La llamada a funciones, también conocida como uso de herramientas, proporciona al LLM definiciones de herramientas externas (por ejemplo, una función get_current_weather). Al procesar una petición, el modelo determina de forma inteligente si se necesita una herramienta y, si es así, genera datos estructurados que especifican la herramienta que se debe llamar y sus parámetros (por ejemplo, get_current_weather(location='Boston')). A continuación, tu aplicación ejecuta esta herramienta, envía el resultado al modelo, lo que le permite completar su respuesta con información dinámica del mundo real o el resultado de una acción. De esta forma, se conecta el LLM con tus sistemas y se amplían sus funciones.
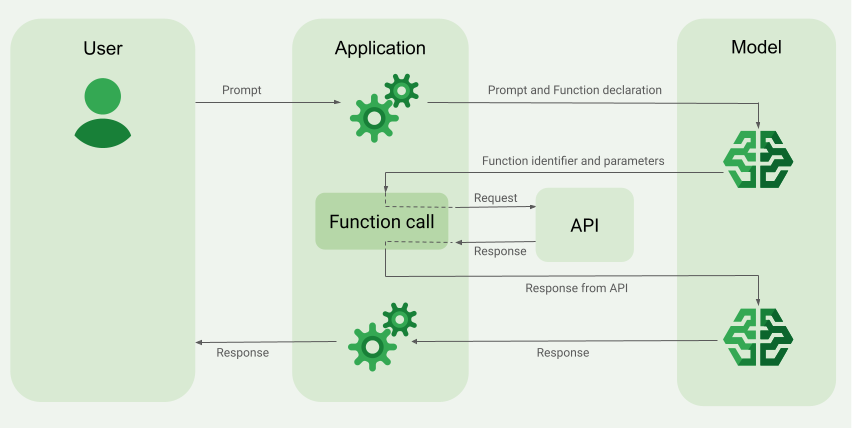
La llamada a funciones permite dos casos prácticos principales:
Obtener datos: recupera información actualizada para las respuestas del modelo, como el tiempo actual, la conversión de divisas o datos específicos de bases de conocimientos y APIs (RAG).
Tomar medidas: realizar operaciones externas, como enviar formularios, actualizar el estado de las aplicaciones u orquestar flujos de trabajo de agentes (por ejemplo, transferencias de conversaciones).
Para ver más casos prácticos y ejemplos basados en la llamada a funciones, consulta Casos prácticos.
Características y limitaciones
Los siguientes modelos admiten la función de llamada a funciones:
Modelos de Gemini:
- Gemini 2.5 Flash-Lite
- Gemini 2.5 Flash con audio nativo de la API Live (versión preliminar)
- Gemini 2.0 Flash con la API Live (versión preliminar)
- Vertex AI Model Optimizer (experimental)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
- Gemini 2.0 Flash-Lite
Modelos abiertos:
Puedes especificar hasta 512
FunctionDeclarations.Define tus funciones en formato de esquema OpenAPI.
Para conocer las prácticas recomendadas relacionadas con las declaraciones de funciones, incluidos consejos sobre nombres y descripciones, consulta Prácticas recomendadas.
En el caso de los modelos abiertos, sigue esta guía del usuario.
Cómo crear una aplicación de llamadas a funciones
Para usar la llamada a funciones, realiza las siguientes tareas:
- Enviar declaraciones de funciones y peticiones al modelo.
- Proporciona la salida de la API al modelo.
Paso 1: Envía la petición y las declaraciones de funciones al modelo
Declara un Tool en un formato de esquema compatible con el esquema OpenAPI. Para obtener más información, consulta Ejemplos de esquemas.
En los siguientes ejemplos se envía una petición y una declaración de función a los modelos de Gemini.
REST
PROJECT_ID=myproject
LOCATION=us-central1
MODEL_ID=gemini-2.0-flash-001
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/${MODEL_ID}:generateContent \
-d '{
"contents": [{
"role": "user",
"parts": [{
"text": "What is the weather in Boston?"
