O recurso de resposta visual a perguntas (VQA, na sigla em inglês) permite fornecer uma imagem para o modelo e fazer uma pergunta sobre o conteúdo da imagem. Em resposta à sua pergunta, você recebe uma ou mais respostas em linguagem natural.
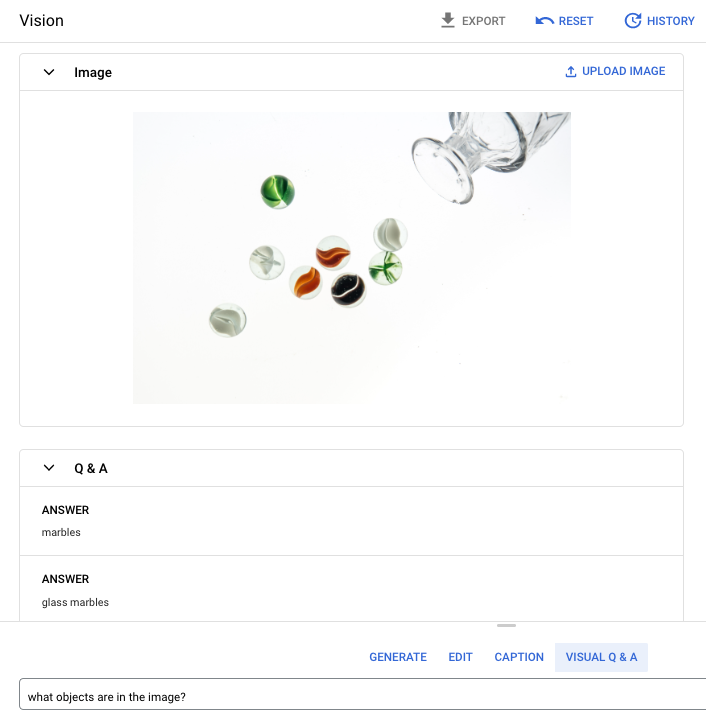
Pergunta imediata: quais objetos estão na imagem?
Resposta 1: bolinhas de gude
Resposta 2: bolinhas de gude de vidro
Linguagens compatíveis
O recurso VQA está disponível nos seguintes idiomas:
- inglês (en)
Desempenho e limitações
Os limites a seguir se aplicam quando você usa esse modelo :
| Limites | Valor |
|---|---|
| Número máximo de solicitações de API (formato curto) por minuto e projeto | 500 |
| Número máximo de tokens retornados na resposta (formato curto) | 64 tokens |
| Número máximo de tokens aceitos na solicitação (somente no formato curto de VQA) | 80 tokens |
As estimativas de latência de serviço a seguir se aplicam quando você usa esse modelo. Estes valores são ilustrativos e não são uma promessa de serviço:
| Latência | Valor |
|---|---|
| Solicitações de API (formato curto) | 1,5 segundos |
Locais
Um local é uma região que pode ser especificada em uma solicitação para controlar onde os dados são armazenados em repouso. Para uma lista de regiões disponíveis, consulte IA generativa em locais da Vertex AI.
Filtragem de segurança da IA responsável
O modelo de recurso de legendagem de imagens e de resposta visual a perguntas (VQA, na sigla em inglês) não aceita filtros de segurança configuráveis pelo usuário. No entanto, a filtragem de segurança geral do Imagen ocorre nos seguintes dados:
- Entrada do usuário
- Saída do modelo
Como resultado, a saída poderá ser diferente da saída da amostra se o Imagen aplicar esses filtros de segurança. Confira estes exemplos.
Entrada filtrada
Se a entrada for filtrada, a resposta será semelhante a esta:
{
"error": {
"code": 400,
"message": "Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.DebugInfo",
"detail": "[ORIGINAL ERROR] generic::invalid_argument: Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394 [google.rpc.error_details_ext] { message: \"Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394\" }"
}
]
}
}
Saída filtrada
Se o número de respostas retornadas for menor que a contagem de amostras especificada,
isso significa que as respostas incompletas serão filtradas pela IA responsável. Por exemplo,
o seguinte é uma resposta a uma solicitação com "sampleCount": 2, mas uma das
respostas é filtrada:
{
"predictions": [
"cappuccino"
]
}
Se toda a saída for filtrada, a resposta será um objeto vazio semelhante a este:
{}
Usar VQA em uma imagem (respostas curtas)
Use os exemplos a seguir para fazer uma pergunta e receber uma resposta sobre uma imagem.
REST
Para mais informações sobre solicitações de modelo imagetext, consulte a referência da API do modelo imagetext.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: o ID do projeto do Google Cloud .
- LOCATION: a região do seu projeto. Por exemplo,
us-central1,europe-west2ouasia-northeast3. Para uma lista de regiões disponíveis, consulte IA generativa em locais da Vertex AI. - VQA_PROMPT: a pergunta que você quer que seja respondida sobre sua imagem.
- Que cor é este sapato?
- Qual é o tipo de manga da camisa?
- B64_IMAGE: a imagem que receberá as legendas. A imagem precisa ser especificada como uma string de bytes codificada em base64. Limite de tamanho: 10 MB.
- RESPONSE_COUNT: o número de respostas que você quer gerar. Valores inteiros aceitos: 1 a 3.
Método HTTP e URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict
Corpo JSON da solicitação:
{
"instances": [
{
"prompt": "VQA_PROMPT",
"image": {
"bytesBase64Encoded": "B64_IMAGE"
}
}
],
"parameters": {
"sampleCount": RESPONSE_COUNT
}
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando abaixo:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict" | Select-Object -Expand Content
"sampleCount": 2 e "prompt": "What is this?". A resposta retorna duas respostas de string de previsão.
{
"predictions": [
"cappuccino",
"coffee"
]
}
Python
Antes de testar essa amostra, siga as instruções de configuração para Python Guia de início rápido da Vertex AI: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Vertex AI para Python.
Para autenticar na Vertex AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Neste exemplo, você usa o método load_from_file para referenciar um arquivo local como
a Image base para acessar informações. Depois de especificar a imagem
de base, use o método ask_question na
ImageTextModel e mostre as respostas.
Node.js
Antes de testar esse exemplo, siga as instruções de configuração para Node.js no Guia de início rápido da Vertex AI sobre como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Vertex AI para Node.js.
Para autenticar na Vertex AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Neste exemplo, você chama o métodopredict
em um
PredictionServiceClient.
O serviço retorna respostas para a pergunta fornecida.
Usar parâmetros para VQA
Ao receber respostas de VQA, há vários parâmetros que podem ser definidos, de acordo com o caso de uso.
Número de resultados
Use o parâmetro de número de resultados para limitar a quantidade de respostas retornadas
para cada solicitação enviada. Para mais informações, consulte a referência da API
do modelo imagetext (VQA).
Número da semente
Um número que você adiciona a uma solicitação para tornar as respostas geradas determinísticas. Adicionar
um número de origem à solicitação é uma maneira de garantir que você sempre receba
a mesma previsão (respostas) todas as vezes. No entanto, as respostas não são
retornadas necessariamente na mesma ordem. Para mais informações, consulte a
referência da API do modelo imagetext (VQA).
A seguir
Confira artigos sobre o Imagen e outras IAs generativas nos produtos da Vertex AI:
- Guia para desenvolvedores sobre como começar a usar o Imagen 3 na Vertex AI
- Novos modelos e ferramentas de mídia generativa criados com criadores para criadores
- Novidades no Gemini: Gems personalizados e geração de imagens aprimorada com o Imagen 3
- Google DeepMind: Imagen 3 — Nosso modelo de qualidade mais alta para conversão de texto em imagem