系统架构
张量处理单元 (TPU) 是 Google 专为加速机器学习工作负载而设计的应用专用集成电路 (ASIC)。Cloud TPU 是一项 Google Cloud 服务,可将 TPU 作为可伸缩资源使用。
TPU 旨在快速执行矩阵运算,因此非常适合机器学习工作负载。您可以使用 TensorFlow、Pytorch 和 JAX 等框架在 TPU 上运行机器学习工作负载。
Cloud TPU 术语
如果您刚开始接触 Cloud TPU,请查看 TPU 文档首页。 以下部分介绍了本文档中使用的术语和相关概念。
批量推理
批量或离线推理是指在生产流水线之外进行推理,通常基于大量输入。批量推理可用于为数据加标签等离线任务,也可用于评估训练后的模型。延迟时间 SLO 不是批量推断的优先事项。
TPU 芯片
一个 TPU 芯片包含一个或多个 TensorCore。TensorCore 的数量取决于 TPU 芯片的版本。每个 TensorCore 都包含一个或多个矩阵乘法单元 (MXU)、向量单元和标量单元。
MXU 由一个收缩阵列中的 128 x 128 个乘积累加器组成。 MXU 提供了 TensorCore 中的大部分计算能力。每个 MXU 能够在每个周期执行 16,000 次乘积累加运算。所有相乘均采用 bfloat16 输入,但所有累加均以 FP32 数字格式执行。
矢量单位用于一般计算,例如激活和 softmax。标量单位用于控制流、计算内存地址和其他维护操作。
TPU 立方体
4x4x4 拓扑。这仅适用于 3D 拓扑(从 v4 TPU 版本开始)。
推理
推断是使用经过训练的模型对新数据进行预测的过程。它由传送进程使用。
多切片与单切片
多切片 (Multislice) 是一组切片,可将 TPU 连接扩展到芯片间互连 (ICI) 连接之外,并利用数据中心网络 (DCN) 将数据传输到切片以外。每个切片中的数据仍由 ICI 传输。利用这种混合连接,Multislice 实现了多个切片的并行性,让您可以为单个作业使用比单个切片可以容纳的更多的 TPU 核心数。
TPU 可用于在单个切片或多个切片上运行作业。如需了解详情,请参阅多切片简介。
Cloud TPU ICI 弹性
ICI 弹性有助于提高在立方体之间连接 TPU 的光链路和光学电路交换机 (OCS) 的容错能力。(立方体内的 ICI 连接使用的是不受影响的铜制链路)。 ICI 弹性允许 ICI 连接围绕 OCS 和光学 ICI 故障进行路由。因此,它可以提高 TPU 切片的调度可用性,但代价是 ICI 性能会暂时下降。
与 Cloud TPU v4 类似,对于一个或更大的 v5p 切片,系统会默认启用 ICI 弹性:
- v5p-128(在指定加速器类型时)
- 4x4x4(指定加速器配置时)
已加入队列的资源
TPU 资源的表示,用于对单切片或多切片 TPU 环境的请求加入队列和管理。如需了解详情,请参阅已加入队列的资源用户指南。
正在处理
服务是将经过训练的机器学习模型部署到生产环境的过程,在该环境中,该模型可用于进行预测或决策。延迟时间和服务级可用性对传送非常重要。
单主机和多主机
TPU 主机是在连接到 TPU 硬件的物理计算机上运行的虚拟机。TPU 工作负载可以使用一个或多个主机。
单主机工作负载仅限一个 TPU 虚拟机。多主机工作负载在多个 TPU 虚拟机上分配训练。
切片
Pod 切片是所有位于同一个 TPU Pod 内的芯片的集合,这些芯片通过高速芯片间互连 (ICI) 连接。切片以芯片或 TensorCore 加以描述,具体取决于 TPU 版本。
芯片形状和芯片拓扑也是指切片形状。
SparseCore
v5p 包含每个芯片有四个 SparseCore,这些核心是 Dataflow 处理器,可加速依赖于推荐模型中的嵌入的模型。
TPU Pod
TPU Pod 是通过专用网络组合在一起的一组连续的 TPU。TPU Pod 中的 TPU 芯片的数量取决于 TPU 版本。
TPU 虚拟机或工作器
一台运行 Linux 并且能够访问底层 TPU 的虚拟机。TPU 虚拟机也称为工作器。
TensorCores
TPU 芯片有一个或两个 TensorCore 用于运行矩阵乘法。 如需详细了解 TensorCore,请参阅这篇 ACM 文章。
工作器
请参阅 TPU 虚拟机。
TPU 版本
TPU 芯片的具体架构取决于您使用的 TPU 版本。每个 TPU 版本还支持不同的切片大小和配置。如需详细了解系统架构和支持的配置,请参阅以下页面:
TPU 架构
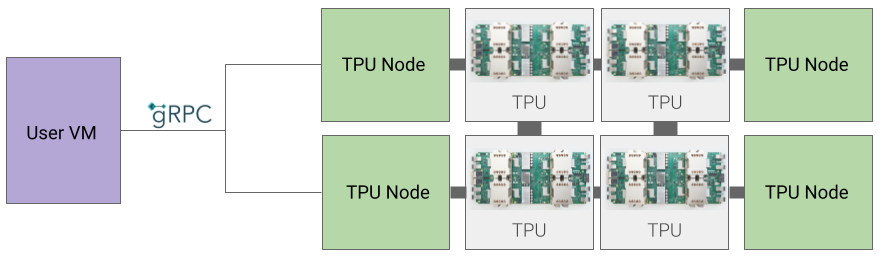
有两种 TPU 架构描述了虚拟机如何物理连接到 TPU 设备:TPU 节点和 TPU 虚拟机。TPU 节点是 v2 和 v3 TPU 版本的原始 TPU 架构。在 v4 中,TPU 虚拟机成为默认架构,但这两种架构都受支持。TPU 节点架构已弃用,仅支持 TPU 虚拟机。如果您使用的是 TPU 节点,请参阅从 TPU 节点迁移到 TPU 虚拟机架构,从 TPU 节点转换为 TPU 虚拟机架构。
TPU 虚拟机架构
通过 TPU 虚拟机架构,您可以使用 SSH 直接连接到以物理方式连接到 TPU 设备的虚拟机。您拥有虚拟机的 root 访问权限,因此可以运行任意代码。您可以访问编译器和运行时调试日志和错误消息。

TPU 节点架构
TPU 节点架构由一个通过 gRPC 与 TPU 主机通信的用户虚拟机组成。使用此架构时,您无法直接访问 TPU 主机,从而难以调试训练和 TPU 错误。
从 TPU 节点迁移到 TPU 虚拟机架构
如果您有使用 TPU 节点架构的 TPU,请按照以下步骤找出、删除它们,并重新预配为 TPU 虚拟机。
转到 TPU 页面:
- 在架构标题下找到您的 TPU 及其架构。如果架构是“TPU 虚拟机”,您无需执行任何操作。如果架构是“TPU 节点”,您需要删除并重新预配 TPU。
删除并重新预配 TPU。