}]
}],
"tools": [{
"functionDeclarations": [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather.",
"default": {
"string_value": "Boston, MA"
}
}
},
"required": [
"location"
]
}
}
]
}]
}'
Python
Puedes especificar el esquema manualmente mediante un diccionario de Python o automáticamente con la función auxiliar from_func. En el siguiente ejemplo se muestra cómo declarar una función manualmente.
import vertexai
from vertexai.generative_models import (
Content,
FunctionDeclaration,
GenerationConfig,
GenerativeModel,
Part,
Tool,
ToolConfig
)
# Initialize Vertex AI
# TODO(developer): Update the project
vertexai.init(project="PROJECT_ID", location="us-central1")
# Initialize Gemini model
model = GenerativeModel(model_name="gemini-2.0-flash")
# Manual function declaration
get_current_weather_func = FunctionDeclaration(
name="get_current_weather",
description="Get the current weather in a given location",
# Function parameters are specified in JSON schema format
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather.",
"default": {
"string_value": "Boston, MA"
}
}
},
},
)
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston?"),
],
)
],
generation_config = GenerationConfig(temperature=0),
tools = [
Tool(
function_declarations=[get_current_weather_func],
)
]
)
También puedes declarar la función automáticamente con la función auxiliar from_func, como se muestra en el siguiente ejemplo:
def get_current_weather(location: str = "Boston, MA"):
"""
Get the current weather in a given location
Args:
location: The city name of the location for which to get the weather.
"""
# This example uses a mock implementation.
# You can define a local function or import the requests library to call an API
return {
"location": "Boston, MA",
"temperature": 38,
"description": "Partly Cloudy",
"icon": "partly-cloudy",
"humidity": 65,
"wind": {
"speed": 10,
"direction": "NW"
}
}
get_current_weather_func = FunctionDeclaration.from_func(get_current_weather)
Node.js
En este ejemplo se muestra un caso práctico de texto con una función y una petición.
Node.js
Antes de probar este ejemplo, sigue las Node.js instrucciones de configuración de la guía de inicio rápido de Vertex AI con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Node.js de Vertex AI.
Para autenticarte en Vertex AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Go
En este ejemplo se muestra un caso práctico de texto con una función y una petición.
Consulta cómo instalar o actualizar Go.
Para obtener más información, consulta la documentación de referencia del SDK.
Define variables de entorno para usar el SDK de IA generativa con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
C#
En este ejemplo se muestra un caso práctico de texto con una función y una petición.
C#
Antes de probar este ejemplo, sigue las C# instrucciones de configuración de la guía de inicio rápido de Vertex AI con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API C# de Vertex AI.
Para autenticarte en Vertex AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Java
Java
Antes de probar este ejemplo, sigue las Java instrucciones de configuración de la guía de inicio rápido de Vertex AI con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de Vertex AI.
Para autenticarte en Vertex AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Si el modelo determina que necesita el resultado de una función concreta, la respuesta que recibe la aplicación del modelo contiene el nombre de la función y los valores de los parámetros con los que se debe llamar a la función.
A continuación se muestra un ejemplo de respuesta del modelo a la petición del usuario "¿Qué tiempo hace en Boston?". El modelo propone llamar a la función get_current_weather con el parámetro Boston, MA.
candidates {
content {
role: "model"
parts {
function_call {
name: "get_current_weather"
args {
fields {
key: "location"
value {
string_value: "Boston, MA"
}
}
}
}
}
}
...
}
Paso 2: Proporciona la salida de la API al modelo
Invoca la API externa y devuelve el resultado de la API al modelo.
En el siguiente ejemplo, se usan datos sintéticos para simular una carga útil de respuesta de una API externa y se envía el resultado al modelo.
REST
PROJECT_ID=myproject
MODEL_ID=gemini-2.0-flash
LOCATION="us-central1"
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/${MODEL_ID}:generateContent \
-d '{
"contents": [
{
"role": "user",
"parts": {
"text": "What is the weather in Boston?"
}
},
{
"role": "model",
"parts": [
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "Boston, MA"
}
}
}
]
},
{
"role": "user",
"parts": [
{
"functionResponse": {
"name": "get_current_weather",
"response": {
"temperature": 20,
"unit": "C"
}
}
}
]
}
],
"tools": [
{
"function_declarations": [
{
"name": "get_current_weather",
"description": "Get the current weather in a specific location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather."
