Le moteur RAG Vertex AI, un composant de la plate-forme Vertex AI, facilite la génération augmentée par récupération (RAG).
Le moteur RAG de Vertex AI est également un framework de données permettant de développer des applications de grand modèle de langage (LLM) augmentées par le contexte. L'augmentation par le contexte se produit lorsque vous appliquez un LLM à vos données. Cette approche implémente la génération augmentée par récupération (RAG).
Un problème courant avec les LLM est qu'ils ne comprennent pas les connaissances privées, c'est-à-dire les données de votre organisation. Le moteur RAG de Vertex AI vous permet d'enrichir le contexte LLM avec des informations privées supplémentaires, car le modèle peut réduire les hallucinations et répondre aux questions plus précisément.
En combinant des sources de connaissances supplémentaires avec les connaissances existantes des LLM, un meilleur contexte est fourni. Le contexte amélioré associé à la requête améliore la qualité de la réponse du LLM.
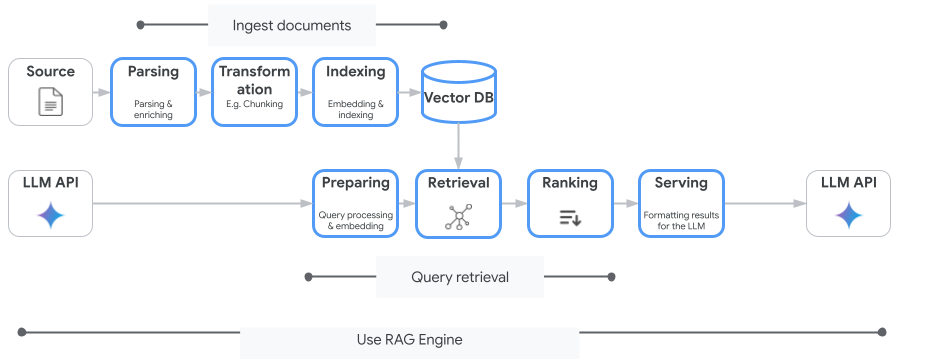
L'image suivante illustre les concepts clés pour comprendre le moteur RAG de Vertex AI.
Ces concepts sont listés dans l'ordre du processus de génération augmentée par récupération (RAG).
Ingestion de données : intégrez des données provenant de différentes sources. Par exemple, les fichiers locaux, Cloud Storage et Google Drive.
Transformation des données : conversion des données en préparation pour l'indexation. Par exemple, les données sont divisées en blocs.
Embedding (ou "plongement") : représentations numériques de mots ou de textes. Ces nombres capturent la signification sémantique et le contexte du texte. Les mots ou textes similaires ou connexes ont tendance à avoir des embeddings similaires, ce qui signifie qu'ils sont plus proches les uns des autres dans l'espace vectoriel de grande dimension.
Indexation des données : le moteur RAG Vertex AI crée un index appelé corpus.
L'index structure la base de connaissances afin qu'il soit optimisé pour la recherche. Par exemple, l'index s'apparente à une table des matières détaillée pour un immense livre de référence.
Récupération : lorsqu'un utilisateur pose une question ou fournit une requête, le composant de récupération du moteur RAG Vertex AI effectue une recherche dans sa base de connaissances afin de trouver des informations pertinentes pour la requête.
Génération : les informations récupérées deviennent le contexte ajouté à la requête utilisateur d'origine pour guider le modèle d'IA générative et lui permettre de générer des réponses factuellement ancrées et pertinentes.
Régions où le service est disponible
Le moteur RAG de Vertex AI est disponible dans les régions suivantes :
Région
Emplacement
Description
Étape de lancement
us-central1
Iowa
Les versions v1 et v1beta1 sont acceptées.
Liste d'autorisation
us-east4
Virginie
Les versions v1 et v1beta1 sont acceptées.
DG
europe-west3
Francfort, Allemagne
Les versions v1 et v1beta1 sont acceptées.
DG
europe-west4
Eemshaven, Pays-Bas
Les versions v1 et v1beta1 sont acceptées.
DG
us-central1 devient Allowlist. Si vous souhaitez tester le moteur RAG de Vertex AI, essayez d'autres régions. Si vous prévoyez d'intégrer votre trafic de production à us-central1, contactez vertex-ai-rag-engine-support@google.com.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2025/09/04 (UTC).
[[["Facile à comprendre","easyToUnderstand","thumb-up"],["J'ai pu résoudre mon problème","solvedMyProblem","thumb-up"],["Autre","otherUp","thumb-up"]],[["Difficile à comprendre","hardToUnderstand","thumb-down"],["Informations ou exemple de code incorrects","incorrectInformationOrSampleCode","thumb-down"],["Il n'y a pas l'information/les exemples dont j'ai besoin","missingTheInformationSamplesINeed","thumb-down"],["Problème de traduction","translationIssue","thumb-down"],["Autre","otherDown","thumb-down"]],["Dernière mise à jour le 2025/09/04 (UTC)."],[],[],null,["# Vertex AI RAG Engine overview\n\n| The [VPC-SC security controls](/vertex-ai/generative-ai/docs/security-controls) and\n| CMEK are supported by Vertex AI RAG Engine. Data residency and AXT security controls aren't\n| supported.\n| You must be added to the allowlist to access\n| Vertex AI RAG Engine in `us-central1`. For users\n| with existing projects, there is no impact. For users with new projects, you\n| can try other regions, or contact\n| `vertex-ai-rag-engine-support@google.com` to onboard to\n| `us-central1`.\n\nThis page describes what Vertex AI RAG Engine is and how it\nworks.\n\nOverview\n--------\n\nVertex AI RAG Engine, a component of the Vertex AI\nPlatform, facilitates Retrieval-Augmented Generation (RAG).\nVertex AI RAG Engine is also a data framework for developing\ncontext-augmented large language model (LLM) applications. Context augmentation\noccurs when you apply an LLM to your data. This implements retrieval-augmented\ngeneration (RAG).\n\nA common problem with LLMs is that they don't understand private knowledge, that\nis, your organization's data. With Vertex AI RAG Engine, you can\nenrich the LLM context with additional private information, because the model\ncan reduce hallucination and answer questions more accurately.\n\nBy combining additional knowledge sources with the existing knowledge that LLMs\nhave, a better context is provided. The improved context along with the query\nenhances the quality of the LLM's response.\n\nThe following image illustrates the key concepts to understanding\nVertex AI RAG Engine.\n\nThese concepts are listed in the order of the retrieval-augmented generation\n(RAG) process.\n\n1. **Data ingestion**: Intake data from different data sources. For example,\n local files, Cloud Storage, and Google Drive.\n\n2. [**Data transformation**](/vertex-ai/generative-ai/docs/fine-tune-rag-transformations):\n Conversion of the data in preparation for indexing. For example, data is\n split into chunks.\n\n3. [**Embedding**](/vertex-ai/generative-ai/docs/embeddings/get-text-embeddings): Numerical\n representations of words or pieces of text. These numbers capture the\n semantic meaning and context of the text. Similar or related words or text\n tend to have similar embeddings, which means they are closer together in the\n high-dimensional vector space.\n\n4. **Data indexing** : Vertex AI RAG Engine creates an index called a [corpus](/vertex-ai/generative-ai/docs/manage-your-rag-corpus#corpus-management).\n The index structures the knowledge base so it's optimized for searching. For\n example, the index is like a detailed table of contents for a massive\n reference book.\n\n5. **Retrieval**: When a user asks a question or provides a prompt, the retrieval\n component in Vertex AI RAG Engine searches through its knowledge\n base to find information that is relevant to the query.\n\n6. **Generation** : The retrieved information becomes the context added to the\n original user query as a guide for the generative AI model to generate\n factually [grounded](/vertex-ai/generative-ai/docs/grounding/overview) and relevant responses.\n\nSupported regions\n-----------------\n\nVertex AI RAG Engine is supported in the following regions:\n\n- `us-central1` is changed to `Allowlist`. If you'd like to experiment with Vertex AI RAG Engine, try other regions. If you plan to onboard your production traffic to `us-central1`, contact `vertex-ai-rag-engine-support@google.com`.\n\nSubmit feedback\n---------------\n\nTo chat with Google support, go to the [Vertex AI RAG Engine\nsupport\ngroup](https://groups.google.com/a/google.com/g/vertex-ai-rag-engine-support).\n\nTo send an email, use the email address\n`vertex-ai-rag-engine-support@google.com`.\n\nWhat's next\n-----------\n\n- To learn how to use the Vertex AI SDK to run Vertex AI RAG Engine tasks, see [RAG quickstart for\n Python](/vertex-ai/generative-ai/docs/rag-quickstart).\n- To learn about grounding, see [Grounding\n overview](/vertex-ai/generative-ai/docs/grounding/overview).\n- To learn more about the responses from RAG, see [Retrieval and Generation Output of Vertex AI RAG Engine](/vertex-ai/generative-ai/docs/model-reference/rag-output-explained).\n- To learn about the RAG architecture:\n - [Infrastructure for a RAG-capable generative AI application using Vertex AI and Vector Search](/architecture/gen-ai-rag-vertex-ai-vector-search)\n - [Infrastructure for a RAG-capable generative AI application using Vertex AI and AlloyDB for PostgreSQL](/architecture/rag-capable-gen-ai-app-using-vertex-ai)."]]