo passou, o que lhe dá estatísticas acionáveis para diagnosticar problemas e medir melhorias.
Ao passar de classificações subjetivas de alto nível para resultados de testes detalhados e objetivos, pode adotar um ciclo de desenvolvimento orientado pela avaliação e aplicar as práticas recomendadas de engenharia de software ao processo de criação de aplicações de IA generativa.
Exemplo de avaliação de rubricas
Para compreender como o serviço de avaliação de IA gen gera e usa rubricas, considere este exemplo:
Comando do utilizador: Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
Para este comando, o passo de geração de rubricas pode produzir as seguintes rubricas:
Rubrica 1: a resposta é um resumo do artigo fornecido.
Rubric 2: A resposta contém exatamente quatro frases.
Rubrica 3: a resposta mantém um tom otimista.
O seu modelo pode produzir a seguinte resposta: The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
Durante a validação da rubrica, o serviço de avaliação de IA gen avalia a resposta em função de cada rubrica:
Rubrica 1: a resposta é um resumo do artigo fornecido.
Veredicto:
PassMotivo: a resposta resume com precisão os principais pontos.
Rubric 2: A resposta contém exatamente quatro frases.
Veredicto:
PassMotivo: a resposta é composta por quatro frases distintas
Rubrica 3: a resposta mantém um tom otimista.
Veredicto:
FailMotivo: a frase final introduz um ponto negativo, que prejudica o tom otimista.
A taxa de aprovação final desta resposta é de 66,7%. Para comparar dois modelos, pode avaliar as respetivas respostas em relação a este mesmo conjunto de testes gerados e comparar as respetivas taxas de aprovação gerais.
Fluxo de trabalho de avaliação
Normalmente, a conclusão de uma avaliação requer a realização dos seguintes passos:
Crie um conjunto de dados de avaliação: reúna um conjunto de dados de instâncias de comandos que reflitam o seu exemplo de utilização específico. Pode incluir respostas de referência (dados reais) se planear usar métricas baseadas em cálculos.
Defina métricas de avaliação: escolha as métricas que quer usar para medir o desempenho do modelo. O SDK suporta todos os tipos de métricas, enquanto a consola suporta rubricas adaptativas.
Gerar respostas do modelo: selecione um ou mais modelos para gerar respostas para o seu conjunto de dados. O SDK suporta qualquer modelo chamável através de
LiteLLM, enquanto a consola suporta os modelos Google Gemini.Executar a avaliação: execute a tarefa de avaliação, que avalia as respostas de cada modelo em função das métricas selecionadas.
Interprete os resultados: reveja as classificações agregadas e as respostas individuais para analisar o desempenho do modelo.
Introdução às avaliações
Pode começar a usar as avaliações através da consola.
Em alternativa, o código seguinte mostra como concluir uma avaliação com o cliente de IA gen no SDK do Vertex AI:
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Vertex AI",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
O serviço de avaliação de IA gen oferece duas interfaces de SDK:
Cliente de IA gen no SDK Vertex AI (recomendado) (pré-visualização)
from vertexai import clientO cliente de IA gen é a interface mais recente e recomendada para avaliação, acedida através da classe de cliente unificada. Suporta todos os métodos de avaliação e foi concebido para fluxos de trabalho que incluem a comparação de modelos, a visualização no bloco de notas e estatísticas para a personalização de modelos.
Módulo de avaliação no SDK Vertex AI (GA)
from vertexai.evaluation import EvalTaskO módulo de avaliação é a interface mais antiga, mantida para retrocompatibilidade com fluxos de trabalho existentes, mas já não está em desenvolvimento ativo. O acesso é feito através da turma
EvalTask. Este método suporta o modelo de linguagem grande como juiz padrão e métricas baseadas em cálculos, mas não suporta métodos de avaliação mais recentes, como rubricas adaptativas.
Regiões suportadas
As seguintes regiões são suportadas para o serviço de avaliação de IA gen.:
Iowa (
us-central1)Virgínia do Norte (
us-east4)Oregon (
us-west1)Las Vegas, Nevada (
us-west4)Bélgica (
europe-west1)Países Baixos (
europe-west4)Paris, França (
europe-west9)