}
},
"required": [
"location"
]
}
}
]
}
]
}'
Python
function_response_contents = []
function_response_parts = []
# Iterates through the function calls in the response in case there are parallel function call requests
for function_call in response.candidates[0].function_calls:
print(f"Function call: {function_call.name}")
# In this example, we'll use synthetic data to simulate a response payload from an external API
if (function_call.args['location'] == "Boston, MA"):
api_response = { "location": "Boston, MA", "temperature": 38, "description": "Partly Cloudy" }
if (function_call.args['location'] == "San Francisco, CA"):
api_response = { "location": "San Francisco, CA", "temperature": 58, "description": "Sunny" }
function_response_parts.append(
Part.from_function_response(
name=function_call.name,
response={"contents": api_response}
)
)
# Add the function call response to the contents
function_response_contents = Content(role="user", parts=function_response_parts)
# Submit the User's prompt, model's response, and API output back to the model
response = model.generate_content(
[
Content( # User prompt
role="user",
parts=[
Part.from_text("What is the weather like in Boston?"),
],
),
response.candidates[0].content, # Function call response
function_response_contents # API output
],
tools=[
Tool(
function_declarations=[get_current_weather_func],
)
],
)
# Get the model summary response
print(response.text)
Para consultar las prácticas recomendadas relacionadas con la invocación de APIs, consulta Prácticas recomendadas: invocación de APIs.
Si el modelo hubiera propuesto varias llamadas de función paralelas, la aplicación debe proporcionar todas las respuestas al modelo. Para obtener más información, consulta el ejemplo de llamada de función paralela.
El modelo puede determinar que la salida de otra función es necesaria para responder a la petición. En este caso, la respuesta que recibe la aplicación del modelo contiene otro nombre de función y otro conjunto de valores de parámetros.
Si el modelo determina que la respuesta de la API es suficiente para responder a la petición del usuario, crea una respuesta en lenguaje natural y la devuelve a la aplicación. En este caso, la aplicación debe devolver la respuesta al usuario. A continuación, se muestra un ejemplo de respuesta en lenguaje natural:
It is currently 38 degrees Fahrenheit in Boston, MA with partly cloudy skies.
Llamadas de funciones con reflexiones
Cuando llames a funciones con la opción thinking habilitada, tendrás que obtener el thought_signature del objeto de respuesta del modelo y devolverlo cuando envíes el resultado de la ejecución de la función al modelo. Por ejemplo:
Python
# Call the model with function declarations
# ...Generation config, Configure the client, and Define user prompt (No changes)
# Send request with declarations (using a thinking model)
response = client.models.generate_content(
model="gemini-2.5-flash", config=config, contents=contents)
# See thought signatures
for part in response.candidates[0].content.parts:
if not part.text:
continue
if part.thought and part.thought_signature:
print("Thought signature:")
print(part.thought_signature)
No es obligatorio ver las firmas de pensamiento, pero tendrás que modificar el paso 2 para que se devuelvan junto con el resultado de la ejecución de la función, de forma que pueda incorporar los pensamientos a su respuesta final:
Python
# Create user friendly response with function result and call the model again
# ...Create a function response part (No change)
# Append thought signatures, function call and result of the function execution to contents
function_call_content = response.candidates[0].content
# Append the model's function call message, which includes thought signatures
contents.append(function_call_content)
contents.append(types.Content(role="user", parts=[function_response_part])) # Append the function response
final_response = client.models.generate_content(
model="gemini-2.5-flash",
config=config,
contents=contents,
)
print(final_response.text)
Cuando devuelvas firmas de pensamiento, sigue estas directrices:
- El modelo devuelve firmas en otras partes de la respuesta, como las partes de llamada a función, texto, texto o resúmenes de pensamientos. Devuelve toda la respuesta con todas las partes al modelo en las siguientes interacciones.
- No combines una parte con una firma con otra parte que también contenga una firma. Las firmas no se pueden concatenar.
- No combines una parte con una firma con otra parte sin firma. Esto rompe el posicionamiento correcto del pensamiento representado por la firma.
Consulta más información sobre las limitaciones y el uso de las firmas de pensamiento, así como sobre los modelos de pensamiento en general, en la página Pensamiento.
Llamadas a funciones paralelas
En el caso de las peticiones como "¿Qué tiempo hace en Boston y San Francisco?", el modelo puede proponer varias llamadas a funciones paralelas. Para ver una lista de los modelos que admiten llamadas a funciones paralelas, consulta Modelos admitidos.
REST
En este ejemplo se muestra una situación con una función get_current_weather.
