Dengan Question Answering Visual (VQA), Anda dapat memberikan gambar ke model dan mengajukan pertanyaan tentang konten gambar. Sebagai jawaban atas pertanyaan Anda, Anda akan mendapatkan satu atau lebih jawaban dengan bahasa alami.
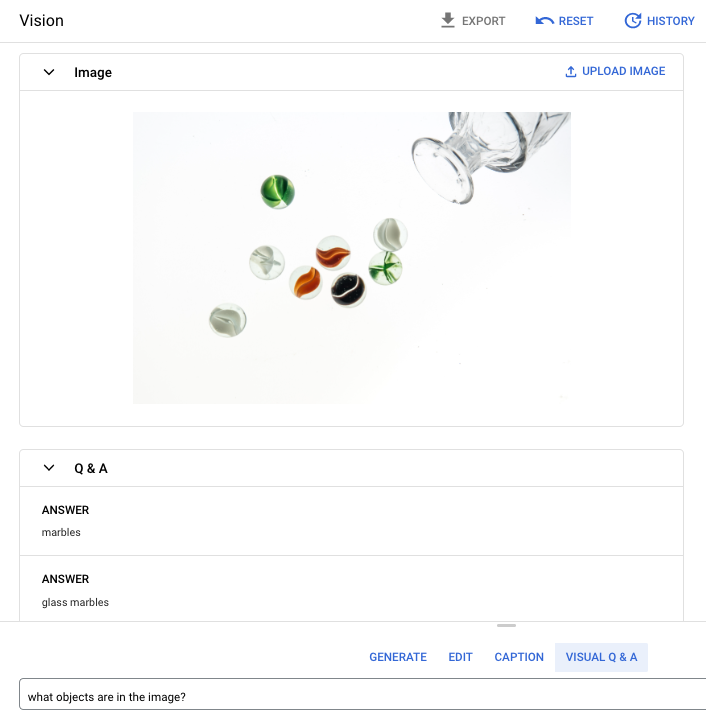
Pertanyaan perintah: Objek apa yang ada dalam gambar?
Jawaban 1: kelereng
Jawaban 2: kelereng kaca
Bahasa yang didukung
VQA tersedia dalam bahasa berikut:
- Inggris (en)
Performa dan batasan
Batasan berikut berlaku saat Anda menggunakan model ini:
| Batas | Nilai |
|---|---|
| Jumlah maksimum permintaan API (bentuk singkat) per menit per project | 500 |
| Jumlah maksimum token yang ditampilkan dalam respons (bentuk singkat) | 64 token |
| Jumlah maksimum token yang diterima dalam permintaan (khusus bentuk singkat VQA) | 80 token |
Estimasi latensi layanan berikut berlaku saat Anda menggunakan model ini. Nilai ini dimaksudkan untuk ilustrasi dan bukan janji layanan:
| Latensi | Nilai |
|---|---|
| Permintaan API (bentuk singkat) | 1,5 detik |
Lokasi
Lokasi adalah region yang dapat Anda tentukan dalam permintaan untuk mengontrol tempat data disimpan dalam penyimpanan. Untuk mengetahui daftar region yang tersedia, lihat Lokasi AI Generatif di Vertex AI.
Pemfilteran keamanan Responsible AI
Model fitur Question Answering Visual (VQA) dan teks gambar tidak mendukung filter keamanan yang dapat dikonfigurasi pengguna. Namun, pemfilteran keamanan Imagen secara keseluruhan terjadi pada data berikut:
- Input pengguna
- Output model
Akibatnya, output Anda mungkin berbeda dari output contoh jika Imagen menerapkan filter keamanan ini. Perhatikan contoh berikut.
Input yang difilter
Jika input difilter, responsnya akan mirip dengan berikut ini:
{
"error": {
"code": 400,
"message": "Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.DebugInfo",
"detail": "[ORIGINAL ERROR] generic::invalid_argument: Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394 [google.rpc.error_details_ext] { message: \"Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394\" }"
}
]
}
}
Output yang difilter
Jika jumlah respons yang ditampilkan kurang dari jumlah sampel yang Anda tentukan,
artinya respons yang hilang difilter oleh Responsible AI. Misalnya,
berikut adalah respons terhadap permintaan dengan "sampleCount": 2, tetapi salah satu
respons difilter:
{
"predictions": [
"cappuccino"
]
}
Jika semua output difilter, responsnya adalah objek kosong yang mirip dengan berikut:
{}
Menggunakan VQA pada gambar (respons singkat)
Gunakan contoh berikut untuk mengajukan pertanyaan dan mendapatkan jawaban tentang gambar.
REST
Untuk mengetahui informasi selengkapnya tentang permintaan model imagetext, lihat
referensi API model imagetext.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT_ID: Google Cloud Project ID Anda.
- LOCATION: Region project Anda. Misalnya,
us-central1,europe-west2, atauasia-northeast3. Untuk mengetahui daftar region yang tersedia, lihat Lokasi AI Generatif di Vertex AI. - VQA_PROMPT: Pertanyaan tentang gambar yang jawabannya ingin Anda peroleh.
- Apa warna sepatu ini?
- Lengan jenis apa yang digunakan di kemeja ini?
- B64_IMAGE: Gambar yang akan diberi teks. Gambar harus ditentukan sebagai string byte berenkode Base64. Batas ukuran: 10 MB.
- RESPONSE_COUNT: Jumlah jawaban yang ingin Anda hasilkan. Nilai bilangan bulat yang diterima: 1-3.
Metode HTTP dan URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict
Isi JSON permintaan:
{
"instances": [
{
"prompt": "VQA_PROMPT",
"image": {
"bytesBase64Encoded": "B64_IMAGE"
}
}
],
"parameters": {
"sampleCount": RESPONSE_COUNT
}
}
Untuk mengirim permintaan Anda, pilih salah satu opsi berikut:
curl
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict"
PowerShell
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict" | Select-Object -Expand Content
"sampleCount": 2 dan "prompt": "What is this?". Tanggapannya akan menampilkan dua jawaban string prediksi.
{
"predictions": [
"cappuccino",
"coffee"
]
}
Python
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Python di panduan memulai Vertex AI menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi API Python Vertex AI.
Untuk melakukan autentikasi ke Vertex AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Dalam contoh ini, Anda menggunakan metode load_from_file untuk mereferensikan file lokal sebagai
Image dasar untuk mendapatkan informasi. Setelah menentukan image
dasar, Anda dapat menggunakan metode ask_question pada
ImageTextModel dan mencetak jawabannya.
Node.js
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Node.js di Panduan memulai Vertex AI menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi API Node.js Vertex AI.
Untuk melakukan autentikasi ke Vertex AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Dalam contoh ini, Anda memanggil metodepredict
pada
PredictionServiceClient.
Layanan ini menampilkan jawaban untuk pertanyaan yang diberikan.
Menggunakan parameter untuk VQA
Saat mendapatkan respons VQA, ada beberapa parameter yang dapat Anda tetapkan, bergantung pada kasus penggunaan Anda.
Jumlah hasil
Gunakan parameter jumlah hasil untuk membatasi jumlah respons yang ditampilkan
untuk setiap permintaan yang Anda kirim. Untuk mengetahui informasi selengkapnya, lihat referensi API model imagetext (VQA).
Nomor seed
Angka yang Anda tambahkan ke permintaan untuk membuat respons yang dihasilkan menjadi determenistik. Menambahkan
nomor seed dengan permintaan Anda adalah cara untuk memastikan bahwa Anda selalu mendapatkan prediksi
(respons) yang sama. Namun, jawaban tidak
ditampilkan dalam urutan yang sama. Untuk mengetahui informasi selengkapnya, lihat
referensi API model imagetext (VQA).
Langkah berikutnya
Baca artikel tentang Imagen dan produk AI Generatif lainnya di Vertex AI:
- Panduan developer untuk mulai menggunakan Imagen 3 di Vertex AI
- Model dan alat media generatif baru, yang dibuat dengan dan untuk kreator
- Baru di Gemini: Gem Kustom dan peningkatan pembuatan gambar dengan Imagen 3
- Google DeepMind: Imagen 3 - Model text-to-image berkualitas tertinggi kami