TPU v6e
This document describes the architecture and supported configurations of Cloud TPU v6e (Trillium).
Trillium is Cloud TPU's latest generation AI accelerator. On all technical surfaces, such as the API and logs, and throughout this document, Trillium will be referred to as v6e.
With a 256-chip footprint per Pod, v6e shares many similarities with v5e. This system is optimized to be the highest value product for transformer, text-to-image, and convolutional neural network (CNN) training, fine-tuning, and serving.
System architecture
Each v6e chip contains one TensorCore. Each TensorCore has 2 matrix-multiply units (MXU), a vector unit, and a scalar unit. The following table shows the key specifications and their values for TPU v6e compared to TPU v5e.
| Specification | v5e | v6e |
|---|---|---|
| Performance/total cost of ownership (TCO) (expected) | 0.65x | 1 |
| Peak compute per chip (bf16) | 197 TFLOPs | 918 TFLOPs |
| Peak compute per chip (Int8) | 393 TOPs | 1836 TOPs |
| HBM capacity per chip | 16 GB | 32 GB |
| HBM bandwidth per chip | 800 GBps | 1600 GBps |
| Inter-chip interconnect (ICI) bandwidth | 1600 Gbps | 3200 Gbps |
| ICI ports per chip | 4 | 4 |
| DRAM per host | 512 GiB | 1536 GiB |
| Chips per host | 8 | 8 |
| TPU Pod size | 256 chips | 256 chips |
| Interconnect topology | 2D torus | 2D torus |
| BF16 peak compute per Pod | 50.63 PFLOPs | 234.9 PFLOPs |
| All-reduce bandwidth per Pod | 51.2 TB/s | 102.4 TB/s |
| Bisection bandwidth per Pod | 1.6 TB/s | 3.2 TB/s |
| Per-host NIC configuration | 2 x 100 Gbps NIC | 4 x 200 Gbps NIC |
| Data center network bandwidth per Pod | 6.4 Tbps | 25.6 Tbps |
| Special features | - | SparseCore |
Supported configurations
The following table shows the 2D slice shapes that are supported for v6e:
| Topology | TPU chips | Hosts | VMs | Accelerator type (TPU API) | Machine type (GKE API) | Scope |
|---|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
Sub-host |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
Sub-host |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
Single-host |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
Single-host |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
Multi-host |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
Multi-host |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
Multi-host |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
Multi-host |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
Multi-host |
Slices with 8 chips (v6e-8) attached to a single VM are optimized for
inference, allowing all 8 chips to be used in a single serving workload. You can
perform multi-host inference using Pathways on Cloud. For more information, see
Perform multihost inference using Pathways.
For information about the number of VMs for each topology, see VM Types.
VM types
Each TPU v6e VM can contain 1, 4, or 8 chips. 4-chip and smaller slices have the same non-uniform memory access (NUMA) node. For more information about NUMA nodes, see Non-uniform memory access on Wikipedia.
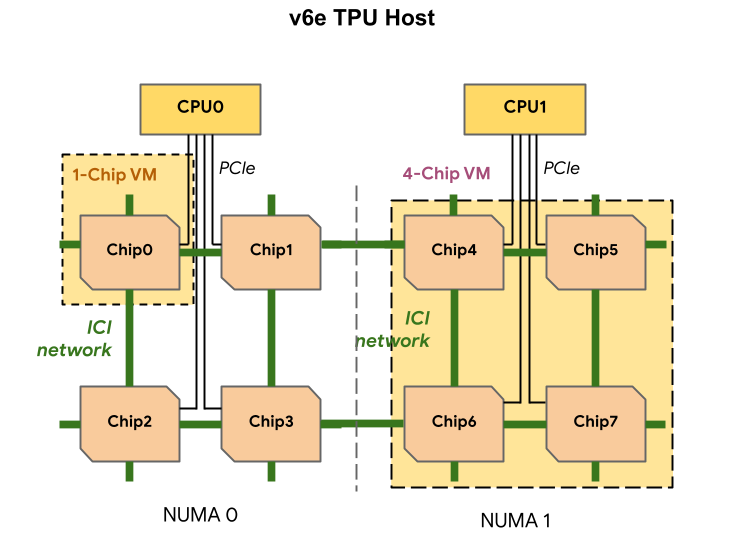
v6e slices are created using half-host VMs, each with 4 TPU chips. There are two exceptions to this rule:
v6e-1: A VM with only a single chip, primarily intended for testingv6e-8: A full-host VM that has been optimized for an inference use case with all 8 chips attached to a single VM.
The following table shows a comparison of TPU v6e VM types:
| VM type | Number of vCPUs per VM | RAM (GB) per VM | Number of NUMA nodes per VM |
|---|---|---|---|
| 1-chip VM | 44 | 176 | 1 |
| 4-chip VM | 180 | 720 | 1 |
| 8-chip VM | 180 | 1440 | 2 |
Specify v6e configuration
When you allocate a TPU v6e slice using the TPU API, you specify its size and
shape using the AcceleratorType parameter.
If you're using GKE, use the --machine-type flag to specify a
machine type that supports the TPU you want to use. For more information, see
Plan TPUs in GKE in the GKE
documentation.
Use AcceleratorType
When you allocate TPU resources, you use AcceleratorType to specify the number
of TensorCores in a slice. The value you specify for
AcceleratorType is a string with the format: v$VERSION-$TENSORCORE_COUNT.
For example, v6e-8 specifies a v6e TPU slice with 8 TensorCores.
The following example shows how to create a TPU v6e slice with 32 TensorCores
using AcceleratorType:
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e
Console
In the Google Cloud console, go to the TPUs page:
Click Create TPU.
In the Name field, enter a name for your TPU.
In the Zone box, select the zone where you want to create the TPU.
In the TPU type box, select
v6e-32.In the TPU software version box, select
v2-alpha-tpuv6e. When creating a Cloud TPU VM, the TPU software version specifies the version of the TPU runtime to install. For more information, see TPU VM images.Click the Enable queueing toggle.
In the Queued resource name field, enter a name for your queued resource request.
Click Create.