La petición del usuario es "¿Qué tiempo hace en Boston y San Francisco?". El modelo propone dos llamadas de función get_current_weather paralelas: una con el parámetro Boston y otra con el parámetro San Francisco.
Para obtener más información sobre los parámetros de solicitud, consulta la API de Gemini.
{
"candidates": [
{
"content": {
"role": "model",
"parts": [
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "Boston"
}
}
},
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "San Francisco"
}
}
}
]
},
...
}
],
...
}
El siguiente comando muestra cómo puedes proporcionar la salida de la función al modelo. Sustituye my-project por el nombre de tu Google Cloud proyecto.
Solicitud de modelo
PROJECT_ID=my-project
MODEL_ID=gemini-2.0-flash
LOCATION="us-central1"
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/${MODEL_ID}:generateContent \
-d '{
"contents": [
{
"role": "user",
"parts": {
"text": "What is difference in temperature in Boston and San Francisco?"
}
},
{
"role": "model",
"parts": [
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "Boston"
}
}
},
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "San Francisco"
}
}
}
]
},
{
"role": "user",
"parts": [
{
"functionResponse": {
"name": "get_current_weather",
"response": {
"temperature": 30.5,
"unit": "C"
}
}
},
{
"functionResponse": {
"name": "get_current_weather",
"response": {
"temperature": 20,
"unit": "C"
}
}
}
]
}
],
"tools": [
{
"function_declarations": [
{
"name": "get_current_weather",
"description": "Get the current weather in a specific location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather."
}
},
"required": [
"location"
]
}
}
]
}
]
}'
La respuesta en lenguaje natural creada por el modelo es similar a la siguiente:
Respuesta del modelo
[
{
"candidates": [
{
"content": {
"parts": [
{
"text": "The temperature in Boston is 30.5C and the temperature in San Francisco is 20C. The difference is 10.5C. \n"
}
]
},
"finishReason": "STOP",
...
}
]
...
}
]
Python
En este ejemplo se muestra una situación con una función get_current_weather.
La petición del usuario es "¿Qué tiempo hace en Boston y San Francisco?".
Sustituye my-project por el nombre de tu Google Cloud proyecto.
import vertexai
from vertexai.generative_models import (
Content,
FunctionDeclaration,
GenerationConfig,
GenerativeModel,
Part,
Tool,
ToolConfig
)
# Initialize Vertex AI
# TODO(developer): Update the project
vertexai.init(project="my-project", location="us-central1")
# Initialize Gemini model
model = GenerativeModel(model_name="gemini-2.0-flash")
# Manual function declaration
get_current_weather_func = FunctionDeclaration(
name="get_current_weather",
description="Get the current weather in a given location",
# Function parameters are specified in JSON schema format
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather.",
"default": {
"string_value": "Boston, MA"
}
}
},
},
)
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston and San Francisco?"),
],
)
],
generation_config = GenerationConfig(temperature=0),
tools = [
Tool(
function_declarations=[get_current_weather_func],
)
]
)
El siguiente comando muestra cómo puedes proporcionar la salida de la función al modelo.
function_response_contents = []
function_response_parts = []
# You can have parallel function call requests for the same function type.
# For example, 'location_to_lat_long("London")' and 'location_to_lat_long("Paris")'
# In that case, collect API responses in parts and send them back to the model
for function_call in response.candidates[0].function_calls:
print(f"Function call: {function_call.name}")
# In this example, we'll use synthetic data to simulate a response payload from an external API
if (function_call.args['location'] == "Boston, MA"):
api_response = { "location": "Boston, MA", "temperature": 38, "description": "Partly Cloudy" }
if (function_call.args['location'] == "San Francisco, CA"):
api_response = { "location": "San Francisco, CA", "temperature": 58, "description": "Sunny" }
function_response_parts.append(
Part.from_function_response(
name=function_call.name,
response={"contents": api_response}
)
)
# Add the function call response to the contents
function_response_contents = Content(role="user", parts=function_response_parts)
function_response_contents
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston and San Francisco?"),
],
), # User prompt
response.candidates[0].content, # Function call response
function_response_contents, # Function response
],
tools = [
Tool(
function_declarations=[get_current_weather_func],
)
]
)
# Get the model summary response
print(response.text)
Go
Modos de llamada de funciones
Puedes controlar cómo usa el modelo las herramientas proporcionadas (declaraciones de funciones) configurando el modo en function_calling_config.
| Modo | Descripción |
|---|---|
AUTO |
El comportamiento predeterminado del modelo. El modelo decide si debe predecir llamadas de funciones o responder con lenguaje natural en función del contexto. Este es el modo más flexible y se recomienda para la mayoría de las situaciones. |
VALIDATED (vista previa) |
El modelo solo puede predecir llamadas a funciones o lenguaje natural, y se asegura de que se cumpla el esquema de las funciones. Si no se proporciona allowed_function_names, el modelo elige entre todas las declaraciones de funciones disponibles. Si se proporciona allowed_function_names, el modelo elige entre el conjunto de funciones permitidas. |
ANY |
El modelo siempre predice una o varias llamadas a funciones y se asegura de que se cumpla el esquema de las funciones. Si no se proporciona allowed_function_names, el modelo elige entre todas las declaraciones de funciones disponibles. Si se proporciona allowed_function_names, el modelo elige entre el conjunto de funciones permitidas. Usa este modo cuando necesites una respuesta de llamada a función para cada petición (si procede). |
NONE |
El modelo tiene prohibido hacer llamadas a funciones. Es lo mismo que enviar una solicitud sin ninguna declaración de función. Usa este modo para inhabilitar temporalmente las llamadas a funciones sin eliminar las definiciones de tus herramientas. |
Llamadas de funciones forzadas
En lugar de permitir que el modelo elija entre una respuesta en lenguaje natural y una llamada a una función, puedes obligarlo a predecir solo llamadas a funciones. Esto se conoce como llamada a funciones forzada. También puede proporcionar al modelo un conjunto completo de declaraciones de funciones, pero restringir sus respuestas a un subconjunto de estas funciones.
En el siguiente ejemplo, se obliga a predecir solo las llamadas a la función get_weather.
Python
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston?"),
],
)
],
generation_config = GenerationConfig(temperature=0),
tools = [
Tool(
function_declarations=[get_weather_func, some_other_function],
)
],
tool_config=ToolConfig(
function_calling_config=ToolConfig.FunctionCallingConfig(
# ANY mode forces the model to predict only function calls
mode=ToolConfig.FunctionCallingConfig.Mode.ANY,
# Allowed function calls to predict when the mode is ANY. If empty, any of
# the provided function calls will be predicted.
allowed_function_names=["get_weather"],
)
)
)
Ejemplos de esquemas de funciones
Las declaraciones de funciones son compatibles con el esquema de OpenAPI. Admitimos los siguientes atributos: type, nullable, required, format, description, properties, items, enum, anyOf, $ref y $defs. No se admiten los atributos restantes.
Función con parámetros de objeto y de array
En el siguiente ejemplo se usa un diccionario de Python para declarar una función que toma parámetros de objeto y de matriz:
extract_sale_records_func = FunctionDeclaration( name="extract_sale_records", description="Extract sale records from a document.", parameters={ "type": "object", "properties": { "records": { "type": "array", "description": "A list of sale records", "items": { "description": "Data for a sale record", "type": "object", "properties": { "id": {"type": "integer", "description": "The unique id of the sale."}, "date": {"type": "string", "description": "Date of the sale, in the format of MMDDYY, e.g., 031023"}, "total_amount": {"type": "number", "description": "The total amount of the sale."}, "customer_name": {"type": "string", "description": "The name of the customer, including first name and last name."}, "customer_contact": {"type": "string", "description": "The phone number of the customer, e.g., 650-123-4567."}, }, "required": ["id", "date", "total_amount"], }, }, }, "required": ["records"], }, )
Función con parámetro enum
En el siguiente ejemplo se usa un diccionario de Python para declarar una función que toma un parámetro enum entero:
set_status_func = FunctionDeclaration( name="set_status", description="set a ticket's status field", # Function parameters are specified in JSON schema format parameters={ "type": "object", "properties": { "status": { "type": "integer", "enum": [ "10", "20", "30" ], # Provide integer (or any other type) values as strings. } }, }, )
Función con ref y def
En la siguiente declaración de función JSON se usan los atributos ref y defs:
{ "contents": ..., "tools": [ { "function_declarations": [ { "name": "get_customer", "description": "Search for a customer by name", "parameters": { "type": "object", "properties": { "first_name": { "ref": "#/defs/name" }, "last_name": { "ref": "#/defs/name" } }, "defs": { "name": { "type": "string" } } } } ] } ] }
Notas sobre el uso:
- A diferencia del esquema de OpenAPI, especifica
refydefssin el símbolo$. refdebe hacer referencia a un elemento secundario directo dedefs; no se permiten referencias externas.- La profundidad máxima del esquema anidado es de 32.
- La profundidad de recursión en
defs(autorreferencia) está limitada a dos.
from_func con el parámetro de array
En el siguiente código de ejemplo se declara una función que multiplica una matriz de números y usa from_func para generar el esquema FunctionDeclaration.
from typing import List # Define a function. Could be a local function or you can import the requests library to call an API def multiply_numbers(numbers: List[int] = [1, 1]) -> int: """ Calculates the product of all numbers in an array. Args: numbers: An array of numbers to be multiplied. Returns: The product of all the numbers. If the array is empty, returns 1. """ if not numbers: # Handle empty array return 1 product = 1 for num in numbers: product *= num return product multiply_number_func = FunctionDeclaration.from_func(multiply_numbers) """ multiply_number_func contains the following schema: {'name': 'multiply_numbers', 'description': 'Calculates the product of all numbers in an array.', 'parameters': {'properties': {'numbers': {'items': {'type': 'INTEGER'}, 'description': 'list of numbers', 'default': [1.0, 1.0], 'title': 'Numbers', 'type': 'ARRAY'}}, 'description': 'Calculates the product of all numbers in an array.', 'title': 'multiply_numbers', 'property_ordering': ['numbers'], 'type': 'OBJECT'}} """
Prácticas recomendadas para las llamadas a funciones
Escribe nombres de funciones, descripciones de parámetros e instrucciones claras y detalladas
Los nombres de las funciones deben empezar por una letra o un guion bajo y solo pueden contener caracteres de la a a la z, de la A a la Z, del 0 al 9, guiones bajos, puntos o guiones. La longitud máxima es de 64 caracteres.
Sé muy claro y específico en las descripciones de las funciones y los parámetros. El modelo se basa en ellos para elegir la función correcta y proporcionar los argumentos adecuados. Por ejemplo, una función
book_flight_ticketpodría tener la descripciónbook flight tickets after confirming users' specific requirements, such as time, departure, destination, party size and preferred airline
Usar parámetros con tipos definidos
Si los valores de los parámetros proceden de un conjunto finito, añada un campo enum en lugar de incluir el conjunto de valores en la descripción. Si el valor del parámetro siempre es un número entero, define el tipo como integer en lugar de number.
Selección de herramientas
Aunque el modelo puede usar un número arbitrario de herramientas, si se le proporcionan demasiadas, puede aumentar el riesgo de que seleccione una herramienta incorrecta o no óptima. Para obtener los mejores resultados, intenta proporcionar solo las herramientas relevantes para el contexto o la tarea. Lo ideal es que el conjunto activo no supere las 10-20 herramientas. Si tienes un número total de herramientas elevado, considera la posibilidad de seleccionar herramientas de forma dinámica en función del contexto de la conversación.
Si proporcionas herramientas genéricas de bajo nivel (como bash), es posible que el modelo use la herramienta con más frecuencia, pero con menos precisión. Si proporcionas una herramienta específica de alto nivel (como get_weather), el modelo podrá usarla con mayor precisión, pero es posible que no se utilice con tanta frecuencia.
Usar instrucciones del sistema
Cuando uses funciones con parámetros de fecha, hora o ubicación, incluye la fecha, la hora o la información de ubicación pertinente (por ejemplo, la ciudad y el país) en la instrucción del sistema. De esta forma, el modelo tiene el contexto necesario para procesar la solicitud con precisión, aunque la petición del usuario no incluya muchos detalles.
Ingeniería de peticiones
Para obtener los mejores resultados, añade al principio de la petición del usuario los siguientes detalles:
- Contexto adicional para el modelo, por ejemplo,
You are a flight API assistant to help with searching flights based on user preferences. - Detalles o instrucciones sobre cómo y cuándo usar las funciones. Por ejemplo,
Don't make assumptions on the departure or destination airports. Always use a future date for the departure or destination time. - Instrucciones para hacer preguntas aclaratorias si las consultas de los usuarios son ambiguas, por ejemplo,
Ask clarifying questions if not enough information is available.
