開發代理程式後,您可以使用 Gen AI 評估服務,評估代理程式完成特定用途的任務和目標的能力。
定義評估指標
請先從空白指標清單 (即 metrics = []) 開始,然後在其中加入相關指標。如要納入其他指標,請按照下列步驟操作:
最終回覆
最終回應評估的程序與模型式評估相同。詳情請參閱「定義評估指標」。
完全比對
metrics.append("trajectory_exact_match")
如果預測軌跡與參照軌跡完全相同,且工具呼叫完全相同,順序也完全一樣,則 trajectory_exact_match 指標會傳回 1 分數,否則會傳回 0。
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。reference_trajectory:代理程式為滿足查詢而預期使用的工具。
依序比對
metrics.append("trajectory_in_order_match")
如果預測軌跡包含參考軌跡中的所有工具呼叫,且順序相同,也可能包含額外的工具呼叫,則 trajectory_in_order_match 指標會傳回 1 分數,否則會傳回 0。
輸入參數:
predicted_trajectory:代理程式預測的軌跡,用於得出最終回覆。reference_trajectory:預期代理程式會採取的路徑,以滿足查詢需求。
不限順序的相符項目
metrics.append("trajectory_any_order_match")
如果預測軌跡包含參照軌跡中的所有工具呼叫,但順序不重要,且可能包含額外的工具呼叫,則 trajectory_any_order_match 指標會傳回 1 分數,否則會傳回 0。
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。reference_trajectory:代理程式為滿足查詢而預期使用的工具。
精確度
metrics.append("trajectory_precision")
trajectory_precision 指標會根據參考軌跡,評估預測軌跡中有多少工具呼叫實際相關或正確。這是 [0, 1] 範圍內的 float 值,分數越高,預測軌跡越準確。
精確度的計算方式如下:計算預測軌跡中也出現在參考軌跡中的動作數量。然後將該次數除以預測軌跡中的動作總數。
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。reference_trajectory:代理程式為滿足查詢而預期使用的工具。
喚回度
metrics.append("trajectory_recall")
trajectory_recall 指標會測量預測路徑實際擷取的參考路徑基本工具呼叫次數。這是 [0, 1] 範圍內的 float 值,分數越高,預測軌跡的召回率就越好。
召回率的計算方式如下:計算參考軌跡中有多少動作也出現在預測軌跡中。然後將該計數除以參考軌跡中的動作總數。
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。reference_trajectory:代理程式為滿足查詢而預期使用的工具。
單一工具用途
from vertexai.preview.evaluation import metrics
metrics.append(metrics.TrajectorySingleToolUse(tool_name='tool_name'))
trajectory_single_tool_use 指標會檢查預測軌跡是否使用指標規格中指定的特定工具。這項指標不會檢查工具呼叫的順序或工具的使用次數,只會檢查工具是否存在。如果沒有工具,值為 0,否則為 1。
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。
自訂
您可以按照下列方式定義自訂指標:
from vertexai.preview.evaluation import metrics
def word_count(instance):
response = instance["response"]
score = len(response.split(" "))
return {"word_count": score}
metrics.append(
metrics.CustomMetric(name="word_count", metric_function=word_count)
)
結果一律會包含下列兩項成效指標。您不需要在 EvalTask 中指定這些屬性:
latency(float):代理程式回應所花的時間 (以秒為單位)。failure(bool):如果代理程式叫用成功,則為0,否則為1。
準備評估資料集
如要準備資料集以評估最終回覆或軌跡,請按照下列步驟操作:
最終回覆
最終回應評估的資料架構與模型回應評估的資料架構類似。
完全比對
評估資料集必須提供下列輸入內容:
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。reference_trajectory:代理程式為滿足查詢而預期使用的工具。
依序比對
評估資料集必須提供下列輸入內容:
輸入參數:
predicted_trajectory:代理程式預測的軌跡,用於得出最終回覆。reference_trajectory:預期代理程式會採取的路徑,以滿足查詢需求。
