Mit VQA (Visual Question Answering) können Sie dem Modell ein Bild zur Verfügung stellen und eine Frage zum Inhalt des Bildes stellen. In Reaktion auf Ihre Frage erhalten Sie eine oder mehrere Antworten in natürlicher Sprache.
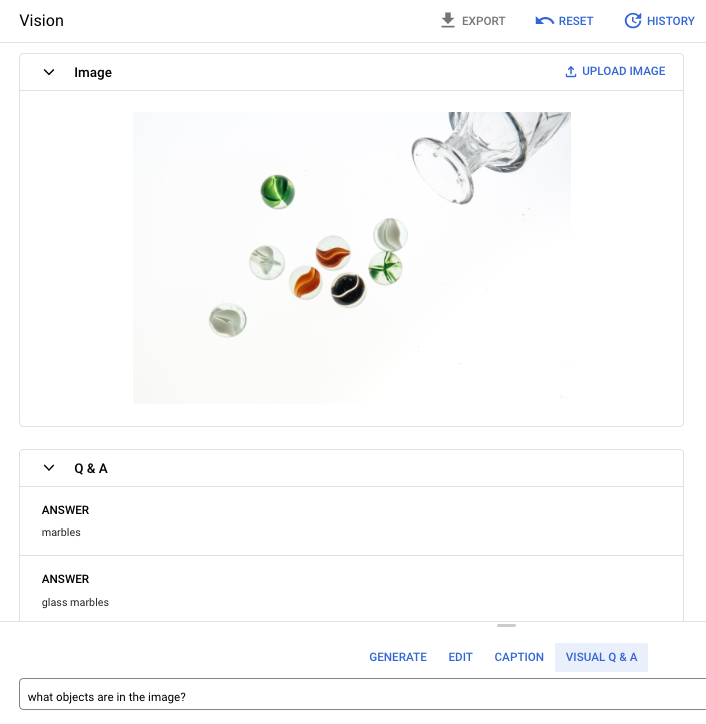
Prompt-Frage: Welche Objekte befinden sich im Bild?
Antwort 1: Murmeln
Antwort 2: Glasmurmeln
Unterstützte Sprachen
VQA ist in folgenden Sprachen verfügbar:
- Englisch (en)
Leistung und Einschränkungen
Die folgenden Limits gelten, wenn Sie das -Modell verwenden:
| Limits | Wert |
|---|---|
| Maximale Anzahl an API-Anfragen (Kurzform) pro Minute und Projekt | 500 |
| Maximale Anzahl von Tokens, die in der Antwort zurückgegeben werden (Kurzform) | 64 Tokens |
| Maximale Anzahl von Tokens, die in der Anfrage akzeptiert werden (nur VQA-Kurzform) | 80 Tokens |
Die folgenden geschätzten Dienstlatenzen gelten, wenn Sie dieses Modell verwenden. Diese Werte dienen nur zur Veranschaulichung und sind kein Versprechen für die Dienstleistung:
| Latenz | Wert |
|---|---|
| API-Anfragen (Kurzform) | 1,5 Sekunden |
Standorte
Ein Standort ist eine Region, die Sie in einer Anfrage angeben können, um zu steuern, wo Daten im Ruhezustand gespeichert werden. Eine Liste der verfügbaren Regionen finden Sie unter Generative AI an Vertex AI-Standorten.
Sicherheitsfilter für verantwortungsbewusste Anwendung von KI
Das Modell für die Funktionen „Bilduntertitelung“ und „Visual Question Answering (VQA)“ unterstützt keine vom Nutzer konfigurierbaren Sicherheitsfilter. Die allgemeine Sicherheitsfilterung von Imagen erfolgt jedoch für die folgenden Daten:
- Nutzereingabe
- Modellausgabe
Daher kann sich Ihre Ausgabe von der Beispielausgabe unterscheiden, wenn Imagen diese Sicherheitsfilter anwendet. Betrachten Sie hierzu folgende Beispiele.
Gefilterte Eingabe
Wenn die Eingabe gefiltert wird, sieht die Antwort in etwa so aus:
{
"error": {
"code": 400,
"message": "Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.DebugInfo",
"detail": "[ORIGINAL ERROR] generic::invalid_argument: Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394 [google.rpc.error_details_ext] { message: \"Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394\" }"
}
]
}
}
Gefilterte Ausgabe
Wenn die Anzahl der zurückgegebenen Antworten kleiner als die von Ihnen angegebene Anzahl ist, bedeutet dies, dass die fehlenden Antworten von der Responsible AI gefiltert werden. Das folgende Beispiel zeigt eine Antwort auf eine Anfrage mit "sampleCount": 2, die beiden Bilder werden jedoch gefiltert:
{
"predictions": [
"cappuccino"
]
}
Wenn die gesamte Ausgabe gefiltert wird, ist die Antwort ein leeres Objekt ähnlich dem folgenden:
{}
VQA für ein Bild verwenden (Kurzantworten)
Verwenden Sie folgende Beispiele, um eine Frage zu stellen und eine Antwort zu einem Bild zu erhalten.
REST
Weitere Informationen zu imagetext-Modellanfragen finden Sie in der imagetextAPI-Referenz des Modells.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_ID: Ihre Google Cloud Projekt-ID.
- LOCATION: Die Region Ihres Projekts. Beispiel:
us-central1,europe-west2oderasia-northeast3. Eine Liste der verfügbaren Regionen finden Sie unter Generative AI an Vertex AI-Standorten. - VQA_PROMPT: Die Frage, die Sie zu Ihrem Bild beantworten lassen möchten.
- Welche Farbe hat dieser Schuh?
- Welche Art von Ärmeln hat das Hemd?
- B64_IMAGE: Das Bild, dem Text hinzugefügt werden soll. Das Bild muss als base64-codierter Bytestring angegeben werden. Größenbeschränkung: 100 MB.
- RESPONSE_COUNT: Die Anzahl der Antworten, die Sie generieren möchten. Zulässige Ganzzahlwerte: 1–3.
HTTP-Methode und URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict
JSON-Text der Anfrage:
{
"instances": [
{
"prompt": "VQA_PROMPT",
"image": {
"bytesBase64Encoded": "B64_IMAGE"
}
}
],
"parameters": {
"sampleCount": RESPONSE_COUNT
}
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict" | Select-Object -Expand Content
"sampleCount": 2 und "prompt": "What is this?". Die Antwort gibt zwei Vorhersagestringantworten zurück.
{
"predictions": [
"cappuccino",
"coffee"
]
}
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Python-Einrichtungsschritten in der Vertex AI-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Vertex AI Python API.
Richten Sie zur Authentifizierung bei Vertex AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
In diesem Beispiel verwenden Sie die Methode load_from_file, um auf eine lokale Datei als Basis-Image zu verweisen, zu der Sie Informationen abrufen. Nachdem Sie das Basis-Image angegeben haben, verwenden Sie die Methode ask_question in der ImageTextModel und drucken die Antworten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Node.js-Einrichtungsschritten in der Vertex AI-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Vertex AI Node.js API.
Richten Sie zur Authentifizierung bei Vertex AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
In diesem Beispiel rufen Sie die Methode in einempredict
PredictionServiceClient auf.
Der Dienst gibt Antworten auf die gestellte Frage zurück.
Parameter für VQA verwenden
Wenn Sie VQA-Antworten erhalten, gibt es je nach Anwendungsfall mehrere Parameter.
Anzahl der Ergebnisse
Verwenden Sie die Anzahl der Ergebnisparameter, um die Anzahl der Antworten zu begrenzen, die pro gesendeter Anfrage zurückgegeben werden. Weitere Informationen finden Sie in der API-Referenz für das Modell imagetext (VQA).
Quell-Nummer
Eine Zahl, die Sie einer Anfrage hinzufügen, um generierte Antworten deterministisch zu machen. Durch Hinzufügen einer Quell-Nummer zu Ihrer Anfrage können Sie sicher sein, dass Sie jedes Mal dieselben Vorhersagen (Antworten) erhalten. Die Antworten werden jedoch nicht unbedingt in derselben Reihenfolge zurückgegeben. Weitere Informationen finden Sie in der API-Referenz für das Modell imagetext (VQA).
Nächste Schritte
Artikel zu Imagen und anderen Produkten für generative KI in Vertex AI:
- Leitfaden für Entwickler zum Einstieg in Imagen 3 in Vertex AI
- Neue generative Medienmodelle und ‑tools, die von und für Creator entwickelt wurden
- Neu in Gemini: Benutzerdefinierte Gems und verbesserte Bildgenerierung mit Imagen 3
- Google DeepMind: Imagen 3 – unser bisher bestes Text-zu-Bild-Modell