Usar la configuración de generación
En el parámetro de temperatura, usa 0 u otro valor bajo. De esta forma, se indica al modelo que genere resultados más fiables y se reducen las alucinaciones.
Validar la llamada a la API
Si el modelo propone la invocación de una función que enviaría un pedido, actualizaría una base de datos o tendría otras consecuencias significativas, valida la llamada a la función con el usuario antes de ejecutarla.
Usar firmas de pensamiento
Las firmas de pensamiento siempre deben usarse con la llamada a funciones para obtener los mejores resultados.
Precios
El precio de las llamadas a funciones se basa en el número de caracteres de las entradas y salidas de texto. Para obtener más información, consulta los precios de Vertex AI.
En este caso, la entrada de texto (petición) hace referencia a la petición del usuario para el turno de conversación actual, las declaraciones de funciones del turno de conversación actual y el historial de la conversación. El historial de la conversación incluye las consultas, las llamadas a funciones y las respuestas de funciones de las conversaciones anteriores. Vertex AI trunca el historial de la conversación a 32.000 caracteres.
El resultado de texto (respuesta) hace referencia a las llamadas a funciones y a las respuestas de texto del turno de conversación actual.
Casos prácticos de la función de llamada
Puedes usar las llamadas a funciones para las siguientes tareas:
| Caso práctico | Descripción de ejemplo | Enlace de ejemplo |
|---|---|---|
| Integrar con APIs externas | Obtener información meteorológica mediante una API meteorológica | Tutorial sobre cuadernos |
| Convertir direcciones en coordenadas de latitud y longitud | Tutorial sobre cuadernos | |
| Convertir monedas con una API de cambio de divisas | Codelab | |
| Crear chatbots avanzados | Responder a las preguntas de los clientes sobre productos y servicios | Tutorial sobre cuadernos |
| Crea un asistente para responder preguntas financieras y de actualidad sobre empresas | Tutorial sobre cuadernos | |
| Estructurar y controlar las llamadas de funciones | Extraer entidades estructuradas de datos de registro sin procesar | Tutorial sobre cuadernos |
| Extraer uno o varios parámetros de la entrada del usuario | Tutorial sobre cuadernos | |
| Gestionar listas y estructuras de datos anidadas en llamadas de funciones | Tutorial sobre cuadernos | |
| Gestionar el comportamiento de las llamadas a funciones | Gestionar llamadas y respuestas de funciones paralelas | Tutorial sobre cuadernos |
| Gestionar cuándo y a qué funciones puede llamar el modelo | Tutorial sobre cuadernos | |
| Consultar bases de datos con lenguaje natural | Convertir preguntas en lenguaje natural en consultas de SQL para BigQuery | Aplicación de ejemplo |
| Llamadas a funciones multimodales | Usar imágenes, vídeos, audio y PDFs como entrada para activar llamadas a funciones | Tutorial sobre cuadernos |
Estos son algunos casos prácticos más:
Interpretar comandos de voz: crea funciones que se correspondan con tareas del vehículo. Por ejemplo, puedes crear funciones que enciendan la radio o activen el aire acondicionado. Envía archivos de audio de los comandos de voz del usuario al modelo y pídele que convierta el audio en texto e identifique la función a la que quiere llamar el usuario.
Automatizar flujos de trabajo en función de activadores ambientales: crea funciones para representar procesos que se puedan automatizar. Proporciona al modelo datos de sensores ambientales y pídele que analice y procese los datos para determinar si se debe activar uno o varios de los flujos de trabajo. Por ejemplo, un modelo podría procesar datos de temperatura en un almacén y activar un sistema de rociadores.
Automatiza la asignación de incidencias de asistencia: proporciona al modelo incidencias de asistencia, registros y reglas contextuales. Pide al modelo que procese toda esta información para determinar a quién se debe asignar la incidencia. Llama a una función para asignar la incidencia a la persona sugerida por el modelo.
Recuperar información de una base de conocimientos: crea funciones que recuperen artículos académicos sobre un tema concreto y los resuman. Permite que el modelo responda a preguntas sobre temas académicos y proporcione citas para sus respuestas.
Siguientes pasos
Consulta la referencia de la API para las llamadas a funciones.
Consulta información sobre Vertex AI Agent Engine.