不限順序的相符項目
評估資料集必須提供下列輸入內容:
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。reference_trajectory:代理程式為滿足查詢而預期使用的工具。
精確度
評估資料集必須提供下列輸入內容:
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。reference_trajectory:代理程式為滿足查詢而預期使用的工具。
喚回度
評估資料集必須提供下列輸入內容:
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。reference_trajectory:代理程式為滿足查詢而預期使用的工具。
單一工具用途
評估資料集必須提供下列輸入內容:
輸入參數:
predicted_trajectory:代理程式用來產生最終回應的工具呼叫清單。
為方便說明,以下是評估資料集的範例。
import pandas as pd
eval_dataset = pd.DataFrame({
"predicted_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_3", "updates": {"status": "OFF"}}
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_z"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
]
],
"reference_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_2", "updates": {"status": "OFF"}},
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_y"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
],
],
})
範例資料集
我們提供下列範例資料集,說明如何評估代理程式:
"on-device":裝置端居家助理的評估資料集。你可以要求代理程式執行查詢,例如「將臥室的空調排定在晚上 11 點到早上 8 點開啟,其他時間關閉」。"customer-support":客戶服務專員的評估資料集。代理商可協助處理「你能取消任何待處理的訂單,並將任何未結案的支援單轉呈給上級嗎?」等查詢。"content-creation":行銷內容建立代理程式的評估資料集。代理程式可協助處理的查詢包括:「將廣告活動 X 重新排定為社群媒體網站 Y 的一次性廣告活動,預算減少 50%,且只在 2024 年 12 月 25 日放送。」
如要匯入範例資料集,請按照下列步驟操作:
下載評估資料集。
裝置上
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/on-device/eval_dataset.json .客戶服務
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/customer-support/eval_dataset.json .內容創作
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/content-creation/eval_dataset.json .載入資料集範例
import json eval_dataset = json.loads(open('eval_dataset.json').read())
生成評估結果
如要產生評估結果,請執行下列程式碼:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(dataset=eval_dataset, metrics=metrics)
eval_result = eval_task.evaluate(runnable=agent)
查看及解讀結果
評估結果會顯示如下:
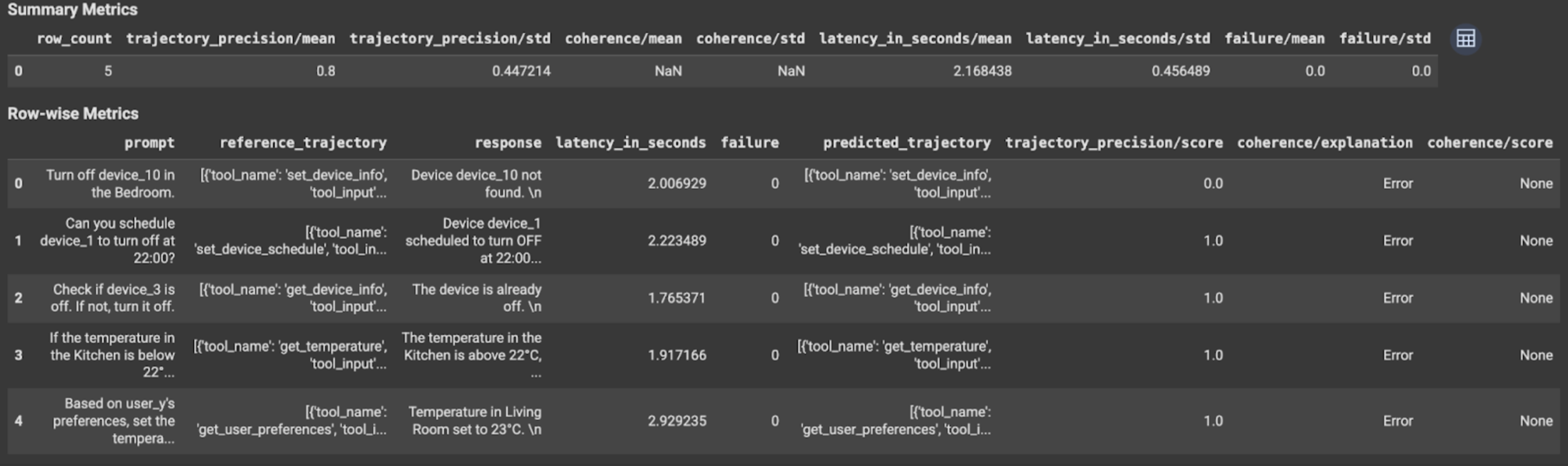
評估結果包含下列資訊:
最終回覆指標
資料列指標:
response:代理程式生成的最終回覆。latency_in_seconds:生成回覆所花的時間 (以秒為單位)。failure:表示是否產生有效的回覆。score:針對指標規格中指定的回應計算的分數。explanation:指標規格中指定的分數說明。
摘要指標:
mean:所有執行個體的平均分數。standard deviation:所有分數的標準差。
軌跡指標
資料列指標:
predicted_trajectory:工具呼叫的序列,後接代理程式,以取得最終回應。reference_trajectory:預期的工具呼叫順序。score:根據指標規格中指定的預測軌跡和參考軌跡計算的分數。latency_in_seconds:生成回覆所花的時間 (以秒為單位)。failure:表示是否產生有效的回覆。
摘要指標:
mean:所有執行個體的平均分數。standard deviation:所有分數的標準差。
後續步驟
請試用下列筆記本: