本页面介绍了 Vertex AI RAG 引擎是什么及其运作方式。
| 说明 | 控制台 |
|---|---|
| 如需了解如何使用 Vertex AI SDK 运行 Vertex AI RAG 引擎任务,请参阅 RAG Python 版快速入门。 |
概览
Vertex AI RAG 引擎是 Vertex AI Platform 的组成部分,有助于检索增强生成 (RAG)。Vertex AI RAG 引擎还是一个用于开发上下文增强型大语言模型 (LLM) 应用的数据框架。当您将 LLM 应用于数据时,上下文便会得到增强。这实现了检索增强生成 (RAG)。
LLM 的一个常见问题是,它们不理解私有知识,也就是您的组织的数据。借助 Vertex AI RAG 引擎,您可以使用更多私密信息丰富 LLM 上下文,因为该模型可以减少幻觉并更准确地回答问题。
通过将更多知识来源与 LLM 所拥有的现有知识相结合,可以提供更好的上下文。改进的上下文与查询一起可提高 LLM 的回答质量。
下图展示用于了解 Vertex AI RAG 引擎的关键概念。
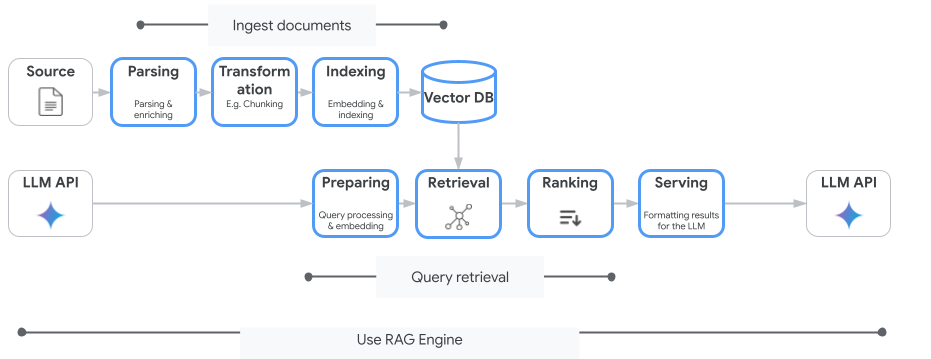
这些概念按检索增强生成 (RAG) 过程的顺序列出。
数据注入:从不同数据源注入数据。例如,本地文件、Cloud Storage 和 Google 云端硬盘。
数据转换:转换数据以准备编制索引。例如,数据会拆分为各个块。
嵌入:字词或文本片段的数值表示法。这些数字可捕获文本含义的语义和上下文。相似或相关的字词或文本往往具有类似的嵌入,这意味着它们在高维向量空间中彼此更靠近。
数据索引编制:Vertex AI RAG 引擎会创建一个称为语料库的索引。索引可对知识库进行结构化处理,以便针对搜索进行优化。例如,索引如同一本大型参考书的详细目录。
检索:当用户提问或提供提示时,Vertex AI RAG 引擎中的检索组件会搜索其知识库,以查找与查询相关的信息。
生成:检索到的信息将成为添加到原始用户查询的上下文(作为生成式 AI 模型的指南),以生成确实有依据的相关响应。
支持的区域
Vertex AI RAG 引擎在以下区域中受支持:
| 区域 | 位置 | 说明 | 发布阶段 |
|---|---|---|---|
us-central1 |
艾奥瓦 | 支持 v1 和 v1beta1 版本。 |
许可清单 |
us-east4 |
弗吉尼亚 | 支持 v1 和 v1beta1 版本。 |
GA |
europe-west3 |
德国法兰克福 | 支持 v1 和 v1beta1 版本。 |
GA |
europe-west4 |
荷兰埃姆斯哈文 | 支持 v1 和 v1beta1 版本。 |
GA |
us-central1变为Allowlist。 如果您想试用 Vertex AI RAG 引擎,请尝试其他区域。如果您计划将生产流量迁移到us-central1,请与vertex-ai-rag-engine-support@google.com联系。
删除 Vertex AI RAG 引擎
以下代码示例演示了如何针对 Google Cloud 控制台、Python 和 REST 删除 Vertex AI RAG 引擎:
提交反馈
如需与 Google 支持团队聊天,请前往 Vertex AI RAG 引擎支持群组。
如需发送邮件,请使用邮箱 vertex-ai-rag-engine-support@google.com。
后续步骤
- 如需了解如何使用 Vertex AI SDK 运行 Vertex AI RAG 引擎任务,请参阅 RAG Python 版快速入门。
- 如需了解接地,请参阅接地概览。
- 如需详细了解 RAG 的回答,请参阅 Vertex AI RAG Engine 的检索和生成输出。
- 如需了解 RAG 架构,请参阅: